OSDI 2020 | 微软亚洲研究院论文一览

编者按:OSDI 是计算机系统软件领域全球最顶级的会议之一,每两年举办一届,被誉为“操作系统原理领域的奥斯卡”,拥有极高的学术地位。第14届 OSDI 将于2020年11月4日至6日召开。此次会议投稿398篇,共录用论文70篇,录用率不足18%。本文中,我们将为大家介绍微软亚洲研究院被录取的6篇论文。
拜占庭有序共识:对拜占庭共识的扩充
Byzantine Ordered Consensus without Byzantine Oligarchy
论文链接:https://www.usenix.org/conference/osdi20/presentation/zhang-yunhao
代码地址:https://github.com/yhzhang0128/archipelago-hotstuff
区块链是当前产业界和学术界十分关心的一种新型应用模式,其核心目标是在分布式、无信任的情况下达成共识。而分布式、无信任共识问题是系统领域中的经典理论问题。拜占庭共识(Byzantine Consensus)是无信任情况下达成共识的一个经典成果。在各种区块链中,许可链(Permissioned Blockchain)系统看起来可以很自然地利用拜占庭共识的结果达到目标。
然而,在微软亚洲研究院和康奈尔大学合作发表的论文 “Byzantine Ordered Consensus without Byzantine Oligarchy” 中,研究员们揭示了事情并没有看上去那么简单。在传统的拜占庭共识问题中,所有正确节点需要达成一致的执行顺序,而具体达成什么样的顺序并不重要。但是,研究员们意识到,在依赖拜占庭共识的许可链中,节点的利益与该顺序紧密相关。例如在应用于拍卖或者交易的许可链中,不同节点提交的购买请求的执行顺序决定了哪些节点能够最终交易成功。在交易中,每个节点都对该顺序拥有话语权,并有义务阻止恶意节点操纵该顺序来获利。然而,共识问题的经典定义中并没有与顺序正确性相关的描述。
因此,在论文中研究员们首次提出了一种新的概念——“拜占庭有序共识”,通过引入顺序正确性维度扩充了共识问题的经典定义。
同时,该论文提出了一个新的实现拜占庭共识的系统构架,该构架通过分离给命令排序的步骤和节点达成共识的步骤,来高效地满足新概念中所定义的顺序正确性,阻止恶意节点单方面控制执行顺序。论文还提出并实现了新的 Pompe 协议,将传统的线性一致性原则自然地扩展到了顺序正确性维度。大规模跨多个数据中心的实验表明,Pompe 可以很好地在满足顺序正确性的条件下达到高性能:在执行时间大致相同的前提下,Pompe 可以通过在命令排序和节点达成共识两个步骤中采用批量命令处理方式获得比其他拜占庭共识协议更高的吞吐率。
