腾讯算法大赛-社交广告APP转化率预测总结与源码分享(决赛第26名)

大数据挖掘DT数据分析 公众号: datadw
本文个别公式为正常显示,详细请查看原文:
https://jiayi797.github.io/2017/06/07/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E8%B7%B5-CVR-Tencent_CVR%E9%A2%84%E4%BC%B0%E5%88%9D%E8%B5%9B%E6%80%9D%E8%B7%AF%E6%80%BB%E7%BB%93/
本文代码获取:
回复公众号 datadw 关键字"腾讯"即可。
正文:
“这一段奔波太过匆忙,有时来不及回头张望。”
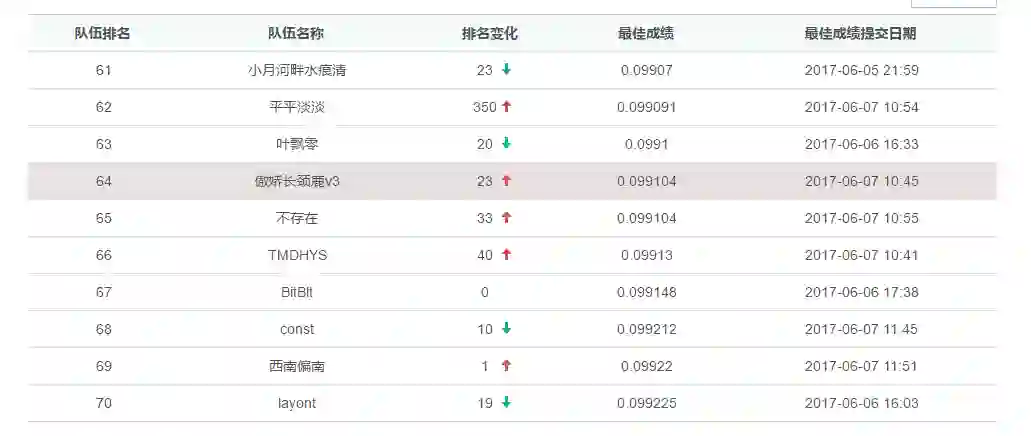
腾讯“人工寻找trick”大赛初赛今天结束了。最终初赛线上logloss为0.099104,排名为64名:
复赛成绩0.101941,排名26名: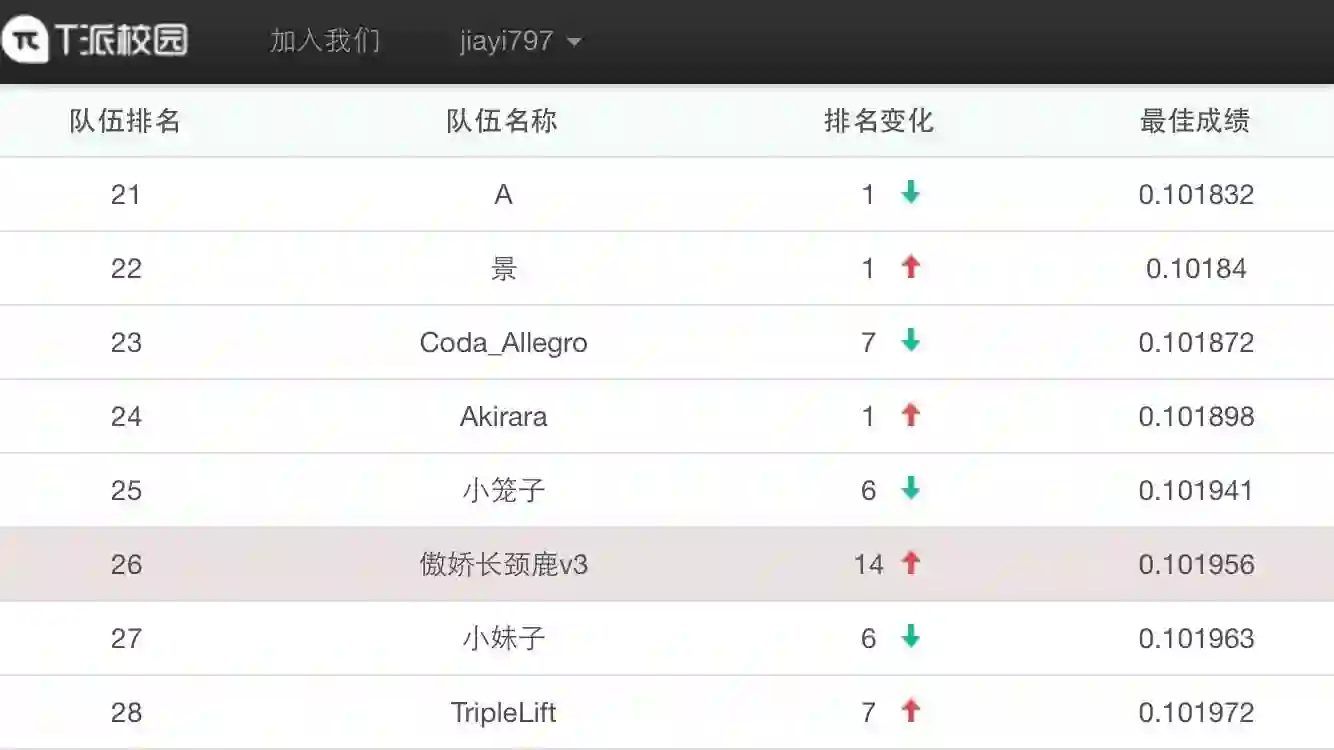
虽然与前排大神的分相差甚远,虽结果不那么如人意,也是对这个领域入了个门。
1. 赛题
详细赛题见官方网站
已知:17-30天移动APP的广告、用户的转化情况,及相关上下文。
预测:第31天指定用户和对应广告的转化率。
循环特征消减:其实就是循环地移除变量和建立模型,通过模型的准确率来评估变量对模型的贡献。这种方式很暴力,但也很准确。但是问题是我们没有那么多的时间来等待模型训练这么多次。
特征重要性评级:“组合决策树算法”(例如Random Forest or Extra Trees)可以计算每一个属性的重要性。重要性的值可以帮助我们选择出重要的特征。
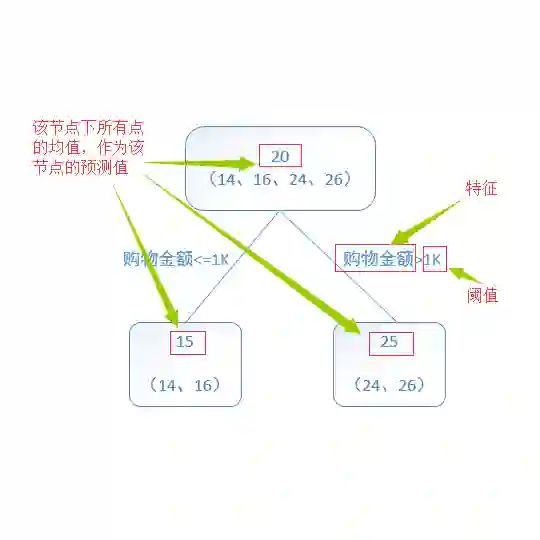
首先要切分数据集,一部分用于训练GBDT,另一部分使用训练好的GBDT模型
