【重磅】最后一届ImageNet榜单出炉:颜水成等中国团队夺多项冠军
1 新智元报道
报道:张易 胡祥杰 文强
【新智元导读】2017年ImageNet (ILSVRC2017)的比赛结果新鲜出炉:在物体检测(识别)、物体定位、视频物体检测三个大类中,南京信息工程大学和帝国理工学院组成的 BDAT 团队、新加坡国立大学与奇虎360合作团队、伦敦帝国理工学院和悉尼大学合作的团队分别拿下冠军。根据此前的消息,本届大规模视觉识别挑战赛(ILSVRC)将是最后一届比赛。

来自ImageNet官方网站的最新消息,2017年ImageNet Large Scale Visual Recognition Challenge 2017 (ILSVRC2017)的比赛结果新鲜出炉:在物体检测(识别)、物体定位、视频物体检测三个大类的竞赛中,南京信息工程大学和帝国理工学院组成的 BDAT 团队、加坡国立大学与奇虎360合作团队、伦敦帝国理工学院和悉尼大学合作的团队分别拿下冠军。
根据此前的消息,本届大规模视觉识别挑战赛(ILSVRC)将是最后一届,以后的比赛将会超越“识别”,往“理解”上发展。
1、物体检测(object detection)
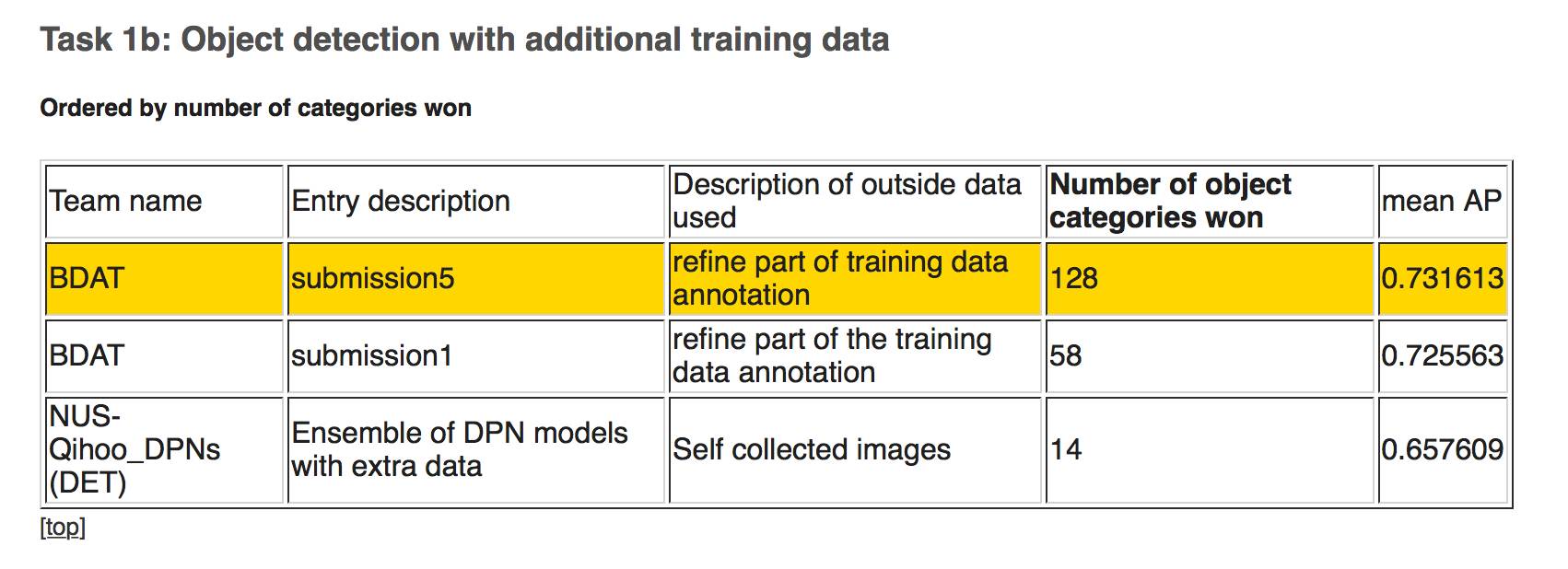
下图,任务1a,用提供的训练数据进行物体检测,前三名都被由南京信息工程大学和帝国理工学院组成的 BDAT 团队包揽,其中 submission4 排在第一,探测物体胜出种类数量 85,平均 AP 0.731392。
BDAT 代表队的人员组成如下:
来自南京信息工程大学:Hui Shuai、Zhenbo Yu、Qingshan Liu、Xiaotong 、Kaihua Zhang、Yisheng Zhu、Guangcan Liu、Jing Yang来自帝国理工学院:Yuxiang Zhou、Jiankang Deng

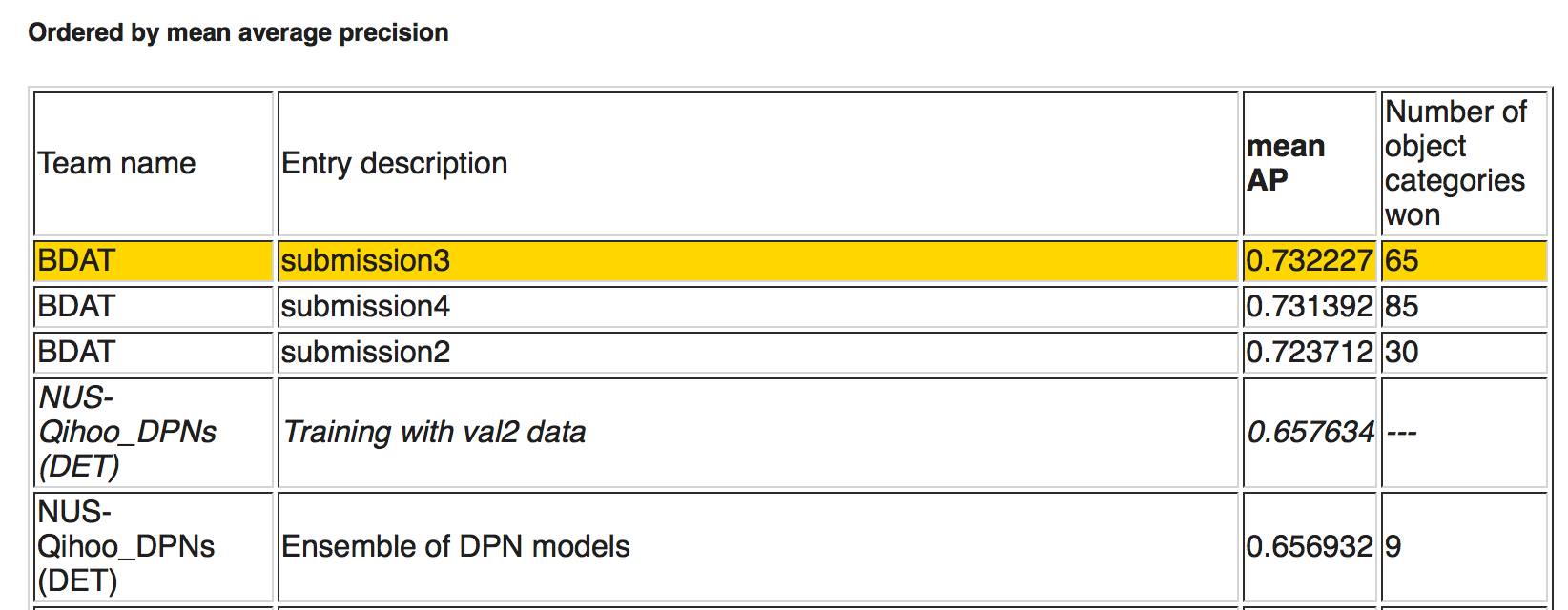
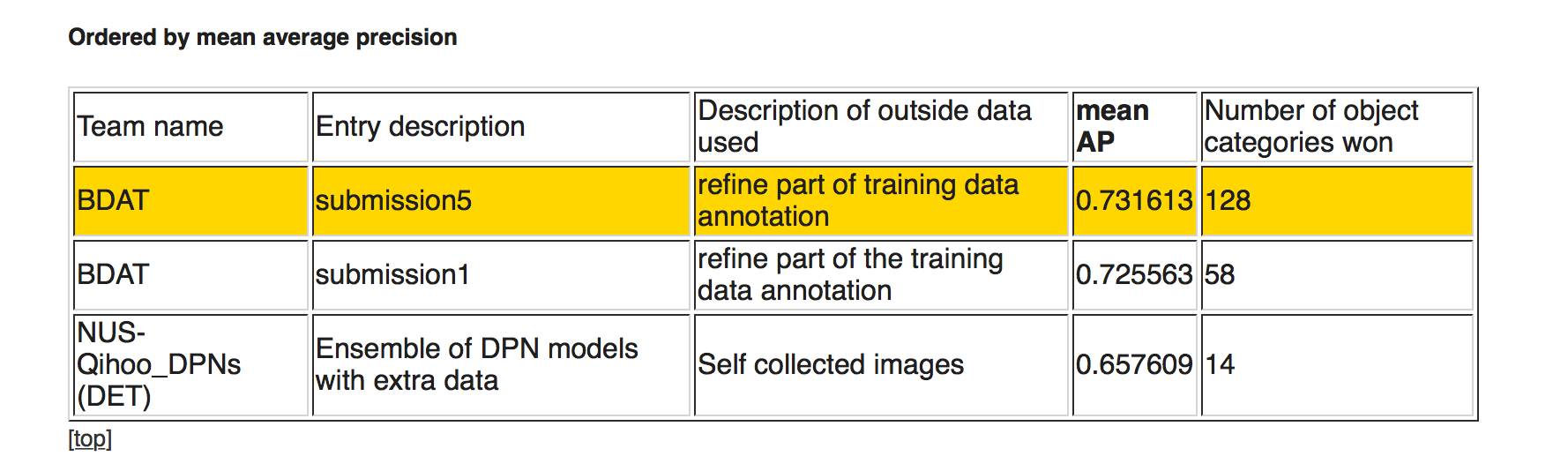
下图,任务1b,使用额外训练数据进行物体探测。前两名由南京信息工程大学和帝国理工学院组成的 BDAT 代表队包揽,使用处理过的标签数据(refine part of training data annotation)。其中 submission5 排在第一,识别物体胜出种类数量 128 个,平均 AP 0.731613。排在第三位的是由新加坡国立大学和奇虎 360 组成的 NUS-Qihoo_DPNs (DET),识别物体胜出种类数量 14 个,平均精度 0.657609.
2.物体定位
下图,任务2a:使用训练数据进行分类+定位
根据定位错误率排列,第一名“NUS-Qihoo_DPNs (CLS-LOC)”是新加坡国立大学与奇虎360 合作提出的 DPN 双通道网络 + 基本聚合,定位错误率为 0.062263。第二名、第三名都来自 Trimps-Soushen(公安部三所)。
其中,新加坡国立大学与奇虎 AI 研究院合作,指出 ResNet 是 DenseNet 的一种特例,深入探讨了各自优缺点并提出了一类新的网络拓补结构,也就是双通道网络(Dual Path Network,DPN)。在 ImageNet-1k 分类任务中:该网络不仅提高了准确率,还将200 层 ResNet 的计算量降低了 57%,将最好的 ResNeXt (64x4d) 的计算量降低了25%;131 层的 DPN 成为新的最佳单模型,并在实测中提速约 300%。(模型及代码:github.com/cypw/DPNs)
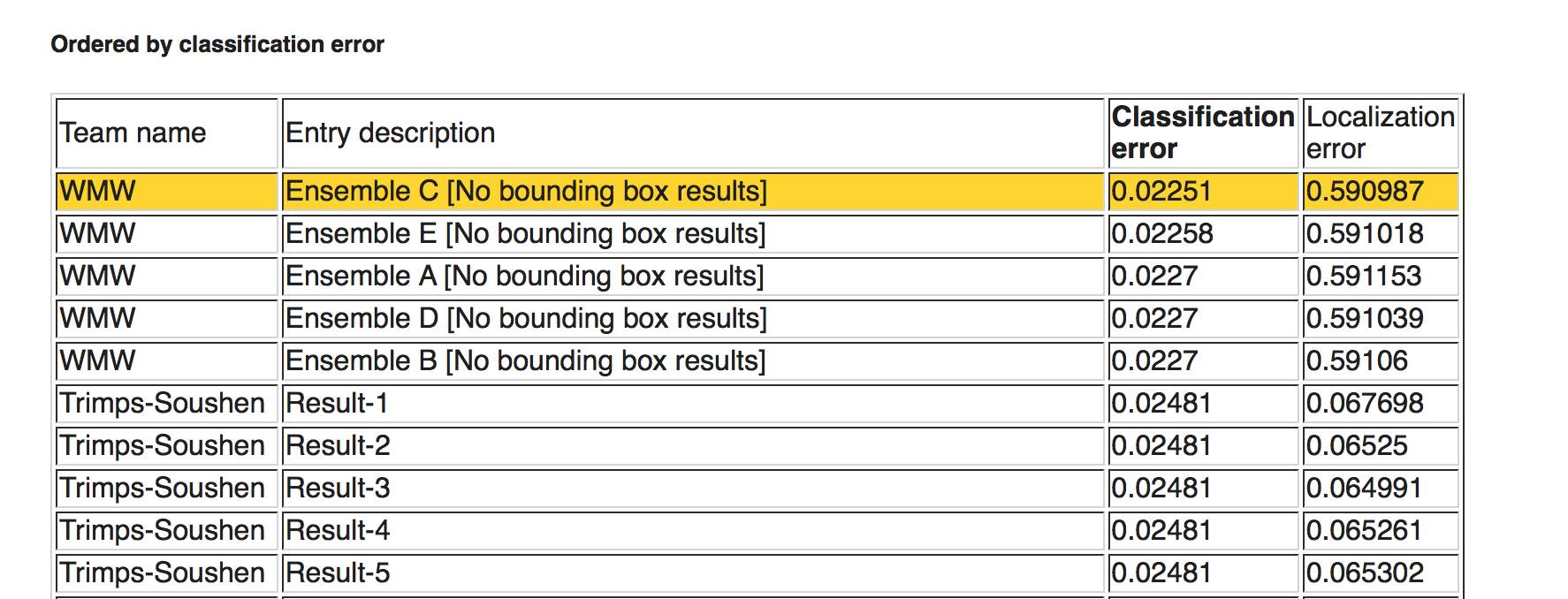
按照分类错误(从少到多),第一名是 WMW,这是 Momenta 与牛津大学合作提出的架构。据介绍,作者设计了一个名为“挤压激励(Squeeze-and-Excitation,SE)”的架构。每个模块通过“挤压”操作嵌入来自全局感受野的信息,并且通过“激励”操作选择性地诱导响应增强。作者在 SE 模块的基础上,开发了多个版本的 SENet,比如 SE-ResNet,SE-ResNeXt 和 SE-Inception-ResNet,在验证集上实现了前 5 个错误率 2.3%。

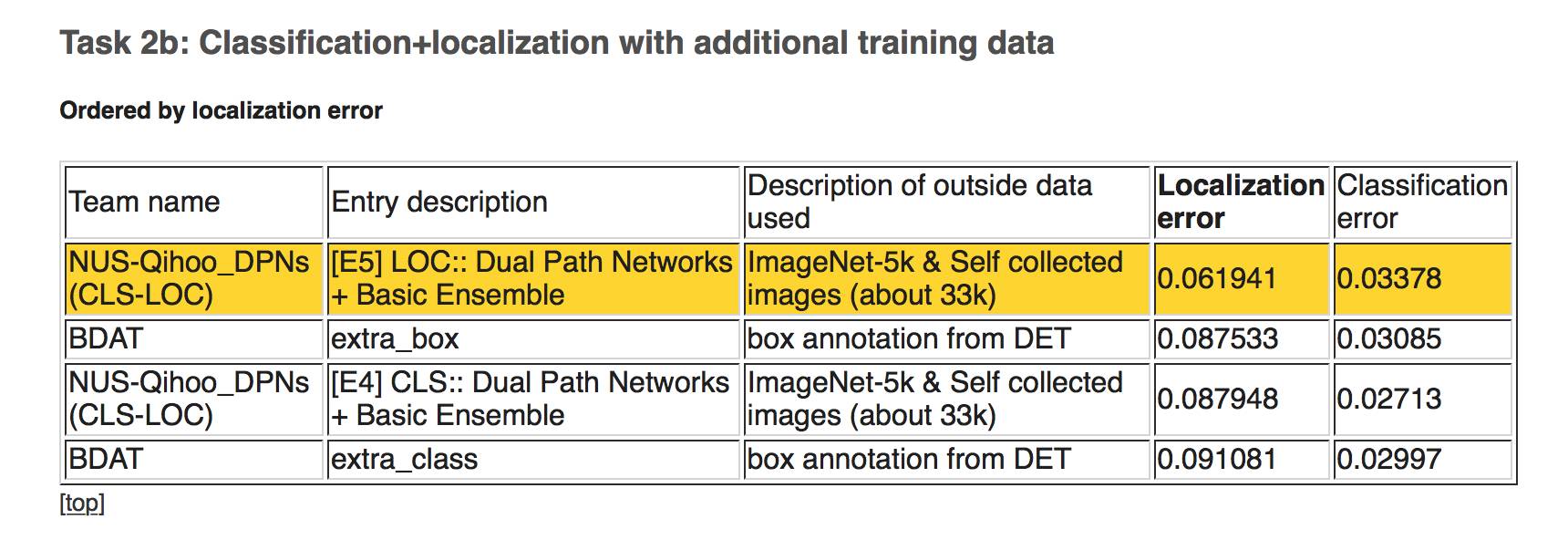
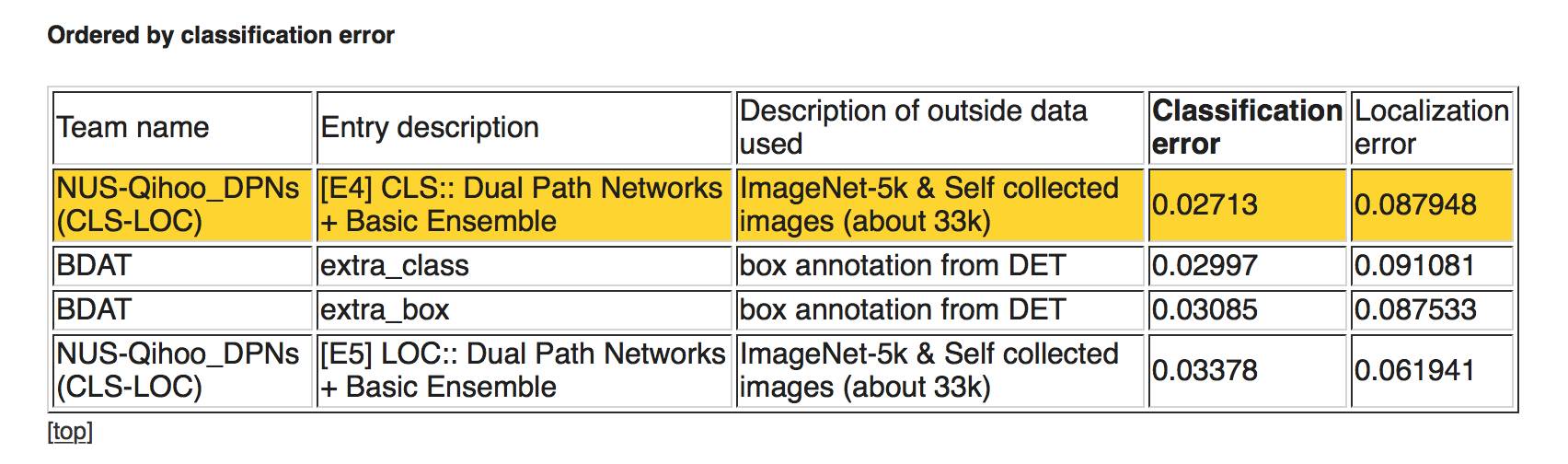
下图,任务 2b:使用额外训练数据进行分类 + 定位
按照定位错误率排列,第一名仍然是新加坡国立大学与奇虎 AI 研究院的 DPN。第二名是南京信息工程大学与伦敦帝国理工大学合作的 BDAT。
按照分类错误率排列,结果也类似。第一名是 DPN,第二、第三名是 BDAT。
3.视频中的物体识别
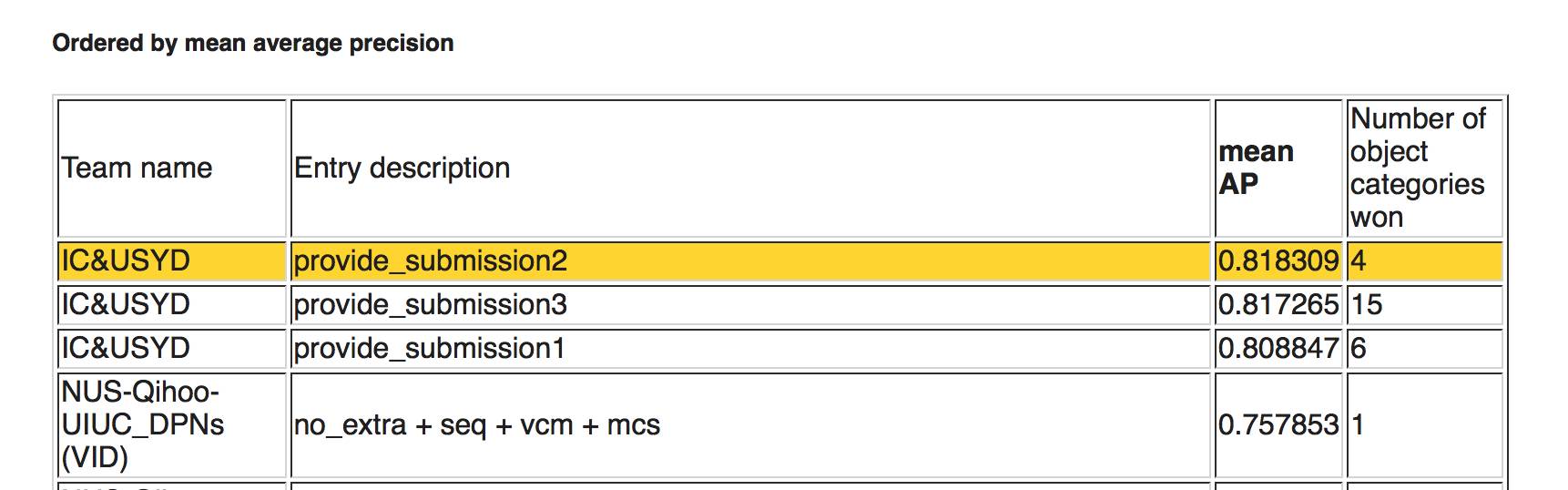
下图,任务3a:给定训练数据条件下的视频物体识别
排名(按照识别出的物体种类)
第一名、第二名和第三名:IC&USYD(伦敦帝国理工学院和悉尼大学合作)
第一名成绩是15个,第二名是6个,第三名是4个
按照平均准确率排名,前三名也是伦敦帝国理工学院和悉尼大学合作的团队IC&USYD。
IC&USYD团队成员:
Jiankang Deng, Yuxiang Zhou, Baosheng Yu, Zhe Chen, Stefanos Zafeiriou, Dacheng Tao

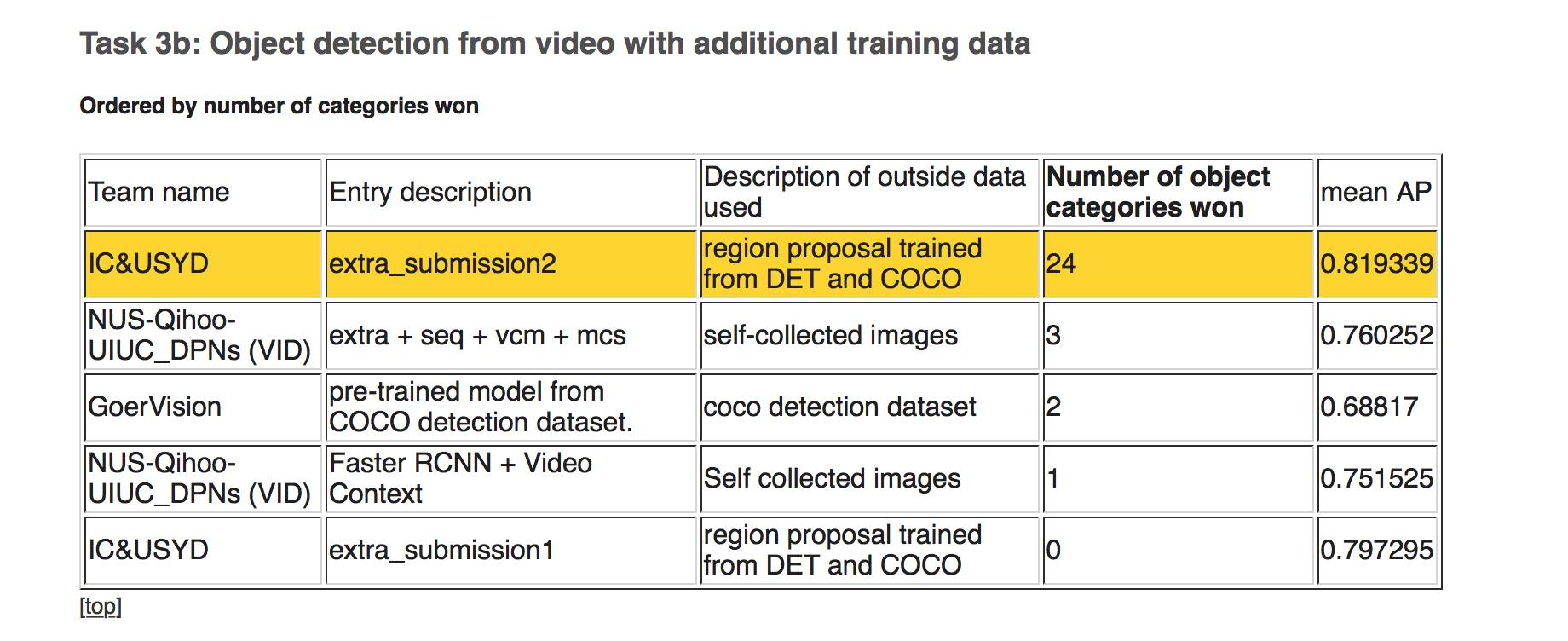
下图,任务3b:额外训练数据条件下的视频物体识别
第一名:IC&USYD ;识别物体数量:24
第二名:NUS-Qihoo-UIUC_DPNs (VID)(新加坡国立大学、奇虎360、美国伊利诺伊大学香槟分校合作团队);识别物体数量:3
第三名:GeorVision(歌尔声学、南洋理工大学、清华大学、加利福尼亚大学(伯克利)、北航大学、密西根大学(安阿伯市)合作);识别物体数量:2
GeorVision团队成员:Yejin Chen, Chunshan Bai, Zhuo Chen, Le Ge, Chengwei Li, Shuo Xu, Yuxuan Bao, Lu Bai, Xinyi Sun, Shun Yuan, Xiangdong Zhang
按照平均准确率排名:
第一名和第二名都是IC&USYD;第三名NUS-Qihoo-UIUC_DPNs (VID)
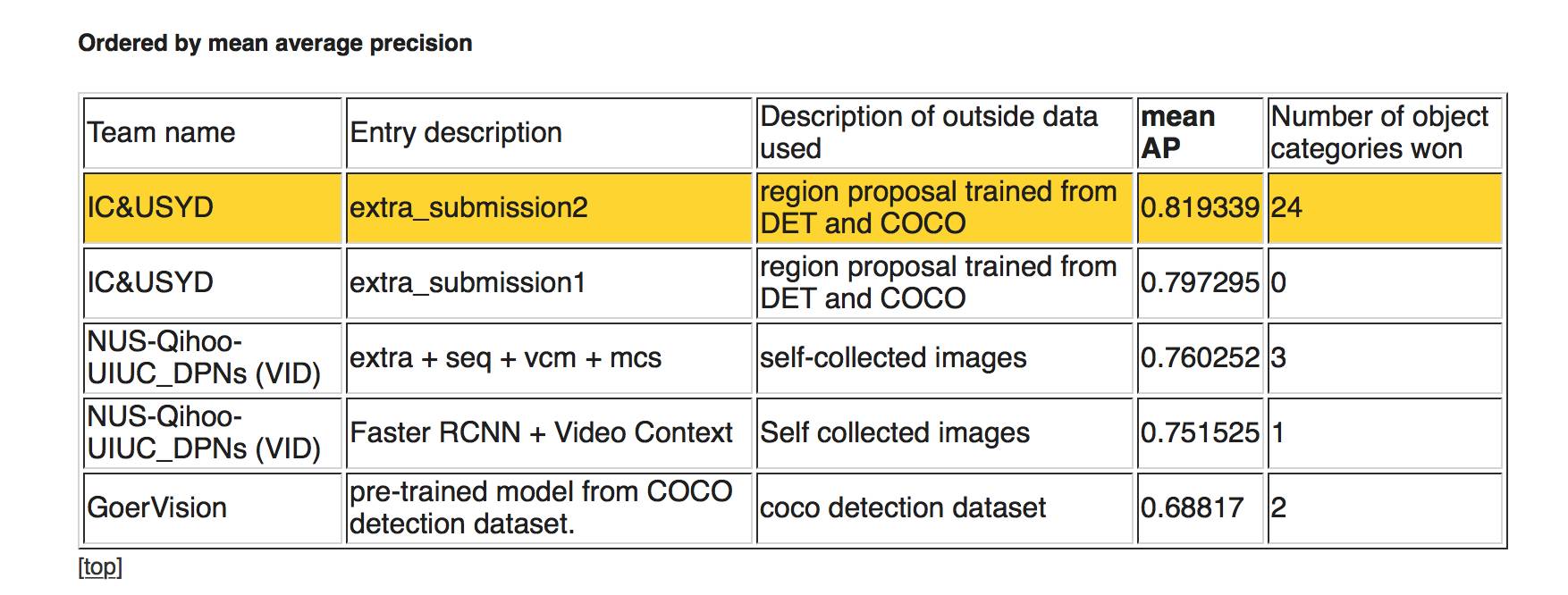
下图,任务3c:给定训练数据条件下的视频物体识别/追踪
第一名:IC&USYD ;平均准确率:0.641474
第二名:IC&USYD;平均准确率:0.544835
第三名:NUS-Qihoo-UIUC_DPNs ,平均准确率:0.544536
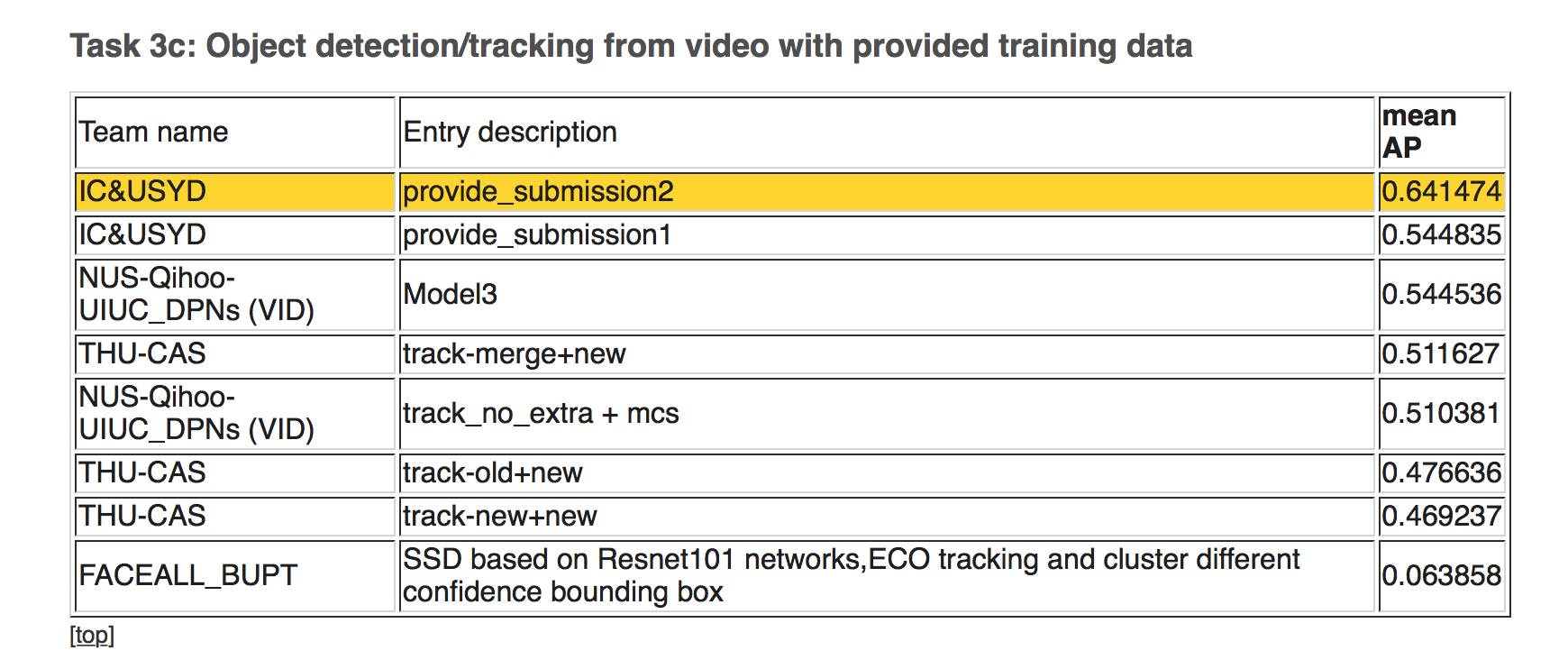
下图,任务3d:额外训练数据条件下的视频物体识别/追踪
第一名:IC&USYD ;平均准确率:0.642935
第二名:IC&USYD;平均准确率:0.57749
第三名:NUS-Qihoo-UIUC_DPNs(VID)0.550078

根据ImageNet官方网站的消息:
2017 年 7 月 26 日,计算机视觉顶会 CVPR 2017 同期举行的 Workshop——“超越 ILSVRC”(Beyond ImageNet Large Scale Visual Recogition Challenge),将宣布计算机视觉乃至整个人工智能发展史上的里程碑——ImageNet 大规模视觉识别挑战赛将于 2017 年正式结束,此后将专注于目前尚未解决的问题及以后发展方向。
根据“超越 ILSVRC” Workshop 官网介绍,这堂研讨会的内容主要包括以下 4 点:
发表 2017 年 ILSVRC 的结果
评估 ILSVRC 2017 图像、视频物体识别、分类的当前最佳结果
探讨这与当前在计算机视觉产业中应用的最优技术的关系
受邀讲者(目前确定的有加州大学伯克利分校的 Jitendra Malik,以及斯坦福大学教授、目前谷歌云首席科学家李飞飞)发表讲话,论述在他们看来从认知视觉到机器人视觉等领域存在的挑战
从下图中可见,无论的图像分类、物体检测、物体识别,计算机的正确率都已经远远超越人类。可以说,计算机视觉在感知方面的问题已经得到了很好的解决。
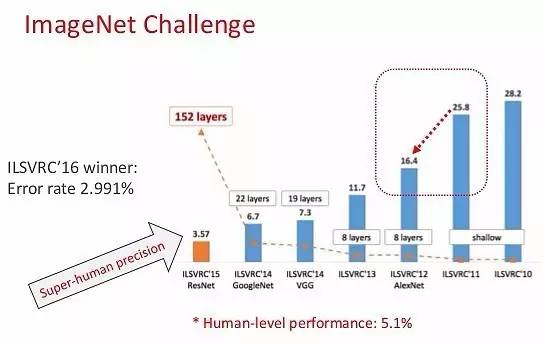
那么,计算机视觉的未来的重点将是什么,ImageNet 竞赛之后,又会出现什么呢?
WebVision 竞赛
WebVision 数据集是通过苏黎世科技大学计算机视觉实验室的网络数据团队收集的。这一数据集的开发得到了谷歌研究院苏黎世分部的支持。
WebVision 数据集使用与 2012 年 ImageNet 竞赛相同的 1000 个类别,涵盖了直接从网络收集到的 240 万张现代图像(包括谷歌图像搜索中获得的 100 万张,以及来自 Flickr 的 140 万张图像)和元数据。

在 CVPR 2017 上,也会举办 WebVision Challenge,这一比赛更加注重对图像和视频数据的学习和理解,它有可能会成为未来的 ImageNet 竞赛吗?

摘要
我们提出 2017 年 WebVision 竞赛,这是一项公开的图像识别挑战赛,旨在基于网页图像进行深度学习,而无需人手工对实例进行标注。此前的计算机视觉挑战赛,如 ILSVRC、Places2 和 PASCAL VOC,通过提供大量的注释数据,用于模型设计和标准化的基准测试,为计算机视觉的发展发挥了关键作用。为了延续它们的精神,我们在本届 CVPR 2017 举办研讨会,进行一项基于大规模网络图像数据集的公开竞赛。WebVision 数据集包含从互联网上用爬虫收集的 240 多万的网络图像,方法是使用从 ILSVRC 2012 基准中的 1000 个语义概念生成的查询(query)。元信息(Meta information)也包含在内。
此外,WebVision 数据集也提供检验数据集和测试数据集,这些数据集中的数据都带有人手工标注的标签,从而便于算法的开发。2017 年 WebVision 挑战赛分为两类,一是在 WebVision 测试数据集上进行图像分类,以及在 PASCAL VOC 2012 数据集上进行迁移学习。在本文中,我们描述了数据收集和注释的细节,突出了 WebVision 数据集的特点,并介绍了相关评估指标。
ImageNet 可以说是计算机视觉研究人员进行大规模物体识别和检测时,最先想到的视觉大数据来源。ImageNet 数据集最初由斯坦福大学李飞飞等人在 CVPR 2009 的一篇论文中推出,并被用于替代 PASCAL 数据集(后者在数据规模和多样性上都不如 ImageNet)和 LabelMe 数据集(在标准化上不如 ImageNet)。

ImageNet 从 Caltech101(2004 年一个专注于图像分类的数据集,也是李飞飞开创的)。ImageNet 不但是计算机视觉发展的重要推动者,也是这一波深度学习热潮的关键驱动力之一。
截至 2016 年,ImageNet 中含有超过 1500 万由人手工注释的图片网址,也就是带标签的图片,标签说明了图片中的内容,超过 2.2 万个类别。其中,至少有 100 万张里面提供了边框(bounding box)。
ImageNet 数据集中“猎狐犬”的部分示例
从 2010 年以来,ImageNet 每年都会举办一次软件竞赛,也即 ImageNet 大规模视觉识别挑战赛(ILSVRC),参赛程序会相互比试,看谁能以最高的正确率对物体和场景进行分类和检测,不仅牵动着产学研三界的心,也是各团队、巨头展示实力的竞技场。
从 2010 年以来,每年的 ILSVRC 都主要包括以下 3 项,后来逐渐增多:
图像分类:算法产生图像中存在的对象类别列表
单物体定位:算法生成一个图像中含有的物体类别的列表,以及轴对齐的边框,边框指示每个物体类别的每个实例的位置和比例
物体检测:算法生成图像中含有的物体类别的列表,以及每个物体类别中每个实例的边框,边框表示这些实例的位置和比例。
2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 创造了一个“大型的深度卷积神经网络”,也即现在众所周知的 AlexNet,赢得了当年的 ILSVRC。这是史上第一次有模型在 ImageNet 数据集表现如此出色。论文中提出的方法,比如数据增强和 dropout,直到现在也在使用,那篇论文“ImageNet Classification with Deep Convolutional Networks”,迄今被引用约 7000 次,被业内普遍视为行业最重要的论文之一,真正展示了 CNN 的优点,并且以破纪录的比赛成绩实打实地做支撑。
2012 年是 CNN 首次实现 Top 5 误差率 15.4% 的一年,当时的次优项误差率为 26.2%。这个表现震惊了整个计算机视觉界。可以说,是自那时起,CNN 才成了家喻户晓的名字。
ImageNet 历届冠军及技术回顾:
| 模型 |
AlexNet | ZF Net | GoogLeNet |
ResNet |
|---|---|---|---|---|
| 时间(年) | 2012 | 2013 | 2014 | 2015 |
| 层数(层) | 8 | 8 | 22 | 152 |
| Top 5 错误率 |
15.4% | 11.2% | 6.7% | 3.57% |
| 数据增强 | √ | √ | √ | √ |
| Dropout | √ | √ | ||
| 批量归一化 | √ |




