AI初识:为了围剿SGD大家这些年想过的那十几招
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
今天来说说 神经网络的优化相关的内容。比如 常 用的优化算法 。 深度学习框架目前基本上都是使用一阶的梯度下降算法及其变种进行优化,在此基础上也发展出了很多的改进算法。 另外,近年来二阶的优化算法也开始慢慢被研究起来。
1 优化简述
深度学习模型的优化是一个非凸优化问题,这是与凸优化问题对应的。
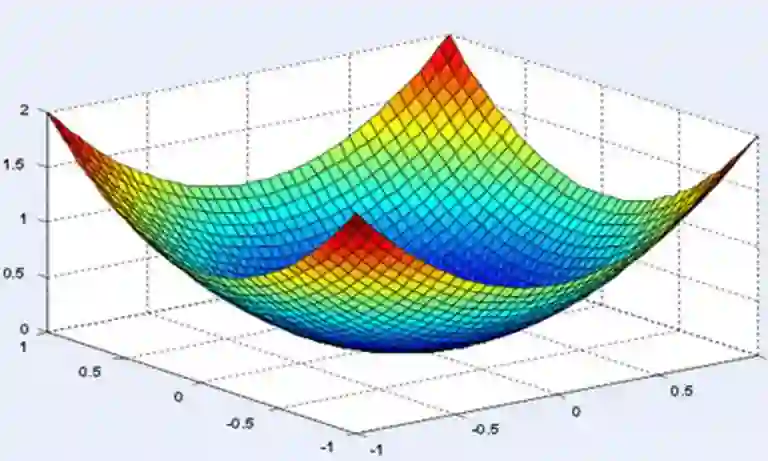
对于凸优化来说,任何局部最优解即为全局最优解。用贪婪算法或梯度下降法都能收敛到全局最优解,损失曲面如下。
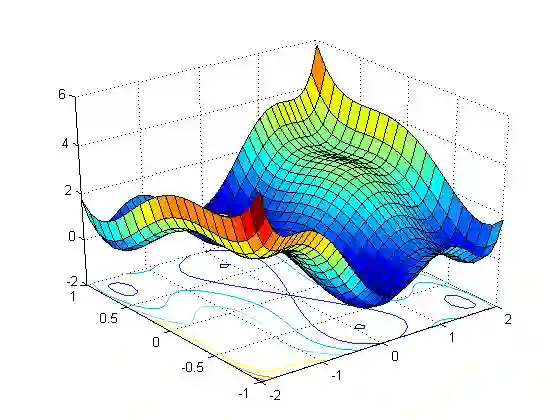
而非凸优化问题则可能存在无数个局部最优点,损失曲面如下,可以看出有非常多的极值点,有极大值也有极小值。
除了极大极小值,还有一类值为“鞍点”,简单来说,它就是在某一些方向梯度下降,另一些方向梯度上升,形状似马鞍,如下图红点就是鞍点。
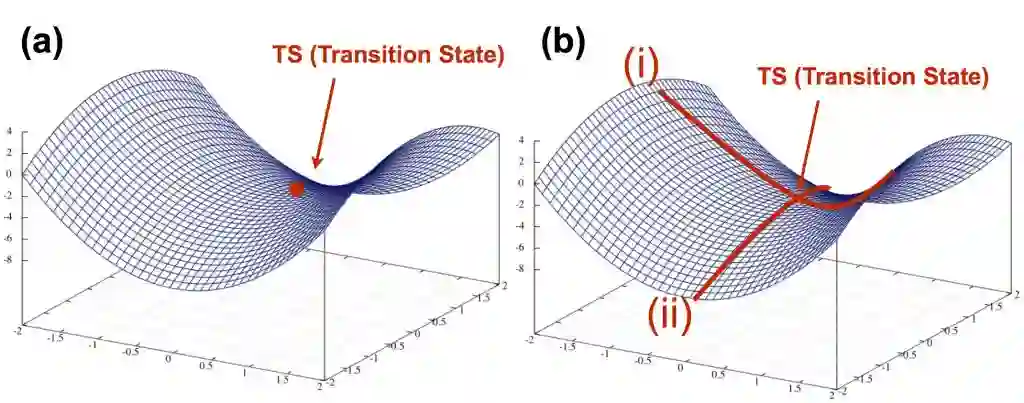
对于深度学习模型的优化来说,鞍点比局部极大值点或者极小值点带来的问题更加严重。
目前常用的优化方法分为一阶和二阶,这里的阶对应导数,一阶方法只需要一阶导数,二阶方法需要二阶导数。
常用的一阶算法就是:随机梯度下降SGD及其各类变种了。
常用的二阶算法就是:牛顿法等。
我们这里主要还是说一阶方法,二阶方法因为计算量的问题,现在还没有被广泛地使用。
2 梯度下降算法
本文目标不是为了从零开始讲清楚优化算法,所以有些细节和基础就略过。
梯度下降算法,即通过梯度的反方向来进行优化,批量梯度下降(Batch gradient descent)用公式表述如下:
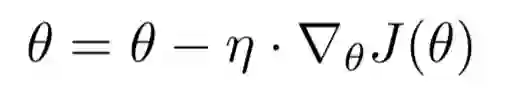
写成伪代码如下:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
上面的梯度下降算法用到了数据集所有的数据,这在解决实际问题时通常是不可能,想想Imagenet1000有100G以上的图像,内存装不下,速度也很慢。
我们需要在线能够实时计算,于是一次取一个样本,就有了随机梯度下降(Stochastic gradient descent),简称sgd。
公式如下:
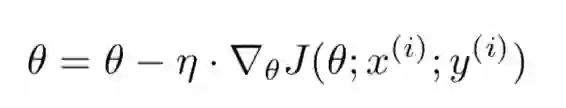
写成伪代码如下:
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function , example , params)
params = params - learning_rate * params_grad
sgd方法缺点很明显,梯度震荡,所以就有了后来大家常用的小批量梯度下降算法(Mini-batch gradient descent)。
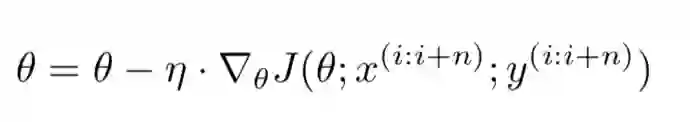
伪代码如下:
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
下面我们要形成共识,说sgd算法,实际上指的就是mini-batch gradient descent算法,没有人会去一次拿整个数据集或者一个样本进行优化。
当然还是要总结一下SGD算法的毛病。
(1) 学习率大小和策略选择困难,想必动手经验丰富的自然懂。
(2) 学习率不够智能,对参数的各个维度一视同仁。
(3) 同时面临局部极值和鞍点的问题。
3 梯度下降算法改进
1 Momentum 动量法
在所有的改进算法中,我觉得真正最有用的就是它。
