技术动态 | 北大邹磊:图数据库中的子图匹配算法
转载公众号 | DataFunTalk

分享嘉宾:邹磊 北京大学 教授
编辑整理:xiaomei
出品平台:DataFunTalk
导读:本次讲座从图数据库中的核心查询算子——子图匹配入题,介绍了图数据库的基本概念、子图匹配的算法,以及在图数据库环境下的子图匹配查询优化等内容。具体包括下面三个方面:
什么是图数据库
子图匹配查询及其优化方法
我们的工作
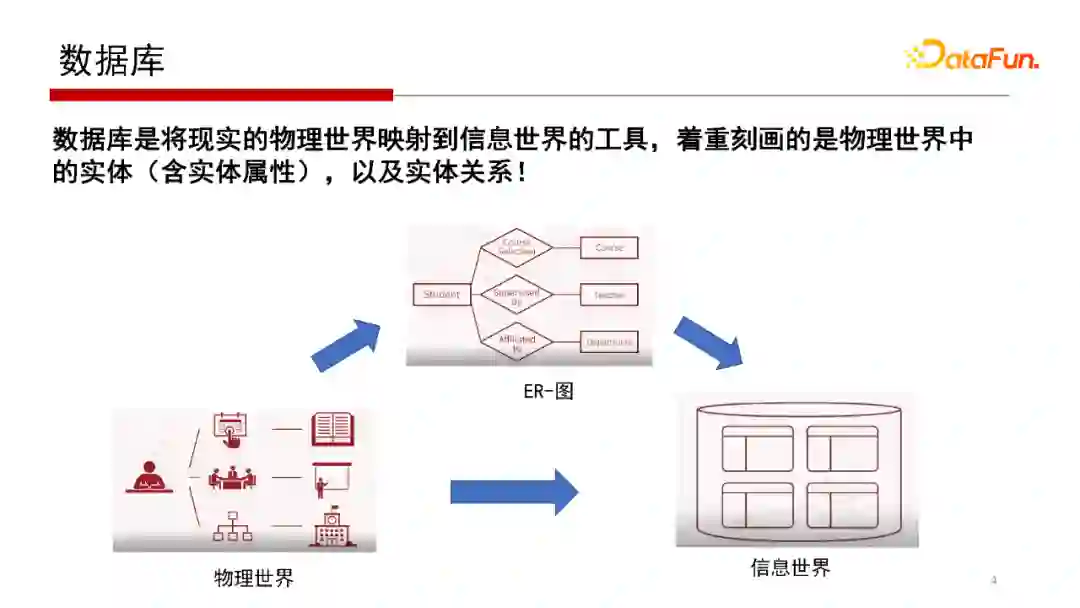
首先,先回顾一下什么是数据库。
1. 数据库
数据库研究的核心就是将物理世界映射到信息世界,在数据库学习课程中会学到一个概念模型E-R图。E-R图表示实体与实体之间的关系,也会将实体的属性包含在内。
2. 回顾-关系型数据库(RDBMS)
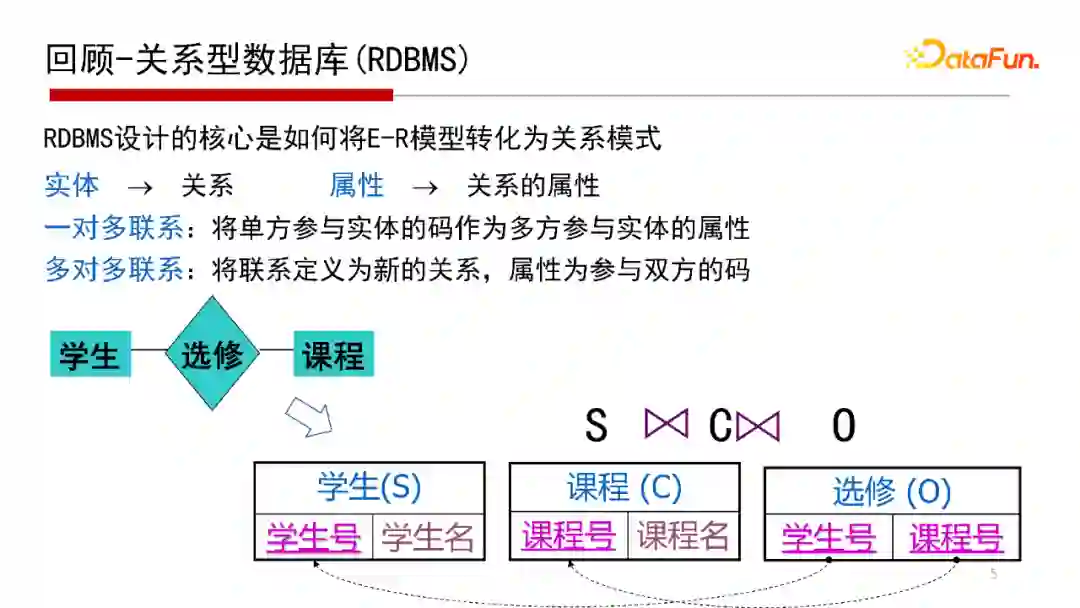
我们再回顾一下关系型数据库是怎么实现E-R关系映射的。E-R图是一个概念模型,是在对信息世界、物理世界建模的时候需要一个概念模型(Conceptual Model)。那么,如何将一个概念模型进行一个物理实现呢?如果底层用的是关系数据库,需要将E-R图结构映射到一个二维的关系表中,如“学生选修课程”的E-R图,映射到学生表、课程表和选修表这样的二维关系表中,这是关系数据库设计的基本思路。
3. 图数据库-Game Changer
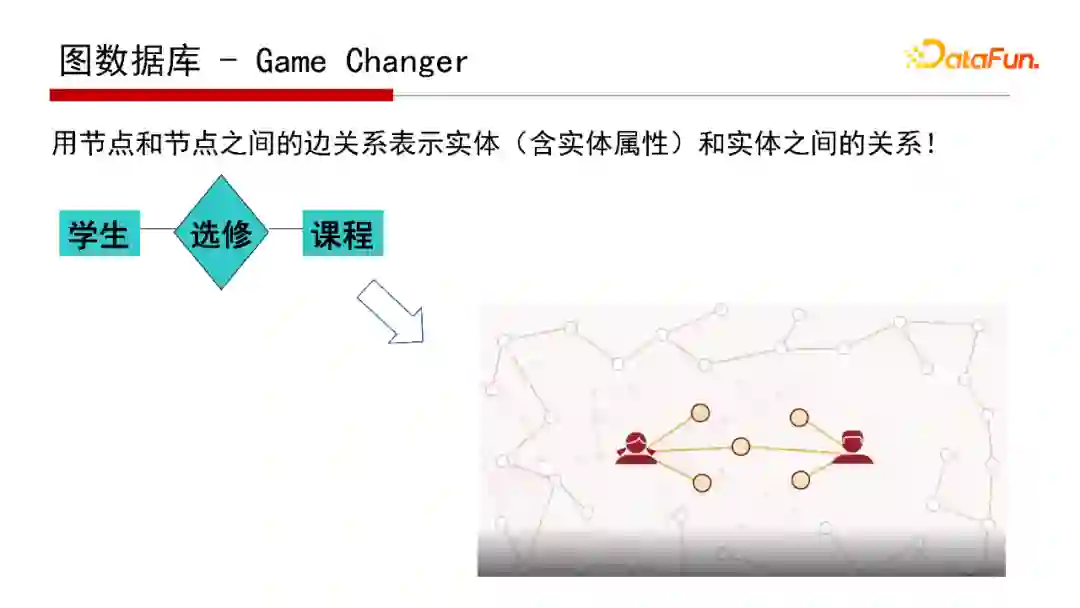
如果采用图数据库作为底层的物理实习,就是把E-R图表示的概念模型映射成图数据库中的节点和边,因为E-R图和图数据库均采用“图”的形式进行表达,因此这样的映射更加直接。那么,E-R图与图数据库的模型有什么区别呢?
首先,两类模型定位不一样。E-R图是概念模型,更像类(class)图,定义的是类之间的逻辑关系,不是数据的实例(Instance)之间的关联;而图数据库的模型是物理实现的数据模型,图数据库中的每个点和边表示实例(也称为实体)的属性与实例之间的关联。
其次,两类模型作用不同。作为概念模型,E-R图用于帮助用户和数据库开发者对于应用需求和所涉及到的数据的含义进行正确理解的工具;而图数据库中的图模型是数据库系统的物理实现模型。
关系数据库需要完成从E-R图到关系表结构,以及关系表之间主外键的映射,图数据库则需要把E-R图(Conceptual Model)映射成用点和边表示实体与实体之间关系的数据模型。
4. 关系数据库 VS 图数据库
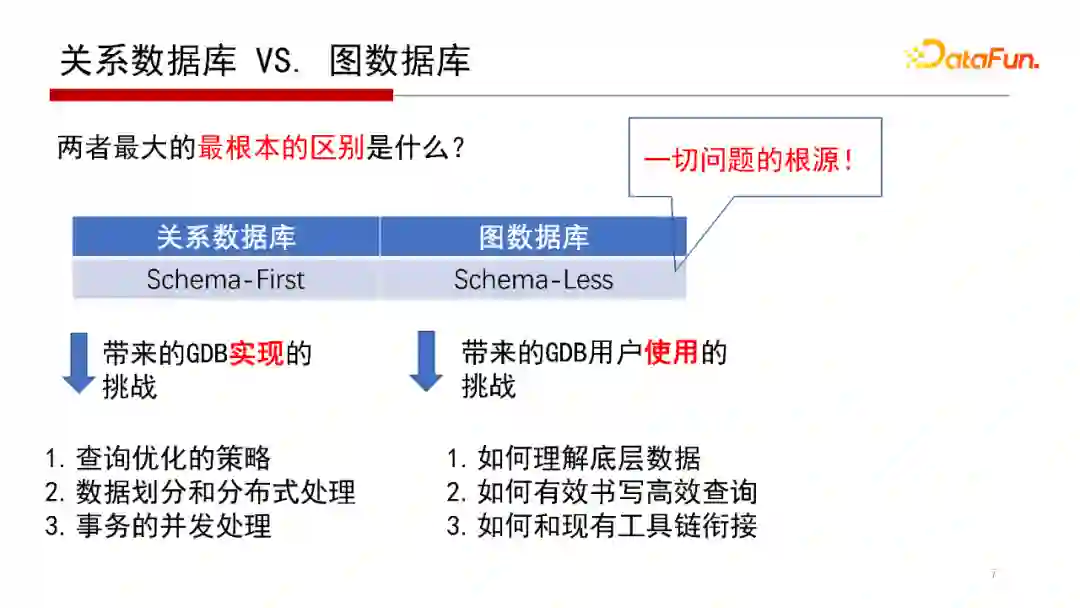
关系数据库与图数据库两者之间有什么区别呢?
首先,我想强调的是两者不是替代关系,至少就目前的技术和研究的发展状态而言;但是两者确实有很多区别,因此造成了在使用场景和内核系统设计中的巨大区别。
这里认为最核心的区别是,关系数据库是Schema-First(模式优先),图数据库是Schema-Less(少模式)。使用关系数据库第一步是先建表结构以及定义表之间主外键关系,这个表结构和表之间主外键关系称为Schema。关系数据库特点是Schema-First,意思是先有表结构才有数据;图数据库有时候称为Schema-Less,甚至有人认为是Non-Schema,是Schema-Less的数据,意思是导入的数据并不是完全与预先设计的Schema完全符合。
例如,假设描述人物信息时,有些人有10个属性,另外一些人只有5个属性,如果在关系数据库中只能取两者属性的合集才能定义表结构;在图数据库当中每个人按需(on-demand)分配属性值就可以,以及边表示的关系也可以是不一样。
关系数据库是Schema-First,也就是首先要有表结构,才能灌入数据;而图数据库跟NoSQL有点儿相似,只要有数据来,哪怕数据并不符合前置定义的Schema,数据仍然可以灌入。
两者的区别带来了在实现和使用上的两个大的区别:
在实现方面,即DBMS(数据库管理系统)内核实现层面。传统关系数据库RDBMS的很多查询优化策略(即查询引擎的执行策略)、数据划分和分布式的处理,以及事务的并发处理都是定义在表结构上的,因此关系数据库的很多技术是依赖于Schema的;而在图数据库中,因为没有像关系数据库一样的Schema,相关的技术都需要重新考虑。这是从实现角度带来的数据库系统DBMS本身带来的技术挑战。
