字节跳动自研万亿级图数据库ByteGraph及其应用与挑战

本文将围绕以下五点展开:
了解图数据库
适用场景介绍举例
数据模型和查询语言
ByteGraph架构与实现
关键问题分析
01
了解图数据库
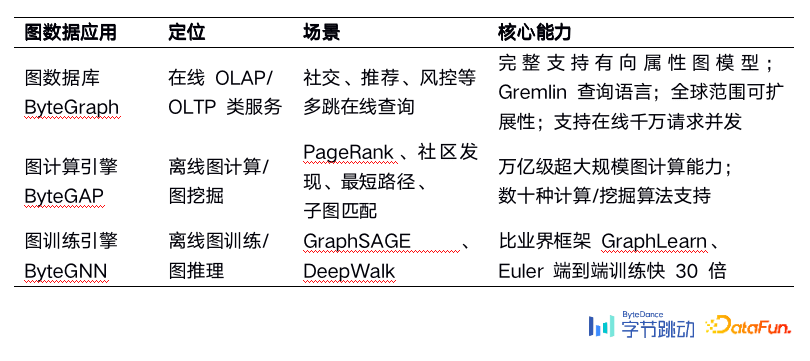
目前,字节内部有如下表三款自研的图数据产品。
1. 对比图数据库与关系数据库
图模型的基本元素包括点、边和属性。举例:张三的好友所在的公司有多少名员工?传统关系型数据库需要多表join,而图作为半结构化数据,在图上进行遍历和属性的过滤会更加高效。
2. 什么是图数据库?
近五年来,图数据库在领域内热度上升趋势非常明显,各个大厂与开源社区都推出了自己的图数据库。用户规模比较大、有一定影响力的查询语言包括Cypher、Apache开源项目的Gremlin等。从集群规模来看,过往有单机数据库,现在大多图数据库都具备分布式能力,这就需要考虑数据的防丢失问题、主副本之间的一致性、多台机器数据上的shard问题。
部分图数据库把图数据库与图计算引擎二者合并在一起,目前字节内部采用的暂时分离的两套系统。
02
1. ByteGraph适用的业务数据模型
