阿里云EMR Remote Shuffle Service在小米的实践

一 问题回顾
-
本地盘依赖限制了存算分离。存算分离是近年来兴起的新型架构,它解耦了计算和存储,可以更灵活地做机型设计:计算节点强CPU弱磁盘,存储节点强磁盘强网络弱CPU。计算节点无状态,可根据负载弹性伸缩。存储端,随着对象存储(OSS, S3)+数据湖格式(Delta, Iceberg, Hudi)+本地/近地缓存等方案的成熟,可当作容量无限的存储服务。用户通过计算弹性+存储按量付费获得成本节约。然而,Shuffle对本地盘的依赖限制了存算分离。
-
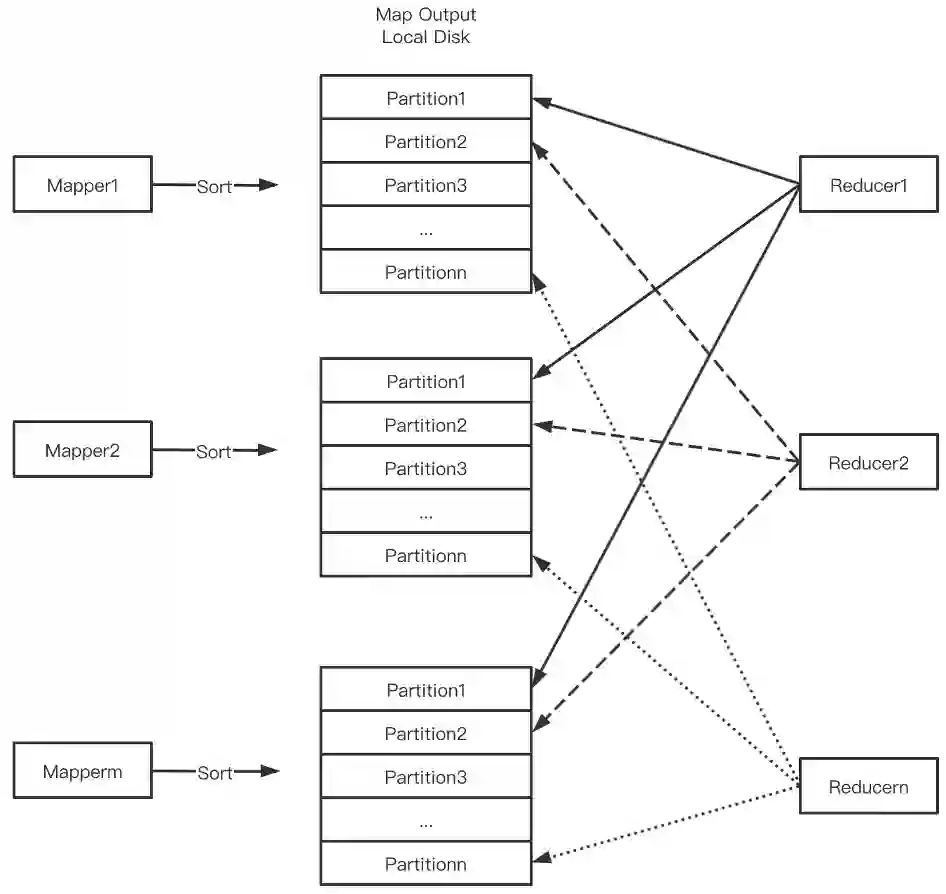
写放大。当Mapper Output数据量超过内存时触发外排,从而引入额外磁盘IO。
-