前面说了梯度下降算法是按照梯度的反方向进行参数更新,但是刚开始的时候梯度不稳定呀,方向改变是很正常的,梯度就是抽疯了似的一下正一下反,导致做了很多无用的迭代。
而动量法做的很简单,相信之前的梯度。如果梯度方向不变,就越发更新的快,反之减弱当前梯度。
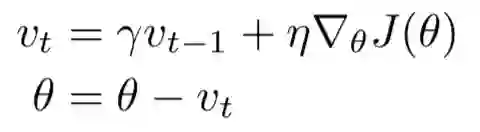
画成图就是这样。
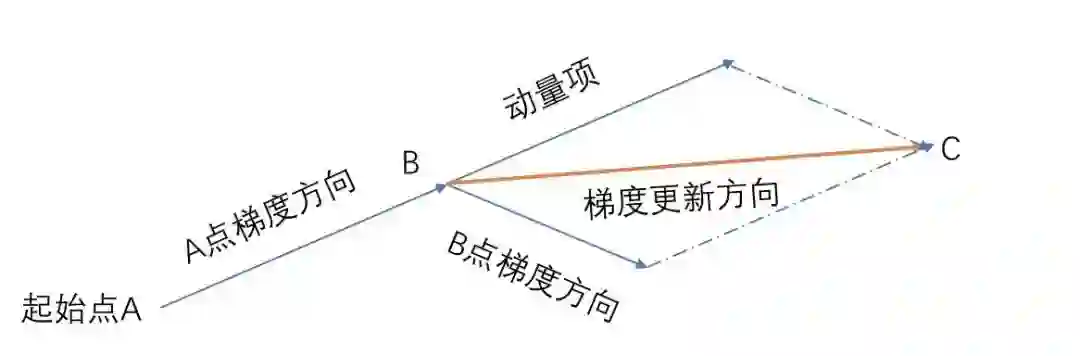
效果对比就这意思。
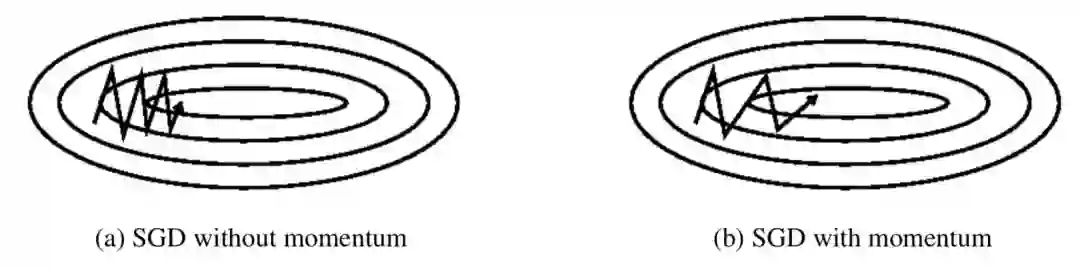
2 Nesterov accelerated gradient法 ,简称NAG算法
仍然是动量法,只是它要求这个下降更加智能。
既然动量法已经把前一次的梯度和当前梯度融合,那何不更进一步,直接先按照前一次梯度方向更新一步将它作为当前的梯度,看下面的式子就明白了。
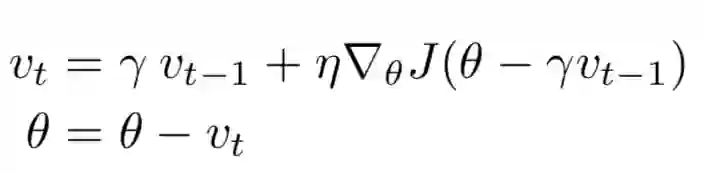
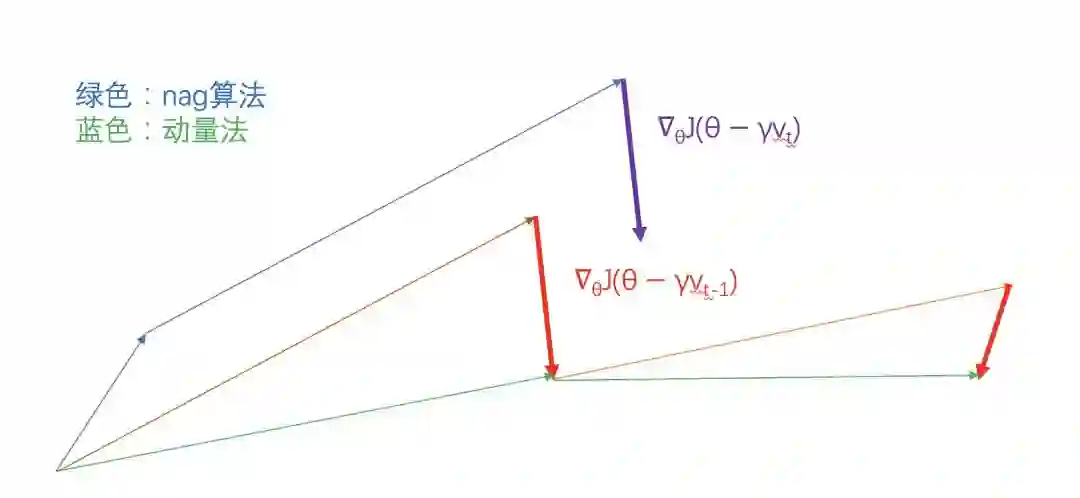
如上图,自己领会。nesterov的好处就是,当梯度方向快要改变的时候,它提前获得了该信息,从而减弱了这个过程,再次减少了无用的迭代。
3 Adagrad法
思路很简单,不同的参数是需要不同的学习率的,有的要慢慢学,有的要快快学,所以就给了一个权重咯,而且是用了历史上所有的梯度幅值。
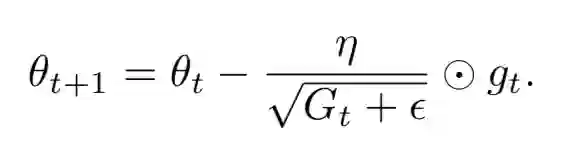
4 Adadelta与Rmsprop
Adagrad用了所有的梯度,问题也就来了,累加的梯度幅值是越来越大的。导致学习率前面的乘因子越来越小,后来就学不动了呀。
Adadelta就只是动了一丢丢小心思,只累加了一个窗口的梯度,而且计算方法也更有效。
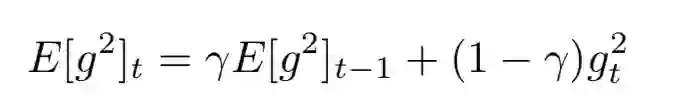