ByteGraph初始立项是在2018年,主要目的是对头条的用户行为及好友关系进行存储来替换Mysql;2019年6月承接对抖音用户关系的数据存储任务,接着在字节内部各种微服务重承接了相关业务。
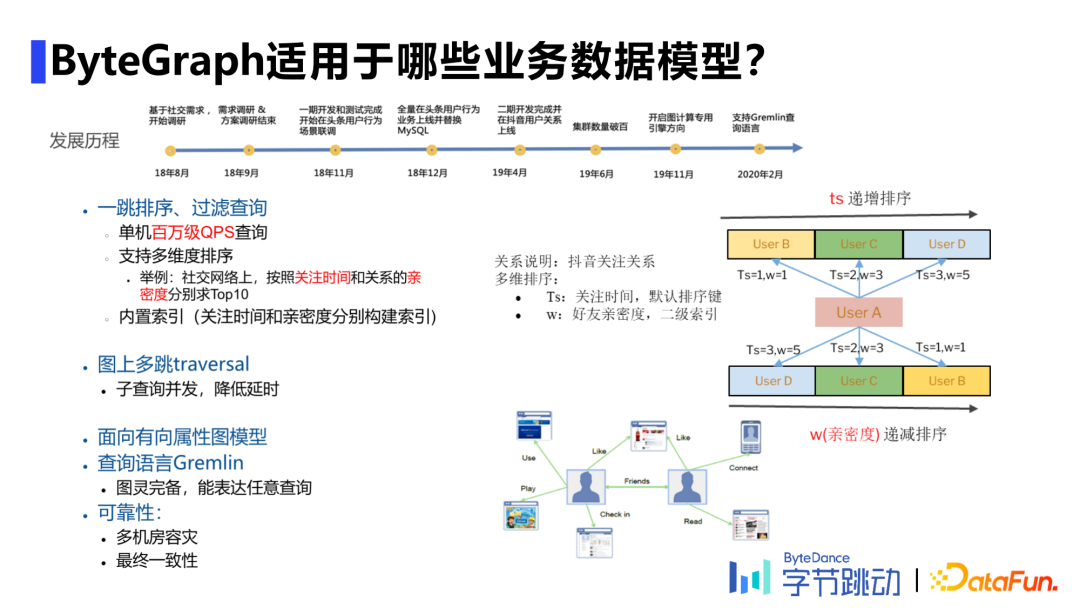
2. 已上线业务场景分类
目前有1.5万台物理机,服务于600+业务集群。
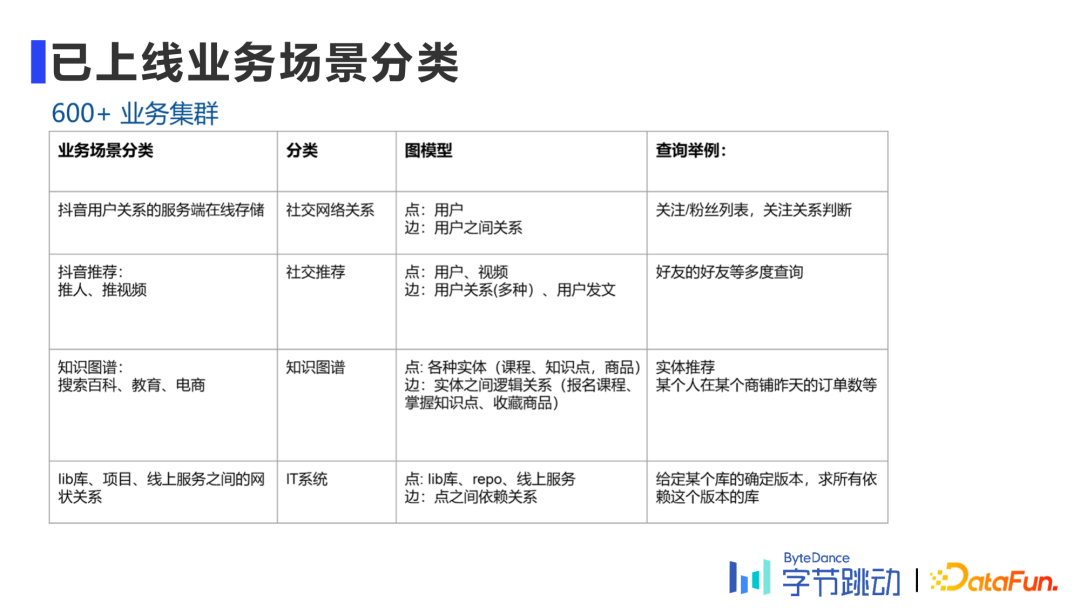
1. 有向属性图建模
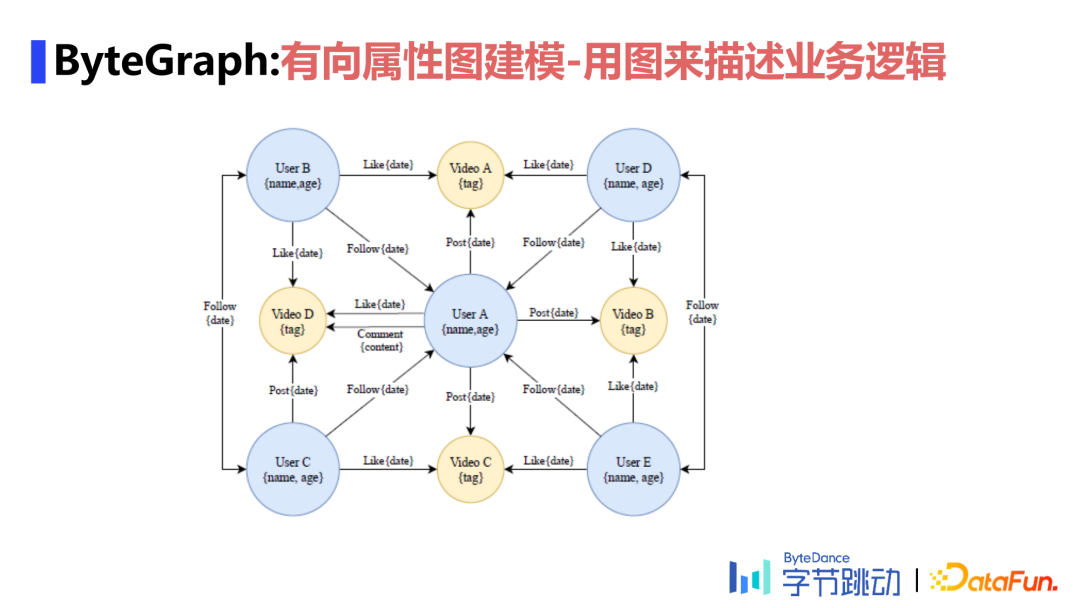
目前来看,图数据库通常有两大类,一种是属性图,另一种是RDF图。属性图在节点和边上有属性表,从某种角度上讲,它仍带有关系数据库的基本特性,类似表结构的形式,实际是采用Key-Value形式来存储的,如用户A关注了用户B,用户C点赞了某个视频等,则会把关注的时间、点赞时间、评论的内容等以不同的有向边存储在属性图中,用图来描述业务逻辑。
2. Gremlin查询语言接口
选用Gremlin语言是考虑到之后方便对图计算、图数据库二者进行融合,本身是图灵完备的图遍历语言,相较于Cypher等类SQL语言,对于善用Python的数据分析师更容易上手。
举例:写一条用户A所有一跳好友中满足粉丝数量大于100的子集。首先定位用户A在图中的点,其次求一跳查询中的所有邻居,判断入度邻居整体数量是否大于100,拉取满足条件的所有用户。

ByteGraph架构与实现
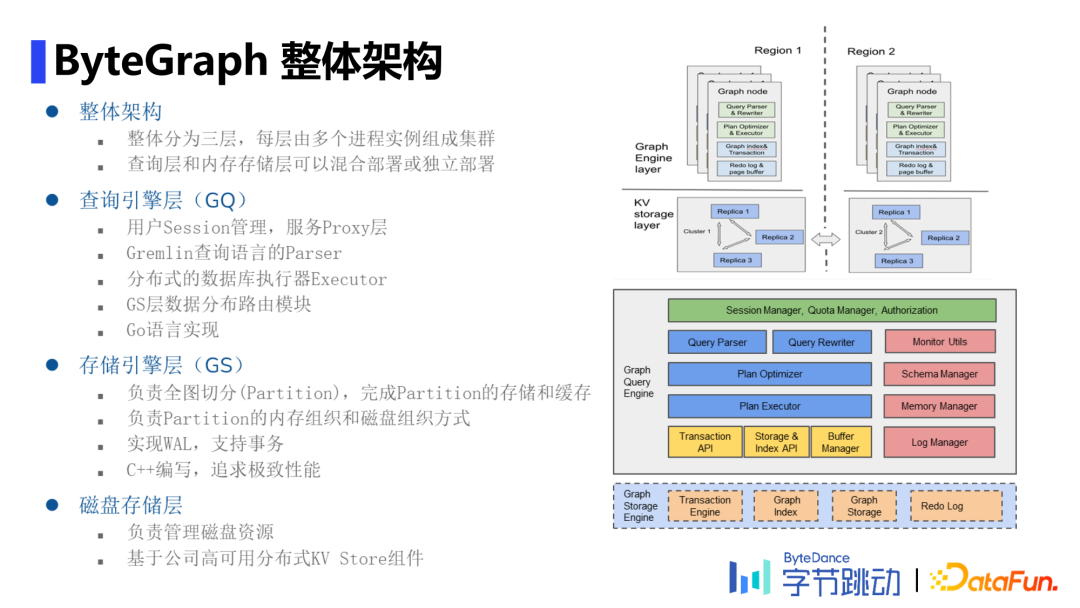
1. ByteGraph整体架构
ByteGraph整体架构分为查询引擎层(Graph Query Engine,下文简称GQ)、存储引擎层(Graph Storage Engine,下文简称GS)和磁盘存储层三层,整体上计算和存储分离,每层由多个进程实例组成集群。
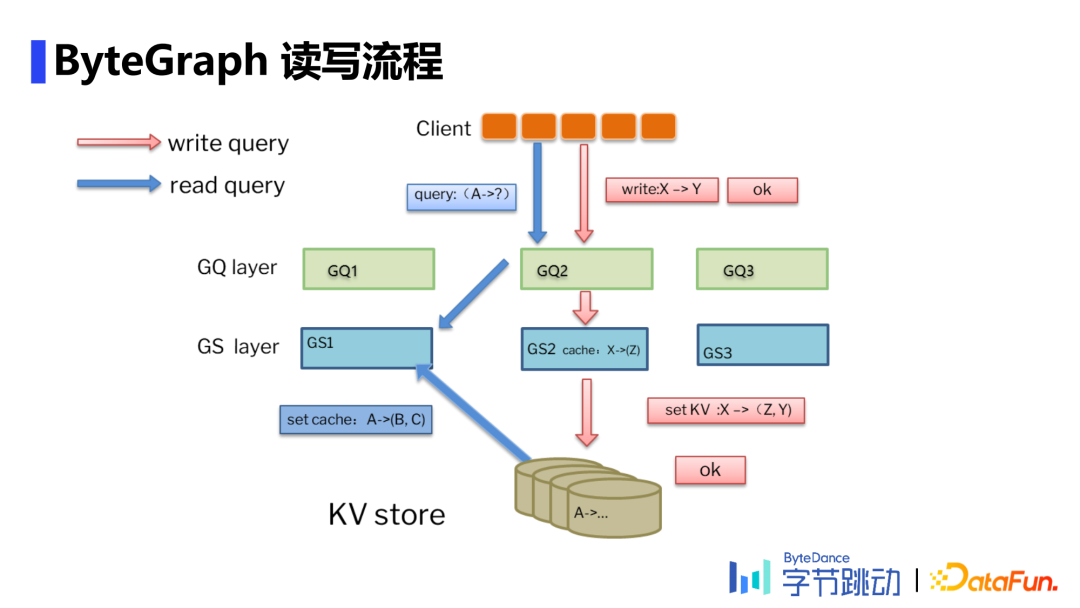
2. ByteGraph读写流程
拿“读流程”举例,请求获取用户A的一跳邻居。首先一个查询进来后,从client端随机挑选一个查询层响应,对应到GQ2上,获取对应的数据存放的位置是哪一台机器,接着把请求给到GS1,检查数据是否在该层以及是否为最新数据,如果不在则去KV store把所需数据拉取至GS1 缓存中。
3. ByteGraph实现:GQ
GQ同MySQL的SQL层一样,负责查询的解析和处理,其中的“处理”可以分为下述三个步骤:
Parser阶段:利用递归下降解析器将查询语言解析为一个查询语法树。
生成查询计划:将Parser阶段得到的查询语法树按照查询优化策略(RBO&CBO)转换为执行计划。
执行查询计划:理解GS数据分Partition的逻辑,找到相应数据并下推部分算子,保证网络开销不会太大,最后合并查询结果,完成查询计划。
RBO主要基于Gremlin开源实现中的自带优化规则、针对字节应用中的算子下推、自定义的算子优化(fusion)三大规则。CBO本质上是对每个点的出入度做统计,把代价用方程量化表示。
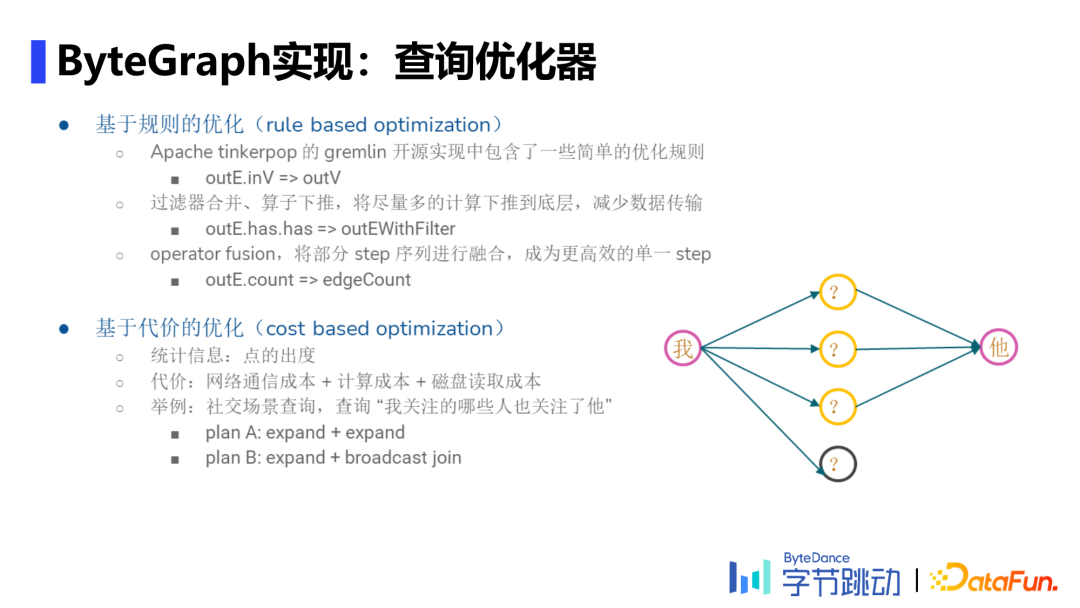
对于不同支持场景使用不同策略,图分区算法的选择与workload强相关,图分区算法能有效减少网络通信次数。
Brute force哈希分区:即根据起点和边的类型进行一致性哈希分区,可以大部分查询场景需求,尤其是一度查询场景。
知识图谱场景:点、边类型极多,但每种类型边数量相对较少,此时根据边类型进行哈希分区,将同种边类型数据分布在一个分区内。
社交场景:更容易出现大V,利用facebook于2016年提出的social hash算法,通过离线计算尽量将有关联的数据放置在同一分片内,降低延迟。
