深度解读 RocketMQ 存储机制

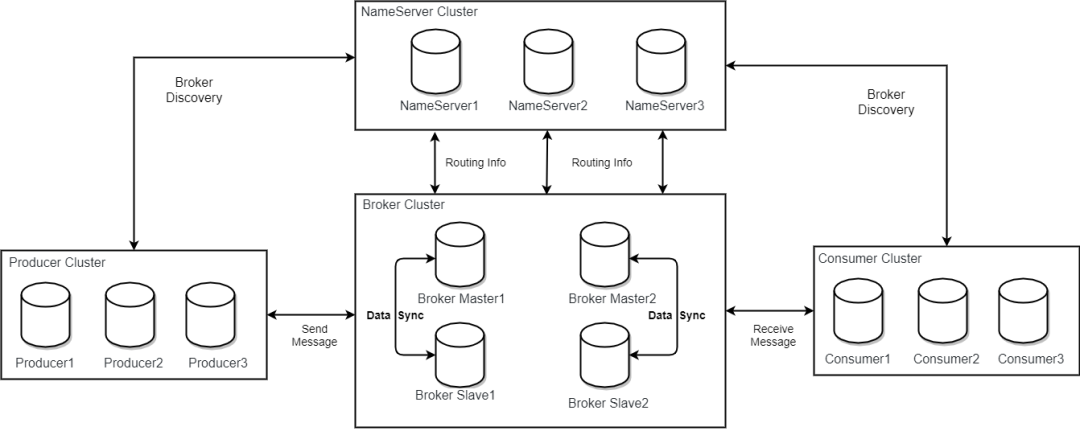
RocketMQ 的架构模型与存储分类
-
服务端 Broker Master1 和 Slave1 构成其中的一个副本组。 -
服务端 Broker 1 和 Broker 2 两个副本组以负载均衡的形式共同为客户端提供读写。
-
元数据管理
-
具体指当前存储节点的主题 Topic,订阅组 Group,消费进度 ConsumerOffset。 -
多个配置文件 Config,以及为了故障恢复的存储 Checkpoint 和 FileLock。 -
用来记录副本主备身份的 Epoch / SN (sequence number) 文件等(5.0-beta 引入,也可以看作 term)
-
消息数据管理,包括消息存储的文件 CommitLog,文件版定时消息的 TimerLog。 -
索引数据管理,包括按队列的顺序索引 ConsumeQueue 和随机索引 IndexFile。
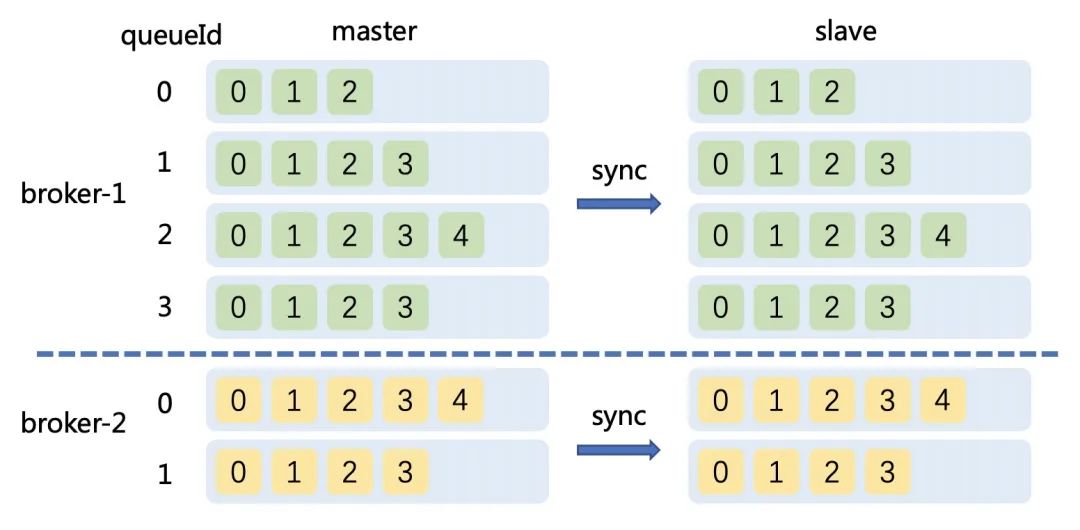
1. 元数据管理与优化
-
批量更新指每次服务端可以接受一批 TopicConfig 的更新,这样 Broker 刷写文件的频率就显著的降低。 -
增量更新指将这个 Map 的持久化换成逻辑替换成 KV 型的数据库或实现元数据的 Append 写,以 Compaction 的形式维护一致性。
消息数据管理
