【Kaggle冠军分享】图像识别和分类竞赛,数据增强及优化算法
1 新智元编译
来源:blog.kaggle.com
编译:贾岳鹏
【新智元导读】Kaggle 海洋鱼类识别和分类竞赛冠军团队技术分享:如何设计鲁棒的优化算法?如何分析数据并做数据增强?技术细节包括使用不同船只的图像进行验证,以及如何处理夜视图像。

今年,Kaggle 社区举办了大自然渔业监测大赛(Nature Conservancy Fisheries Monitoring competition),征召参赛者开发能够自动对渔船捕捞的海洋生物种类进行检测和分类的算法。
非法捕鱼等行为对海洋生态系统构成了威胁。这些算法将有助于增强大自然保护协会分析摄像机监控系统数据的能力。在下面这篇获奖者访谈中,冠军队伍“Towards Robust-Optimal Learning of Learning”(Gediminas Pekšys,Ignas Namajūnas,Jonas Bialopetravičius)分享了他们算法的技术细节,比如如何使用不同船只的图像进行验证,以及如何处理夜视图像。
由于比赛数据集中的照片不能公开,团队招聘了平面设计师 Jurgita Avišansytė 为此博文制作了插图。
在进入这个挑战赛之前,你的背景是什么?
P:剑桥数学毕业,做了大约 2 年的数据科学家/顾问,约 1.5 年的软件工程师,作为监控应用研究工程师大约有 1.5 年的物体检测研究和框架开发经验。
N:数学本科,计算机科学硕士和 3 年研发工作,在 9 个月的监控项目研究负责人经验。
B:软件工程学士,计算机科学硕士,6 年计算机视觉和机器学习专业经验,目前正在研究天体物理学,对应用深度学习方法十分感兴趣。
有什么以前的经验或领域知识帮助你在这场比赛中取得了成功?
P:我上次参加 Kaggle 比赛获得的工作和研究经验帮助了我参加这次竞赛,也即在第一周的时间里建立合理的验证方法。
N:我在大学学习(主要是自学)、研发的工作经验,还有前两次 Kaggle 计算机视觉竞赛的经验,以及每天阅读 arXiv 论文。
B:我的硕士论文是关于深度学习的,我也有一些 Kaggle 竞赛经验。我在工作中定期解决计算机视觉问题。
你是如何开始参与 Kaggle 竞赛的?
P:我第一次听说 Kaggle 是在我成为数据科学家第一年的时候,但在我转为从事计算机视觉之后几年后才开始考虑参赛。Kaggle 竞赛能让人专注于稍微不同的问题/数据集,并有效地验证不同的方法。
N:我曾经喜欢参与 ACM ICPC 等竞赛。我没有取得特别值得一提的成就,但作为维尔纽斯大学团队成员参加国际比赛是我的学生生涯中最好的体验。在开始从事机器学习和计算机视觉工作后,我喜欢上了长期的挑战赛,所以 Kaggle 再适合不过。
B:我喜欢解决机器学习问题,而 Kaggle 正是做这个的平台。
是什么让你决定参赛的?
P:我想为计算机图像检测和分类做更多的堆叠和定制模型的实验。我还想要比较最近的检测框架/体系结构。
N:对象检测是我的强项之一,这个问题看上去很有挑战性,因为成像条件“in the wild”程度很高。
B:主要是因为这场比赛看起来难度很高,特别是缺乏好的数据。
你们从以前的研究或比赛中借鉴了什么方法吗?
借鉴了 Faster R-CNN,它在以前参赛中表现很好,我们也有使用和修改它的经验。
使用了什么监督学习方法?
我们主要使用带 VGG-16 的 Faster R-CNN作为特征提取器,其中一个模型是用的带 ResNet-101 的 R-FCN。
数据预处理和数据增强是怎么做的?