4. ByteGraph实现:GS
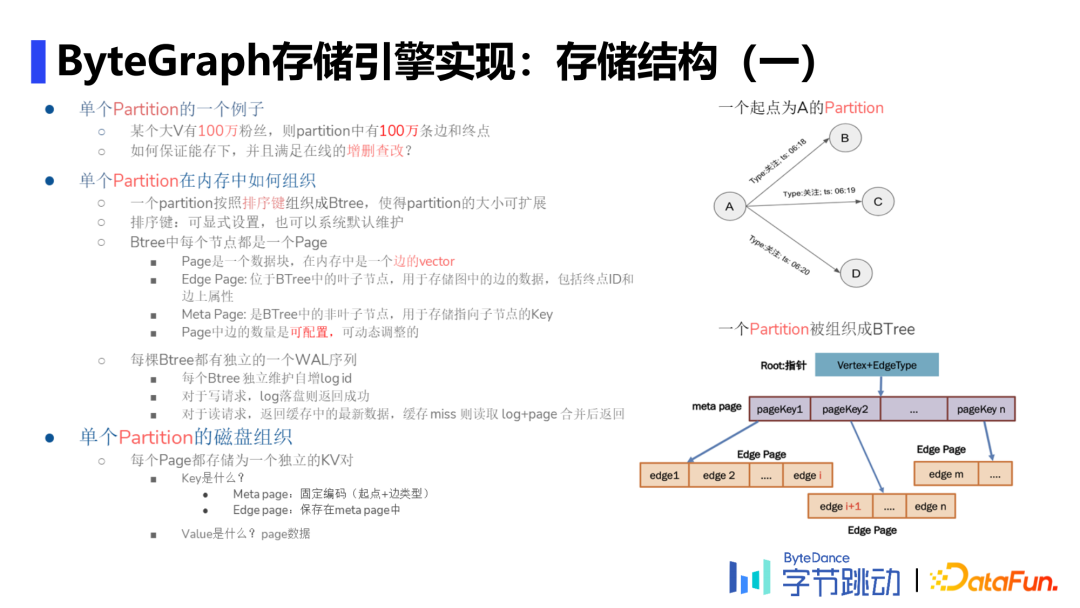
存储结构
单个Partition定义为一个起点+一种特定的边类型扇出的一跳邻居。在GS中,将一个Partition按照排序键(可显式设置或系统默认维护)组织成Btree。每棵Btree都有独立的WAL序列,独立维护自增logid。这种设计有利于支持GNN场景,做分布式采样。
Edge Page、Meta Page分别是位于Btree中的叶子结点、非叶子结点(充当index作用),分别用于存储图中的边数据和指向子节点的Key。Meta page长度是固定的,但是一个meta page会放多少edge page是可配的,通常配置为2000一片。如上图,Partition在磁盘中将每个page都存储为一个独立的键值对(下文简称KV対)。meta page的key是起点+边类型,edge page的key存在meta page中实现对特定edge page的查找。
单机内存引擎整体采用hash map的结构,partition和page按需加载到内存中,根据LRU策略(Least Recent Used),swap到磁盘;某个page被修改后,WAL同步写到磁盘,page会插入到dirty链表中,考虑当前机器状态,异步写回。
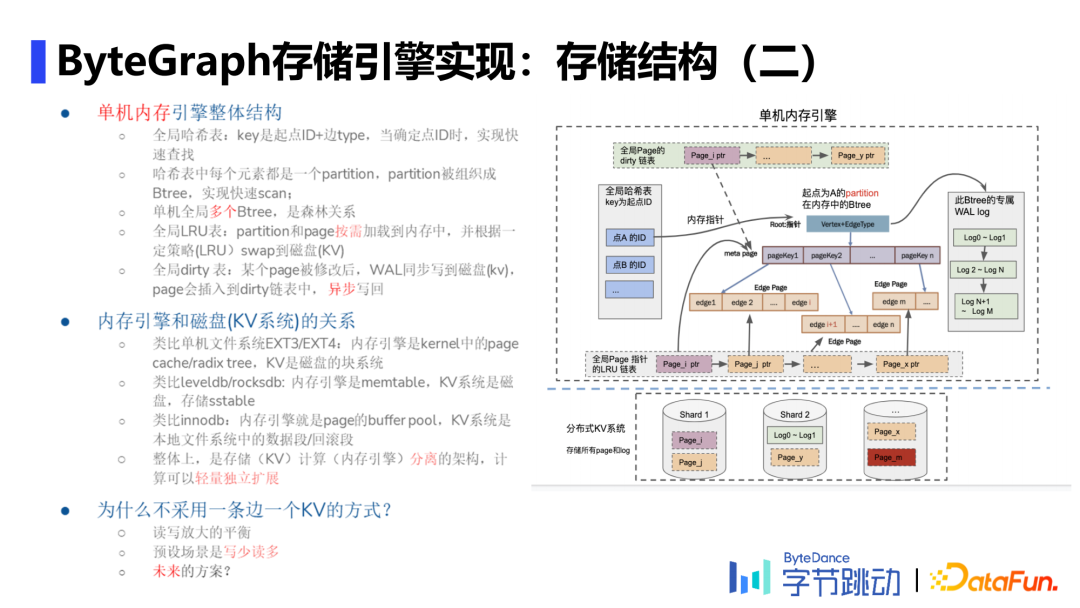
日志管理:单个起点+边类型组成一棵Btree,每个结点是一个KV对。
每棵Btree单一写者,防止并发写入导致不完整;每棵树都有独立的WAL日志流,且写入请求处理流程中只写入WAL,并修改内存中数据,compaction时再将数据落盘,解决由于每个KV对可能由多条边组成而导致的写放大。即使内存数据丢失,仍可通过更新后的logid在磁盘上进行WAL的查询并写入。
缓存实现:根据不同场景及当下cpu的开销有不同策略。
图原生缓存:相对于Memcached等直接缓存二进制数据而言,能更好的理解图的语义,并支持一度查询中的部分计算下推功能。
高性能LRU Cache:支持缓存逐出,且逐出的频率和触发阈值可调;采用numa aware和cpu cacheline aware设计,提高性能;支持Intel AEP等新硬件。
Write-through cache:支持多种与底层存储同步数据的模式,可以每次写入或定时落盘;支持定期与底层存储校验数据,防止数据过旧;支持负缓存等常见优化策略。
缓存与存储分离:当数据规模不变、请求流量增大的情况下,缓存与存储分离的模式可以快速扩容缓存以提高服务能力。
1. 索引
局部索引:给定一个起点和边类型,对边上的属性构建索引
特点:边上元素皆可做索引项,能够加速查询,提高属性过滤和排序性能;但会额外维护一份索引数据,与对应的原数据使用同一条日志流,保证一致性。
全局索引:目前只支持点的属性全局索引,即指定一个属性值查询出对应的点。
数据存储在不同机器上,索引数据的一致性使用分布式事务解决。
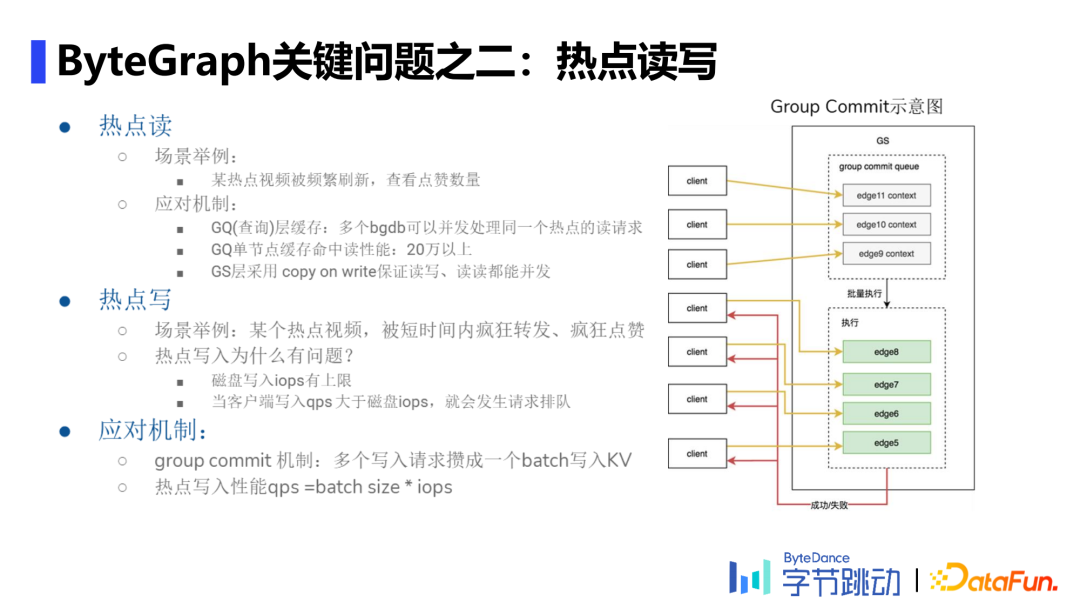
2. 热点读写
热点读
场景举例:某热点视频被频繁刷新,查看其点赞数量。
应用机制:GQ层采用多个bgdb并发处理同一热点的读请求,单节点缓存命中读性能可达20万以上;GS层采用copy on write(即先拷贝,再写入并替换)保证读写、读读均可并发。
热点写
场景举例:某热点视频短时间内被疯狂转发、点赞。
问题溯源:单机cpu使用率被拉高,磁盘写入iops有上限,当客户端写入qps>磁盘iops时,就会发生请求排队。
应对机制:采用group commit机制,即将多个写入请求组合至一个batch写入KV,再批量返回,降低磁盘层iops的上限。
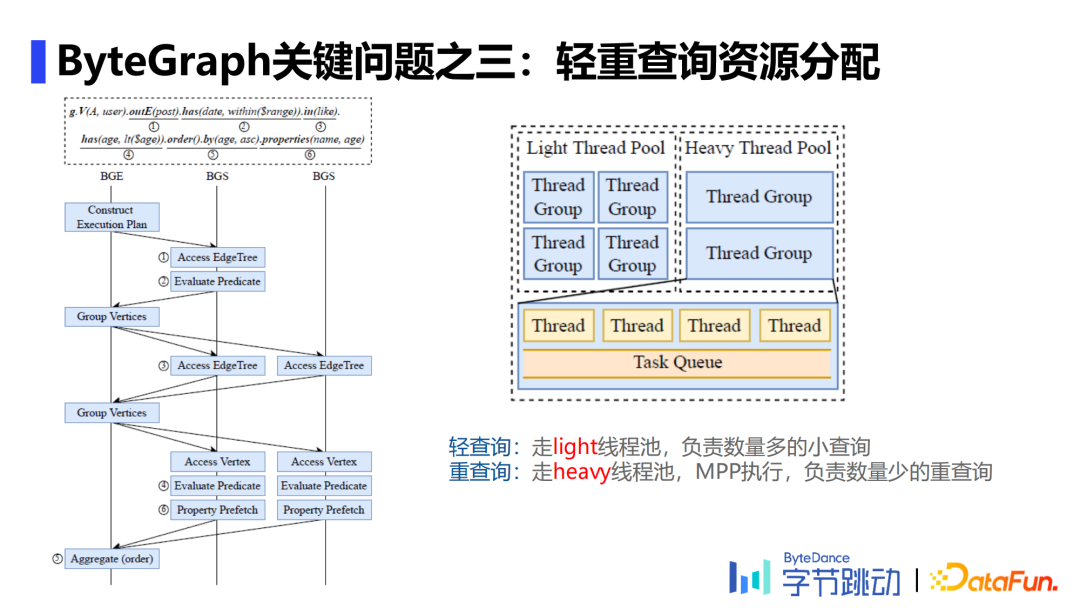
3. 轻重查询资源分配
将轻重查询的资源池分离,轻查询走light线程池,负责数量多的小查询;重查询则走heavy线程池,负责数量少的重查询。当heavy线程池空闲时,轻查询也可走。
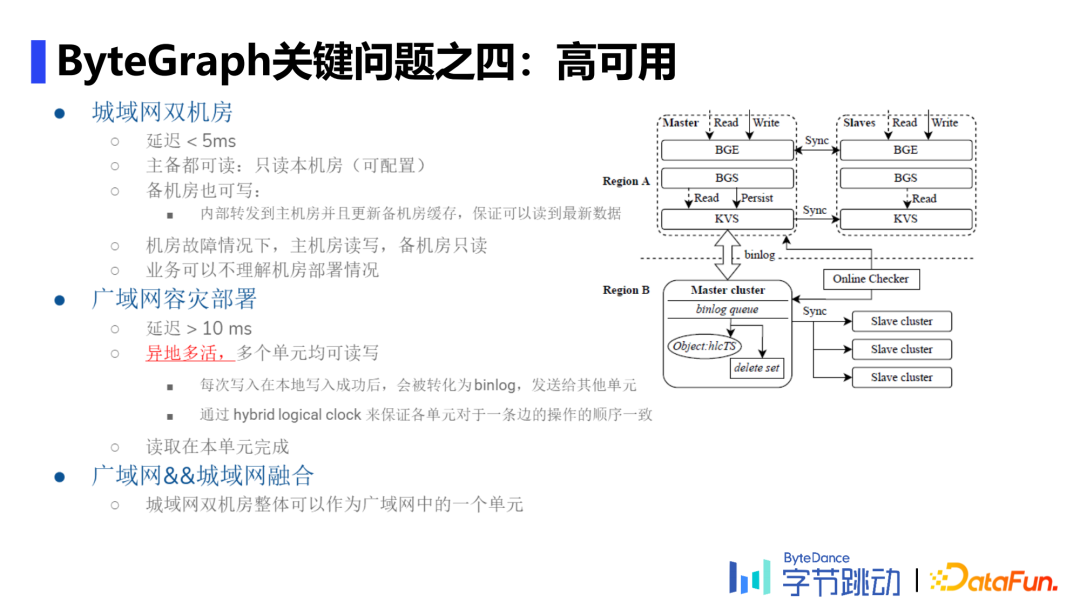
4. 高可用
城域网双机房,如国内的两个机房,延迟较低。follow一写多读策略,备机房把写流量转入主机房,只有主机房会把WAL更新到KV存储上。
广域网容灾部署,如新加坡和美国的两台机器,延迟较高。follow了mysql的思想,每次写入在本地写入成功后,会被转化为binlog,再发送给其他单元;并通过hybrid logical clock保证各单元对于一条边的操作顺序一致性。
5. 离线在线数据流融合
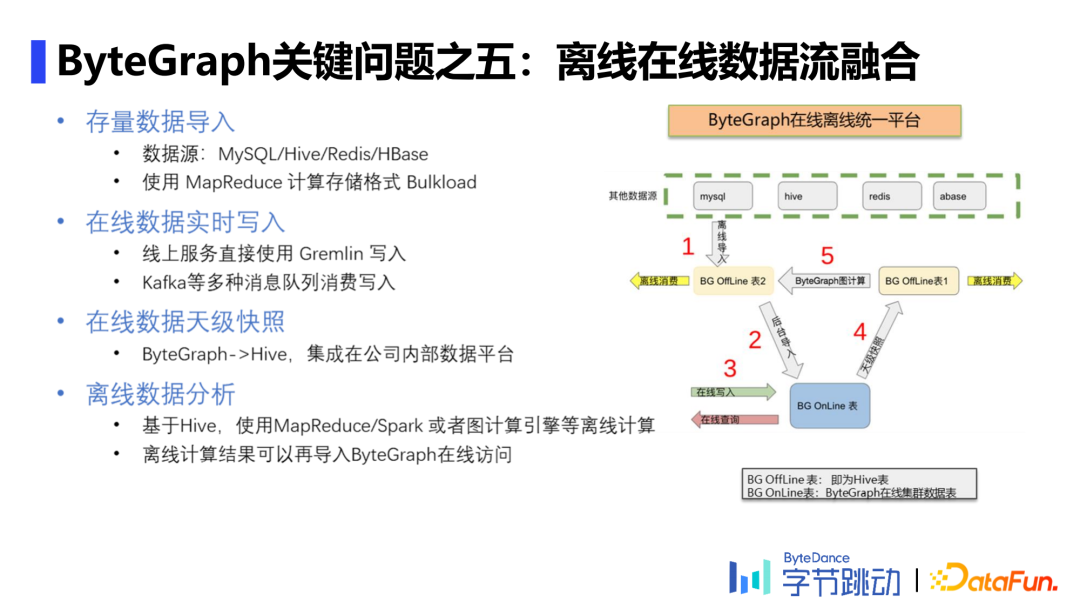
导入存量数据、写入在线数据,将二者集成在公司内部数据平台进行离线数据分析,具体流程如图。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“图数据库” 就可以获取《图数据专知资料合集》专知下载链接