并且,将学习率用前一时刻参数的平方根来代替,最终更新算法变成了这样。
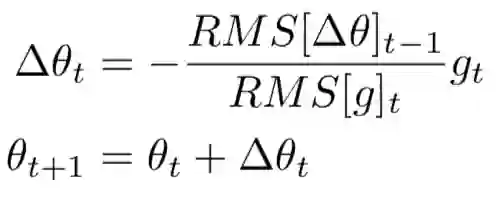
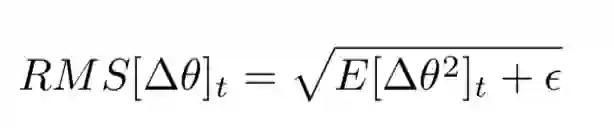
把γ变成0.9,就是RMSprop方法了,这个方法在Hinton的课程中使用的,没有发表成论文,毕竟有Adadelta了,没有发表必要。与adadelta另一个不同是还是需要学习率的,建议0.001。
5 Adam方法
Adam算法可能是除了SGD算法之外大家最熟悉的了,无脑使用,不需调参。
Adam对梯度的一阶和二阶都进行了估计与偏差修正,使用梯度的一阶矩估计和二阶矩估计来动态调整每个参数的学习率。
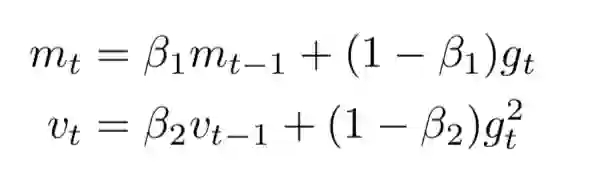
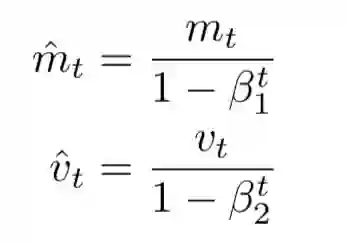
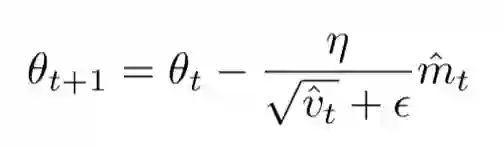
看出来了吧,与Adadelta和Rmsprop如出一辙,与Momentum SGD也颇为相似。上面的式子根据梯度对参数更新的幅度进行了动态调整,所以Adam对学习率没有那么敏感。
Adam每次迭代参数的学习步长都有一个确定的范围,不会因为很大的梯度导致很大的学习步长,参数的值比较稳定,但是它也并非真的是参数不敏感的,学习率在训练的后期可仍然可能不稳定导致无法收敛到足够好的值,泛化能力较差,这在文[3]中有非常详细的研究,后面也会简单说一下。
6 AdaMax
将Adam使用的二阶矩变成更高阶,就成了Adamax算法。
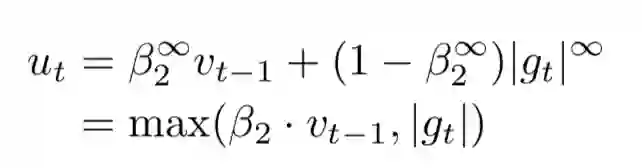
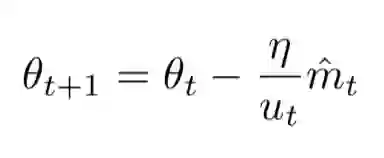
7 Nadam法