在使用方面,即用户如何使用DBMS系统层面。对于使用者来说,使用关系数据库到使用图数据库最重要的是概念和思维方式的转变,关系数据库是用表结构理解数据,图数据库则是以图的思路来理解数据和数据质量管理。另外,两者查询语句也不一样,和现有工具链也存在衔接的问题。因为两者定位不同,所以不能说图数据库和关系数据库是一个替代关系,但从工具链角度、生态来说图数据库是一个新的变化。
5. 图数据库
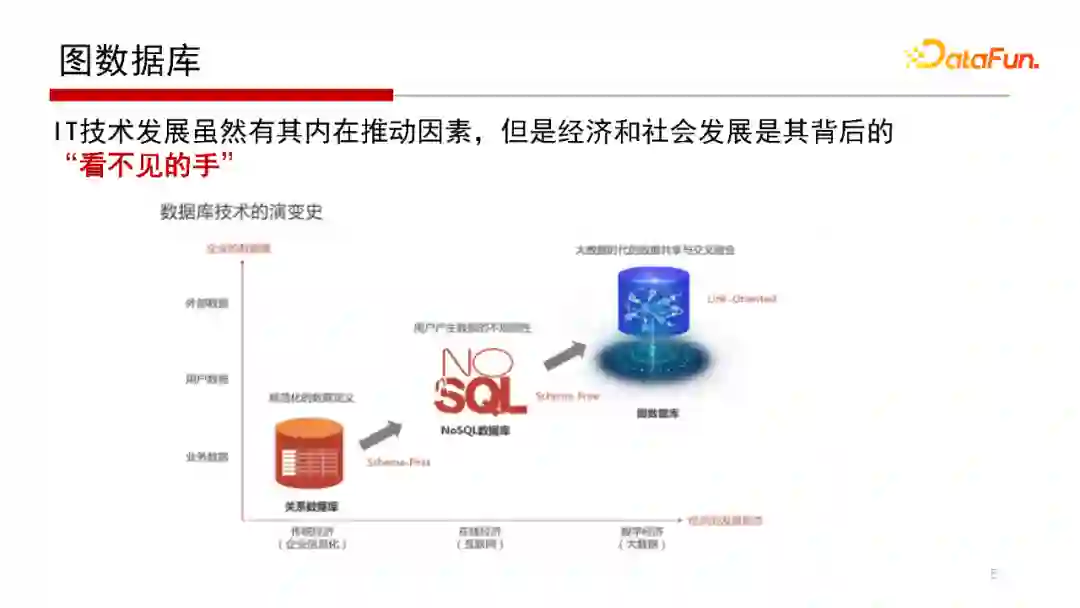
随着研究与实践应用的进行,我们越来越发现,虽然IT技术发展有内在的推动因素,但是经济和社会发展也是“无形的手”。这里我们不去详细讨论从数据管理系统(DBMS)早期从层次、网状数据库到关系数据库转变的过程。其实这个早期过程的核心解决的是如何将数据库系统的应用程序开发人员与数据库系统的内核开发人员进行有效隔离,以提高生产效率的问题,这是一个软件系统演化的过程:完成了从最原始的文件系统管理数据,到构建起一个独立的数据库系统软件来管理数据。
这里,我们重点观察一下从关系数据库到近些年NoSQL再到Graph Database。这一步一步转变,并不是说完全替代,只是随着经济和社会发展出现了NoSQL、出现了Graph Database。这里我们也不从软件系统演化的技术逻辑去做分析,而是从市场主体的企业的数据观角度去试图理解这点变化。前面已经提到关系数据库是Schema-First,其特点是需要有一个表结构,表结构来自E-R图,E-R图从需求来,需求来自企业本身对这个任务有一个很清晰的业务逻辑,它适合传统经济场景,解决的是传统企业的信息化问题。传统企业只有把问题信息化才有业务逻辑,才有需求,才能明确地画出E-R图。有了E-R图后才可以映射成表和表结构,通常情况下这个表结构不会做太大变化,因为关系数据库表结构或Schema做变化是一个非常耗时的任务。
在互联网经济时代,数据不仅仅是企业内部业务系统产生的,有很多数据的产生也不满足提前预设的Schema,这类数据通常称为Users Generate Content(UGC)。这样的数据存储需求催生了 Key-Value为代表的NoSQL数据库系统,以解决在线经济中互联网情景下用户产生的数据不规则、不满足预设Schema的数据存储问题。
前面提到的NoSQL关注的是用户及相关数据,传统关系数据库关注的是企业的内部业务数据;而图数据库关注的是外部数据。在大数据、数据经济时代讲究的是数据之间融合和关联。因为一个企业在做业务执行、决策判定的时候,需要大量的外部数据。在企业经营时,需要跟其他单位做一些数据的交换,获取一些外部数据,而外部数据获得与企业本身掌握的数据之间要完成数据的关联,而这种数据关联以“图”的形式表示是最为合适的;图的点和边之间的关联,是能够表达数据之间深层次的语义相关性的,因此认为图数据库是数字经济和大数据时代的一种重要的数据模型。
从上面的分析可以看出,技术的发展通常是有着经济和社会发展作为背后的推动和选择因素。
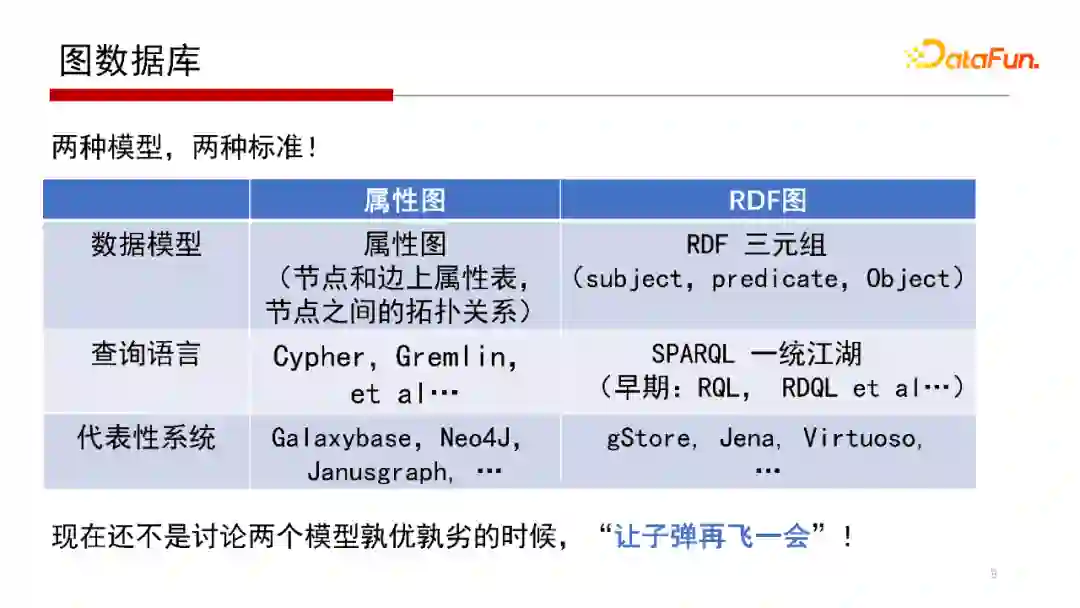
目前看,图数据库通常有两大类,一种是属性图,另一种是RDF图。
其中,属性图在节点和边上有属性表,从某种角度上讲,它仍带有关系数据库的基本特性,类似表结构的形式,实际是采用Key-Value形式来存储的。针对属性图的节点和边上的属性表的定义,各个厂商的差别也比较大。例如有些模型中不允许同一个节点分属不同的类别。因各个厂商有自己的查询语言,其中查询语言使用比较多,用户规模比较大、有一定影响力的查询语言包括Cypher、Apache开源项目的Gremlin等。
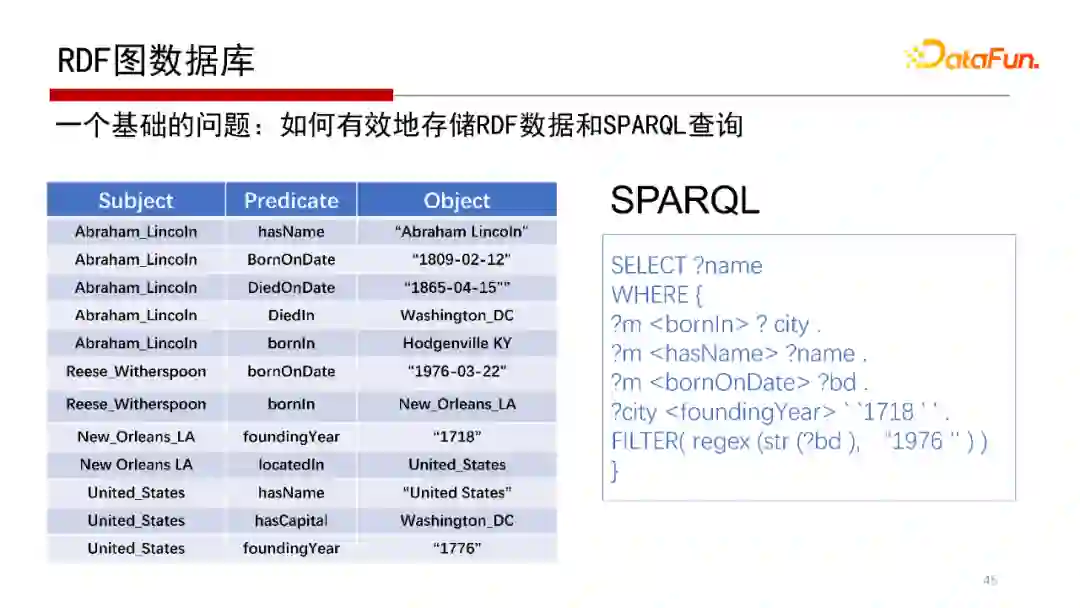
RDF图全称是Resource-Description-Framework,是从语义网演变来的,借用了很多语义网的协议标准,具体就是语义网框架下的数据语言与查询语言的标准,包括RDF三元组和SPARQL。RDF三元组表示其图结构是用主谓宾的形式来表达的,查询语言是SPARQL,当然早期语言还有RQL、RDQL等。这类图数据库系统最大的好处是协议统一,从数据模型到查询语言的模型都有一套严格的规范标注。代表性的系统包括我们北京大学数据管理实验室(PKUMOD)的gStore系统、Apache开源项目Jena等。
这两个模型孰优孰劣,现在还不是很好讨论,因为两个模型各有各的优劣。例如,语义网特点是比较容易支持后期的推理,而且其标准化做得比较好。而目前图数据库也正在做标准化的事情。评判两个模型的优劣也不应该仅从技术角度做评判,因此认为还不是评判的时候。下面我们简单介绍一下相关模型。
6. RDF图数据模型

