NeurIPS 2018 AutoML Phase1 冠军队伍 DeepSmart 团队解决方案分享

近日,由第四范式、ChaLearn、微软和阿卡迪亚大学联合举办的 NeurIPS 2018 AutoML 挑战赛公布了最终结果:Feed-Back 阶段由微软与北京大学组成的 DeepSmart 团队斩获第一名,由 MIT 和清华大学组成的 HANLAB 斩获第二名,由南京大学 PASA 实验室斩获第三名。在 Blind Test 阶段由 Autodidact.ai,Meta_Learners,GrandMasters 斩获前三名。
作者丨罗志鹏
单位丨微软Bing搜索广告算法工程师
研究方向丨NLP、广告相关性匹配、CTR预估

DeepSmart Team介绍
罗志鹏:微软 Bing 搜索广告算法工程师,北京大学软件工程专业硕士,专注于深度学习技术在 NLP、广告相关性匹配、CTR 预估等方面的研究及应用。
黄坚强:北京大学软件工程专业硕士在读,擅长特征工程、AutoML、自然语言处理、深度学习。
团队成员曾经获奖记录:
CIKM Cup 2018 - 1st place
KDD Cup 2018 (Second 24-Hour Prediction Track) - 1st place
KDD Cup 2018 (Last 10-Day Prediction Track) - 1st place
Weibo Heat Prediction - 1st place
Shanghai BOT Big Data Application Competition - 1st place
Daguan Text Classification - 1st place
DeepSmart 团队在 Feed-Back 阶段的 5 项测试任务中斩获了 4 项第一、1 项第二的优异成绩,其中 4 项任务的 AUC 指标大幅度胜出。官方排名规则是把5个任务的 Rank(在所有队伍中的排名)值进行平均做为最后的排名依据,DeepSmart Team 的 Rank 平均指标为 1.2,在所有队伍中具有显著的领先优势。
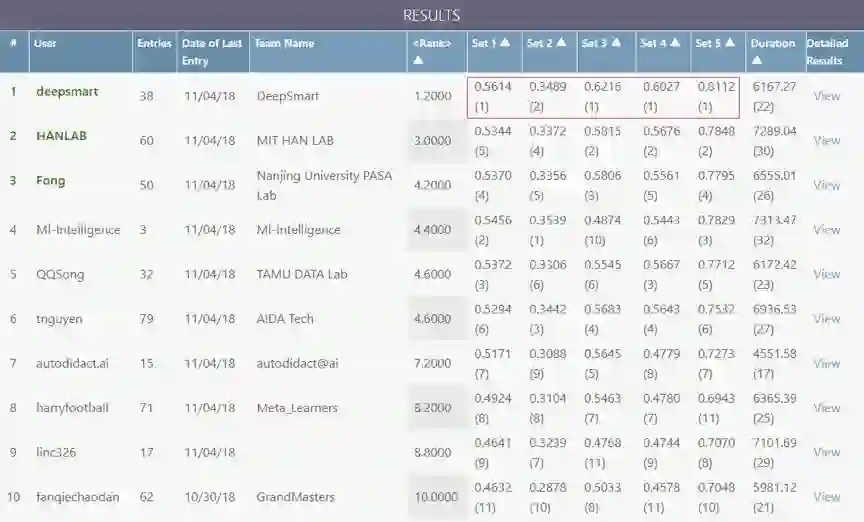
▲ 图1. Feed-Back阶段排行榜
榜单链接:
https://competitions.codalab.org/competitions/20203#results
大赛简介
许多实际应用程序的开发依赖于机器学习,然而这些程序的开发人员却并不都具备专业的机器学习算法研发能力,因而非常需要部署 AutoML 算法来自动进行学习。另外,有些应用中的数据只能分批次获取,例如每天、每周、每月或每年,并且数据分布随时间的变化相对缓慢。
这些原因要求 AutoML 具备持续学习或者终生学习的能力。这一类的典型问题包括客户关系管理、在线广告、推荐、情感分析、欺诈检测、垃圾邮件过滤、运输监控、计量经济学、病人监控、气候监测、制造等。本次 AutoML for Lifelong Machine Learning 竞赛将使用从这些真实应用程序中收集的大规模数据集。
相比于与之前的 AutoML 比赛,本次比赛的重点是概念漂移,即不再局限于简单的 i.i.d. 假设。要求参与者设计一种能够自主(无需任何人为干预)开发预测模型的计算机程序,利用有限的资源和时间,在终身机器学习环境下进行模型训练和评估。
这次竞赛主要有以下难点:
• 算法可扩展性:比赛提供的数据集比之前组织的竞赛大 10 到 100 倍;
• 不同的特征类型:包括各种特征类型(连续,二元,顺序,分类,多值分类,时间);
• 概念漂移:数据分布随着时间的推移而缓慢变化;
• 终身环境:本次比赛中包含的所有数据集按时间顺序分为 10 批,这意味着所有数据集中的实例批次按时间顺序排序(请注意,一批中的实例不保证按时间顺序排列)。参与者的算法需要基于前面批次的数据进行训练来预测后一批次的数据,从而测试算法适应数据分布变化的能力。测试后,才能把当前的测试集纳入训练数据中。
本次比赛分为 Feed-Back 阶段及 Blind-Test 阶段:
Feed-Back 阶段:反馈阶段是代码提交的阶段,可以在与第二阶段的数据集具有相似性质的 5 个数据集上进行训练。最终代码提交将转发到下一阶段进行最终测试。
Blind-Test 阶段:该阶段不需要提交代码。系统自动使用上一阶段的最后一次提交的代码对 5 个新数据集进行盲测。代码将自动进行训练和预测,无需人工干预。最终得分将通过盲测的结果进行评估。
Feed-Back阶段Top队伍方案具有重要价值
根据大赛主办方申明的规则,Blind-Test 阶段与 Feed-Back 阶段使用可比的数据集,在 Blind-Test 阶段,参赛者在 Feed-Back 阶段最后提交的代码将在 5 个新数据集进行盲测,但是最终 Top 6 中的第 1、2、3、5、6 名的队伍都因为内存超过 16G 的限制而未能在 Blind-Test 阶段得到有效成绩。
DeepSmart team 在 Feed-Back 阶段的 5 个数据集中内存使用峰值为 8G 左右,但是在 Blind-Test 中也因超出了 16G 的限制而无缘 Blind-Test 榜单。这导致 Feed-Back 阶段的许多有重要价值的解决方案由于内存溢出而在 Blind-Test 阶段拿不到得分而无法参与排名。
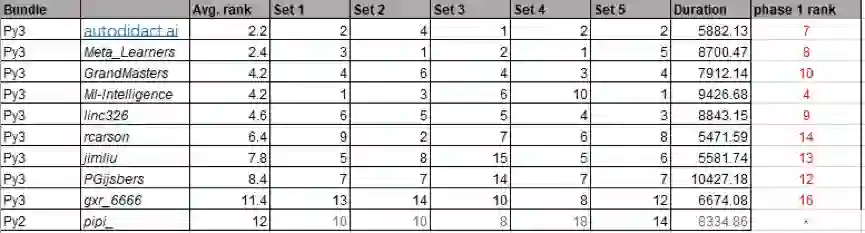
从 Blind-Test 榜单来看总的测试排名结果比较稳定,与 Feed-Back 差别不大,但由于 1、2、3、5、6 名在五个解决方案中某个更多特征或更大数据集的任务上因内存溢出而没有得分使得 autodidact.ai 从第 7 上升到第一名。