大量随机读。Mapper Output属于某个Reducer的数据量很小,如Output 128M,Reducer并发2000,则每个Reducer只读64K,从而导致大量小粒度随机读。对于HDD,随机读性能极差;对于SSD,会快速消耗SSD寿命。
-
高网络连接数,导致线程池消耗过多CPU,带来性能和稳定性问题。
-
Shuffle数据单副本,大规模集群场景坏盘/坏节点很普遍,Shuffle数据丢失引发的Stage重算带来性能和稳定性问题。
二 RSS发展历程
1 Sailfish
2 Dataflow
3 Riffle
4 Cosco
5 Zeus
6 RPMP
7 Magnet
8 FireStorm
-
集成到Spark内部还是独立服务。 -
RSS服务侧架构,选项包括:Master-Worker,含轻量级状态管理的去中心化,完全去中心化。 -
Shuffle数据的存储,选项包括:内存,本地盘,DFS,对象存储。 -
多副本的实现,选项包括:Client多推,服务端做Replication。
三 阿里云RSS核心架构
-
独立服务。考虑到将RSS集成到Spark内部无法满足存算分离架构,阿里云RSS将作为独立服务提供Shuffle服务。 -
Master-Worker架构。通过Master节点做服务状态管理非常必要,基于etcd的状态状态管理能力受限。 -
多种存储方式。目前支持本地盘/DFS等存储方式,主打本地盘,将来会往分层存储方向发展。 -
服务端做Replication。Client多推会额外消耗计算节点的网络和计算资源,在独立部署或者服务化的场景下对计算集群不友好。
-
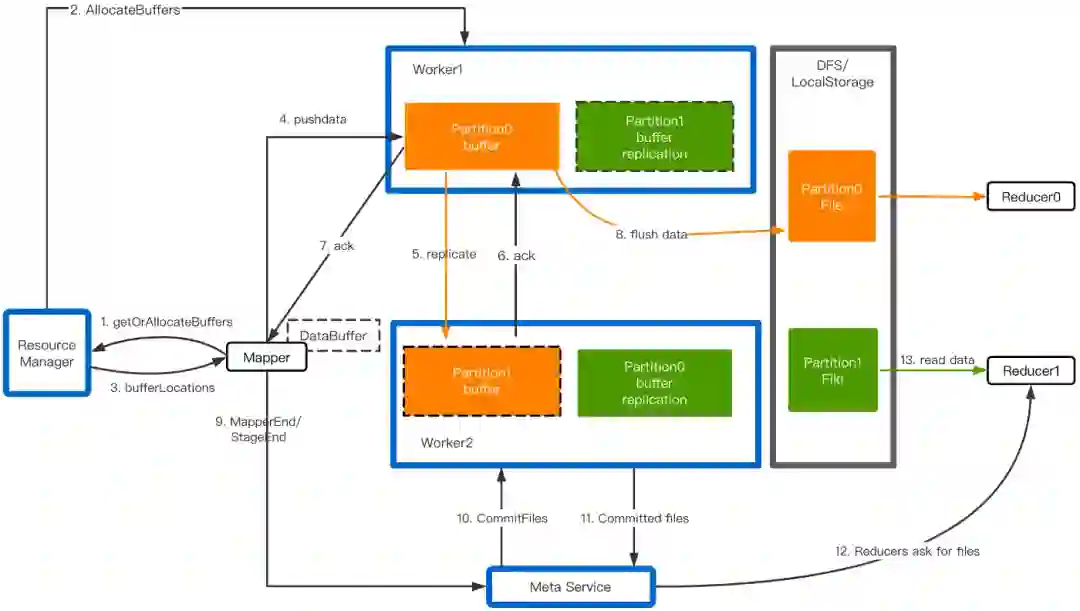
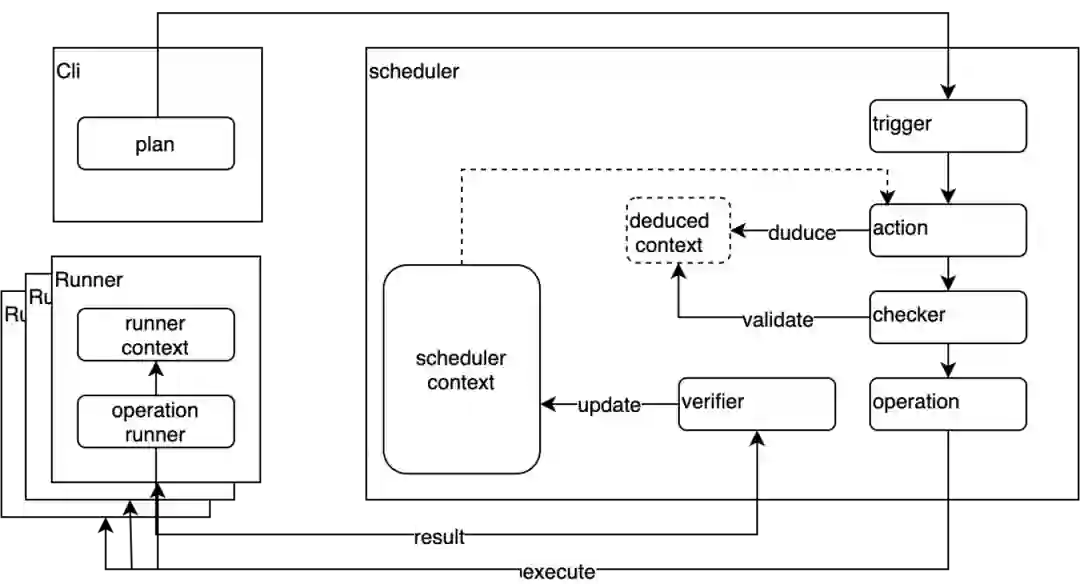
Mapper在首次PushData时请求Master分配Worker资源,Worker记录自己所需要服务的Partition列表。 -
Mapper把Shuffle数据缓存到内存,超过阈值时触发Push。 -
隶属同个Partition的数据被Push到同一个Worker做合并,主Worker内存接收到数据后立即向从Worker发起Replication,数据达成内存两副本后即向Client发送ACK,Flusher后台线程负责刷盘。 -
Mapper Stage运行结束,MetaService向Worker发起CommitFiles命令,把残留在内存的数据全部刷盘并返回文件列表。 -
Reducer从对应的文件列表中读取Shuffle数据。
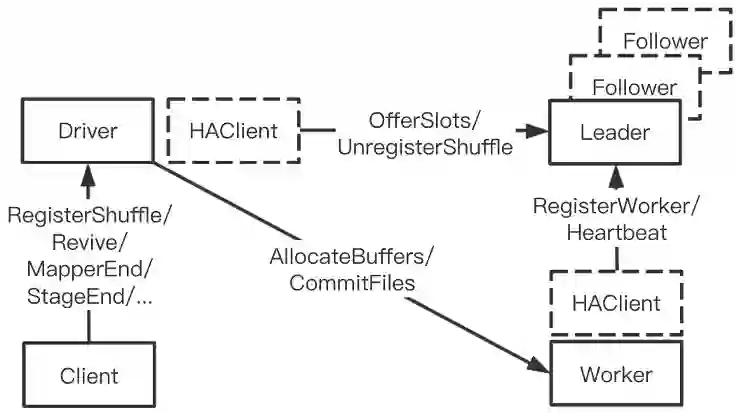
1 状态下沉
2 Adaptive Pusher
3 磁盘容错
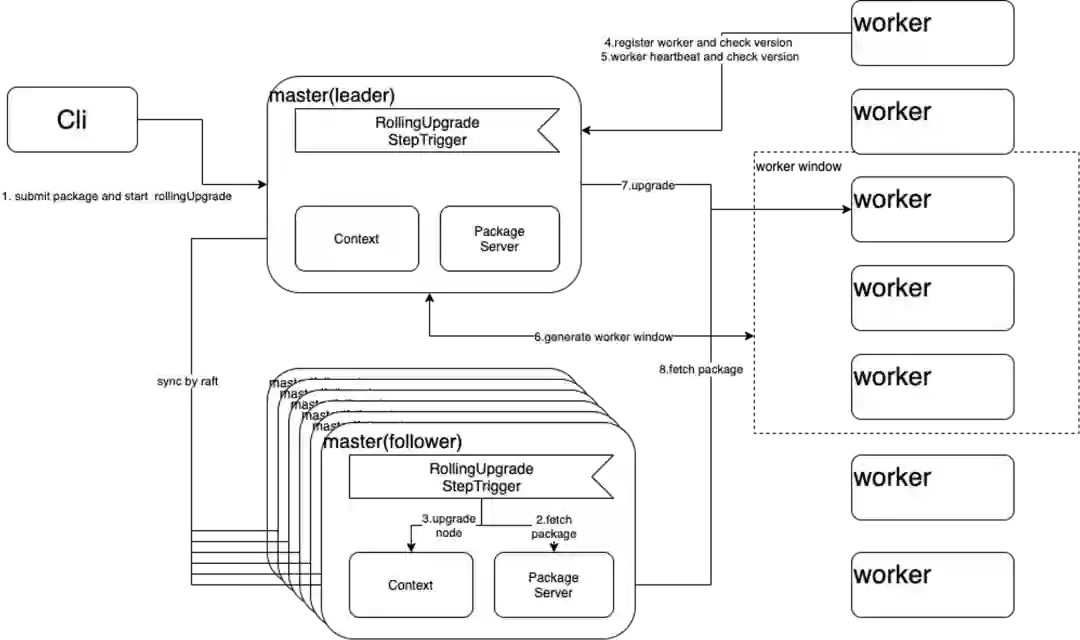
4 滚动升级
5 混乱测试框架
6 多引擎支持
7 测试