GBDT模型的apply方法生成x在GBDT每个树中的index,然后通过onehot编码做成特征。
新的特征输入到分类(如LR)模型中训练分类器。
Trick特征:
通过观察原始数据是不难发现的,有很多只有clickTime和label不一样的重复数据,按时间排序发现重复数据如果转化,label一般标在头或尾,少部分在中间,在训练集上出现的情况在测试集上也会出现,所以标记这些位置后onehot,让模型去学习,再就是时间差特征,关于trick我比赛分享的这篇文章有较详细的说明。比赛后期发现了几个和这个trick相类似的文章1和文章2,可以参考。统计特征:
原始特征主要三大类:广告特征、用户特征、位置特征,通过交叉组合算统计构造特征,由于机器限制,统计特征主要使用了转化率,丢掉了点击次数和转化次数。初赛利用了7天滑窗构造,决赛采用了周冠军分享的clickTime之前所有天算统计。三组合特征也来自周冠军分享的下载行为和网络条件限制,以及用户属性对app需求挖掘出。贝叶斯平滑user相关的特征特别废时间,初赛做过根据点击次数阈值来操作转化率,效果和平滑差不多但是阈值选择不太准。活跃数特征:
特征构造灵感来自这里,比如某个广告位的app种数。
均值特征:
比如点击某广告的用户平均年龄
平均回流时间特征:
利用回流时间方式不对的话很容易造成leackage,这里参考了官方群里的分享,计算了每个appID的平均回流时间,没有回流的app用其所在类的平均回流时间代替用户流水和历史特征:
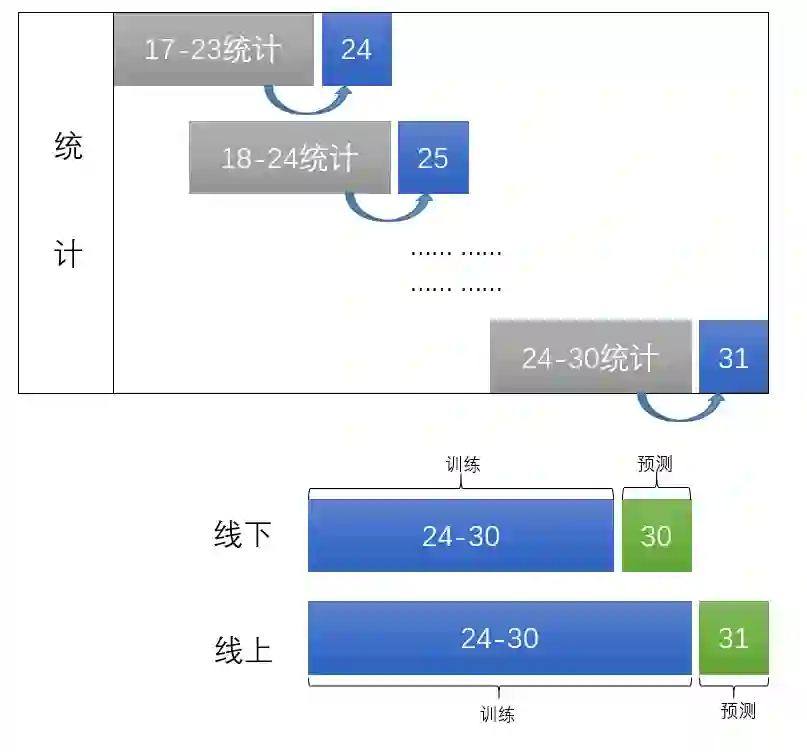
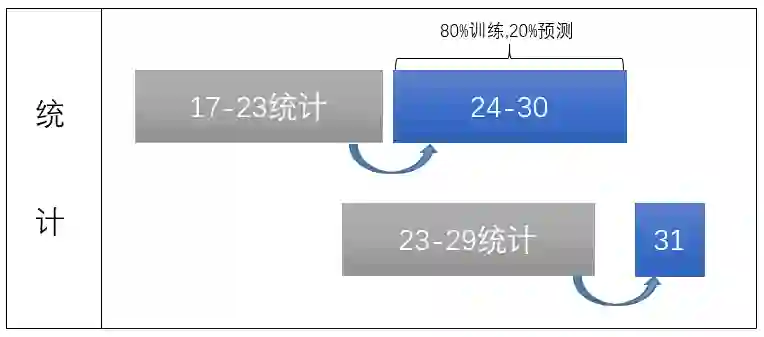
利用installed文件关联user和app获得历史统计特征,利用actions进行7天滑动窗口获得用户和app流水特征。用滑动窗口,即每天的前七天的统计(统计指统计转化量、点击量、转化率,下同)来作为第本天的特征。并拿30号来做线下测试集。