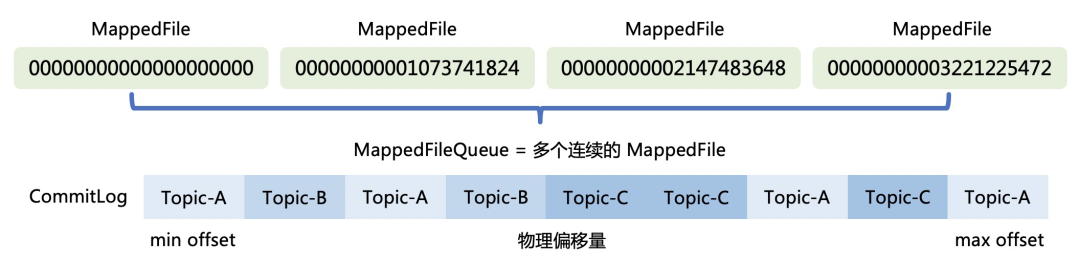
2.1 单条消息的存储格式
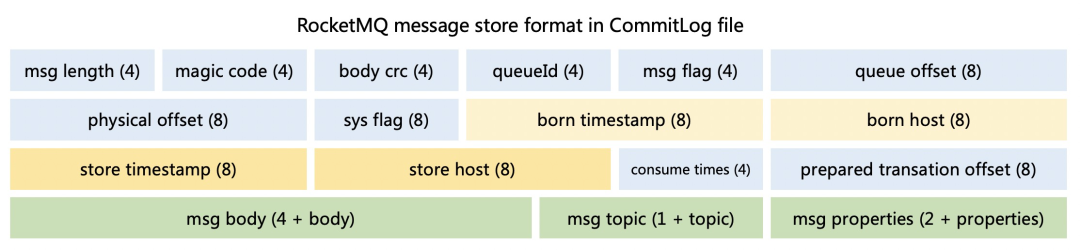
2.2 多条消息的连续写
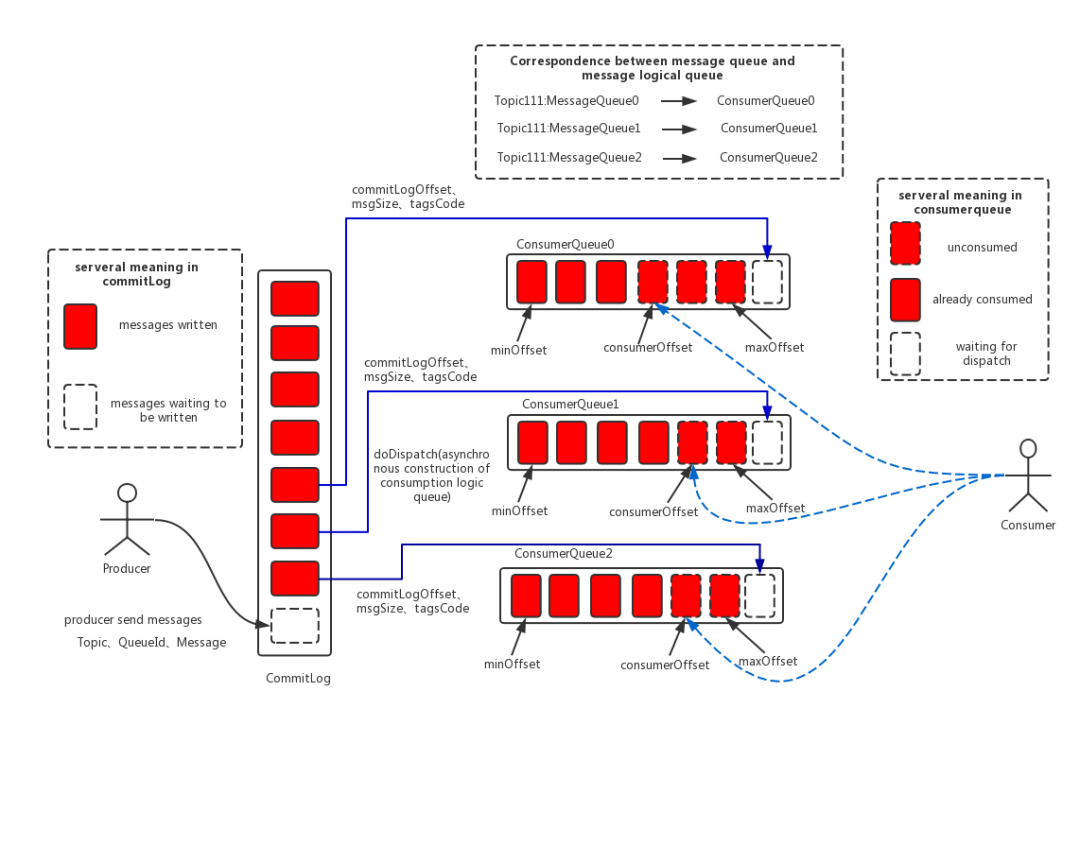
2.2.1 独占锁实现顺序写
-
预计算索引的位置,即 ConsumeQueueOffset,这个值也需要保证严格递增 -
计算在 CommitLog 存储的位置,physicalOffset 物理偏移量,也就是全局文件的位置。 -
记录存储时间戳 storeTimestamp,主要是为了保证消息投递的时间严格保序
2.2.2 成组提交与可见性
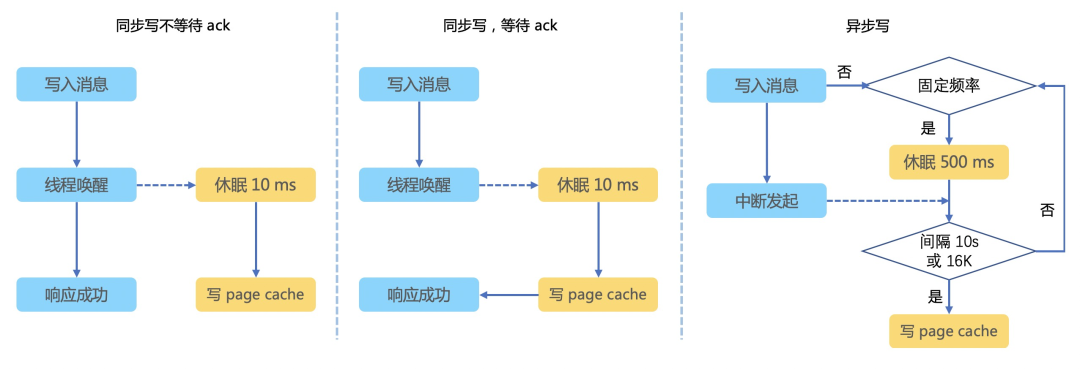
2.3 持久化机制
-
同步持久化,使用 GroupCommitService。 -
异步持久化且未开启 TransientStorePool 缓存,使用 FlushRealTimeService。 -
异步持久化且开启 TransientStorePool 缓存,使用 CommitRealService。
2.3.1 持久化
2.3.2 读写分离
-
像数据库一样主写从读,分摊读压力,牺牲延迟可靠性更高,适用于消息读写比非常高的场景。 -
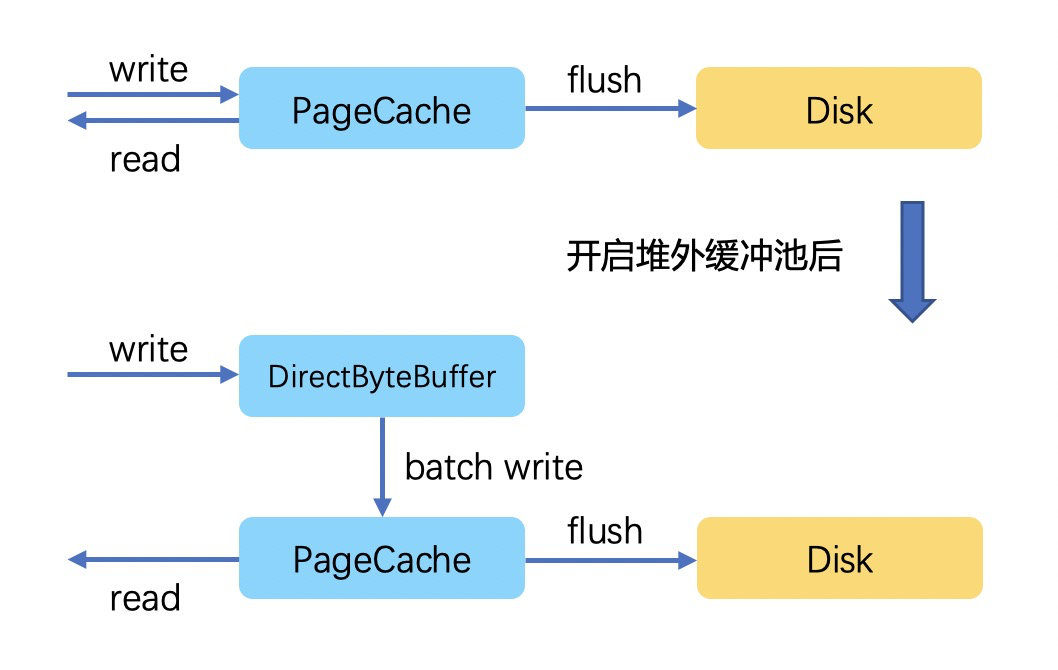
存储写入将消息暂存至 DirectByteBuffer,当数据成功写入后,再归还给缓冲池,将写入 page cache 的动作异步化。