Nag加上Adam,就成了Nadam方法,即带有动量项的Adam,所以形式也很简单,如下,可以将其分别与Adam算法和NAG算法的式子比较看看。
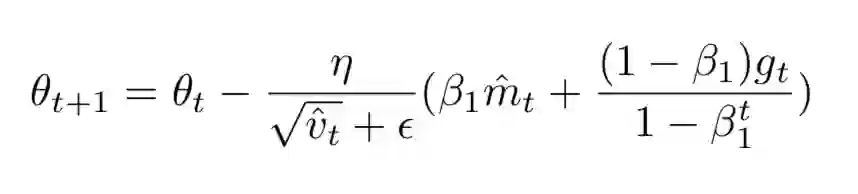
8 AMSgrad方法
ICLR 2018最佳论文提出了AMSgrad方法,研究人员观察到Adam类的方法之所以会不能收敛到好的结果,是因为在优化算法中广泛使用的指数衰减方法会使得梯度的记忆时间太短。
在深度学习中,每一个mini-batch对结果的优化贡献是不一样的,有的产生的梯度特别有效,但是也一视同仁地被时间所遗忘。
具体的做法是使用过去平方梯度的最大值来更新参数,而不是指数平均。
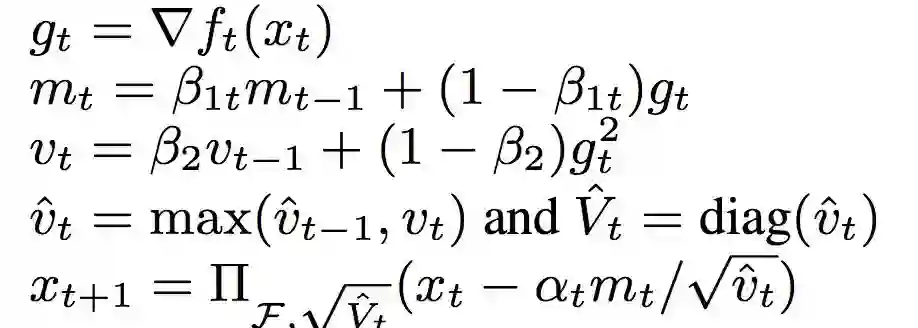
9 Adafactor方法
Adam算法有两个参数,beta1和beta2,相关研究表明beta2的值对收敛结果有影响,如果较低,衰减太大容易不收敛,反之就容易收敛不稳定。Adafactor是通过给beta1和beta2本身也增加了一个衰减。
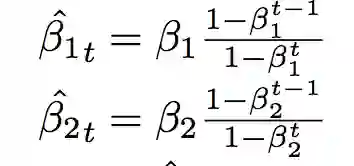
beta2的值刚开始是0,之后随着时间的增加而逼近预设值。
10 Adabound方法
上面说了,beta2的值造成Adam算法有可能不收敛或者不稳定而找不到全局最优解,落实到最后的优化参数那就是不稳定和异常(过大或者过小)的学习率。Adabound采用的解决问题的方式就非常的简单了,那就是限制最大和最小值范围,约束住学习率的大小。
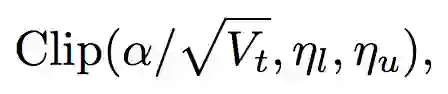
ηl(t)和ηu(t)分别是一个随着时间单调递增和递减的函数,最后两者收敛到同一个值。
说了这么多,对上面各种方法从一个鞍点开始优化,表现如何的预期效果图如下,参考文[1]。
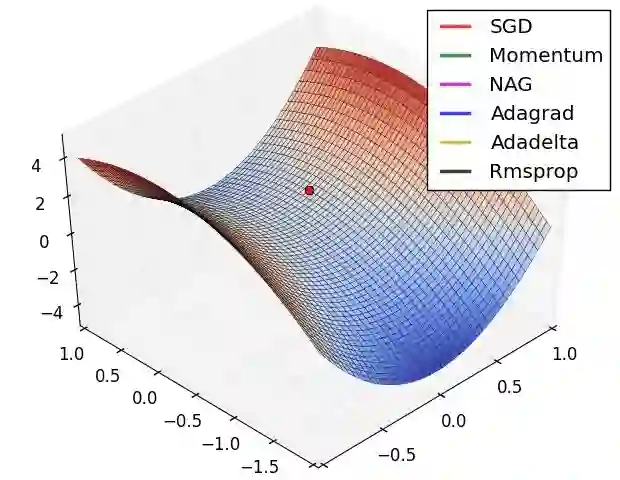
