面经 | 搜狗算法面经
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:要offer不要oppo
https://www.nowcoder.com/discuss/231973
本文已由作者授权,未经允许,不得二次转载
1. 手撕算法题,最优解决旋转数组中寻找目标值
leetcode 33
2. 神经网络权重是否可以初始化为0
不可以,准确的说,是不可以初始化为相同的值。后面两张有关公式推导的图片,是摘抄自知乎某博主。
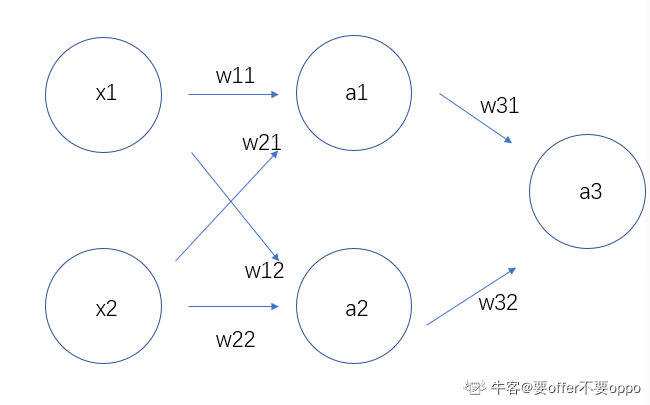


可见经公式推导后,如果神经网络的权值初始化为相同的值,那么会导致神经网络在无论反向传播多少次,都无法改变它对称的事实。这个对称是指,比如某模型为y=0.3*体重+0.3*身高,那么无论多少次网络迭代,模型的特征前的系数依旧是相等,使得网络无法收敛。
3. 神经网络的权值可以初始化为很大的值嘛?
也不可以。其实有关神经网络初始值的设定,是个很大的课题,甚至出过很高质量的论文。初始化为很大的值,会使得反向传播时出现梯度爆炸的情况。
4. 为什么会出现梯度消失与梯度爆炸
https://www.cnblogs.com/pinking/p/9418280.html
说的非常好了。这是以及激活函数的演化与改进也是面试常考的点,同时也是深度学习的一大课题。
5. 讲讲常见的优化器
这个又是深度学习的一大课题。一般应付面试官,讲四个即可,比较有代表性,也比较连贯。它们分别是SGD、Momentum、AdaGrad、adam。
SGD
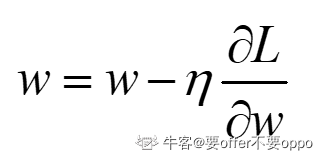
简单好理解,但是其存在的缺陷是,只有当自变量是一个维度的时候,它的前进方向才是真正梯度下降的方向。当存在多维变量时,若某一维度的梯度过大,会使得下降方向在该梯度方向的分量过大,偏离了真正的轨道。
下面两个优化器,便是对它的优化
Momentum
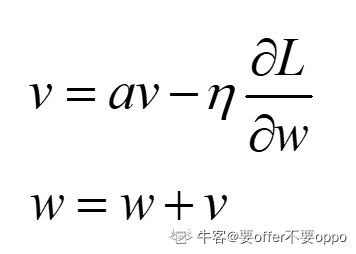
其公式意义为,如果一直朝着某个方向前进,那么在这个方向上的梯度会越来越大。当使用SGD时,会出现过度振荡,徘徊前进,而在这个过程中其实那个梯度分量过大的方向的梯度其实在慢慢减小的,原本梯度分量较小的方向在慢慢增大,动量思想可以放大这个过程,使得模型尽快收敛。
AdaGrad
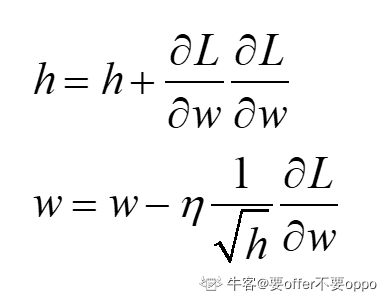
其与动量思想殊途同归,用不同的方法解决相同的问题。h是梯度累积和,求梯度更新的时候,除以它,可以有效的削减大梯度,利于小梯度方向。
Adam
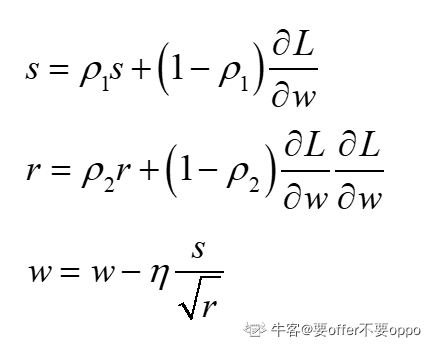
adam综合以上两个优化器的思想,集他们的大成。动量是当前的瞬时梯度越大,那么越快,AdaGrad是如果当前梯度大,就极速削减。其实就好比精确率和召回率他们可以指代不同的指标,而F1分数集合它俩,取了一个均衡。
6. 如果训练模型出现验证误差上下波动比较大,不收敛,这是为什么?
batch选择的太小了。设想一下,如果batch=1的情况下,一次训练样本就一个,随机性太大。很可能这次抽中的样本比较好,第二次抽中的就很差。
---End---
如果你想要了解更多算法岗实习和校招内推,以及算法面试经验和面试题,欢迎加入AI算法岗求职群,详情请见:重磅!2019 AI算法岗求职群来了
2019AI算法岗求职群(知识星球)
本星球不仅面向今年(2020届)找工作和找实习的学生(研一/研二/大三等),还面向刚入学或已工作的人群。目前已有超过1480+位同学加入。星球旨在分享AI算法岗的秋招准备攻略(含刷题)、面试经验和校招/社招/实习的内推机会(含提前批)、学习路线、知识题库和Offer如何选择等。
希望这个星球可以让你少走一些弯路
扫码进星球
如果喜欢招聘/面经/内推,麻烦给个在看
麻烦给我一个在看!