如下图所示:
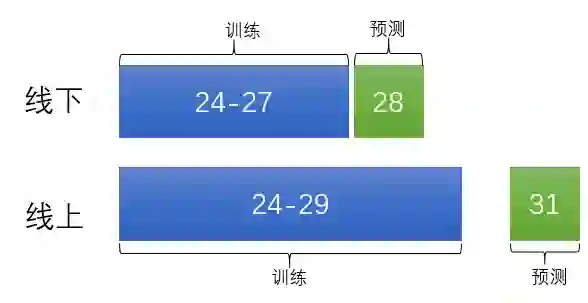
经测试我们发现,即使我们去掉了30号的部分负样本,还是有一些问题的。因此我们将时间区间改了一下:
这样做出于两种目的:一是尽量做到了线上线下统一,二是不让模型学习30号的样本数据,防止一些错误样本被模型学到。用第一周统计,第二周做交叉验证并训练模型。如下图所示:
2. 主要流程
这是Kaggle上数据挖掘比赛的黄金流程图: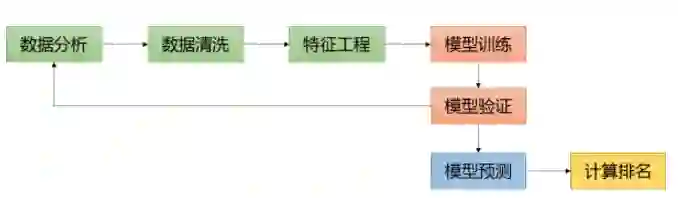
其实对于这个比赛的初赛而言,线上是容易过拟合的。因为线上只有一个集,可反复提交多次来使得线上得分很高,但实际上模型是有些过拟合的。不过这不是重点。
接下来一步步做说明
3. 数据分析与清洗
训练集train.csv没有大问题,我注意的只是后几天的一些数据没有回流的问题。
值得注意的是,本次竞赛的训练数据提供的截止第31天0点的广告日志,因此,对于最后几天的训练数据,也就是说后五天部分用户实际上是转化了,但广告主还没有来得及将这条转化汇报给广告系统,导致数据集中的label被误标记为了0(实际上是1)。(如果我还没有描述清楚,这里具体可以看官网赛题FAQ.1)
这里我采取了一种很暴力的方法,即去掉每个广告主最后一次回流之后的数据。
通过分析我们发现,其实有近一半的广告主还是尽职尽责的,直到30号23点还在反馈回流。只有有一部分广告主在30号下班后,或29号下班后就不回流了。所以我们将这些广告主最后一次回流之后的数据都删除(其实这些都是负样本),这样就在一定程度上减少了不准的负样本。
这样筛去了大概有3万条,也不算多。
4. 特征工程