对比 DeepSmart 团队与 Blind-Test 阶段 Top 3 的队伍所取得的结果,在 5 项任务的平均 AUC 指标上 DeepSmart 比 Top 3 队伍分别高出 7.004%、8.488%、10.578%。与 Top 3 队伍表现最好的任务相比,DeepSmart 比 Top 3 队伍分别高出 4.01%、3.85%、6.11%。与 Top 3 队伍表现最差的任务相比,DeepSmart 比 Top 3 队伍分别高出 12.48%、12.47%、14.49%。
AUC 指标是一项相对而言很难提升的指标,通常在竞赛中 top 队伍只能在该指标上拉开千分位、万分位的差距,而 DeepSmart team 在 5 项任务中领先 Blind-Test 阶段 Top 3 队伍 3.85-14.49%,具有压倒性的优势。
从表格中也可以观察到 Feed-Back 的 5 个任务的平均 AUC 排名和 Blind-Test 基本保持一致,如果 Top 队伍能够获得得分最终 Blind-Test 榜单很可能会有巨大变化。
从以上分析来看,Feed-Back 阶段的解决方案具有重要价值,所以举办方承认了 Feed-Back 阶段的解决方案的价值,向前三名分别授予了奖牌和证书,并且邀请他们参加 NeurIPS 会议进行解决方案分享。虽然他们没有去现场分享,但在这里 DeepSmart 团队将把他们的解决方案分享给大家。