理论上,就是上面这样的。文章作者会告诉你对于数据稀疏的问题,用自适应学习率算法就好了,而且使用人家推荐的参数就好。其中,Adam会最佳。
4 总结
4.1 改进方法是否都比SGD算法强?
上面说了这么多理论,分析起来头头是道,各种改进版本似乎各个碾压SGD算法。但是否真的如此。笔者曾经做过一个简单的实验,结果如下。
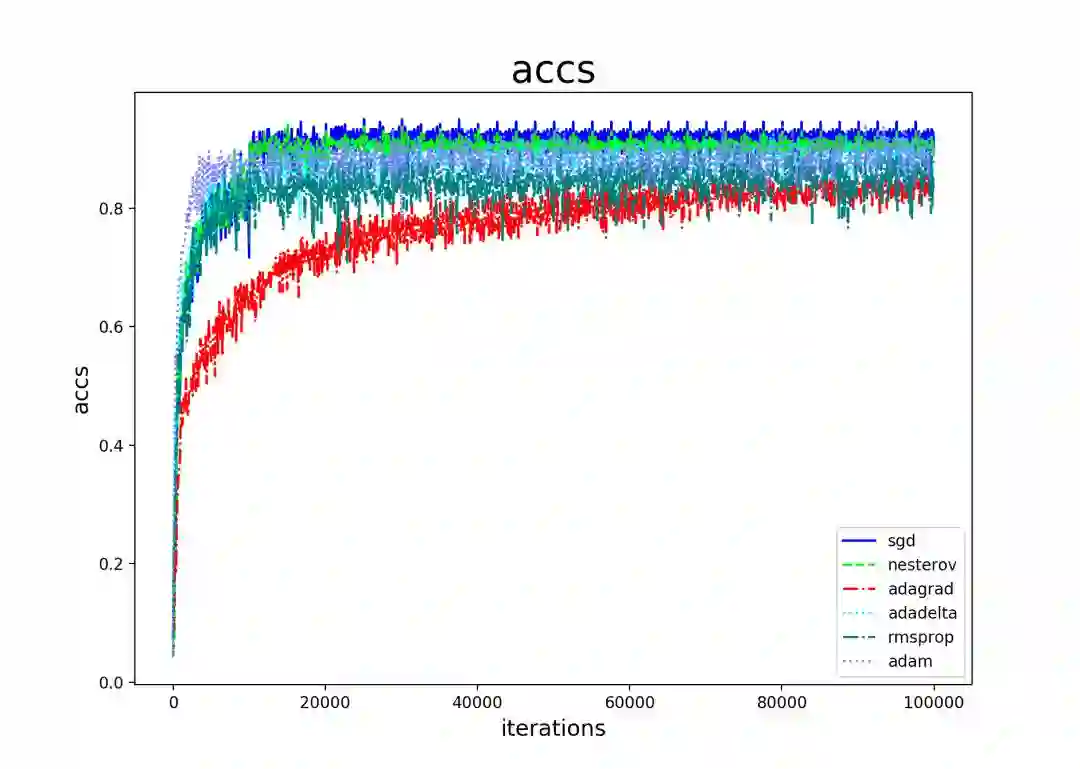
所有方法都采用作者们的默认配置,并且进行了参数调优,不好的结果就不拿出来了。
nesterov方法,与sgd算法同样的配置。
adam算法,m1=0.9,m2=0.999,lr=0.001。
rms算法,rms_decay=0.9,lr=0.001。
adagrad,adadelta学习率不敏感。
看起来好像都不如SGD算法,实际上这是一个很普遍的现象,各类开源项目和论文[3-4]都能够印证这个结论。
总体上来说,改进方法降低了调参工作量,只要能够达到与精细调参的SGD相当的性能,就很有意义了,这也是Adam流行的原因。但是,改进策略带来的学习率和步长的不稳定还是有可能影响算法的性能,因此这也是一个研究的方向,不然哪来这么多Adam的变种呢。
4.2 二阶方法研究的怎么样了呢?
二阶的方法因为使用了导数的二阶信息,因此其优化方向更加准确,速度也更快,这是它的优势。
但是它的劣势也极其明显,使用二阶方法通常需要直接计算或者近似估计Hessian 矩阵,一阶方法一次迭代更新复杂度为O(N),二阶方法就是O(N*N),深层神经网络中变量实在是太多了,搞不动的。
不过,还是有研究者去研究的。比如东京工业大学和NVIDIA在[5]中使用的K-FAC方法,用1024块Tesla V100豪无人性地在10分钟内把ImageNet在35个epoch内训练到75%的top-1精度。K-FAC已经在CNN的训练中很常用了,感兴趣的可以去了解。
其他的二阶方法笔者也关注到了一些,以后等有了比较多稳定靠谱的研究,再来分享把。
[1] Ruder S. An overview of gradient descent optimization algorithms[J]. arXiv preprint arXiv:1609.04747, 2016.
[2] Reddi S J, Kale S, Kumar S. On the convergence of adam and beyond[J]. 2018.
[3] Bottou L, Curtis F E, Nocedal J. Optimization methods for large-scale machine learning[J]. Siam Review, 2018, 60(2): 223-311.
[4] Keskar N S, Socher R. Improving generalization performance by switching from adam to sgd[J]. arXiv preprint arXiv:1712.07628, 2017.
[5] Osawa K, Tsuji Y, Ueno Y, et al. Second-order Optimization Method for Large Mini-batch: Training ResNet-50 on ImageNet in 35 Epochs[J]. arXiv preprint arXiv:1811.12019, 2018.
-完-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:进群-姓名-研究方向,即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~