RDF图的特点是主、谓、宾表示方式,无论是表示实体、属性还是实体与实体的关系,都用主谓宾的表示。
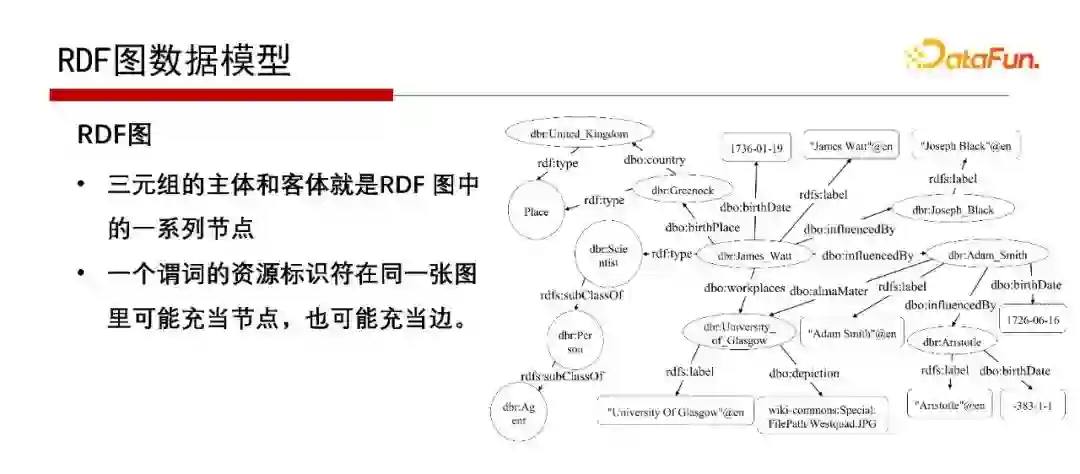
那为什么是图的形式呢?因为主语和宾语就是两个点,它们之间的关系就是一条边,因此是RDF Graph;不是把RDF数据看成Graph图,而是它本身就是Graph图,只是它不仅可以表示成三列表的形式,也可以表示成Graph图的形式。
7. SPARQL查询语言

查询语言SPARQL与SQL很像,也是一种描述性语言,具体如何执行依赖数据库引擎。
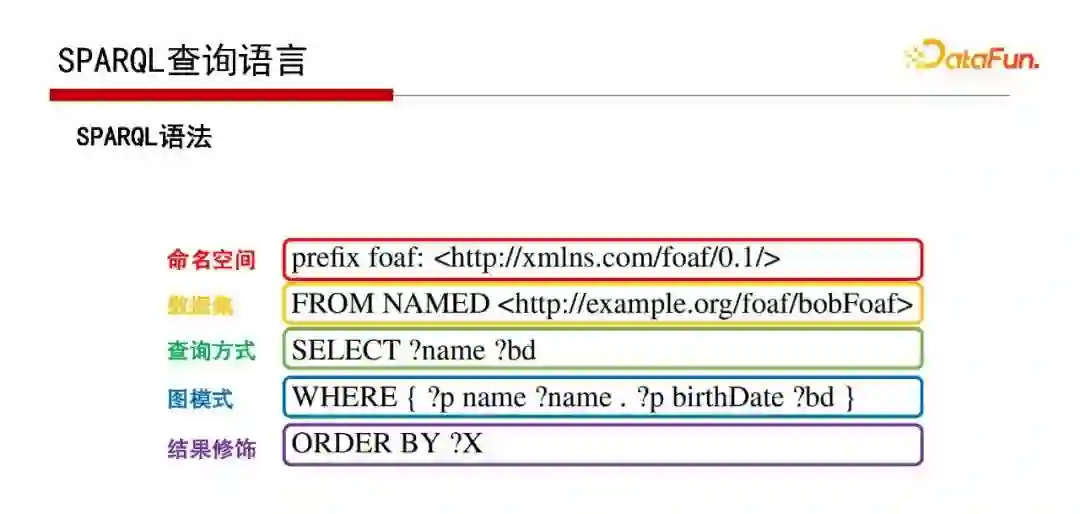
此为SPARQL查询语言的语法示例。

除基本的图模式外,还有复杂的图模式,如带有OPTIONAL、UNION等的语句,见以上示例,这里不再赘述。
8. 属性图模型
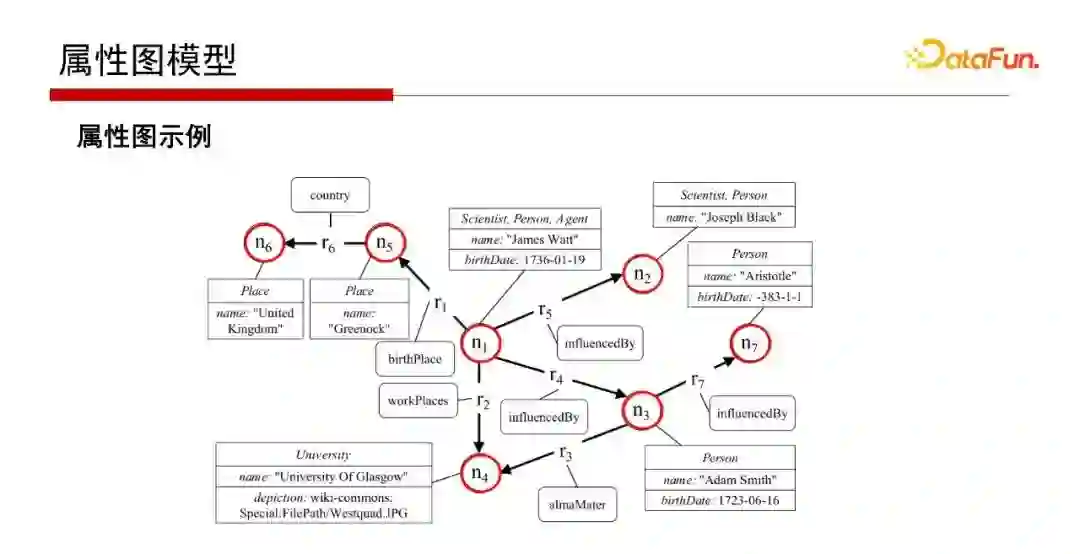
属性图如之前所讲,其点和边都是有属性表的,如Person,Person的名字name、Person的birthDate;如边r7上目前只画了标签influencedBy,但实际也可以是属性表的。这是属性图的一个非常好的优势。
9. Cypher查询语言

属性图的查询语言Cypher,如示例简单解释一下Cypher查询语言的含义,找到属性图中任务的出生地点以及受多少人影响,这个查询语言是:
MATCH(r:Person),首先是找一个人,类型是Person,将所有的Person复制到一张中间表中,中间表的名字为r;
OPTIONAL MATCH(r)-[:birthPlace]->(pl:Person),r表中的每个记录是否有birthPlace,左连接方式,如果有birthPlace,则找出;
MATCH(r)-[:influencedBy*]->(p:Person),再看这些人受哪些人影响,因为带*,则把直接影响或多跳即间接影响的人都找到。