一开始的时候我们采用了很多基本特征,即各种ID(AppID,UserID,creativeID,pisitionID等)的onehot编码,又对单特征进行了一定的统计。后来看了大神“为情所困的少年”的分享,才反应过来其实无论是onehot还是对ID单维度的统计特征,其实都是对于一个特征的一种表达,从一定意义上是重复的。我个人感觉onehot之后的稀疏特征更适合于线性模型,如LR;而统计量的连续特征更适合于树模型,如GBDT。
回头来看,其实特征工程需要根据模型预先选择方向。李沐说过,模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
就此题来说,有两个方向:
4.1. 海量离散特征+简单模型
如果我们懒得分析数据(初期我们就是这样),并且有还不错的设备(自以为64G内存很有优势),我们可以直接选择这个方向。
初期的时候,我们是选择的这条路。
当时只有简单的ID类特征,以及ID类特征的交叉组合,将这些特征onehot之后输入了LR模型。
关于特征组合,我在后面会介绍到。
做完特征和特征组合,将它onehot之后输入模型就可以了。
对于LR这种线性模型来说,它更适合于onehot类型的特征,首先它对于稀疏高维特征处理是无压力的,其次离散化后的特征对异常数据有很强的鲁棒性,这些在参考文献2逻辑回归LR的特征为什么要先离散化中可以看到。
但由于ID类特征非常多,例如本题的UserID有好几百万个。这时就会带来维度灾难问题,见参考文献4机器学习中的维度灾难。不仅如此,这时基本上也就被设备问题限制死了。这很烦。于是我们就换模型了。
4.2. 少量连续特征+复杂模型
这是我们暂定的一个方案,就是采用少量、但表现很不错的组合特征统计量,以及一些手工提取的特征(如用户历史安装次数、APP历史被安装次数),这些特征主要来源于群内“为情所困”大神分享的一张表。
模型我们采用的是GBDT,直接使用了陈天奇大牛的xgboost框架。模型我暂时还没有很认真地研究,只是熟悉了一些参数,为决赛做了一些准备。
5. 特征组合
特征组合真是我遇到的一个大难题。
5.1. 怎么表达组合特征?