这篇论文展示了新的应用场景可以对经典计算机理论产生新挑战,驱动计算机理论进一步发展,让新理论满足新的需求,从而达到理论从实践中抽象而生又可以应用回实践中的良性循环。
HiveD:新的多租户 GPU 集群管理方案
HiveD: Sharing a GPU Cluster for Deep Learning with Guarantees
论文链接:https://www.usenix.org/conference/osdi20/presentation/zhao-hanyu
代码地址:https://github.com/microsoft/hivedscheduler/
随着深度学习训练需求的不断扩张,很多组织和机构都会选择自建多租户集群来共享昂贵的 GPU 资源。然而现有的 GPU 集群管理方案因为使用了 GPU 配额(Quota)机制,可能导致严重的共享异常(Sharing Anomaly)现象:某些租户的深度学习任务甚至比在私有集群中性能更差。为了从根本上解决该问题,微软亚洲研究院和微软(亚洲)互联网工程院、北京大学、香港大学合作提出了一个新的多租户 GPU 集群管理方案 HiveD,通过新的资源抽象和调度框架从而100% 保证共享安全(Sharing Safety),同时不失一般性地和任何任务调度策略兼容。
现有集群管理方案无法满足共享安全的根本原因是因为采用了 GPU 配额这一资源抽象,使得租户无法对 GPU 拓扑资源进行预留。HiveD 首先提出了一种新的资源抽象,被称为 Cell(类比蜂巢 Hive 中的蜂窝)。研究员们通过多级 Cell 来描述 GPU 集群拓扑的层级组织。如图1所示,一个 Cell 就是一个由同一级拓扑结构互联的 GPU 的集合。Cell 的定义取决于所管理的 GPU 服务器集群的拓扑组织方法,并不只限于图1所示的形式。

图1:HiveD 提供的基于多级 Cell 的资源抽象
在 Cell 的基础上,HiveD 会为每个租户提供一个虚拟私有集群(Virtual Private Cluster,简称 VC)。每个租户的 VC 显式定义了它拥有的各级 Cell 的配额。有了 VC 作为参考,HiveD 可以轻易地分辨出每个租户的任务可以使用什么 GPU 拓扑。而用户也可以根据自己任务的需求,灵活地为自己的任务选择消耗什么级别的 Cell。