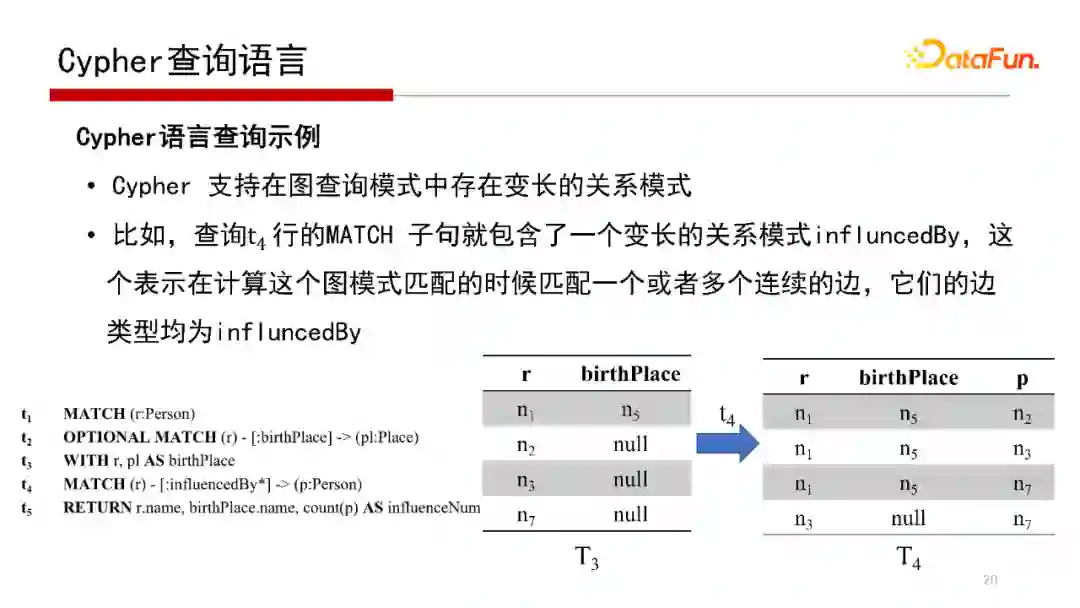
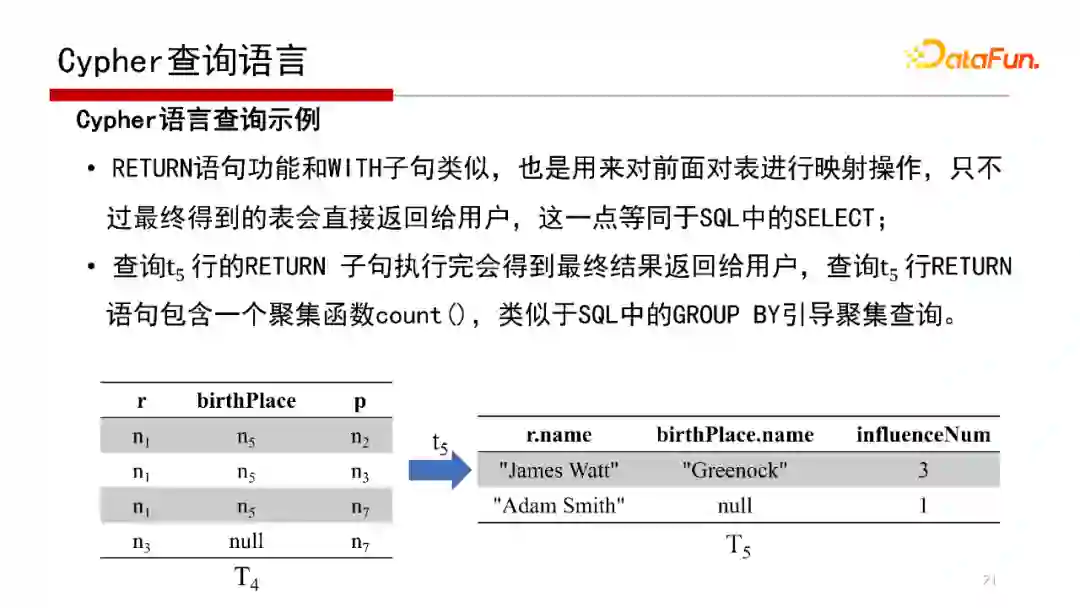
Cypher查询语言的执行见上图,这里不再赘述。
前面讲了数据模型、数据模型的查询语言,那与本期主题“子图匹配”有什么关系呢?
1. 子图匹配
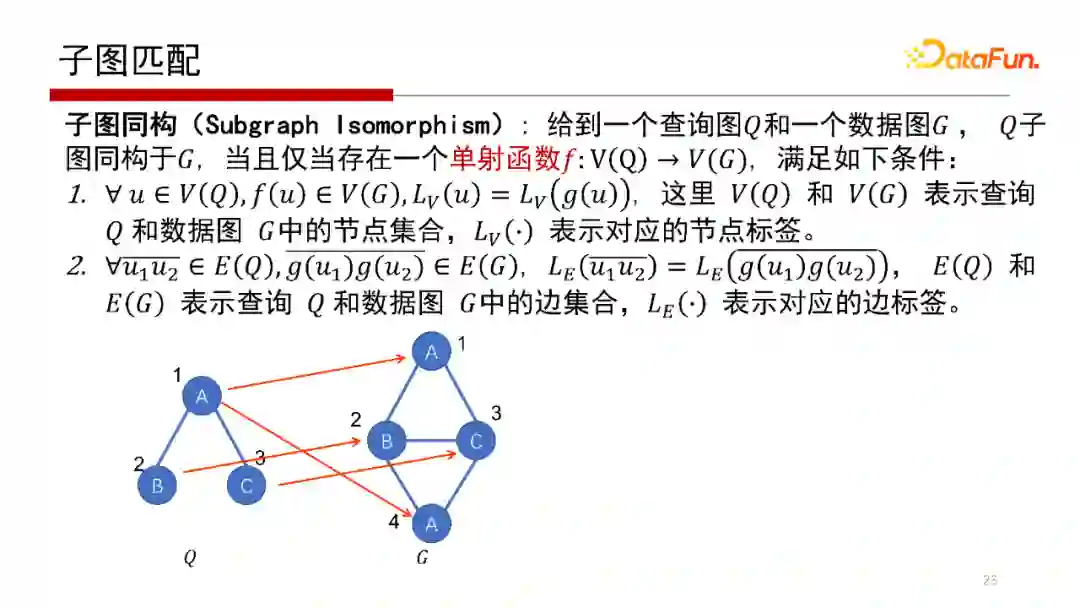
子图匹配核心概念是给到一个查询图Q和一个数据图G,Q里的每一个点通过一个单射函数映射到G当中去,即单射函数f:V(Q)→V(G)。Q中的每一个点在单射函数Function(f)作用下唯一映射到G的每个点上去,如上图中Q的1、2、3在G的中的第一个子图匹配是(1、2、3),第二个子图匹配是(2、3、4)。子图匹配的本质就是给一个Q,找到Q在G中的所有匹配,如示例中找到所有的二叉结构。
2. 问题的复杂性

从计算复杂性来讲,子图匹配是一个非常复杂的问题。如果对查询图Q不加限制,子图匹配的判定是NP-Complete的;列举所有的子图匹配出现的位置是NP-Hard。虽然匹配算法本身是指数的,但在实践中,可以采用大量的过滤策略来检索搜索空间,从而提高查询的性能。
3. 子图匹配与图数据库
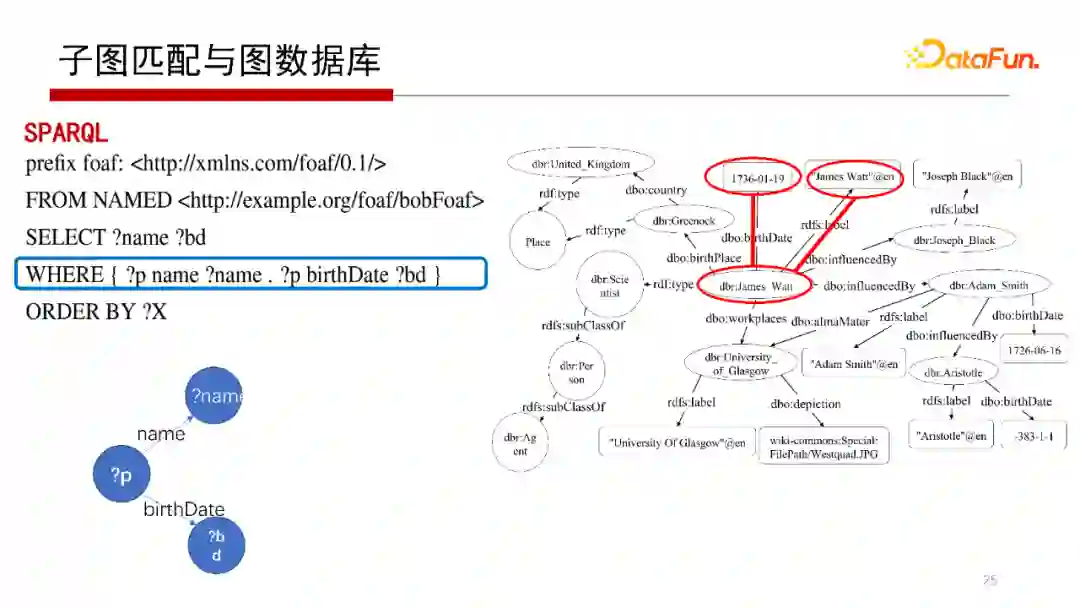
子图匹配与图数据库有什么关系?
上面的SPARQL查询的WHERE子句部分,可以表达为一个查询图,如这页中的左下图。其中带有“?”的“?p”表示变量的含义。我们在这个例子中可以找到图G中的子图匹配,如红色表示的部分。执行上述SPARQL语句,本质上就是Q到G的子图匹配问题。其中,Q可能会更复杂,它不仅仅是Basic Graph Pattern(基础图模式),这个后面有机会再阐述。
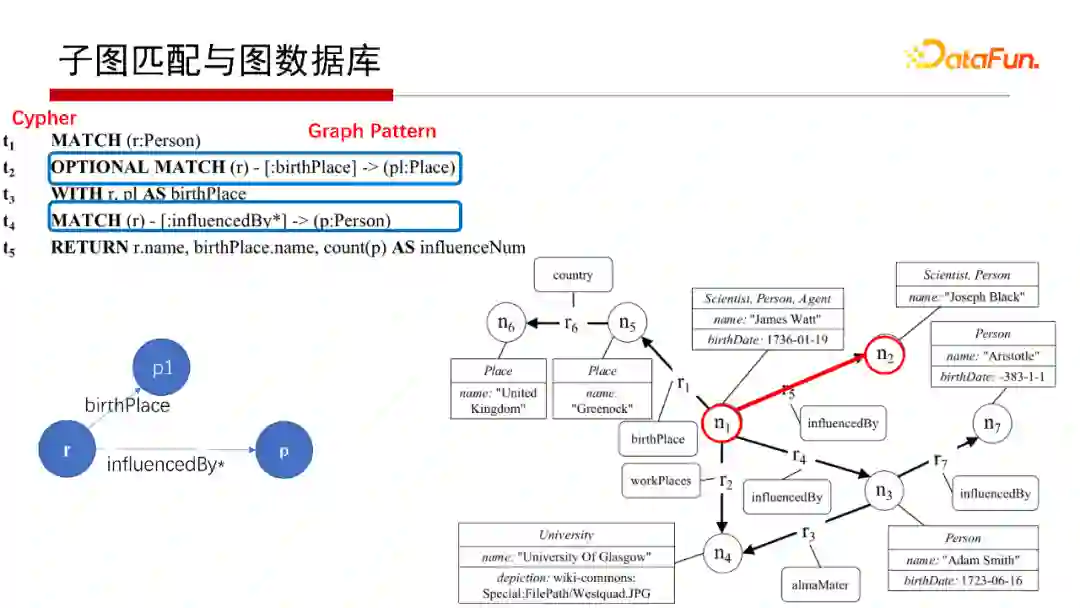
对于Cypher查询语言也是一个子图匹配。如上图中OPTIONAL MATCH和MATCH语句,其可以表现为上图中左下角的Q,在匹配右侧G时,“birthPlace”是匹配到节点的属性值上去了,仅此而已,其实也是一个子图匹配的过程。
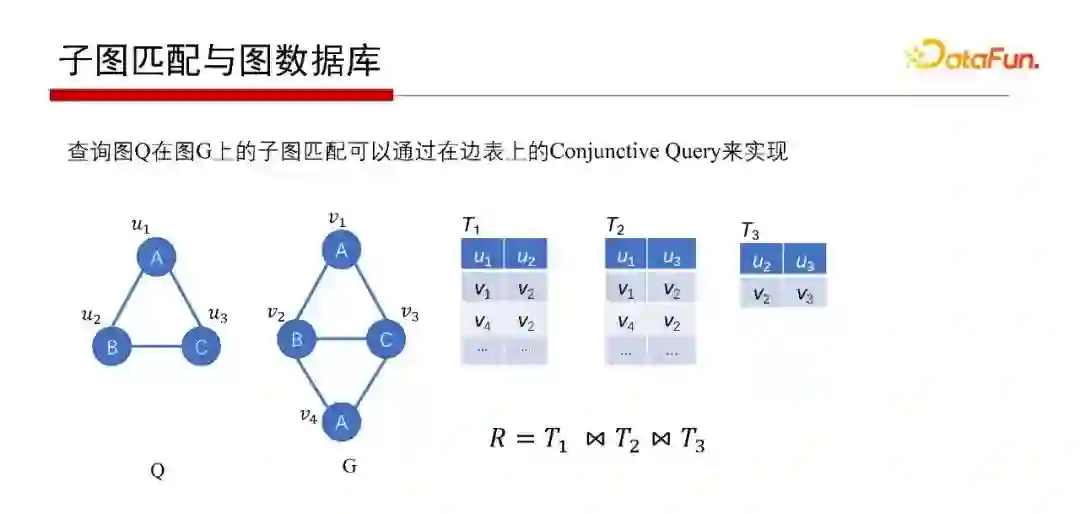
那子图匹配如何解呢?子图匹配问题用关系数据库也可以解。如上图G存在边表里,表示边的起点和终点。回答Q在G中的子图匹配查询,则分别先找到匹配查询图Q中的AB边的是T1表、匹配AC边的是T2表和匹配BC边的是T3表,然后T1、T2、T3做自然连接(Join)操作,如果结构非空,就找到Q的子图匹配了。所以,如果用关系代数来解决子图匹配的问题,则等同于关系数据库的Conjunctive Query。
4. 子图匹配的算法
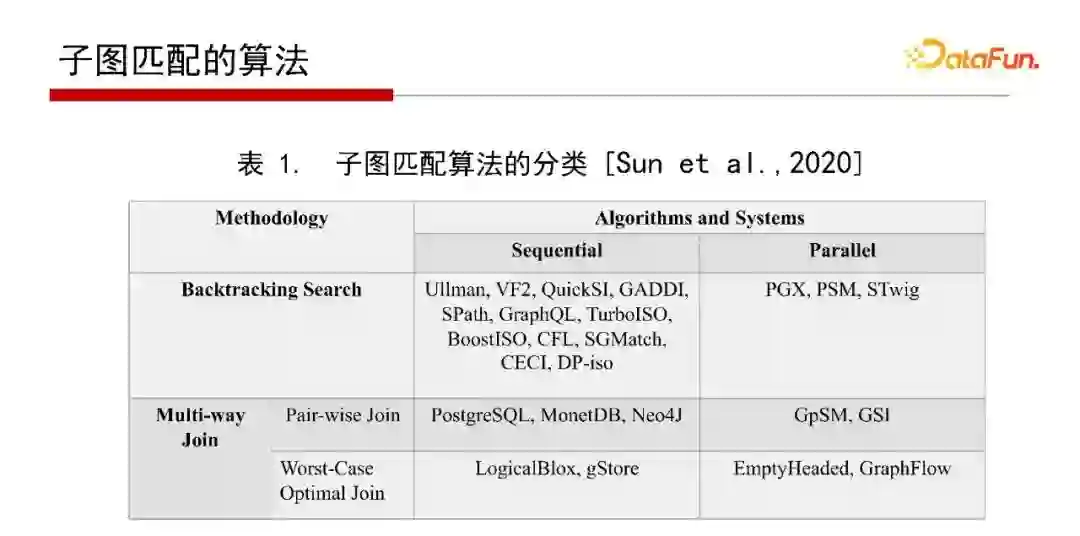
在一篇SIGMOD 2020实验论文中指出,做子图匹配可以有两类算法,一类为基于深度搜索加回溯的方式(Backtracking Search),一类为基于广度优先的Multi-way Join方法。
5. 子图匹配的搜索空间
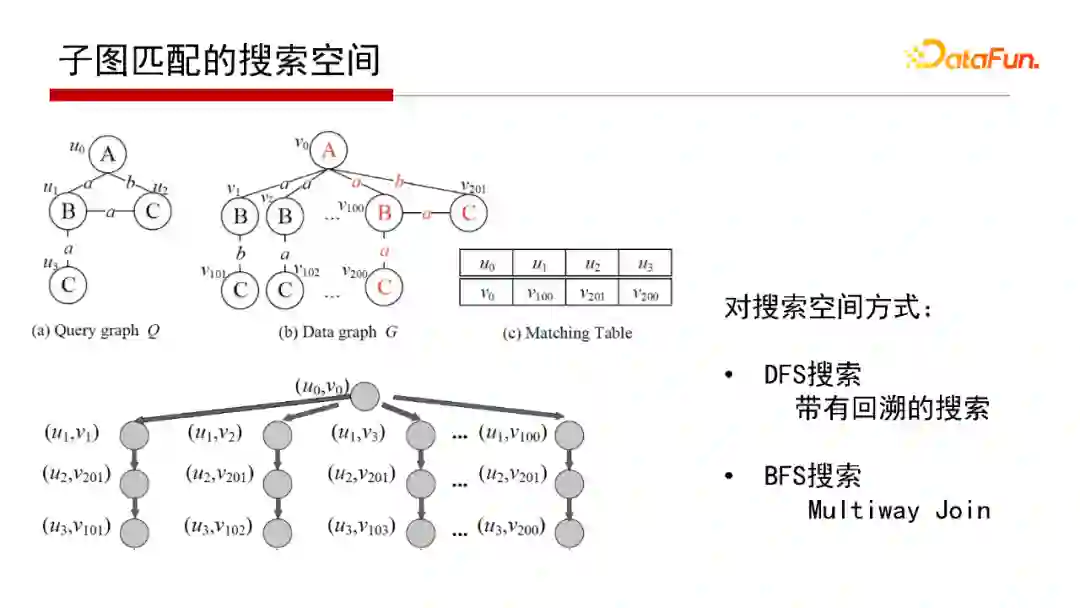
这里对子图匹配的两类算法形象化解释一下。假设有个Q和一个G,找到Q在G的子图匹配,实际就是在搜索空间查找。这里把搜索空间定义成一个搜索树(如上图左下角的属性图),Backtracking Search搜索的策略是深度优先(DFS搜索),再回溯回来;Multi-way Join搜索的策略则是宽度优先(BFS搜索),即在搜索树上一层一层去找。
6. 带有回溯的搜索算法(Backtracking Search)
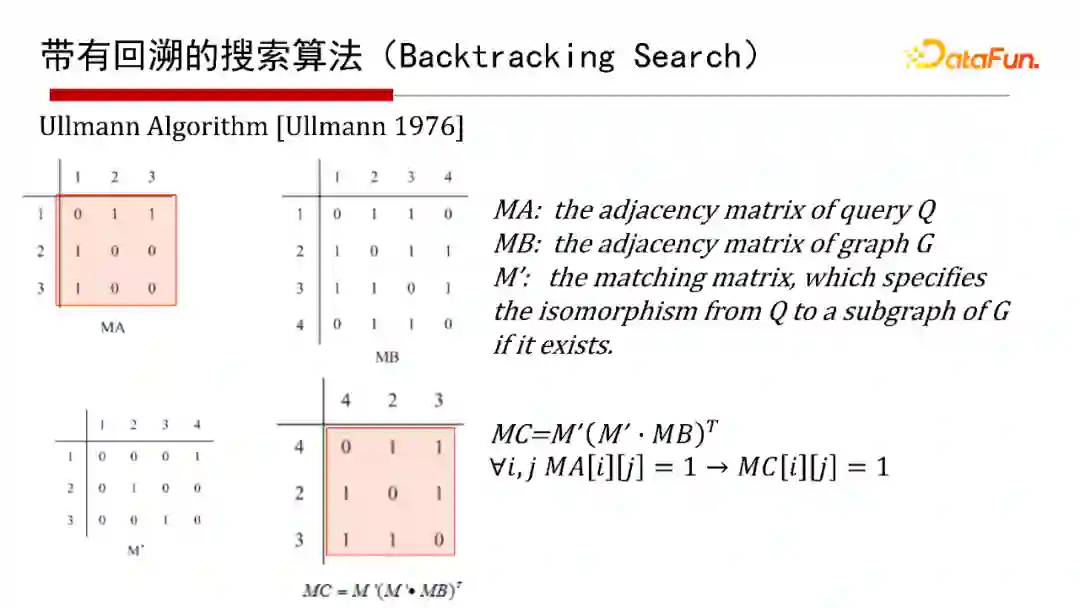