-
好处: 数据写堆外后便很快返回,减少了用户态与内核态的切换开销。 -
弊端: 数据可靠性降为最低级别,进程重启就会丢数据(当然这里一般配合多副本机制进行保障),也会增加一些端到端的延迟。
2.3.3 宕机与故障恢复
2.4 文件的生命周期
2.5 避免存储抖动
2.5.1 快速失败

2.5.2 预分配与文件预热
-
请求分配内存并进行 mlock 系统调用后并不一定会为进程完全锁定这些物理内存,此时的内存分页可能是写时复制的。此时需要向每个内存页中写入一些假的值,有些固态的主控可能会对数据压缩,所以这里不会写入 0。 -
调用 mmap 进行映射后,OS 只是建立虚拟内存地址至物理地址的映射表,而实际并没有加载任何文件至内存中。这里可能会有大量缺页中断。RocketMQ 在做 mmap 内存映射的同时进行 madvise 调用,同时向 OS 表明 WILLNEED 的意愿。使 OS 做一次内存映射后对应的文件数据尽可能多的预加载至内存中,从而达到内存预热的效果。
2.5.3 冷数据读取
-
请求来自于这个副本组的其他节点,进行副本组内的数据复制,也可能是离线转储到其他系统。 -
请求来自于客户端,是消费者来消费几个小时以前的数据,属于正常的业务诉求。
索引数据管理
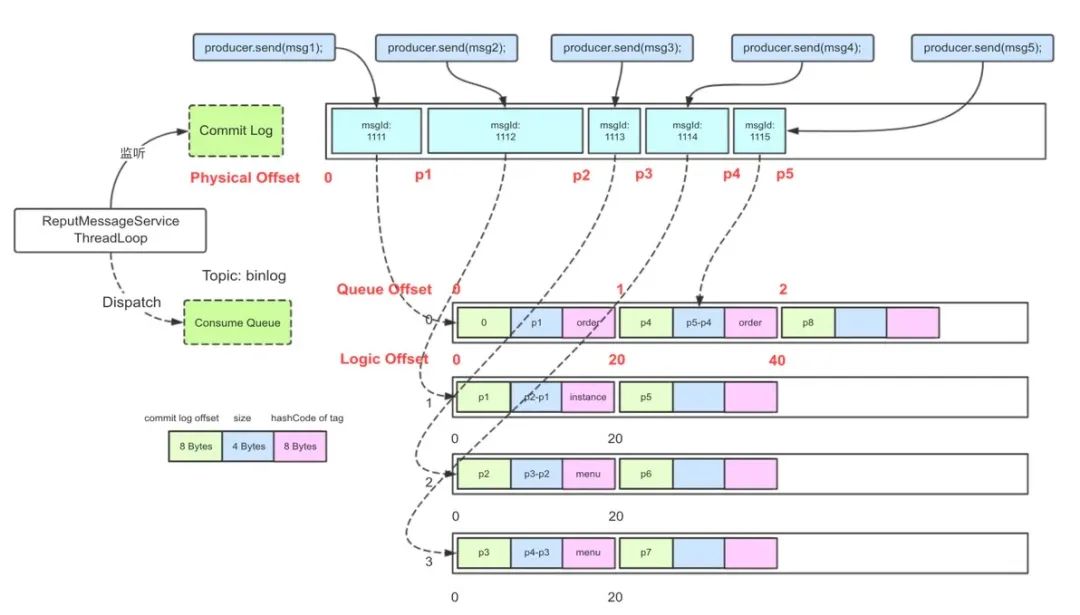
3.1 队列维度的有序索引 ConsumeQueue

-
根据 Tag 的 Hash 值查询 ConsumeQueue 文件(由 physicOffset + size + Tag HashCode 组成) -
根据 ConsumeQueue 拿到 physicOffset + size -
根据 physicOffset 查询 CommitLog 文件(上文的 MappedFileQueue ) 获得消息
3.2 消息维度的随机索引 IndexFile

存储机制的演进方向
4.1 KV 模型与 Queue 模型结合
4.2 消息的压缩与归档存储
4.3 存储层资源共享与争抢
4.3.1 磁盘 IO 的抢占
4.3.2 用户态文件系统
-
多点挂载。常用的 Ext4 等文件系统不支持多点挂载,让存储能够支持多个实例的对同一份数据的共享访问。 -
调整对于 IO 的合并策略,IO优先级,polling 模式,队列深度等。 -
使用文件系统类似 O_DIRECT 的非缓存方式读写数据。
RocketMQ 的未来
参考文献
从概念、部署到优化,Kubernetes Ingress 网关的落地实践
点击阅读原文查看详情。
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年8月29日
Arxiv
0+阅读 · 2022年8月29日
Arxiv
0+阅读 · 2022年8月29日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年8月29日
Arxiv
0+阅读 · 2022年8月29日
Arxiv
0+阅读 · 2022年8月29日