说到特征组合,从统计的角度解释,基本特征仅仅是真实特征分布在低维空间的映射,不足以描述真实分布,加入组合特征是为了在更高维空间拟合真实分布,使得预测更准确。
组合特征我现在用过的有以下两种方式:
对离散ID进行hash生成新特征
在初期用LR的时候,我们采用的方式是hash。即对两个ID做hash运算,得到一个新特征。这是一个很巧妙的方法。例如下面这个表,我们做哈希:
得到第三列:
| age | gendar | hash |
|---|---|---|
| 1 | 0 | 10 |
| 2 | 1 | 21 |
| 3 | 2 | 32 |
第三列的的特征的取值有两位,十位是age,个位是gendar。新特征是一种新的交叉特征的体现。
对组合进行统计生成新特征
像之前“为情所困”大神说过的那样,其实无论onehot还是统计特征,其实都是对于一个特征的一种表达。因为后期我们采用了GBDT,因此我们弃用了之前的hash组合方式,而选用统计量(即点击量、转化量和转化率)。这样就在一个维度上表达了这两个特征的组合,而且非常便于计算。
5.2. 选谁做特征组合?
需要注意的是,特征组合也不是随便从原来的特征里摘出来两列就做组合。这种随意地对特征堆叠其实会增加模型的负担,而且这些其实就像是“随机数一般的,毫无作用的特征”,可能会使得效果变差。
究竟对谁做组合,这也是一直困扰我们的问题。以下是我搜集到的几种方案:
迭代选取方式
Jerrylin大神曾经说过,可以先对一个组合做groupby分析,看看转化率的分布。可是我遇到了一个瓶颈——大多数特征的转化率分布都是不均匀的,组合起来就更不均匀了。不知道大神是怎么解决的,也许是计算这个分布的方差?【这是个问题,等来日解决,我再回来填坑】
大神刚才回我了,他说他是按照gbdt给的一个评分,选取评分较高的几个进行组合,然后再次输入模型进行迭代筛选。
在此我要再次偷偷感谢一下这位大神。要是没有他,我可能还会在二百名外挣扎。
刚才风,飞扬。。大神告诉我,其实xgb给的评分也是只能作为一个参考,因为不一定组合之后给会更高。
忆『凌』殇大神说,构造的特征很可能相关性很高,然后这两个特征的重要性肯定都不低。但是因为相关性高反而会影响性能。这个相关性可以计算这两个特征的相关系数corrcoef来得到。
穷举后用卡方检验筛特征
参考文献描述量选择及特征的组合优化提到,由于任何非穷举的算法都不能确保所得结果是最优的,因此要得最优解,就必需采用穷举法,只是在搜索技术上采用一些技巧,使计算量有可能降低。
我的学长“酱紫”对此有一种建议就是直接对所有基本特征进行遍历两两组合,然后用卡方检验筛出来一些比较好的特征。这种方式很简单,大多数工作只需要交给模型来完成。
循环特征消减和特征重要性评级
参考文献scikit-learn系列之特征选择中提到,在scikit-learn中有两种特征选择的方法,一种叫做循环特征消减(Recursive Feature Elimination)和特征重要性评级 (feature importance ranking)。
用GBDT筛特征
主要思想:
GBDT每棵树的路径直接作为LR输入特征使用。
原理:
用已有特征训练GBDT模型,然后利用GBDT模型学习到的树来构造新特征,最后把这些新特征加入原有特征一起训练模型。构造的新特征向量是取值0/1的,向量的每个元素对应于GBDT模型中树的叶子结点。当一个样本点通过某棵树最终落在这棵树的一个叶子结点上,那么在新特征向量中这个叶子结点对应的元素值为1,而这棵树的其他叶子结点对应的元素值为0。新特征向量的长度等于GBDT模型里所有树包含的叶子结点数之和。
【这里其实不太懂,一会问问张思遥】
步骤:
实现:
参考文献GBDT原理及利用GBDT构造新的特征-Python实现的末尾有一个调用GBDT训练模型构建树,调用apply()方法得到特征,然后将特征通过one-hot编码后作为新的模型输入LR进行训练。feature trainsformation with ensembles of tree官方文档
5.3. 本赛题特征构造
竟然有这种操作队分享总结得非常好,主要特征是分为以下几类:
5.4. 一些特殊的东西
多线程抽特征
决赛数据集太大,而我们组合特征非常多。因此我们采用了多线程抽特征的方式。
代码见TencentAD_contest,extra_rate_thread_0623.py
贝叶斯平滑
在决赛时,我们还使用了贝叶斯平滑。针对Pandas,我们对网上已有的代码进行了改进。
贝叶斯平滑笔记
word embedding
这个我没有做过多研究,这里是word embedding笔记
SVD分解
思路和代码主要看我这篇博客SVD分解
6. 训练集构造
训练集特征做不好,就很容易造成泄露。这是我试过的两种方式:
相信很多人都用的是这两种其中的一种。我是一个对自己极度不自信的人,来来回回换了好几次。最终觉得第2种方式很稳定,线上线下较统一。第1种方式特征更新较快,模型更准确,但带来的问题就是线上线下不太统一。
7. 模型训练和验证
至此特征工程已经完毕,开始训练。
训练其实没什么好说的,只要注意一下别过拟合就可以。
初赛我们采用的xgboost,决赛用的lightgbm。其实都是对GBDT的实现,两者都很好,但lightGBM更快一些,因为它只对部分节点进行生长。
7.1. stacking
在初赛的时候听到最多的就是stacking魔法了。文章【SPA大赛】腾讯广告点击大赛:对stacking的一些基本介绍非常详细地介绍了stacking大法。我觉得这句话很好:“在我看来stacking严格来说不能称为一种算法,我理解的是一种非常精美而复杂的对模型的集成策略。”
8. 总结
平时在学习的过程中,过于注重理论的推导,只是在一遍遍地看那些公式。但没有切身实践过,感受不到模型真正的威力和缺憾。通过这次比赛,还是收获比较多的。注意到了平时学习过程中自以为不重要的、很容易被忽略的细节。
在初赛中,我们其实并没有注重模型的调参等,而是一直在做特征工程。其实我初期也不知道究竟该怎么办。但JerryLin大神用他的言行教会我,特征决定了结果的上限,而模型只是在不断地逼近这个上限而已。只有得到了好的特征,才会拿到好的模型。
做了这么久的特征工程,最大的感想就是,只有认认真真、踏踏实实分析数据,才能得到好的特征。过度依赖算法在工业上是不可靠的。
越来越发现务实基础的必要性。比如LR中为什么要采用正则化项,为什么GBDT能有筛特征的功效,为什么树模型容易过拟合,为什么为什么……这些为什么直接决定了在遇到问题的时候能不能独立解决。而不能像我现在一样,分分钟心态爆炸,宛如一只无头的苍蝇。
还有就是,写代码一定要认认真真地写。不能直接把别人的直接粘过来用,这样是极其不负责的,也非常容易出错。在比赛的过程中,我的xgboost预测的代码是直接粘贴的O2O优惠券使用预测的冠军的代码,但他那个的目标是auc,因此他将结果映射到了(0,1)区间上。这句话让我白白浪费了很久很久的时间去试特征,结果发现线上线下不统一,整个人直接崩溃。
希望自己在未来的日子里,能将周志华老师的《机器学习》和李航老师的《统计学习方法》这两本书吃透,而不是像现在这样,狗熊掰棒子。
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注