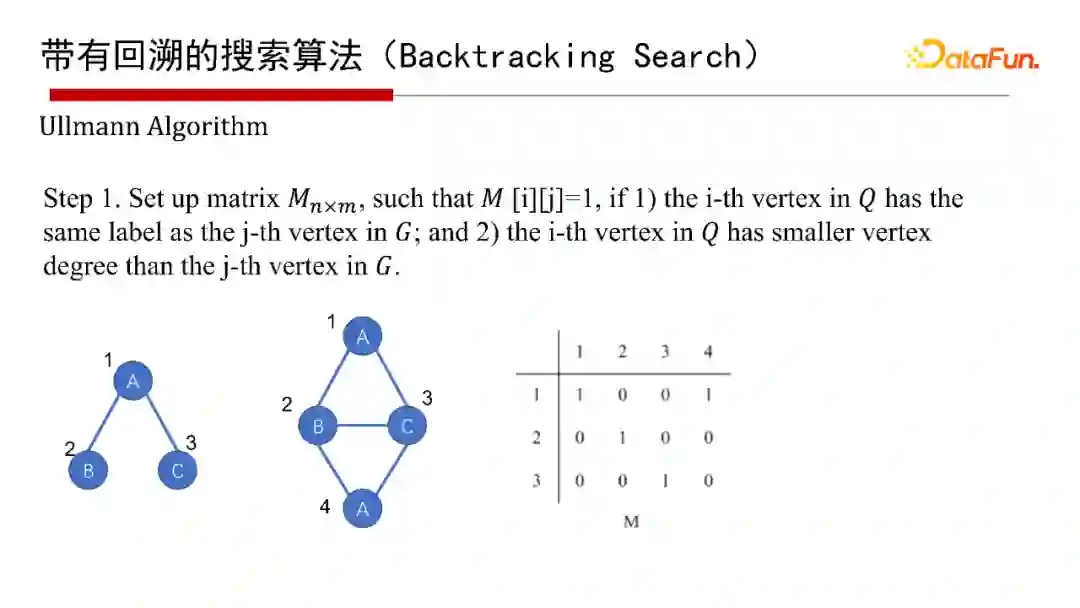

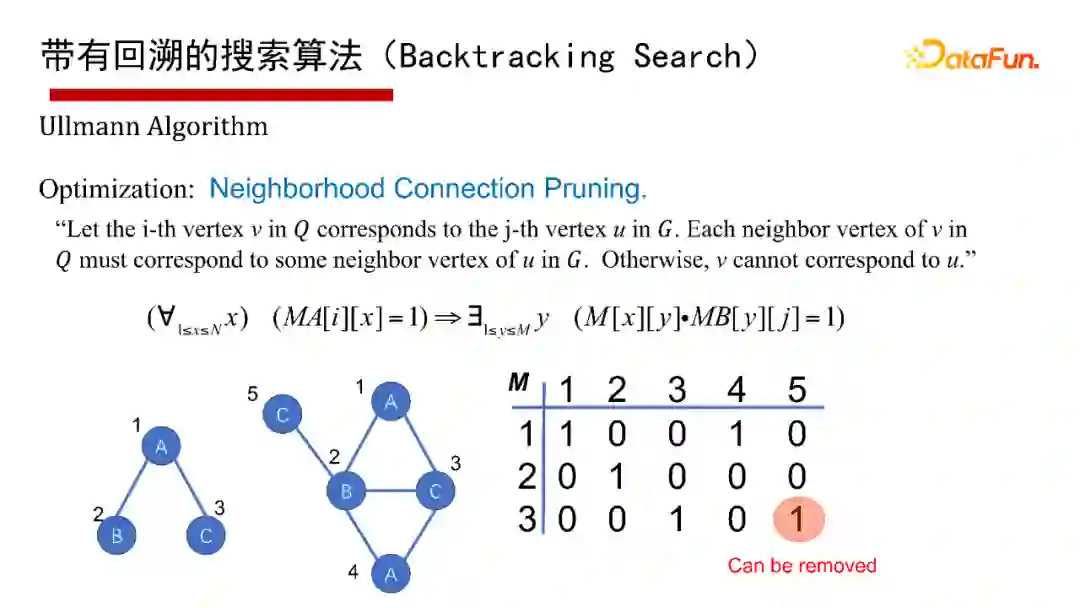
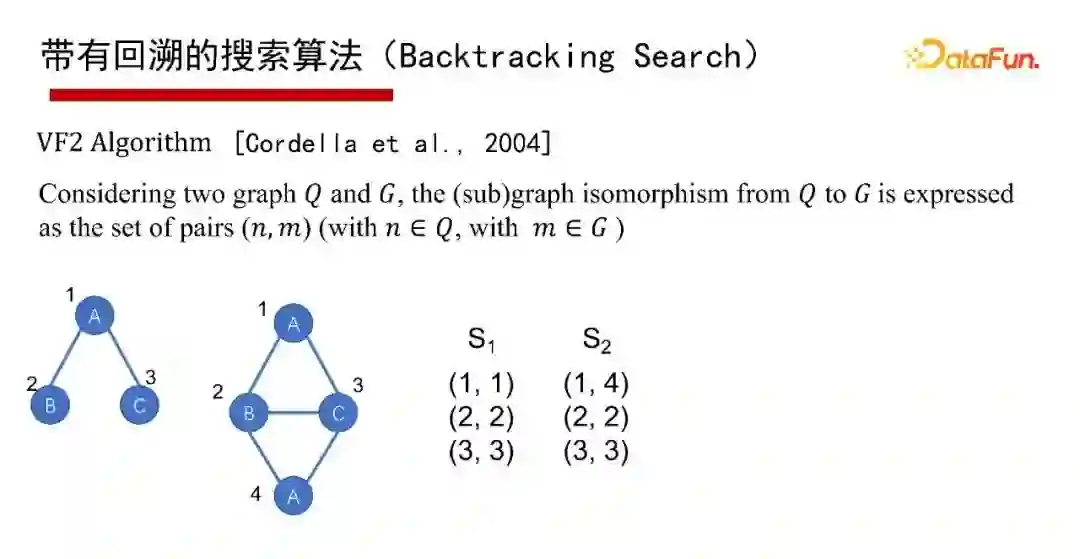
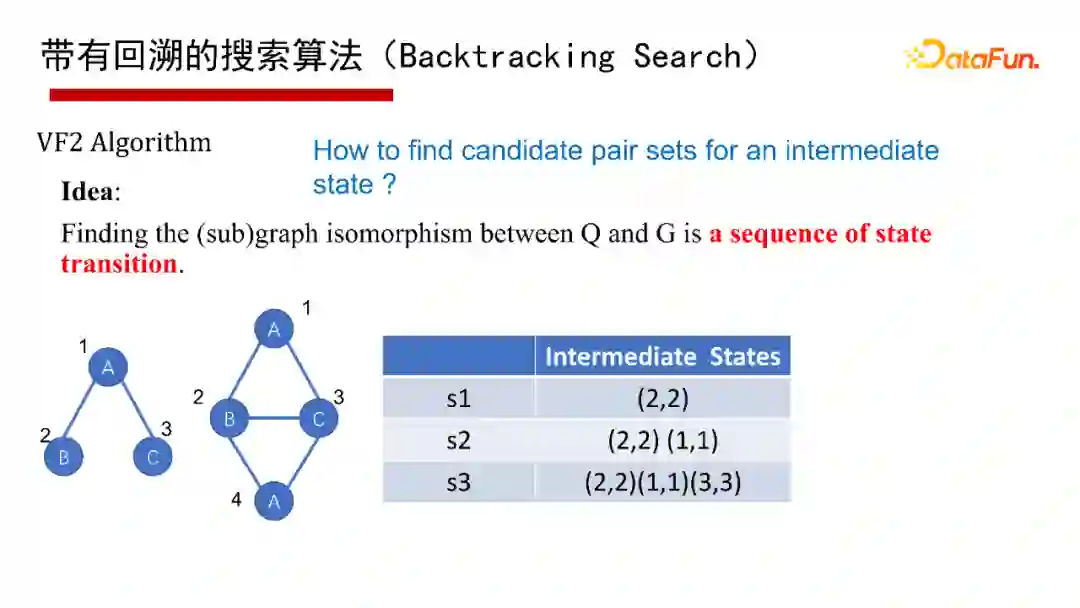
带有回溯的搜索算法(Backtracking Search),有1976年最早开始的Ullmann算法,2000年的Ullmann Algorithm算法,2004年的VF2 Algorithm算法等,这里就不再具体介绍算法本身了,有兴趣的同学们可以参考给出的参考文献。

这里采用通用的算法框架(Common Framework)来讲讲带有回溯的搜索算法。给一个查询图Q,首先定义一个节点被匹配的顺序,即最先匹配哪个点,然后是哪个点(generate a matching order),然后每次试图按节点匹配顺序进行一个点一个点的匹配;如果当前状态匹配不了,则回溯;如果要找全部的解集,也得做回溯。其优点是可避免产生大量的中间结果,因采用深度优先,仅有递归调用栈的空间,没有什么中间结果。其缺点是难以并行执行,会有大量的递归开销,因此适合做LIMIT K和TOP-K的子图匹配查询,即只返回K个或TOP K个结果(K很小的情况下)。
7. 基于多路连接的算法 (Multiway Join)
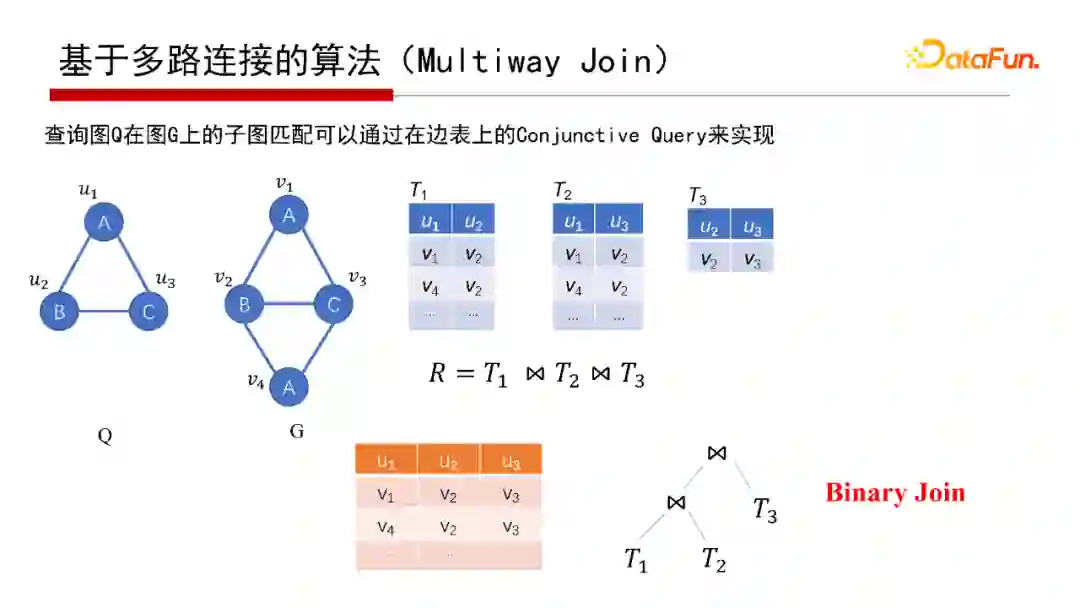
对于宽度优先的算法,实际关系数据库每次的Join就是宽度优先。子图匹配从逻辑来说是T1、T2、T3的Join操作。Join怎么执行呢?从Join执行角度来说,有两种不同的执行方案,一种是Binary Join,即第一张表T1和第二张表T2作Join,结果再与第三张表T3作一次Join,是以边为中心。
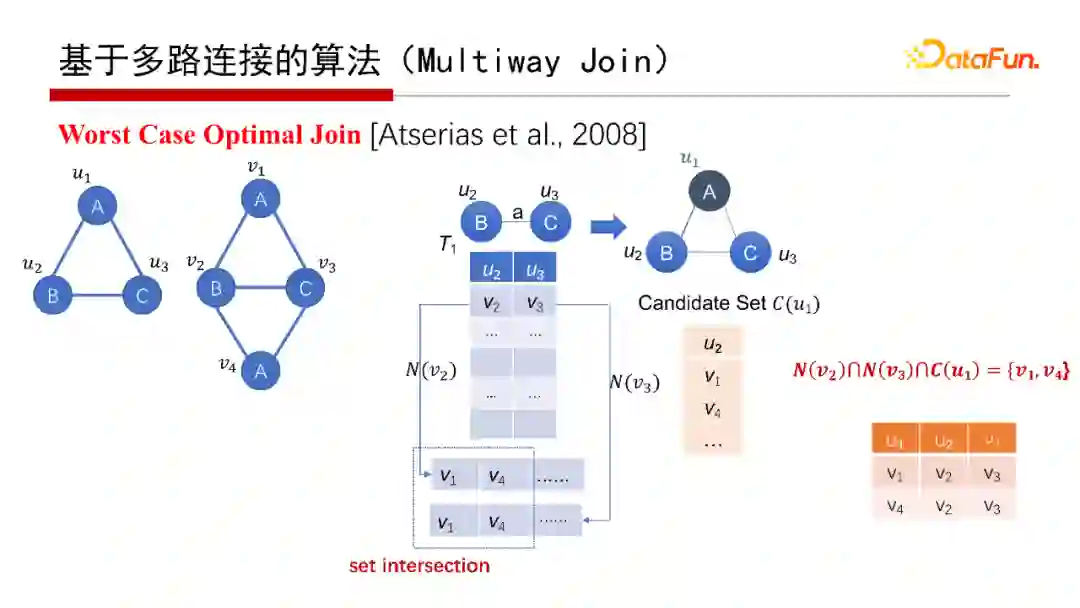
还有一种是Worst Case Optimal Join(具体可以查看给出的参考文献)。例如,假设已经匹配了BC这条边,即G中的v2和v3匹配了Q中的u2和u3,那么要找查询图Q的ABC的匹配,则查找G中是否有一个三角形恰好能够匹配Q的ABC,并且三角形包含v2和v3。例如考虑中间结果表的第一行,把v2和v3的邻居N(v2)和N(v3)找出来,然后两个集合做一个交集set intersection,再和A点的候选集合C(u1)做个交集,N(v2)、N(v3)、C(u1)三个集合的交集不为空,在这个例子中交集为{ v1, v4};将其分别串联到v2和v3后面,得到v1、v2、v3和v4、v2、v3这两个匹配。在上面的例子中,可以对每一行都执行该操作,因此该算法很容易做并行。

请注意上面给出的WOJ算法中,有一个很重要的操作,就是集合求交。

之所以称之为Worst Case Optimal Join,是针对Binary Join而言,其复杂性是和它在worst case情况下的输出结果数量相匹配的。以ABC三角形查询图为例,其最多有N1.5个三角形,N是边的数目。如果用Binary Join,有可能会产生N2的中间结果。如果采用Worst Case Optimal Join算法,则永远不可能产生超过N1.5的中间结果,其运行时间的复杂性也是N1.5。对于其他的查询图,Worst Case Optimal Join也表现出该种特点。
8. Binary Join + Worst Case Optimal Join

但并不意味着Worst Case Optimal Join算法一定比Binary Join算法好。Worst Case Optimal Join算法只是保证在最差情况下比Binary Join算法好。
滑铁卢大学做的图数据库系统GraphFlow,就提出把Worst Case Optimal Join和Binary Join相结合,在子图匹配的执行选择中既考虑Binary Join,又考虑Worst Case Optimal Join。

启发式地讲,Worst Case Optimal Join和Binary Join各有好处。Binary Join比较适合没有环或者是树形或者环比较稀少的查询图。Worst Case Optimal Join比较适合密集环形的查询图。因此,比较好的Join方法是依赖于查询图的图结构。
简单介绍一下我们北京大学数据库管理实验室(PKUMOD)做的一些工作。
1. RDF图数据库
RDF图数据库,查询语言是SPARQL。
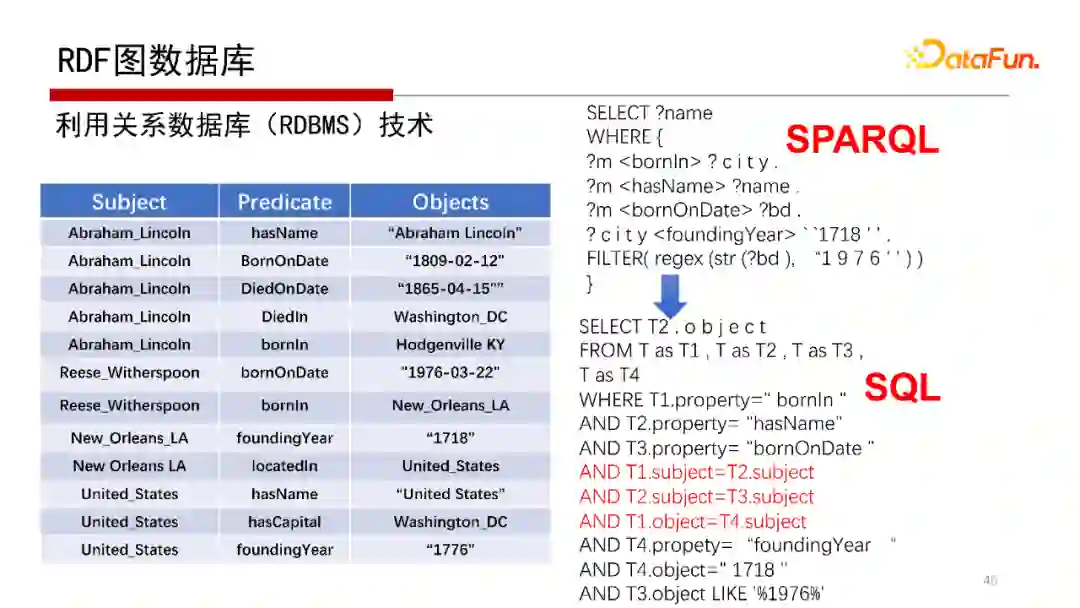
SPARQL语句也可以用关系数据库来解。可以将SPARQL转化为SQL语句。

然后用SQL语句去执行,或者可以把一张大表的表结构划分成不同的表,仍然采用转化成SQL语句,类似关系数据库一样去查询,如Oracle、DB2最新的版本支持RDF,就是用这种方法去做的。但该方法的Join会很多,性能会非常低。
2. gStore[Zou et al.,2011]
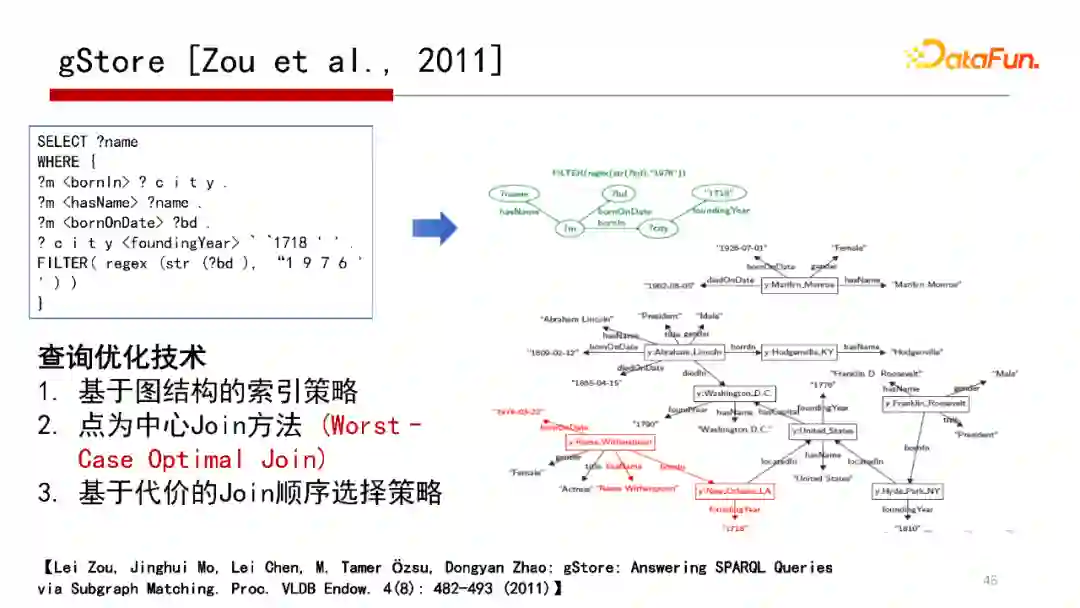
我们在2011年有一篇发在VLDB的工作“gStore: Answering SPARQL Queries via Subgraph Matching.”,给一个SPARQL,把它Match到一个查询图Q,那么回答SPARQL就是在Data Graph中找到查询图Q的匹配,如果能找到,那么就能很快回答SPARQL,这是gStore系统最核心的思路。
gStore系统思路从技术层面,在索引的方式、Join的策略和Join顺序的选择提出了三种查询优化方式。在原来的系统版本中,采用的是以点为中心的策略,类似Worst Case Optimal Join,没有用Worst Case Optimal Join和Binary Join合在一起的。但在即将发布的1.0版本,则考虑了Worst Case Optimal Join 加 Binary Join合在一起的策略。
gStore的开源项目官网在http://www.gstore.cn/,里面有详细的使用文档,在gitHub和gitee(码云在线)上面都有gStore的源码;同时我们也有个在线 gStore 云平台(http://cloud.gstore.cn/),大家可以免安装直接使用。
3. 分布式gStore[Pengu et al.,2016]
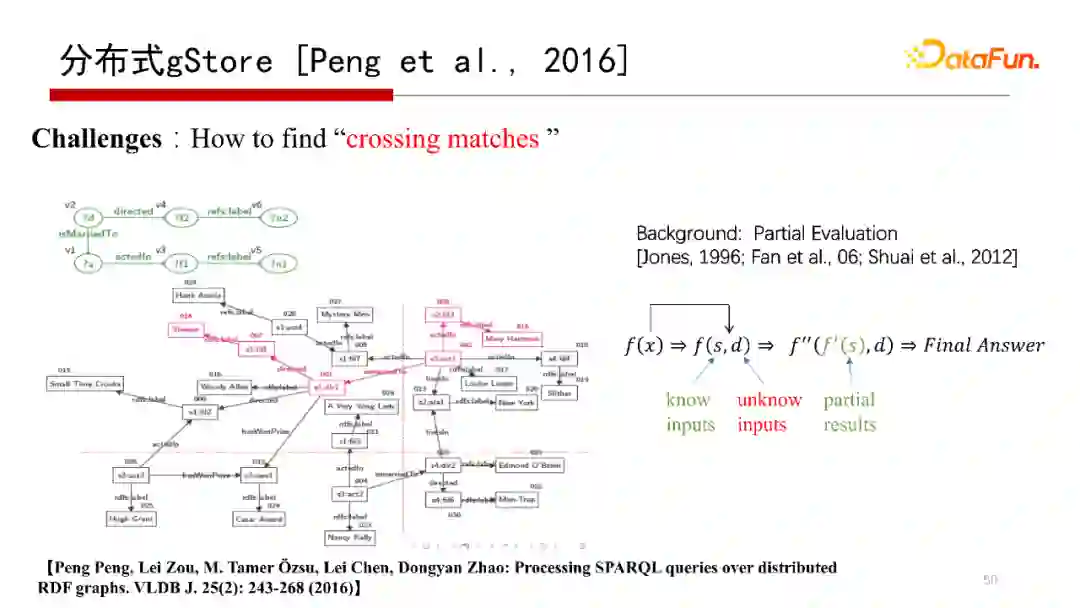
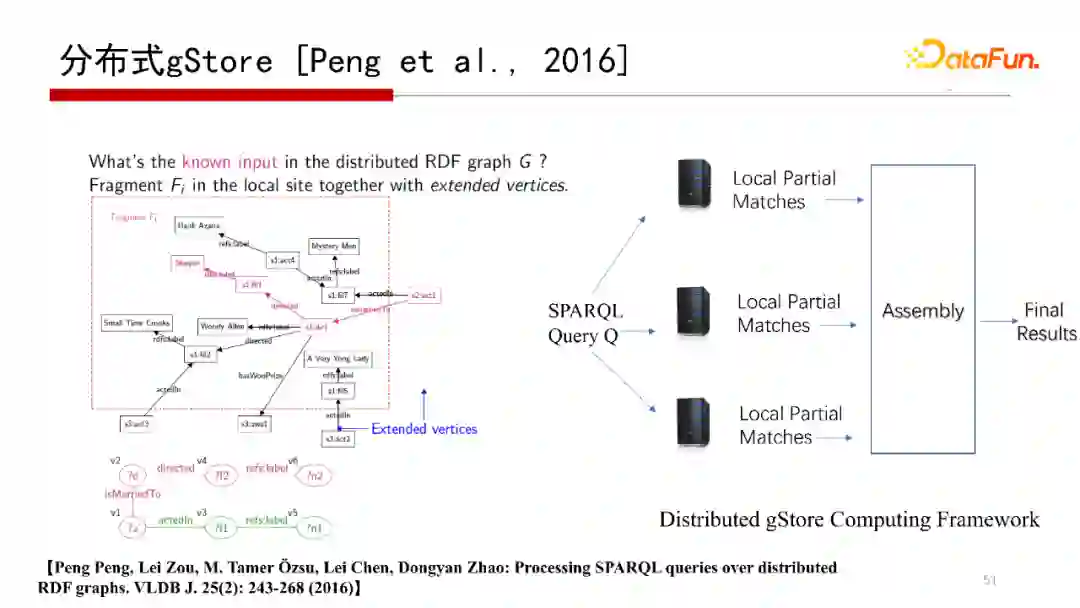
下面提到的是分布式gStore系统,解决的是单机存储不下一个大的RDF图,需要分布式存储在多个机器上,而查询结果跨在多台机器上的问题。我们在VLDB Journal 2016的一篇文章“Processing SPARQL queries over distributed RDF graphs”有介绍分布式gStore。
4. 优化原子操作-Set Intersection

前面提到在做 Worst Case Optimal Join 时最重要的是集合求交操作。集合求交是子图匹配中很重要的算子操作,那么集合求交怎么加速呢?
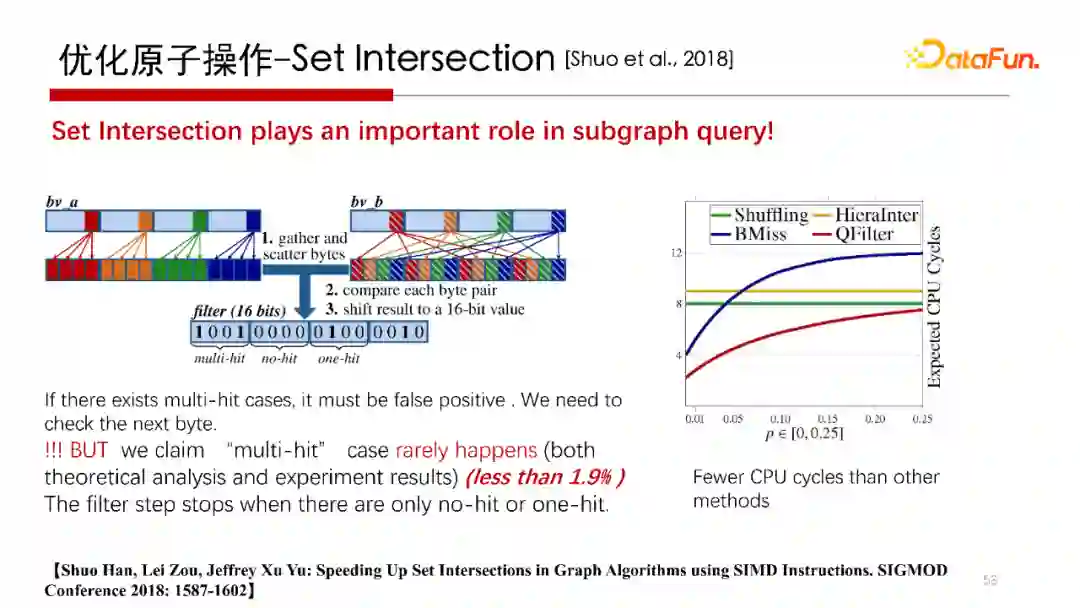
我们在2018年SIGMOD上面发表的“Speeding Up Set Intersections in Graph Algorithms using SIMD Instructions”文中,提出了一种利用 CPU 的 SIMD(单指令多数据流)向量计算方法,通过设计一种精巧的数据布局(Data Layout)策略,可以降低对集合求交中CPU运行的Cycles的数目。
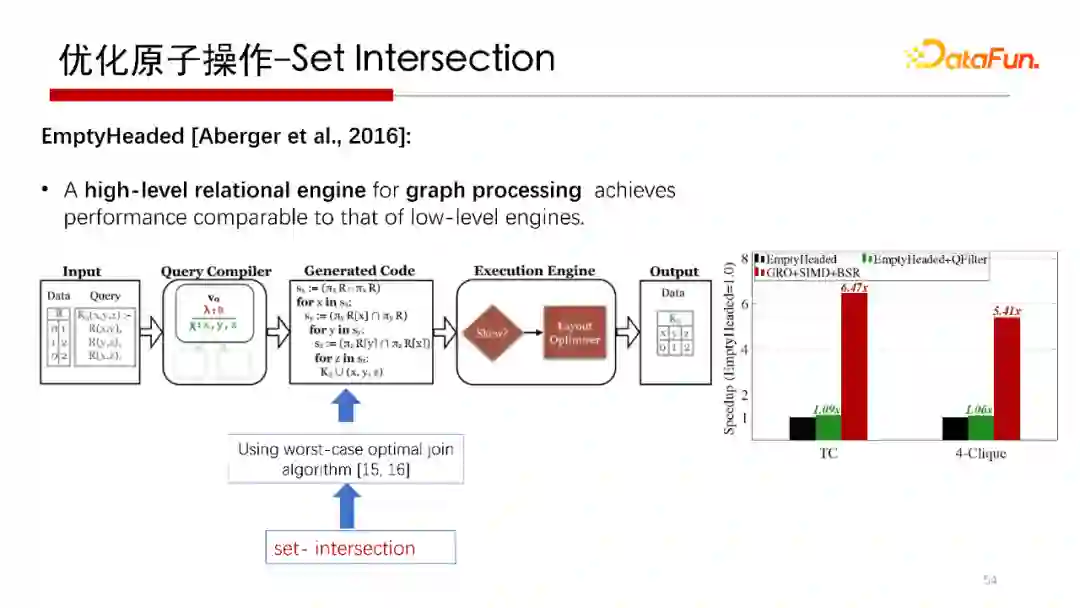
Stanford做的开源的图处理引擎(graph processing)系统,也是用Worst Case Optimal Join做的,在其系统中,将我们研究的集合求交优化算法替换之后,发现性能有比较明显的提升。
5. 硬件加速

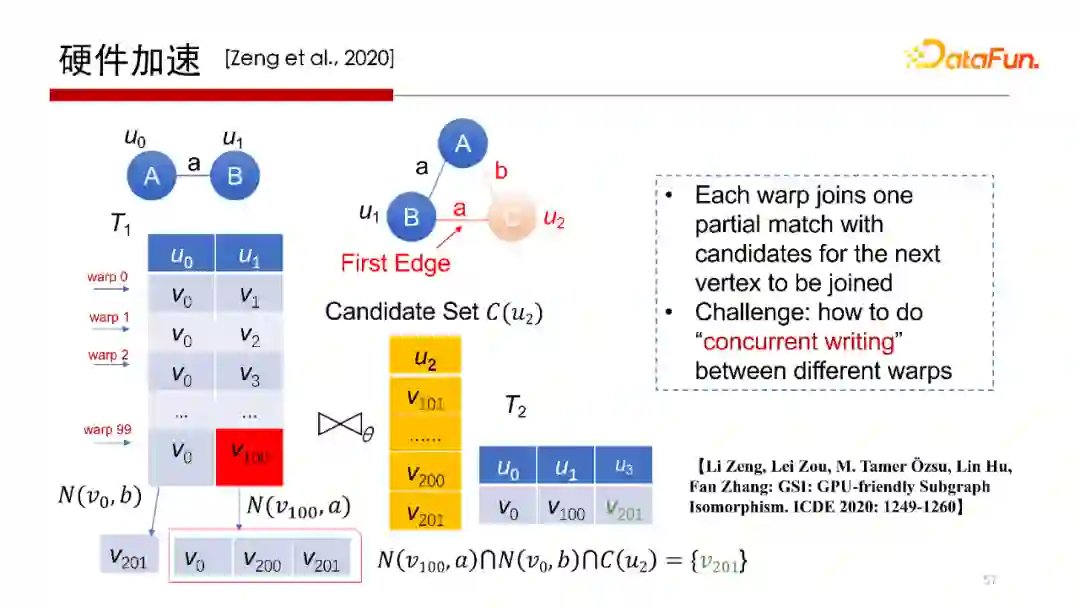

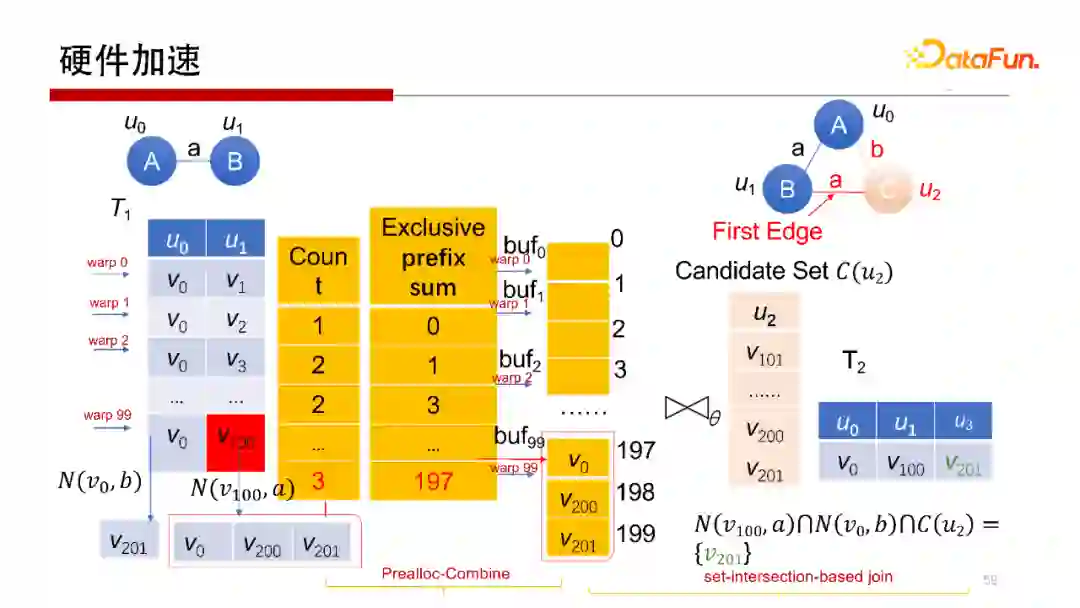
刚才提到,Worst Case Optimal Join算法,每一行是完全独立的查询操作,非常容易做并行。所以会想到使用在GPU上运行操作。但在GPU上执行操作,其每个线程或每个wrap做计算没有问题,但中间结果如何写回去,如何避免写冲突是需要考虑的。我们提出一种方案使得每一个wrap独立地去执行,并且可以独立地去写,在不需要加锁的方式下不会产生写冲突。
6. 总结

最后,总结一下:首先介绍了什么是图数据库以及我们对图数据库的一些思考;第二个重点关注查询引擎组件的工作,子图匹配和查询引擎之间的关系;第三个是对我们北京大学数据管理实验室(PKUMOD)的相关研究工作的介绍。


以上是一些参考文献。

这是我们组的一个公众号“图谱学苑”和gStore图数据库官网信息,大家有兴趣可以关注一下。谢谢大家。
今天的分享就到这里,谢谢大家。
分享嘉宾:

OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。