百度基于 Prometheus 的大规模线上业务监控实践

Prometheus 在云原生监控领域已经成为事实的标准。在业界常见的实践案例中,更多是介绍如何做基础的监控能力对接,很少介绍如何将 Prometheus 大规模的应用于生产环境的案例。而在现实场景中,大型互联网公司 / 金融行业场景的大规模、高可用、高时效性、高精确度等要求,会对现有的联邦或分布式存储 Prometheus 解决方案带来挑战。
本文将会介绍,百度云原生团队是如何针对金融行业的场景需求,结合百度内的应用实践经验,构建基于 Prometheus 的大规模线上业务交易监控能力。
Prometheus 最大的优势在于 PromQL,它提供了灵活的数据分析查询能力,结合 Grafana 提供的仪表盘查询,可以满足指标监控的大部分需求。
而面向大型互联网公司、金融行业等大规模业务监控的场景,原生的 Prometheus 单实例模式无法直接满足需求,需要一种面向生产环境的集群化高可用方案来进行支撑。
Prometheus 常见的集群化高可用思路包括两种:
一种是 Prometheus 联邦集群方案:
Prometheus 联邦集群方案,是基于 Prometheus 单体模式的一种补充。可以让一系列 Prometheus 的单体分别采集不同的目标,然后将数据统一汇总到中央的 Prometheus 集群服务中。
在这种该方案中,中央的 Prometheus 仍然为单体模式,实际的存储能力仍然会受到单机的限制。所以在构建联邦模式时,需要根据数据量,对第一层的 Prometheus 所采集到的数据进行一些聚合计算,将减少后的数据传输到中央 Prometheus 中。故这种方案只能适用于最终需要分析的数据量偏少的场景。
同时该方案本身的维护成本颇高,需要对集群中的每一个 Prometheus 分片采集配置、预计算配置进行管理,如要访问除中央 Prometheus 集群中的数据,还需记录每一个 Prometheus 分片的访问路由。
另一种是 Prometheus 远端存储方案:
远端存储可以提供相比单体 Prometheus,突破了单机的资源限制,能够提供更大规模和更长时间的存储能力。
通过这种方式,整体集群的管理会更加简单,只需要对 Prometheus 设置分片采集,统一将数据导入远端存储即可,配置管理成本也会降低许多。
基于以上分析,可以判断出在大规模的业务监控场景下,一种基于远端存储的 Prometheus 方案是必须的。但对于远端存储,仍然有如下问题需要解决:
远端存储本身仍然有容量的上限限制,针对数据存储时长、性能等要求,并不可能无限扩容。
存储的数据量越大,查询分析的压力也就会越大,一些涉及聚合计算曲线较多的查询、预计算规则 (Record Rule)、报警规则 (Alert Rule) 所带来的大量查询,仍然会将整个集群拖垮。
我们从两个角度,来构建出一套解决方案:
减少指标量级:借鉴 Prometheus 联邦的思路,从采集层做预聚合,来减少指标量级,这个需要从业务角度来进行分析,如何针对交易量类型的指标,缩减指标量级。
提升架构性能:从架构实现角度,如何解决单纯远端存储无法解决的大规模数据分析和报警检测的需求。
在落地实施过程中,团队对业界的各种 Prometheus 集群方案进行了验证,但很不幸,在真实的量级及性能要求之下,基本处于完败状态。
接连碰壁之后,我们决定换一种思路:先减少数据量级,先通过一些方法把指标量降低到架构上能够承载的程度。
经过观察发现,业务中核心要监控的是交易量的指标,这部分指标占全部指标量的 99% 以上。之所以量级这么大,有几方面原因:
负责执行交易动作的模块下包含的实例数量多,每个模块下实例数量能达到几千的级别。
指标下的维度多。一个交易请求指标,包含了分数据中心、交易类型、状态码、请求接口、请求来源等十余个维度。这样单个实例产出的指标量级就将达到数十万量级。
减少指标量级,核心需要分析业务对于这些指标是如何进行使用的。在故障定位场景中,一般故障更容易出现在两个角度:
单个进程实例导致的问题,不管是由于灰度的部署还是单个实例的资源不足等异常,都会体现在单实例的异常上,这时候更多的会在实例级别增加单个实例错误数、错误率、响应时间的的报警。
业务导致的问题,有些异常会出现在某种交易或某个接口上。这种异常一般是该模块全局产生的问题,较少出现的单个实例上某种交易的异常。
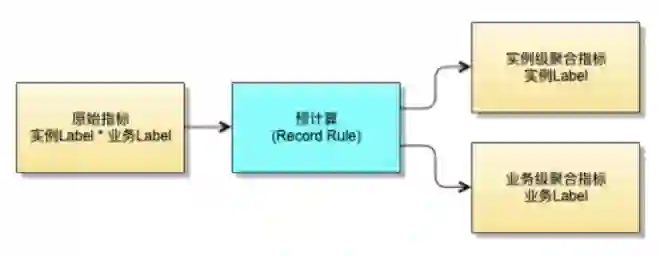
根据以上分析,我们决定对原有指标进行“降维打击”,即减少指标包含的 Label,对相同 Label 的数据进行合并,减少最终数据量级。
根据业务的故障报警与定位的需求,对原有指标进行聚合计算,派生出如下指标:
将原有的实例与业务指标的全叉乘组合,转换为两种数据,即实例级指标和业务级汇聚指标。核心针对这两种指标进行长期存储和报警。
而对于实例叉乘业务的原始指标,根据实际的需求,在部分细节问题定位时仍然会有用,设计其进行短期存储。
通过以上缩减思路,可以将需要长期存储和实时报警的数据量下压几个量级。
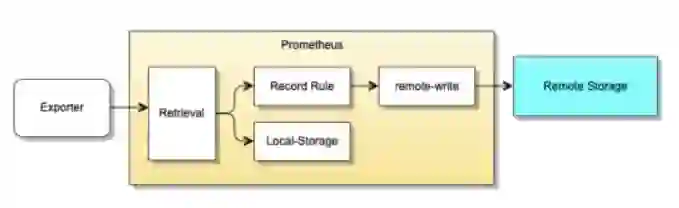
架构实现上,采用 Prometheus 作为采集端,对原始指标进行全量采集,同时保留少量存储,来存储原始指标数据。同时对指标进行加工,降维缩减量级后,传输到远端存储服务中。
业务交易量的指标类型,为 Histogram 类型,用于统计每一个模块处理交易请求的数量、响应时间,以及获得分位值数据。
Histogram 类型包含如下指标:
_count:表示增加的次数,如交易量的次数,Counter 类型。
_sum:表示增加的总耗时,如交易的总耗时,Counter 类型。
_bucket:表示在不同耗时分桶区间内,增加的次数,如在 0-500ms 内的交易量次数。同样为 Counter 类型。
在做降维计算时,我们一开始想到了使用 sum 聚合函数。则根据之前所讲的聚合思路,分别聚合到实例级和业务级,可以写出如下的聚合规则:

以上规则正确吗?
答案是否定的,对 Counter 数据的直接求 sum 会导致最终数据错误。
原因在于 Counter 指标的特殊性:
Counter 指标是一个递增值,会记录从服务启动到现在的总量
当出现服务重启时,Counter 指标会从 0 开始重新计数
这种特别的设计,也带来了特别的使用方法:
由于 Counter 持续递增的特征,直接使用 Counter 指标没有意义,需要使用算子获得前后两个值的差值。如 Prometheus 中提供了 increase、rate、irate、delta 等算子,专用于处理 Counter 类型的数据。
由于 Counter 值在服务重启时会重新从 0 计数,会导致数据不再递增,此事如果做差值计算,会出现负值的情况。Prometheus 的上述算子对这种情况进行了特殊处理,当发现前后点差值为负数,会认为该数据出现了重置,则会使用后一个点的值减去 0,作为该点的实际增量。
基于以上特征,当我们直接使用 sum 算子将多个实例的曲线加和后,其中一个实例的重启,就会导致整体的数据出现后值小于前值的情况,基于 Prometheus 算子实现原理,断崖部分会使用后者值直接减去 0,远比实际值要高很多,出现突增。
那么如何解决这个问题?
我们选择绕过 Counter 指标。在聚合计算时,首先将 Counter 指标进行差值计算,转换为 Gauge 数据,获得周期内的增量,然后对这个 Gauge 数据进行 sum 聚合。就可以避免 increase、rate 等算子的特殊行为。
具体更换后算子如下(以采集周期为 5s 举例):

其中内层用于将 Counter 指标转换为按照周期的 Gauge 增量指标:
rate 表示求周期内的增长速率,由于 rate 等算子,必须包含两个点来进行计算,在 5s 采集周期下,填入 10s 的窗口来保证这个条件。
-
*5 表示将速率转换为 5s 周期内的变化量。
外层的 sum,表示对内层产生的 Gauge 指标进行聚合。
则正确的计算任务修改为如下规则:

使用一个 Prometheus 集群来满足对业务所有服务 Exporter 的监控,这就涉及如何做分片管理。
应对方法是建设独立的 Prometheus 采集分片管理服务,Prom-Scheduler 与 Prom-Agent 服务:
Prom-Scheduler 负责基于采集任务,进行任务分配。同时通过定期的对采集端点进行探测,获得 Exporter 产出的指标量级,根据 Exporter 的指标量级进行任务负载均衡。
Prom-Agent 则与 Prometheus 采集服务一同部署,负责管理该分片 Prometheus 的采集配置。
整个 Prometheus 采集服务使用 Kubernetes 进行部署,在资源情况允许的情况下,通过对采集指标量级的监控,实现自动的采集服务扩缩容。
根据上文所述的预聚合需求,针对不同场景拆分了两个 Prometheus 采集集群,应用不同的自动分配算法来满足不同场景的自动伸缩监控需求。
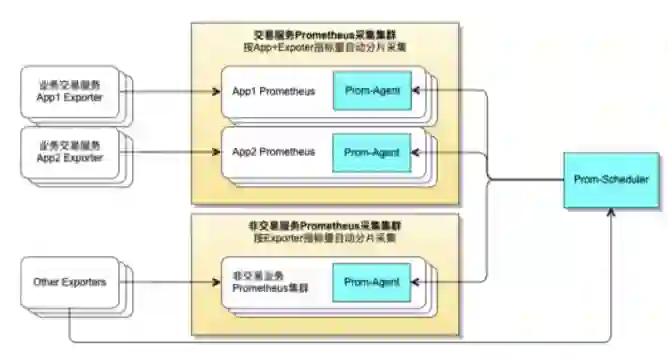
交易服务 Prometheus 采集集群:
针对包含业务指标的服务监控,采用按 App 自动分片采集,同一个 App 所属的实例 Exporter 分配在同一组 Prometheus 采集服务上
同一个 App 的指标能够基于预计算规则尽量减少量级。
对于非交易服务 Prometheus 采集集群:
通过计算每个 Exporter 产生的指标数量,负载均衡到 Prometheus 集群中,实现分片采集。
其中 Exporter 的指标量级,通过定期对目标端点进行探测,来获取指标量级的变化。
通过指标降维的方案实现了指标的减量,但不幸的是,减量后的指标量级,仍然超过了远端存储服务能够承载的上限。尤其是存储服务上的计算规则 (Record Rule) 和报警规则 (Alert Rule) 由于涉及数据量大,常处于超时状态。
因此我们引入了 Flink 构建流式计算服务,承接原有由存储服务支持的预计算和报警阈值检测能力,降低对于存储的查询时计算压力。
基于流式计算的特征,业务所提出的计算、报警低延迟的需求也同样得到了满足。
整体架构方案如下图所示:
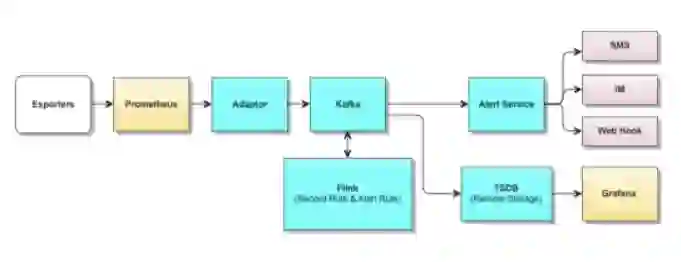
采集服务:
使用 Prometheus 作为采集服务,额外增加自动分片管理能力,实现对业务模块、中间件等 Exporter 进行自动发现与数据采集。
同时如上文所述,该部分同时会进行业务指标进行降维计算,使得发送到监控数据通路的数据进行。
转发服务:
Prometheus 数据发送到 Adaptor 服务,Adaptor 服务负责将 Prometheus 发送的数据,转发到 Kafka 对应的 topic 中。Flink 流式计算服务及存储服务可以从 Kafka 中订阅所需的数据。
转发服务同时构建了高可用数据去重的方案,该部分会在后续的文章中具体进行介绍。
流式计算服务:
基于 Flink 构建的流式计算服务,负责执行用户配置的 Record Rule 和 Alert Rule,将计算结果写回 Kafka。
在 Flink 算子的实现中,通过对原有的 Prometheus 算子针对流式计算进行并行化重写,实现了流式计算算力的提升。
存储服务:
远端存储服务使用了百度自研的时序数据存储方案,远端存储服务实现了 Prometheus remote-write 接口与 Kafka 订阅两种模式,满足不同场景的数据接入需求。
查询层,实现了与 Prometheus 兼容的 PromQL 查询引擎与接口实现。能够无缝对接 Grafana 等查询服务。
同时基于 Prometheus 的数据模型,增加了数据多层级降采样等特征,来满足长时间存储需求。
报警服务:
报警服务采用了百度自研的报警事件及通告管理服务,相比原生 Prometheus 中 AlertManager 偏薄弱的基础告警通知能力,自研的 Alert Service 对告警通知、告警处置、告警渠道管理,及 AIOps 故障分析定位能力进一步增强。满足用户告警处理需求。
在本文中,我们初步介绍了针对大规模的业务监控场景,百度云原生团队基于 Prometheus 技术方案进行的一些探索。包括基于 Prometheus 进行指标降维、Prometheus 的自动分片采集、以及基于 Flink 流式计算构建的预计算与报警规则替代方案。
在后续的系列文章中,我们将对该场景进一步进行分析,从数据采集、计算、存储和报警等各环节技术细节出发,继续探讨如何基于 Prometheus 构建高性能、低延迟、高可用的监控系统,敬请期待。
解读数据库的2021:资本进来添了一把火,开源已占据半壁江山
下载量和Vue一样大的开源软件被作者恶意破坏,数千款应用受到牵连
西安一码通半个月崩溃两次,被工信部点名;快手再传裁员:最高比例达 30%;阿里调整大淘宝组织架构 | Q 资讯
Apache Flink 不止于计算,数仓架构或兴起新一轮变革

点个在看少个 bug 👇