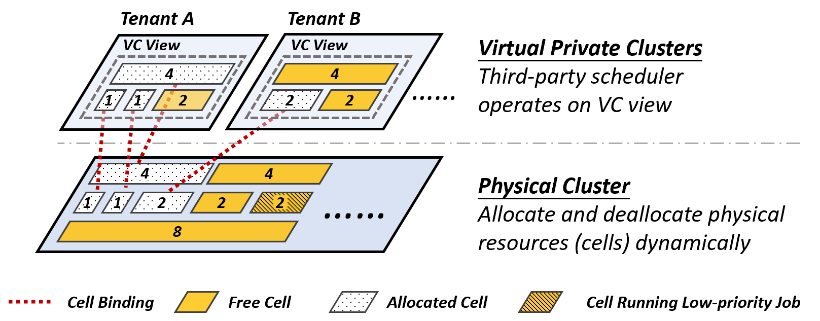
图2:HiveD 为各租户提供独立的 VC,并动态地进行 Cell 和物理 GPU 的绑定
为了在保证共享安全的同时,灵活地分配 GPU 资源,研究员们在 HiveD 中设计了一个 Buddy Cell Allocation 算法,来把 VC 中的逻辑 Cell 和物理 GPU 进行动态绑定。除了提供共享安全,HiveD 的 Buddy Cell Allocation 还有其他好处,如降低物理集群的 GPU 碎片化、更灵活地处理设备故障、支持动态重配置 VC 等。
HiveD 的整个调度流程可以被理解为两级调度:VC 内调度和物理调度。当一个租户提交任务时,该任务首先会进行 VC 内调度,来决定申请使用哪些逻辑 Cell。然后这些被选择的逻辑 Cell 会在物理调度时再由 HiveD 的 Buddy Cell Allocation 算法绑定到物理集群的 GPU 上。因为 VC 内的所有 Cell 可以被看成一个虚拟的私有集群,这种设计允许 HiveD 在 VC 内部兼容各种任务调度算法(比如 Gandiva, Tiresias, Philly, Optimus)。每个租户甚至可以根据自己的需求来采用不一样的任务调度算法。
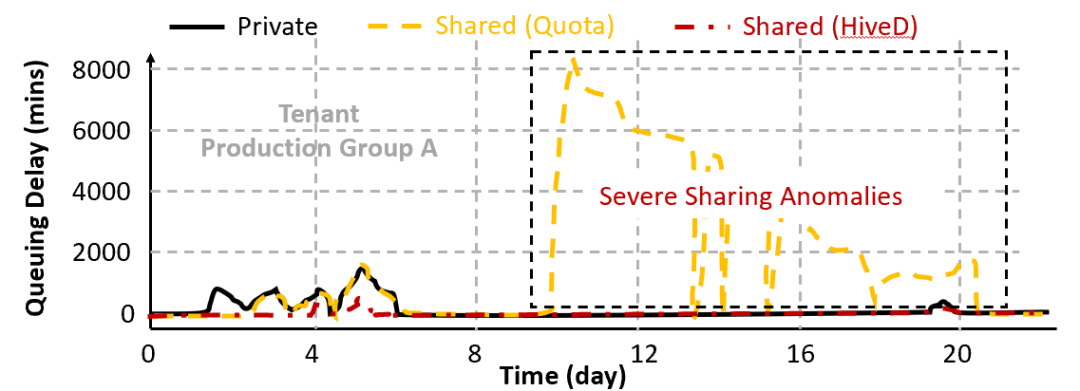
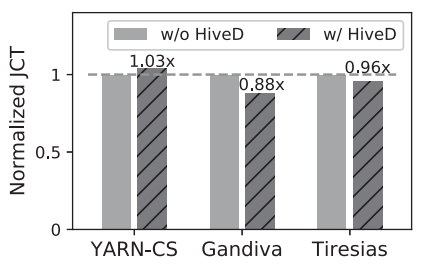
图3:在生产集群数据集的实验验证了 HiveD 在几乎不损失调度效率的情况下,避免了所有共享异常
到目前为止,HiveD 已经在微软内部数个集群上线并稳定运行了超过11个月,以负责调度各种生产和科研性质的深度学习任务。
NARYA:基于“预测+自适应缓解”的集群故障处理方案
Narya: Predictive and Adaptive Failure Mitigation to Avert Production Cloud VM Interruptions
论文链接:https://www.usenix.org/conference/osdi20/presentation/levy
高可靠性一直是各大云计算平台的追求。针对云计算集群内部发生的故障,传统的做法是“发生故障->造成负面影响(服务中断、性能下降等)->检测到问题->诊断、归因->修复问题->重新部署”,而在这个过程中用户会持续被影响,严重影响用户的体验并可能给用户造成严重的经济损失。为了解决这一问题,微软亚洲研究院的研究员与微软 Azure 团队一起提出了一种基于“预测+自适应缓解”的故障处理方案,命名为 NARYA。