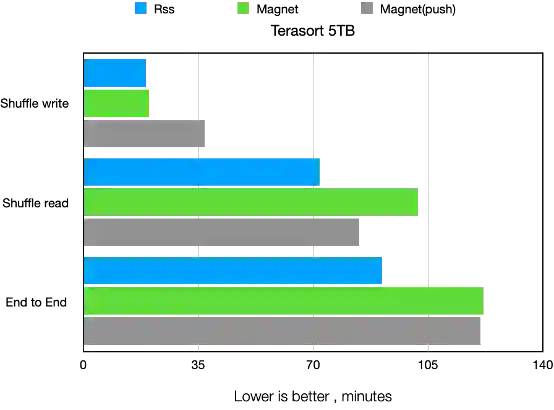
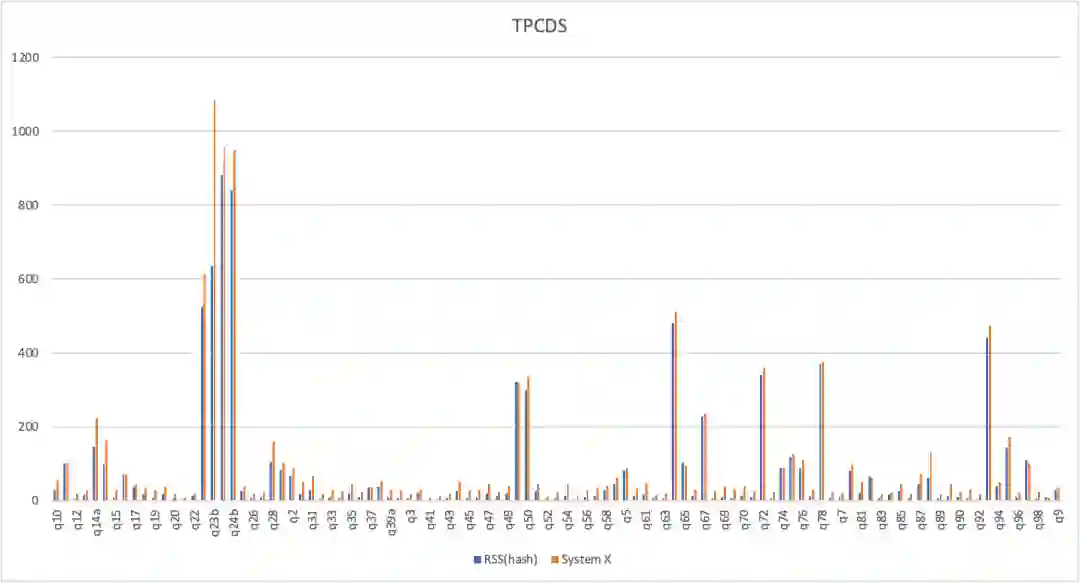
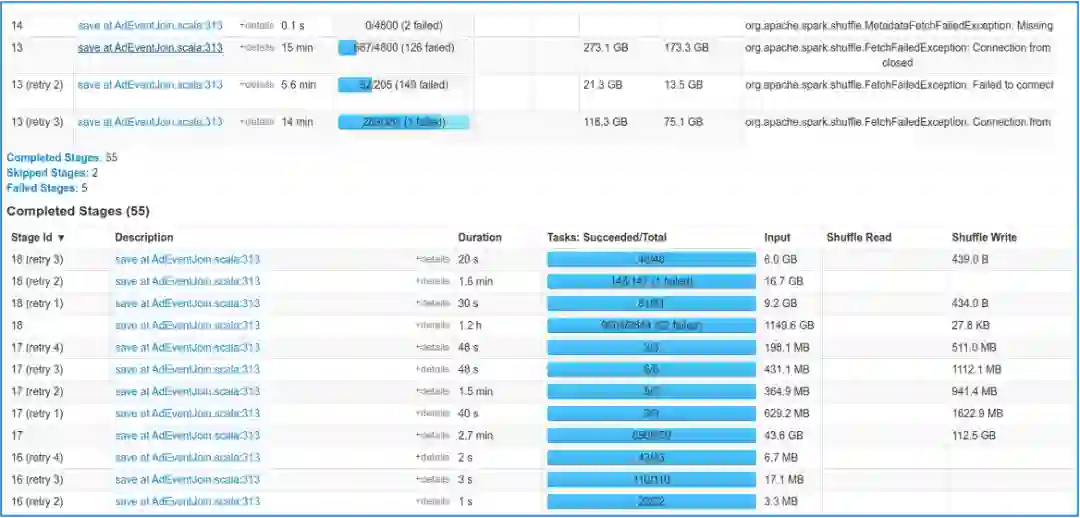
四 阿里云RSS在小米的实践
1 现状及痛点

2 RSS在小米的落地
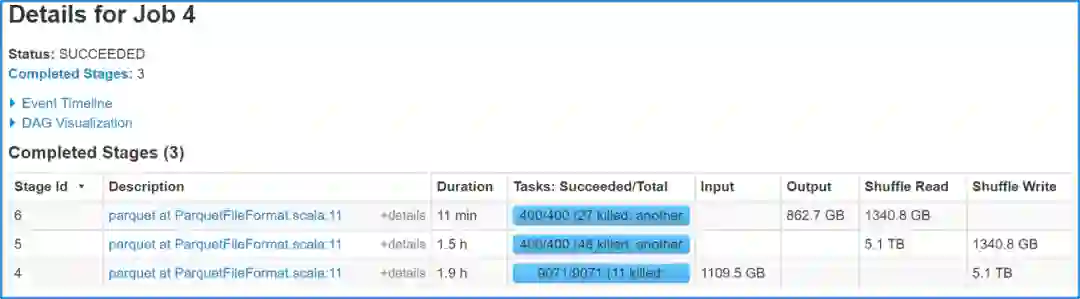
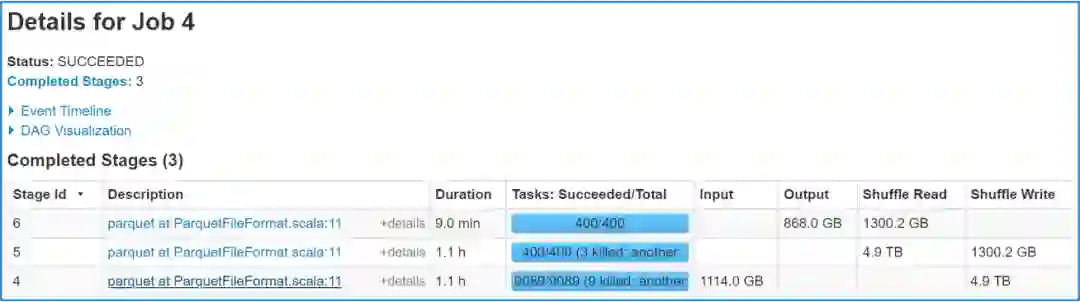
3 效果

五 开源
-
AE -
Spark多版本支持
-
Better 流控 -
Better 监控
-
Better HA -
多引擎支持
六 Reference
Redis数据库入门
登录查看更多
相关内容

专知会员服务
24+阅读 · 2022年3月24日





相关VIP内容
专知会员服务
24+阅读 · 2022年3月24日
相关资讯
相关论文