DeepSmart团队解决方案
我们团队基于所给数据实现了一个 AutoML 框架,包括自动特征工程、自动特征选择、自动模型调参、自动模型融合等步骤,并且利用了多种策略对运行时间进行了有效的控制,以确保解决方案能在限制时间内通过。然而出乎我们的意料,最终我们的解决方案却由于内存不足而无缘最终排行榜。
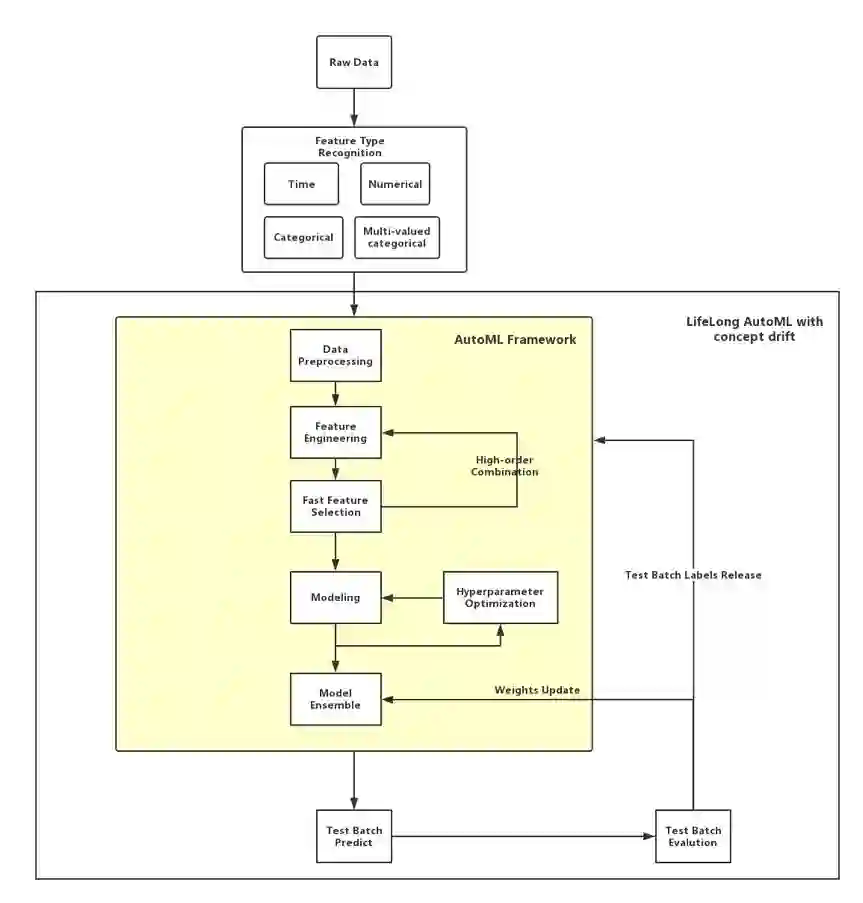
▲ 图2. DeepSmart AutoML框架
自动特征工程
目前,在大部分机器学习工业界应用中,数据和特征对于模型往往是最为关键的。在现有的 AutoML 框架中,大部分特征的提取是通过数值特征进行高阶组合,它们的模型很难提取出跟时序问题或者概念漂移有关的关键特征,然而现实中存在大量的时序问题,而且往往带有概念漂移。
我们构建的自动特征工程不仅是基于数值特征做横向高阶组合,同时我们基于分类变量、数值变量、时间变量、多值分类变量自动提取跨时间和样本的横向及纵向高阶组合。这是我们团队所做出的不同于以往模型的自动特征工程方案,同是也是我们在比赛中能取得显著优势的重要因素。
自动特征选择
高阶组合往往容易导致生成大量特征,但我们通过构建自动快速特征选择来提取重要特征,这能极大地加速我们的特征工程,同时也极大地减少模型所使用的特征总量。
自动模型调参
我们采用 GBDT 模型,通过验证集调整模型学习率、叶子结点、树的深度等。由于时间有限,我们只能进行较少次的模型调参及验证,这三个参数对于 GBDT 的影响较大,能取得较为显著的效果提升。
由于数据是极度不平衡的,有的数据集甚至只有几千个正样本,负样本却能达到几十万个。所以,我们在树提升的过程中使用了不同的行采样方法。
在现有的树提升模型中,他们对正负样本采用同一个行采样率来控制采样。我们使用不同的正负样本行采样率,以使得模型可以使用足够多的正样本和合适的负样本。它不仅可以大大减少模型的运行时间,同时模型也可以取得更好的效果。
自动模型融合
基于所给时间,我们使用不同的行采样及列采样来训练多个不同的模型,这不仅仅更加充分的利用了样本,也使得每个模型使用的数据和特征具有充分的差异性,同时大大减少了过拟合的风险。
总结
AutoML 的发展空间还很大,目前大部分工业界机器学习问题都需要专业人士不断重复特征工程、特征选择、模型调参及模型训练等过程,需要耗费大量的人力成本及时间成本才能产生一个较为有效的模型。
本次 AutoML 竞赛中,参赛者们不仅从竞赛中学到了很多,也间接地能推动了 AutoML 的发展。随着更多 AutoML 学术上的探讨以及相关比赛的出现,我们相信 AutoML 能在学术界及工业界中得到快速发展。我们将进一步完善这一 AutoML 框架,争取能够将其应用于更多实际问题中。
最后感谢主办方提供高质量的数据和竞赛平台,也给我们提供了在 AutoML 领域中学习和实践的机会。感谢所有的参赛选手,让我们不断努力把效果做到极致。祝贺所有的 Top 队伍!愿下一届 AutoML 竞赛办得更加成功!

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐