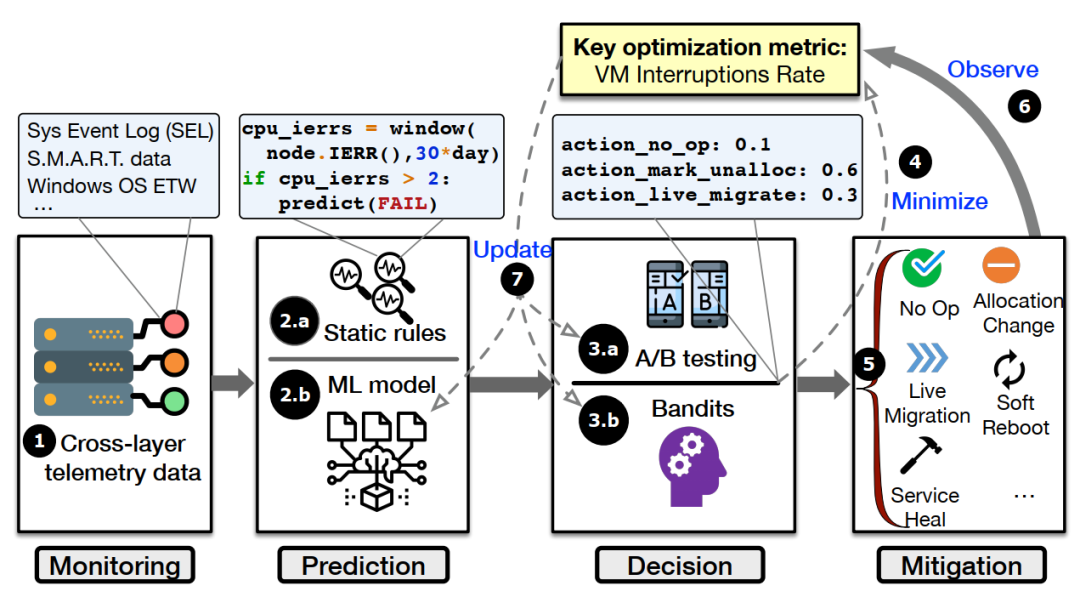
图4: NARYA 整体框架图
NARYA 首先通过模型来预测故障的发生,然后对即将发生故障的组件自适应地采取缓解措施,使整个故障处理流程对用户透明并避免用户受到负面影响。
1,故障预测:NARYA 采用深度学习模型来预测某组件是否快要发生故障,不同于其他现有 SOTA 故障预测模型的是,它是一个完全基于注意力机制的模型,包括两个编码器,一个用来编码时序信息,一个用来编码组件的上下文信息。所以 NARYA 不仅利用了组件自身的信息还利用了组件的上下文环境信息来进行故障预测,极大地提升了预测的准确性。
2,自适应采取缓解措施:在实际生产环境中,云计算系统是不断演化的(如集群规模,软硬件升级等),所以某个缓解故障的措施可能在以前有效,但随着系统自身的演化将变得不再有效。为了“因地制宜、因时制宜”,研究团队提出了基于强化学习的自适应决策策略,它可以通过可控随机实验来探索动作(缓解措施)空间,然后收集用户的体验数据作为反馈,从而得到当前集群状态下各措施对应的奖惩信息。为了最大化奖励,它将不断自我优化,变得越来越“聪明”、采取的缓解措施也越来越符合当前系统的需要。
目前这一方案已经被集成到微软 Azure 云计算平台上,上线15个月以来平均减少了26%的服务中断问题,充分证明了 NARYA 的有效性。
Protean: 提供大规模的 VM 配置服务
Protean: VM Allocation Service at Scale
论文链接:https://www.msra.cn/wp-content/uploads/2020/10/Protean-VM-Allocation-Service-at-Scale.pdf
本篇论文介绍了微软云计算平台 Azure 的一个核心服务 Protean 的设计和实现。Protean 的任务是负责将虚拟机分配到 Azure 遍布全球的数据中心里运行着的数以百万计的服务器上。如果将 Azure 比作一台巨大的超级电脑,那么 Protean 就是这台电脑操作系统内核中的计算资源分配模块。
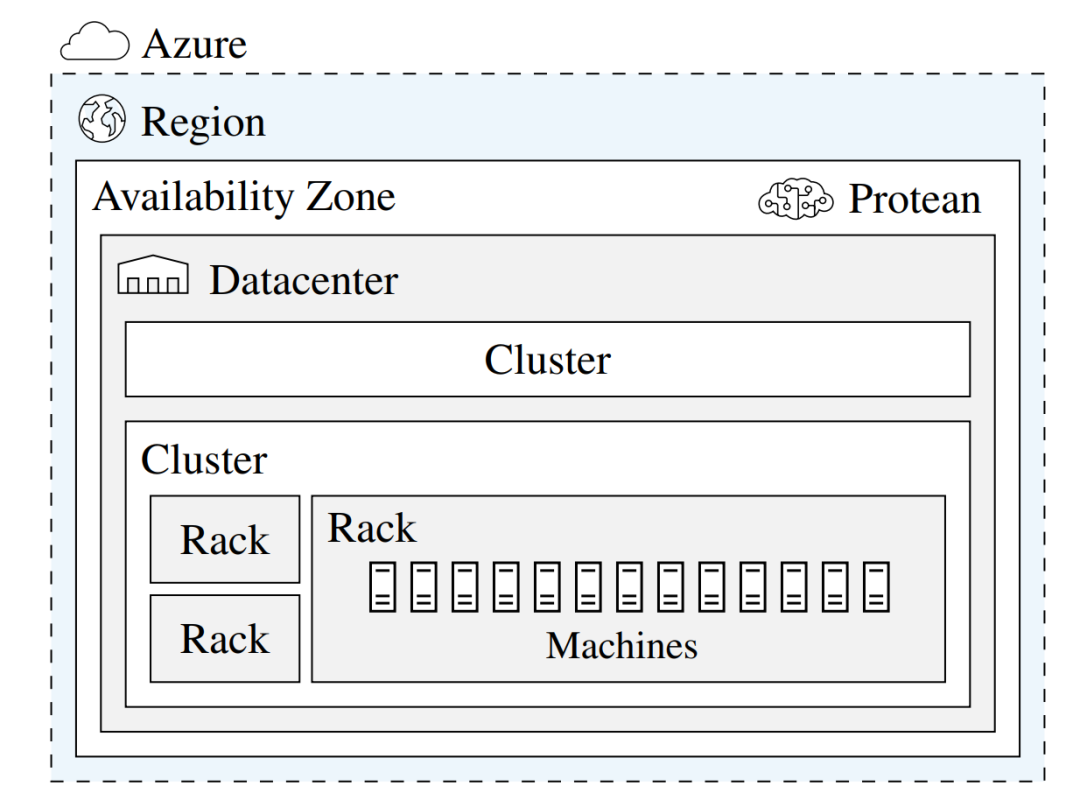
图5:Azure 拓扑结构
虚拟机作为云计算平台的基本资源分配单元,能够给用户的应用程序提供独立、安全和可靠的运行环境。Protean 需要根据用户的需求自动将 Azure 的各种服务器动态分割成大小不同的虚拟机,并满足用户对于这些虚拟机所处的地理区域(region)和可用区(available zone)的要求,以及虚拟机之间的相对位置、虚拟机对服务器的独占需求等各种限制条件。同等重要的是,Protean 还需要在追求资源的充分利用和预留足够的空闲资源用于容错和扩容之间取得平衡。
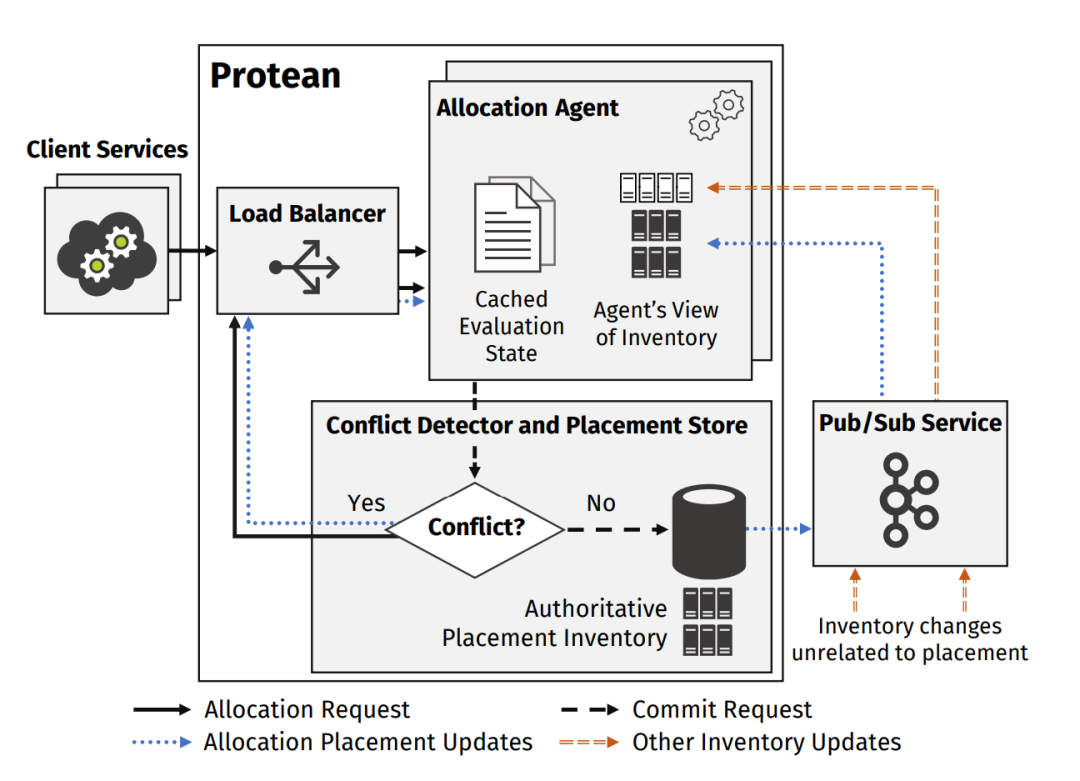
图6:Protean 框架图
Protean 是微软工程团队和研究人员在过去十多年中,伴随着云计算业务的飞速发展,而不断迭代产生的结晶。它经过了实践的充分检验,达到了高可扩展性、高可配置性、高资源利用率、高吞吐量、低响应延迟的设计目标。
这篇论文最大的价值在于首次向学术界和工业界披露了微软 Azure 云计算平台在虚拟机分配方面需要解决的关键问题和经过时间考验的真实解决方案。微软 Azure 作为全球最先进、规模最大的云计算平台之一,使得这些宝贵的洞见和经验,具有巨大的现实意义和启发性。
RAMMER: 如何通过全局视角编译深度学习计算
Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks
论文链接:https://www.usenix.org/conference/osdi20/presentation/ma
代码地址:https://github.com/microsoft/nnfusion/
传统深度学习框架由于其自身的局限性,如今还远没有充分发挥出硬件的计算性能。微软亚洲研究院的研究员们在一些测试集上发现,现有的深度学习模型只能用到 GPU 2%到40%的性能。传统的深度学习框架通常通过分层调度来将一个深度学习模型调度到硬件设备(通常是 GPU 这样的协处理器)上进行计算。首先,在上层,深度学习模型通常会被抽象为由算子(Operator)和依赖关系构建而成的数据流图(DFG),深度学习框架主要负责将每个算子按照正确的依赖关系依次调度到下层设备上;接着,在下层硬件设备上(如 GPU),会有一个硬件的调度器将每个算子根据其内部并行性调度到硬件内的并行计算核上。这样两层调度的模型尽管较为简洁明晰,但在实际的部署中,两个调度层互相不感知会导致较大的调度开销,以及较低的硬件利用率。
传统深度学习框架在实现全面神经网络优化上的核心障碍在于:首先,现有的基于数据流图的抽象无法表示算子内部的并行性,对于由深度学习框架控制的图调度器完全是黑盒;其次,硬件厂商往往将细粒度的任务调度隐藏在硬件中,对上层框架调度也是黑盒。
针对现有深度学习框架的局限,微软亚洲研究院和北京大学、上海科技大学合作提出了一种可以成倍甚至几十倍地提升深度学习计算速度的编译框架 RAMMER。
RAMMER 一方面将原数据流图中的算子通过 rOperator 抽象暴露出算子内部的并行性,从而在数据流图中同时表示算子间和算子内的并行度;另一方面,通过虚拟设备(Virtualized Device)抽象将底层的硬件充分暴露出硬件内部的计算单元以及调度能力。通过 rOperator 和虚拟设备的抽象,整个深度学习计算流图可以根据其本身各层次的并行度以及硬件所提供的并行度在编译期生成完整调度方案,并“静态”映射到硬件计算单元上,因此可以天然地消除原本存在的调度开销,提高硬件利用率。
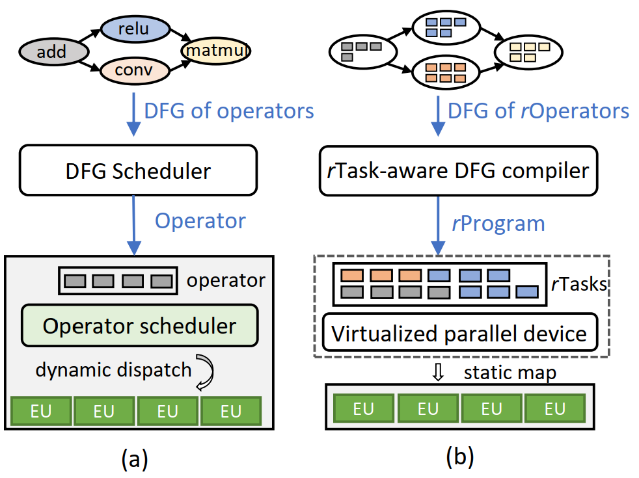
图7:(a)传统深度学习框架,(b)RAMMER 深度学习编译框架
更重要的是,RAMMER 的整个设计是硬件通用的。它可以很好地适配到诸如多核 CPU、主流深度学习加速器等设备上。通过在 NVIDIA GPU、AMD GPU 和 Graphcore IPU 上进行充分的实验评测,相比于当前最先进的神经网络编译器如 XLA 和 TVM,该编译技术可以使现有模型的性能提升高达20倍。甚至和 NVIDIA 内部高度优化过的私有计算库 TensorRT 相比,也能得到高达3倍的性能超越。这些显著的性能提升很大程度上得益于 RAMMER 的系统抽象所充分暴露出来的优化空间,也再次验证了系统抽象对优化空间、优化策略、以及整体计算性能的重要影响。
Retiarii: 一种支持“探索性训练”的新型深度学习框架
Retiarii: A Deep Learning Exploratory-Training Framework
论文链接:https://www.usenix.org/conference/osdi20/presentation/zhang-quanlu
代码地址:https://github.com/microsoft/nni/tree/retiarii_artifact
深度学习框架(Deep Learning Framework)是目前研究人员开发深度神经网络的主要工具。以 TensorFlow、PyTorch 为代表的深度学习框架为深度神经网络的成功应用和快速发展起到了重要的促进作用。
在和深度学习领域研究员的长期合作中,微软亚洲研究院系统领域的研究员发现在开发新的神经网络时,研究人员通常需要探索一类神经网络结构,而不是单个具体的神经网络。在探索过程中,深度神经网络的研究人员通常从构建一个基础网络(Base Graph)为出发点,对该网络进行训练,根据训练情况的反馈,对该神经网络的结构进行调整,然后再次训练。通过一系列反复的训练、调整,最终找到符合要求的神经网络。在论文中,研究员将上述过程称为“探索性训练”(Exploratory-Training)。
目前的深度学习框架只支持开发单个神经网络,然而这仅完成了整个探索性训练过程中的一步。另一方面,现有自动机器学习(AutoML)的方案如神经网络结构搜索(NAS: Neural Architecture Search)或超参数优化(HPO: Hyperparameter Optimization)缺乏可编程性和模块化,这使得一种 NAS/HPO 解决方案通常只能用在某一类神经网络结构上。此外,在探索性训练过程中很多神经网络结构是相似的,利用这些相似性有很多优化的机会可以加速整个探索性训练的过程。而现有的深度神经网络开发工具并没有系统性地利用这些相似性来加速探索过程。
针对以上不足,本篇论文提出了一种支持探索性训练的新型深度学习框架 Retiarii。Retiarii 创新性地将神经网络的开发看成一系列网络模型的“变形“ (Mutation),这一系列变形组成了在一个网络空间(Model Space)内的搜索过程。Retiarii 提出将“变形器”(Mutator)作为基本的编程范式,神经网络开发人员利用变形器对一个基础网络 (Base Graph) 进行编程变形,如增加或删除某个网络节点。在每次变形时,变形器通过选择 (choose()) 这一接口将网络具体如何变形的选择权交给了“探索策略”(Exploration Strategy),甚至可以实时地交给开发者本人。这样整个探索性训练就是将一系列的变形器作用于一个基础网络上,并交由探索策略来驱动整个探索过程。Retiarii 的上述设计让整个探索过程更加可编程和模块化。
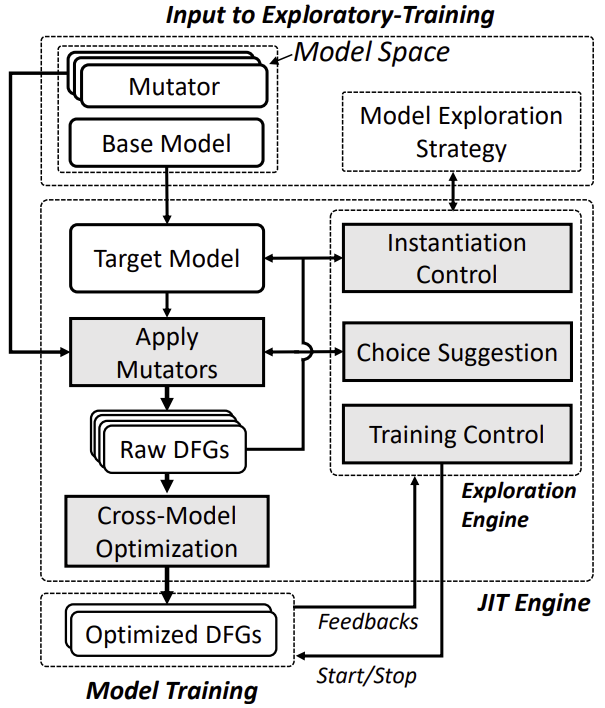
图8:Retiarii 的系统架构
论文表明,不同的搜索策略可以和少数几个变形器组合起来,实现多达27种神经网络结构搜索方案。另外,Retiarii 的跨网络优化器还可以自动地发现探索性训练期间各个网络之间的相似性,利用相似性实现多达8.58倍的网络搜索加速。
微软亚洲研究院正在积极开发和完善 Retiarii 的用户体验,计划于近期将其正式集成在开源自动机器学习工具集 NNI 中。
NNI链接:https://github.com/microsoft/nni
你也许还想看:










