听说你想入坑AI,作为过来人我有几条建议给你
编者按:本文作者Tom Silver是MIT的博士生,并且已有两年AI工作的经验。最近,他在自己的博客上发表了文章,面向所有AI爱好者给出了一些具体的建议,包括学习和生活方面,希望对学生和职场小白有用。以下是论智对原文的编译。
注:Tom Silver本科毕业于哈佛大学计算机和数学专业,之后在Vicarious AI工作了两年,现在是MIT EECS的一名博士生。
最近我的一位朋友想从事人工智能研究,他向我求助,让我就自己的学习工作经历给出一些建议。希望对你们有用。
新手上路
大胆提问
起初我有些畏惧我的同事们,不敢问一些基础问题,生怕暴露自己的缺陷。几个月前,我才渐渐敢向几位同事问问题,但是问之前我还是精心组织了语言。现在我还有三四位没有问过的同事,我有些后悔为什么没有早点向他们求助。现在,只要我一有问题,就会马上向人求助。
在不同领域找科研灵感
做研究最难的部分就是决定做什么。以下是我经过长期观察发现的研究者通用的做法:
与另一个和你不同领域的研究者交流。询问他们感兴趣的问题,并且试着用计算机术语重新表述该问题。问问他们有没有想要分析的数据集,并且现有的技术无法对其进行高效地分析。机器学习很多重要的研究成果都来源于不同领域的碰撞,例如生物学、化学、物理、社会科学或纯数学。例如,NIPS 2016中的这篇Composing graphical models with neural networks for structured representations and fast inference就来源于一个关于老鼠行为的数据集;另一篇ICML 2017的论文Neural Message Passing for Quantum Chemistry是与量子化学的结合。
编写一套简单的代码基准,对问题有大致了解。例如,尝试编写一些用于控制OpenAI钟摆的代码,或者试试在自然语言数据集上推动运行词袋模型。在编写基线代码时,我常常遇到意外——我的思维模型或代码中会存在bug。当我的基准模型正在工作时,我通常会用很多其他方法试着解决,或者对问题有更深入的了解。
扩展你所喜欢的论文中的实验部分。仔细阅读方法和结果,首先考虑最简单的扩展,思考论文中所提出的方法是否已经足够,想一下没有提到的方法,在什么情况下这些方法会失效。
重视视觉工具和技巧
在撰写研究代码时,我先从创建可视化脚本开始。当其他代码写完后,运行可视化脚本能让我迅速地判断代码是否符合我的预期。更重要的是,好的可视化通常会让我的思维或代码中的bug更加明显并且可解释。除此之外,这样还有一个好处,那就是当我完成这个代码后,还能给别人展示精美的表格或视频。
为手头的问题找到合适的可视化工具可能非常困难。如果你正在用迭代优化模型(例如深度学习),可以试着从绘制损失曲线开始。除此之外还有很多可视化技术和解释神经网络学习权重的方法,例如引导反向传播。在强化学习和规划中,最明显的可视化是智能体在环境中的动作,它可以是雅达利游戏,也可能是机器人任务,或者是简单的网格世界(也就是OpenAI Gym中的环境)。根据设置的不同,它可以将价值函数可视化,以及它是如何随着训练过程发生改变的(如下所示),或是探索状态树。在处理图形模型时,对一维或二维变量随着推理进行改变的可视化也具有很多信息量(如下所示)。可视化技术是否有效的一个标准是估计每次分析可视化时你所掌握的信息量。糟糕的可视化可能需要你回想生成它的详细代码,一个好的可视化会立刻得出明显的结论。
Tensorb是对TensorFlow深度学习模型可视化的热门GUI
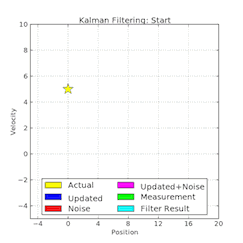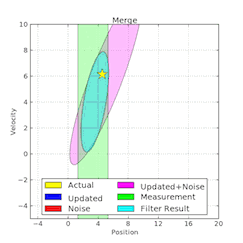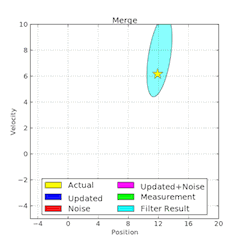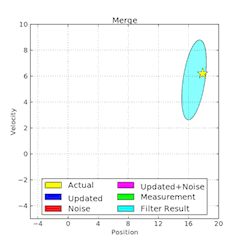
绘制分布范围,让调试图形模型更容易
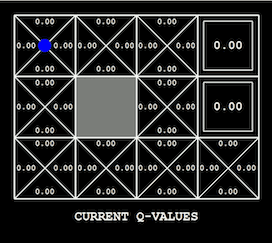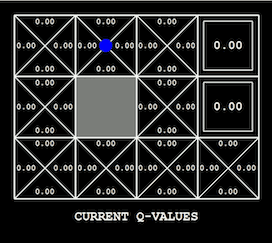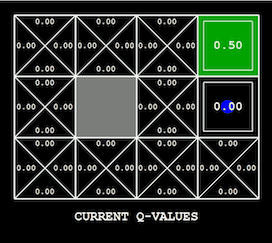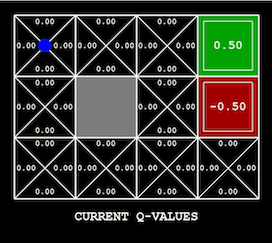
用Q-学习获取的价值函数,通过网格表示
确定研究人员和论文的首要目标
人工智能同一领域的专家,即使在同一场会议上发布了论文,甚至用了同样的技术术语,在研究目的上也可能截然相反。有些人甚至提出为每个领域都起不同的名字(比如Micheal Jordan发布的博客)。这里的研究目的至少有三大类:数学、工程和认知。
数学目的:人工智能系统的基本特征和极限是什么?
工程目的:如何用人工智能系统解决真实问题,而不用其他方法?
认知目的:我们如何建造像人类和其他动物那样的自然智能系统?
这几项目的可以同时存在,许多AI论文也有着多种目标。
但是,这些目的也可能互相矛盾。我有一些朋友和同事是明显的“工程”派,其他一些人对“生物”很感兴趣。一篇论文表明,现有技术的某些巧妙结合可以超越目前最好的方法,这会引起工程师们的极大兴趣,但是认知科学家可能会对此嗤之以鼻。
优秀的论文和研究者会表明他们最初的研究目的,我认为在阅读论文时从多个角度看待研究目的是非常有帮助的。
站在巨人的肩膀上
找论文
AI领域的论文一般都比较好找,它们大多发布在arXiv上,目前为止发表的论文数量已经非常庞大了。一些研究者自愿做了些工具,让论文查找更加容易。Andrej Karpathy开发了arXiv sanity preserver,加入了有用的分类、查找和过滤特征。Miles Brundage每晚都会在推特上分享一个arXiv论文列表。许多推特用户也会是不是的分享有趣的链接。点击链接可以看到我在推特上关注的最喜欢的研究者:twitter.com/tomssilver/following
如果你喜欢逛Reddit,r/MachineLearning这个节点非常不错,不过里面的内容个偏向于机器学习实践,而不是学术研究。Jack Clark每周都会发布“Import AI”,介绍AI新闻,Denny Britz也有类似的栏目,名为“The Weekend Weeki in AI"。
除此之外,关注大会的进展也非常有用。其中最重要的三场会议是:NIPS、ICML和ICLR。其他著名的会议包括AAAI、IJCAI、UAI。同时,每个细分领域也有自己的会议。对计算机视觉来说,这里有CVPR、ECCV和ICCV。对自然语言来说,有ACL、EMNLP、NAACL。对机器人领域来说,有CoRL这种学术型会议,也有ICAPS这种规划型会议,以及ICRA、IROS和RSS。对于更加理论化的工作,有AISTATS、COLT和KDD。各大会议是论文发表的主战场,但同时还有一些重要的期刊。JAIR和JMLR是两个细分领域的优质期刊。而同时一些专业文章也会出现在通用科学期刊,例如Nature和Science中。
翻看旧论文也非常重要,但是找起来比较困难。这些被看成“经典”的论文常常出现在文末的引用中,或者出现在研究生课程的阅读清单里。另一种发现旧论文的方法是从该领域的一位资深研究者开始,找出它们早起的研究成果,然后顺着这位教授的工作找下去。同时不要害怕向教授发邮件要链接或引用。最后就是用谷歌学术搜索那些不太出名,容易被忽略的论文。
需要花多长时间读论文?
对于一个人需要花多长时间阅读前人研究,我听过两种常见的说法。其一是,在研究刚开始时,就要把所有相关论文都读了!很多人都说,硕士的第一年啥也别干,就读论文。第二种说法是,大概过了准备期的时候,不要花太多时间阅读论文。因为与之前的研究走得太近可能会影响现在问题的解决。
就我个人而言,我同意第一种说法。我认为一个人应该尽可能多地读论文,如果在不熟悉前人的努力,就像提出一种新颖且优秀的解决方法,似乎不太可能,而且还是一种很傲慢的想法。的确,对一个问题全新的观察角度确实很重要,而且许多人在跳出固定的圈子之后对长久以来的难题提出了新颖的解决方案听上去也很振奋人心。但是要把研究作为事业,就不能寄希望于这些运气上。绝大多数时间都应该耐心地遵循进度,有条不紊地解决问题。阅读相关论文是一个了解我们自己和目标的有效方法。
关于阅读论文,重要的一点是:花时间消化和阅读一样重要。花一天时间边读论文边做笔记,同时不断思考,比一直不断地读下去有用得多。
对话 >> 视频 > 论文 > 会议发言
论文是了解一个不熟悉理论的最简便方法。但是哪种方法是最高效的呢?不同的人可能有不同的答案。但是我认为,对话是目前为止最快速、最高效了解一个领域的方式。如果找不到这方面的材料,那么视频也是不错的选择,例如论文的作者被邀请做的演讲。当演讲者在台上发表演讲时,他首先会保证讲得清晰而不是简介。而论文写作正好相反,其中论文字数是个重要指标,而对论文背景的解释可以看出作者对该领域是否熟悉。最后,简短的会议发言会比上课更正式一点。如果你能与作者直接对话,那可是非常宝贵的机会。
警惕夸张
AI研究的成功吸引了很多人的注意,也有许多人想进入这一领域,接着就有更多成功的研究成果。虽然这个循环非常有价值,但其中有害的一点就是夸张。媒体们为了吸引点击量、公司为了融资、研究者为了发表更多的文章及获得更多引用,不惜将AI吹嘘得越来越夸张。
在NIPS 2017上,在针对一篇论文进行Q&A环节时,台下有几百名观众,一位杰出的教授拿着麦克风(“代表炒作卫士”),告诫论文作者们在标题中慎用“imagination”一词。这种公开表明立场的行为让我感觉很复杂,因为我正好对这类文章有兴趣。但是我非常同情这位教授的沮丧。人工智能研究中最常见、也最令人厌恶的宣传方式之一就是给旧术语变个花样,用新词代替。遇到新的流行语要保持警惕,重点还是要看其中的实验和结果。
科研是场马拉松
保持循序渐进
当查找早期的研究项目时,我花了大量的时间做头脑风暴。在那个时候,我把头埋在桌子上,希望能灵光一现把模糊的概念变得清晰。一天下来精疲力尽,这难道就是真正的研究吗?
当然,做研究没有标准流程,大多数时间我们都在黑暗中摸爬滚打。然而,我现在发现把任务分成可实现的几部分会更加容易,也更有成就感。如果我对下一步的工作没什么想法,那么我的目标就是:把模糊的想法尽可能详细地记录下来;如果在写的过程中我将其放弃,那么写下放弃的原因。在没有灵感的时候,可以读读论文,或者和同事聊天。结束一天的工作之后,我会试着回忆一下工作内容。即使没有用到自己的想法,也不会垂头丧气,并且之后也不会在已经放弃的想法上浪费时间。
“当断则断”
优秀的研究者能在好的想法上花更多时间,是因为他们在糟糕的想法上花了很少时间。将好想法和差想法区分开似乎需要积累大量经验,但是,任何水平的研究人员都会遇到这种问题。我的研究理论有缺陷,我应该A)继续支持这个想法,还是B)完全放弃这一想法?我个人认为,如果必须做B,就不支持A的做法。之前我有好几次都走到了死胡同,但是在那里耽误太长时间了。如果能认识到自己的错误,果断放弃,就能节省很多时间。
Write!
我曾有幸向一位非常杰出的AI研究者咨询早期职业发展建议。它的建议非常简单:Write!写博客和论文是必须的,更重要的是,要写下来每天你所想的事情。经过他的点播,我发现记录要比单纯地想想进步更快。
保持身心健康
为了追求学术废寝忘食可不是个好习惯。锻炼和休息也是投资,而不是浪费。如果花8个小时睡觉,工作4小时,工作效率比睡4个小时工作8小时要高。
在一个棘手的问题中停止工作很快困难,即使当我已经度过了疲惫和沮丧的时候,没有休息却也没有进展的时候,我仍然会非常刻苦地钻研。这样当我停止的时候就会很高兴。我希望在下一个研究阶段,我能把这种习惯变为自然。
原文地址:web.mit.edu/tslvr/www/lessonstwoyears.html