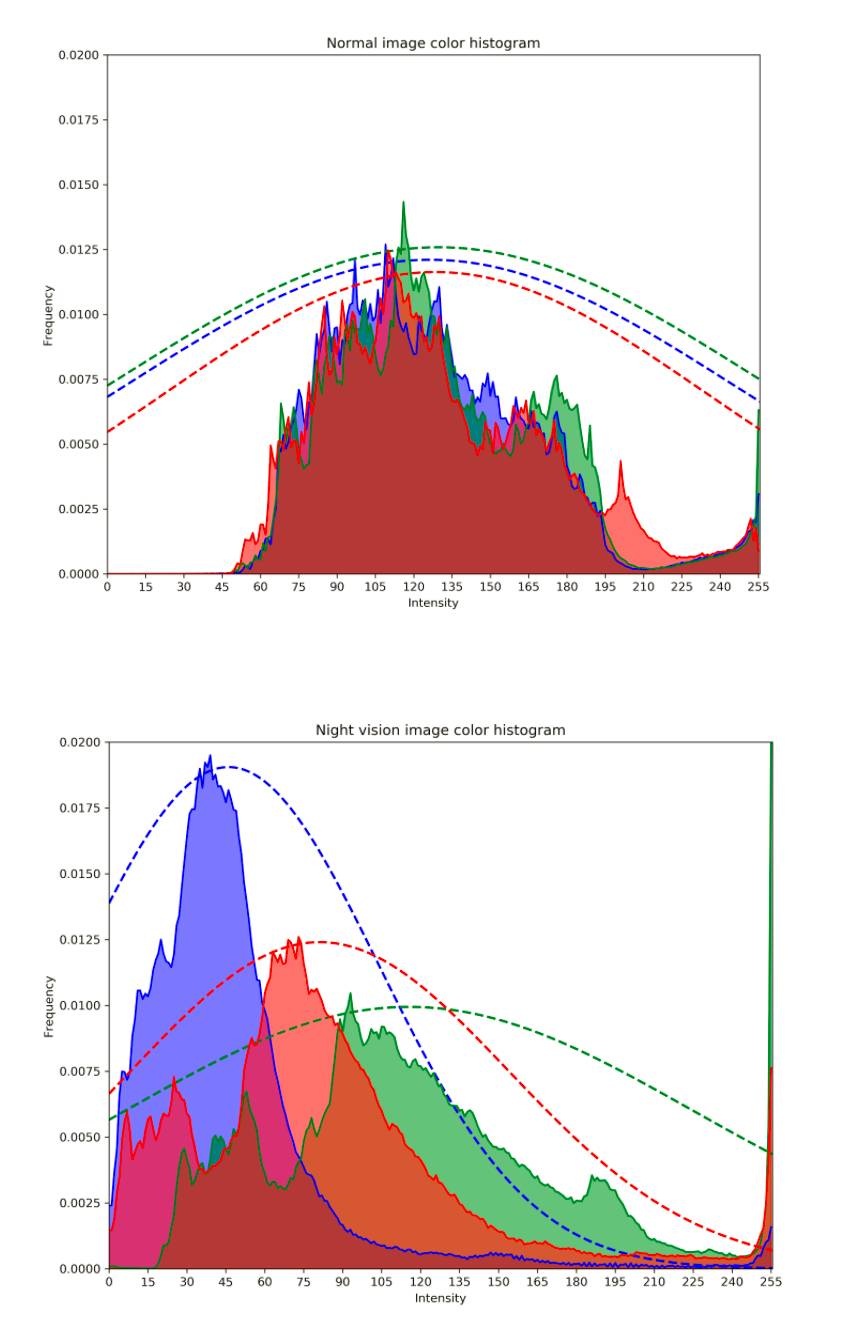
大多数用于训练模型的增强管道都是相当标准的。随机旋转,水平翻转,模糊和尺度变化我们都用了,这些方法也都提高了验证分数。然而,最重要的两件事情是使用夜视图像和图像颜色。
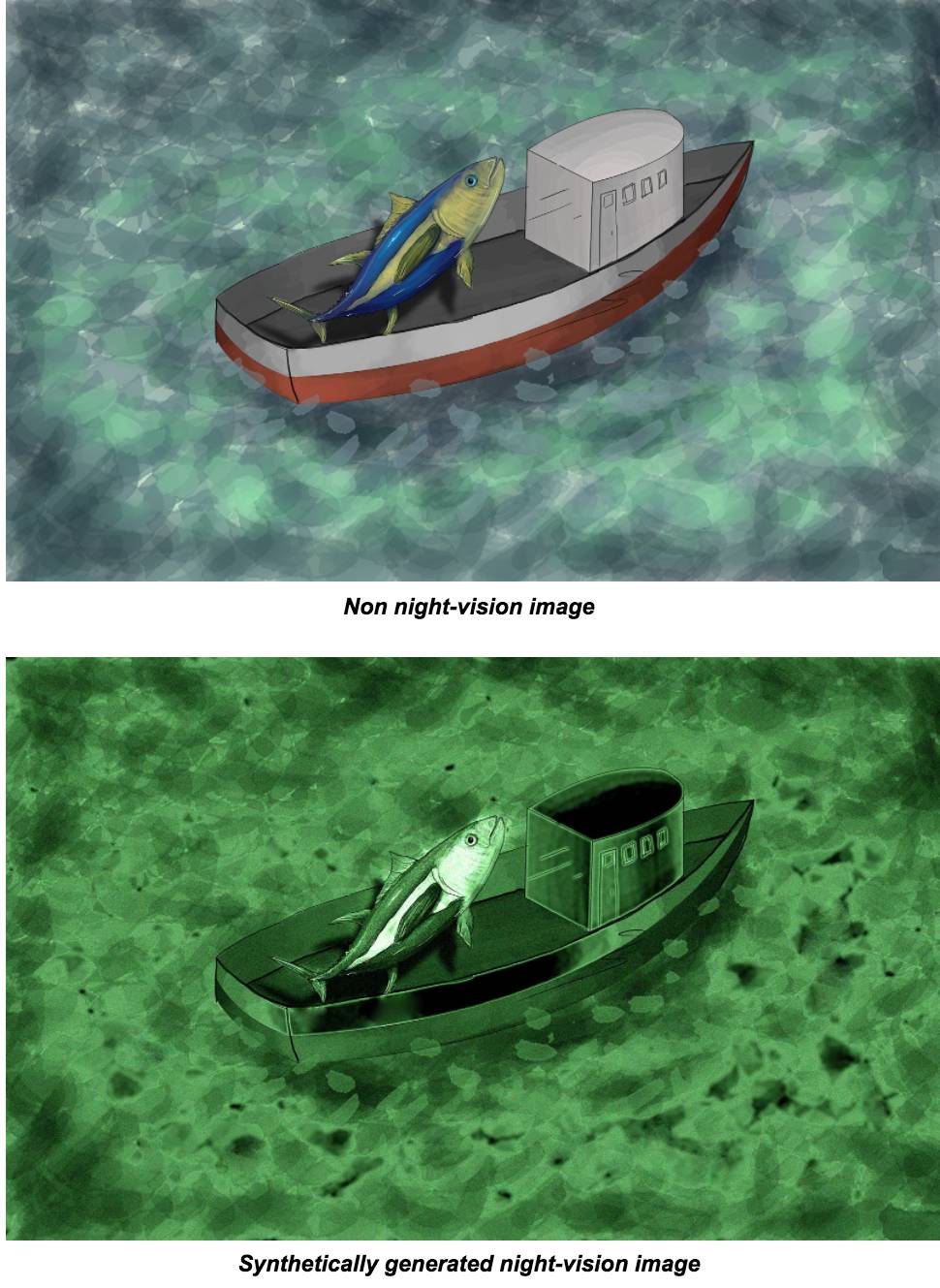
我们在早期注意到,夜视图像真的很容易识别——只需检查绿色通道的平均值是否比红色和蓝色通道两者相加的均值更亮就行了,加权系数为 0.75,在所有情况下都适用。观察典型正常图像和夜视图像的颜色强度直方图,可以清楚地发现差异,因为常规图像的颜色分布通常彼此相近,这可以从下图中看出。虚线表示近似这些分布的最佳拟合高斯。
我们想要增加更多的夜视图像。因此,最终的一个模型,也是最后成绩最好的单一模型,随机分配了一些训练图像,并且扩展了直方图,使其更接近于夜视图像。