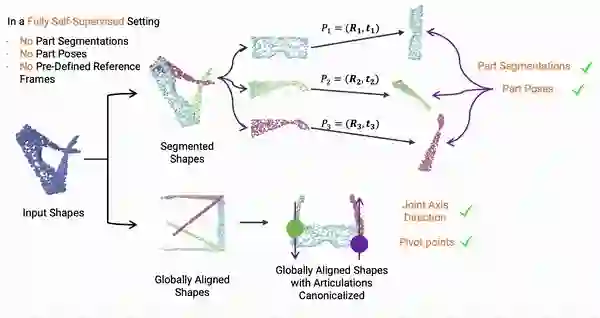
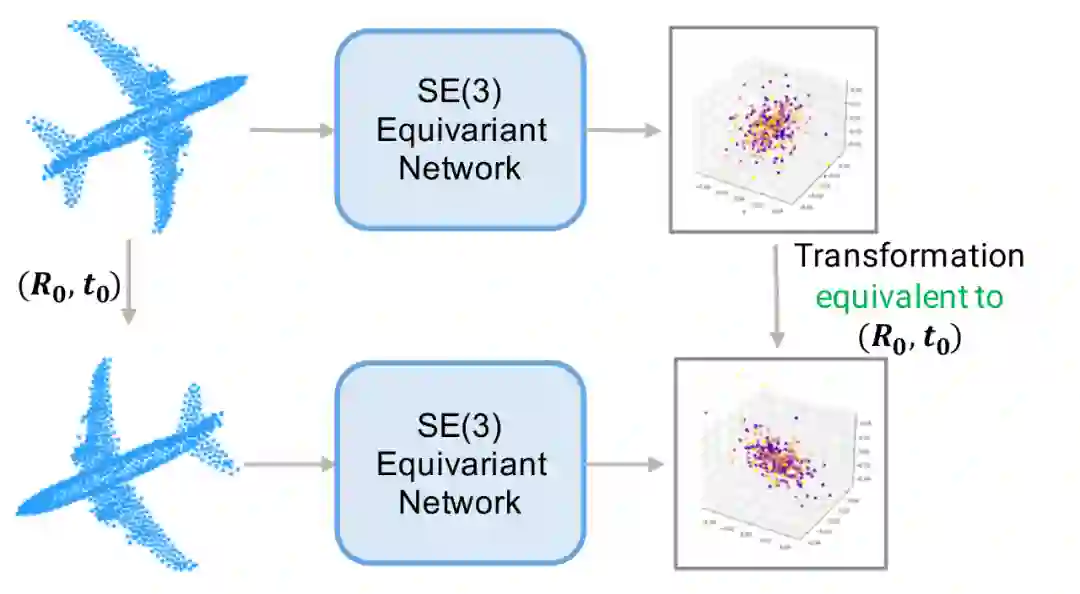
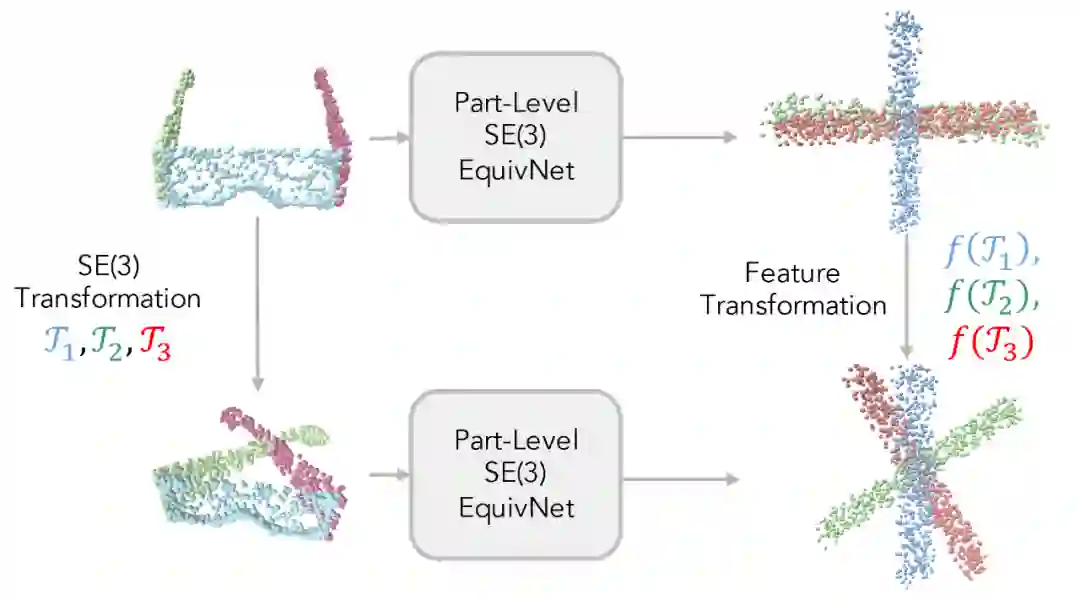
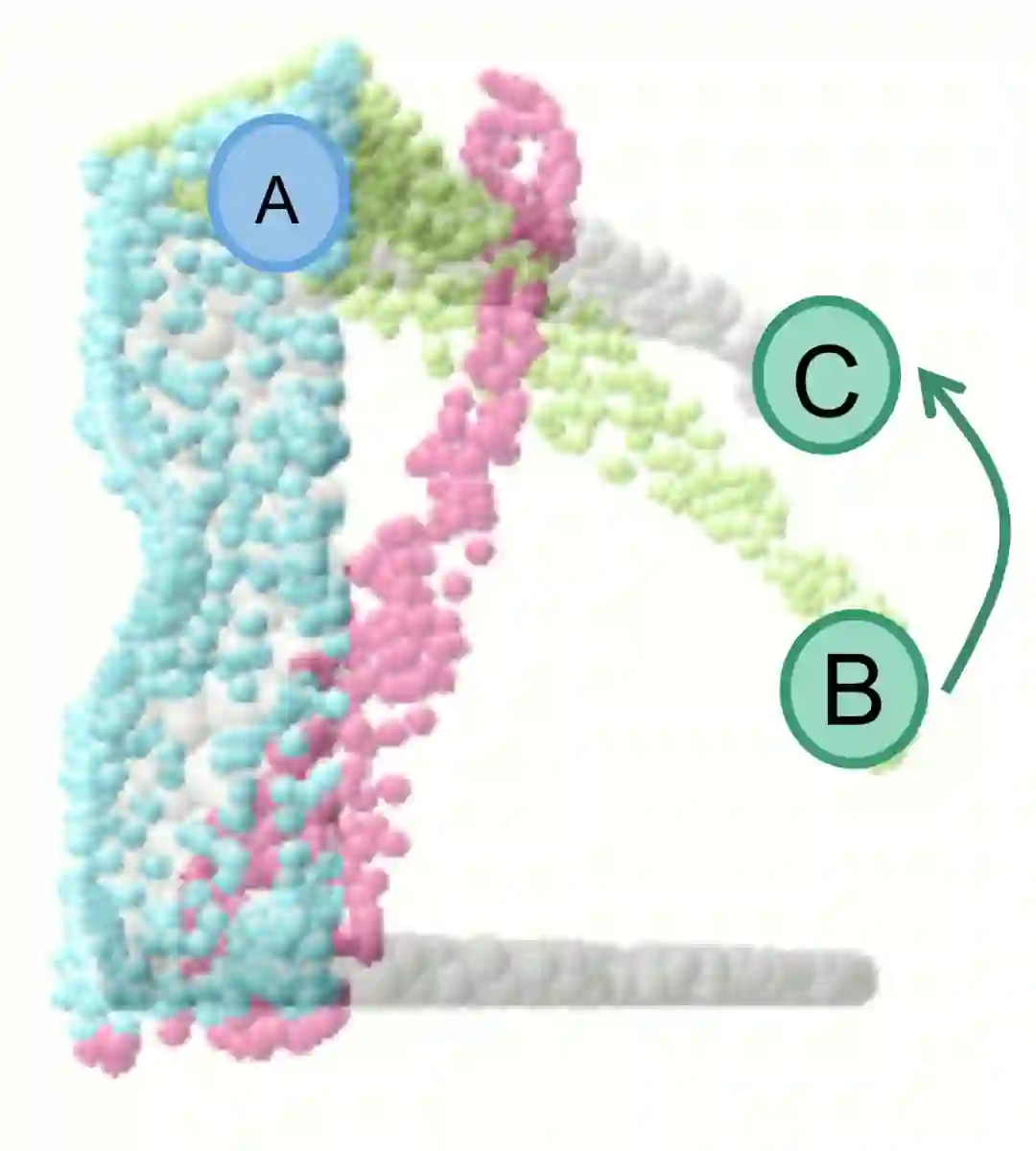
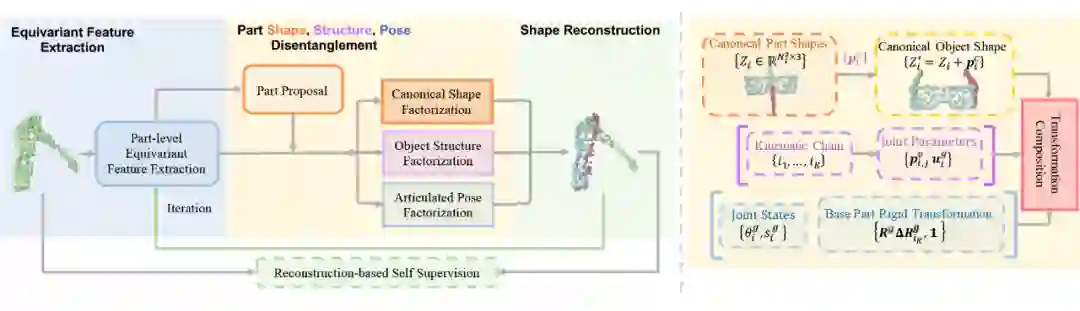
为了实现点级别 SE(3) 等变性,我们将每个点的位姿信息纳入到卷积运算之中。在卷积运算过程中,我们的卷积运算计算邻居节点处在当前节点所定义的局部坐标系下对当前节点特征向量的影响来更新当前节点的特征。如下图所示,当使用点 B 的特征更新点 A 的特征时,这种卷积运算会计算它实际上处在 C 点时的特征,并会用这样的特征来更新点 A 的特征。
[1] Xiaolong Li, He Wang, Li Yi, Leonidas J Guibas, A Lynn Abbott, and Shuran Song. Category-level articulated object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3706–3715, 2020a.[2] Maurice Weiler, Mario Geiger, Max Welling, Wouter Boomsma, and Taco S Cohen. 3d steerable cnns: Learning rotationally equivariant features in volumetric data. Advances in Neural Information Processing Systems, 31, 2018.[3] Nathaniel Thomas, Tess Smidt, Steven Kearnes, Lusann Yang, Li Li, Kai Kohlhoff, and Patrick Riley. Tensor field networks: Rotation-and translation-equivariant neural networks for 3d point clouds. arXiv preprint arXiv:1802.08219, 2018.[4] Fabian Fuchs, Daniel Worrall, Volker Fischer, and Max Welling. Se (3)-transformers: 3d rototranslation equivariant attention networks. Advances in Neural Information Processing Systems, 33:1970–1981, 2020.[5] Yongheng Zhao, Tolga Birdal, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas, and Federico Tombari. Quaternion equivariant capsule networks for 3d point clouds. In European Conference on Computer Vision, pp. 1–19. Springer, 2020.[6] Haiwei Chen, Shichen Liu, Weikai Chen, Hao Li, and Randall Hill. Equivariant point network for 3d point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14514–14523, 2021.[7] Xiaolong Li, Yijia Weng, Li Yi, Leonidas Guibas, A. Lynn Abbott, Shuran Song, and He Wang. Leveraging se(3) equivariance for self-supervised category-level object pose estimation, 2021.[8] Deng, C., Litany, O., Duan, Y., Poulenard, A., Tagliasacchi, A., & Guibas, L. J. (2021). Vector neurons: A general framework for so (3)-equivariant networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 12200-12209).