这是针对每个颜色通道分别完成的,并假设是高斯的(实际情况并不是高斯的),并且相应地修改了平均值和标准偏差——基本上就是缩小红色和蓝色通道,从图中可以看出。之后我们也分别对每个颜色通道进行了随机的对比度拉伸。因为夜视图像本身可能是非常多样的,而固定变换无法体现这种变化。
因为这个模型性能非常好,我们还添加了一个不单独使用夜视图像的模型,但却加长了所有图像的对比度。因为这是分别在每个通道上完成的,可能会改变鱼类或周围环境的颜色。由于数据中海洋里光照条件变化多端,真实图像中的颜色不太稳定,所以这种方法结果看上去还是很好的。
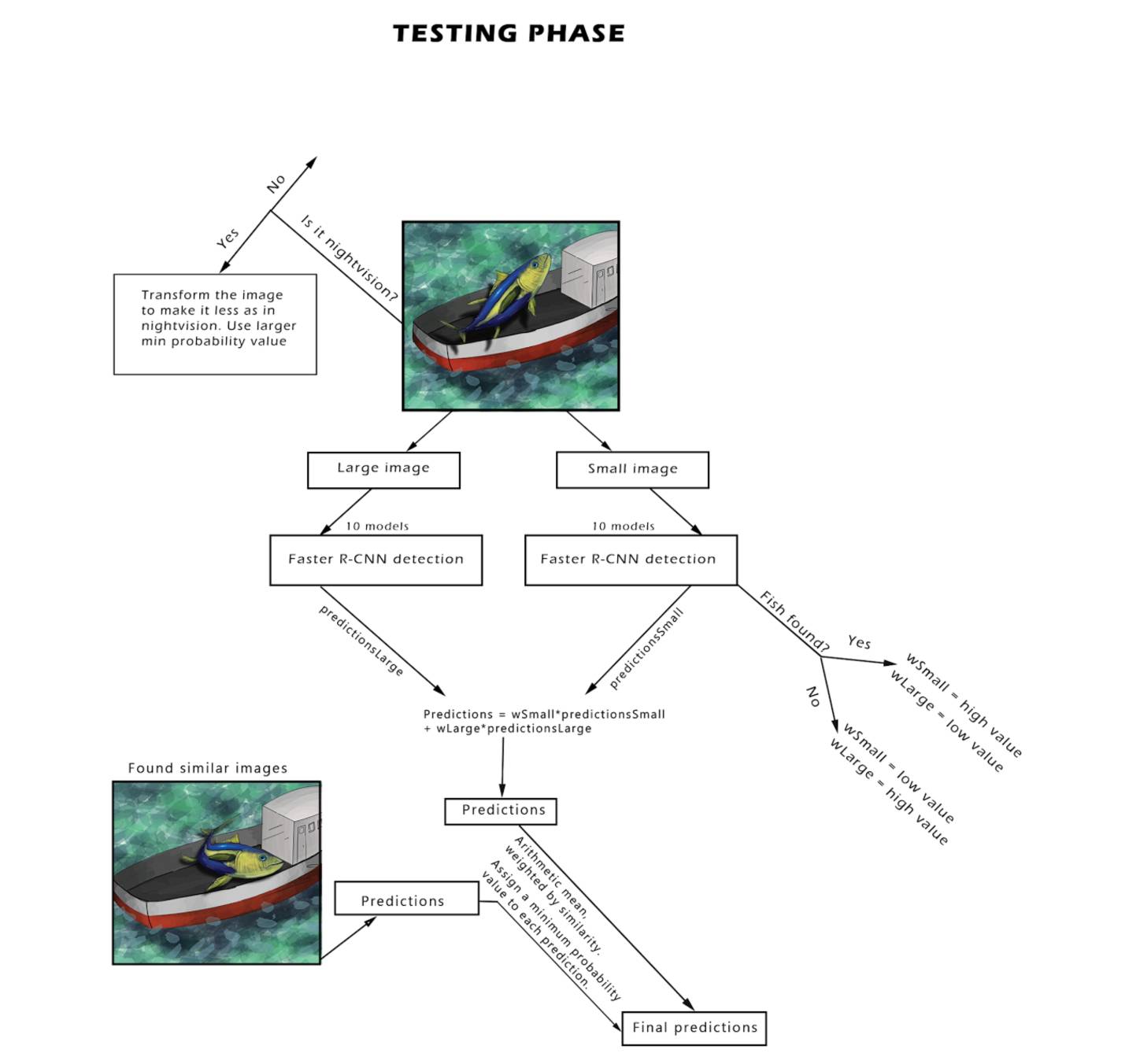
比赛中,关于数据方面,你们最重要的看法是什么?
首先,必须具有包含来自不同船舶的图像的验证集,而不是训练集中的图像,否则模型可以根据船舶特征学习分类鱼类,这虽然不会在验证分数上有所体现,但可能会导致 stage2 测试集的精确度下降。
其次,整个数据集中鱼的大小都非常不同,因此对这一点进行处理显然是有用的。
第三,有大量的夜视图像具有不同的颜色分布,因此用不同的方式处理夜视图像也提高了我们的分数。
更重要的是,其他团队在论坛上发布的附加数据似乎包含了很多这样的图像,其中的鱼看起来与放在船上的鱼看起来不一样,因此过滤掉这部分数据很重要。
最后,我们对原始训练图像进行了多边形注释,这有助于我们在旋转图像上实现更准确的边界框,否则图像将包含很多背景(如果旋转框的边框被视为基本真实的)。
你们使用了哪些工具?
我们使用从定制的存储库 py-R-FCN(包括 Faster R-CNN)代码:https://github.com/Orpine/py-R-FCN 。
你们在这次比赛中都做了哪些事情?
我们花了一些时间注释数据,从论坛上发布的图像中找到有用的附加数据,找到正确的扩充来训练模型,查看生成的验证图像预测,然后查看模型可能学到的任何虚假模式。
你们的硬件设置是什么样的?
两台 NVIDIA GTX 1080,一台 NVIDIA TITAN X
你们获胜解决方案的训练和预测运行时间分别是多少?
非常粗略的估计,GTX 1080 训练大约 50 小时,预测每个图像 7-10 秒。我们最好的单一模型其实比整个系统更加精确,可以在 4 小时内训练,需要 0.5 秒进行预测。
对刚入门数据科学的人有什么建议吗?
先阅读介绍类的材料,然后逐渐开始阅读论文,尝试自动动手解决机器学习问题,培养直觉,检查训练好的模型,努力去了解出了什么问题。计算机视觉问题对于练手来说相当不错。学习享受机器学习过程要付出长期的努力,保持兴趣才能保持动力。Kaggle 是学习机器学习的完美平台。
编译原文:http://blog.kaggle.com/2017/07/07/the-nature-conservancy-fisheries-monitoring-competition-1st-place-winners-interview-team-towards-robust-optimal-learning-of-learning/

点击阅读原文查看新智元招聘信息