NLP大赛冠军总结:300万知乎多标签文本分类任务(附深度学习源码)
七月,酷暑难耐,认识的几位同学参加知乎看山杯,均取得不错的排名。当时天池AI医疗大赛初赛结束,官方正在为复赛进行平台调试,复赛时间一拖再拖。看着几位同学在比赛中排名都还很不错,于是决定抽空试一试。结果一发不可收拾,又找了两个同学一起组队(队伍init)以至于整个暑假都投入到这个比赛之中,并最终以一定的优势夺得第一名。
1. 比赛介绍
这是一个文本多分类的问题:目标是“参赛者根据知乎给出的问题及话题标签的绑定关系的训练数据,训练出对未标注数据自动标注的模型”。通俗点讲就是:当用户在知乎上提问题时,程序要能够根据问题的内容自动为其添加话题标签。一个问题可能对应着多个话题标签,如下图所示。
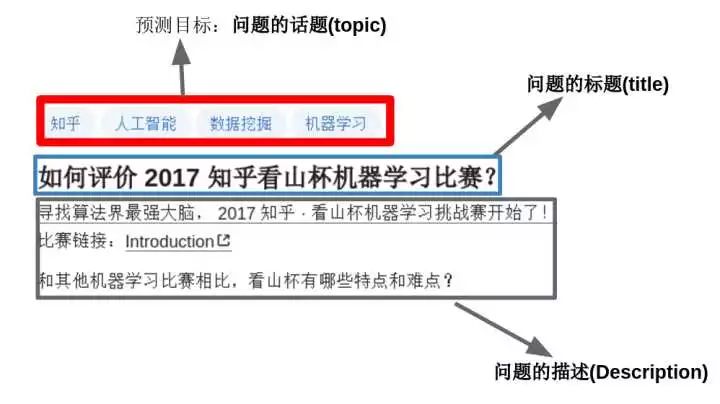
这是一个文本多分类,多label的分类问题(一个样本可能属于多个类别)。总共有300万条问题-话题对,超过2亿词,4亿字,共1999个类别。
1.1 数据介绍
参考 https://biendata.com/competition/zhihu/data/
https://biendata.com/competition/zhihu/rules/?next_url=%2Fcompetition%2Fzhihu%2Fdata%2F
总的来说就是:
数据经过脱敏处理,看到的不是“如何评价2017知乎看山杯机器学习比赛”,而是“w2w34w234w54w909w2343w1"这种经过映射的词的形式,或者是”c13c44c4c5642c782c934c02c2309c42c13c234c97c8425c98c4c340"这种经过映射的字的形式。
因为词和字经过脱敏处理,所以无法使用第三方的词向量,官方特地提供了预训练好的词向量,即char_embedding.txt和word_embedding.txt ,都是256 维。
主办方提供了1999个类别的描述和类别之间的父子关系(比如机器学习的父话题是人工智能,统计学和计算机科学),但这个知识没有用上。
训练集包含300万条问题的标题(title),问题的描述(description)和问题的话题(topic)
测试集包含21万条问题的标题(title),问题的描述(description),需要给出最有可能的5个话题(topic)
1.2 数据处理
数据处理主要包括两部分:
char_embedding.txt 和 word_embedding.txt 转为numpy格式,这个很简单,直接使用word2vec的python工具即可
对于不同长度的问题文本,pad和截断成一样长度的(利用pad_sequence 函数,也可以自己写代码pad)。太短的就补空格,太长的就截断。操作图示如下:
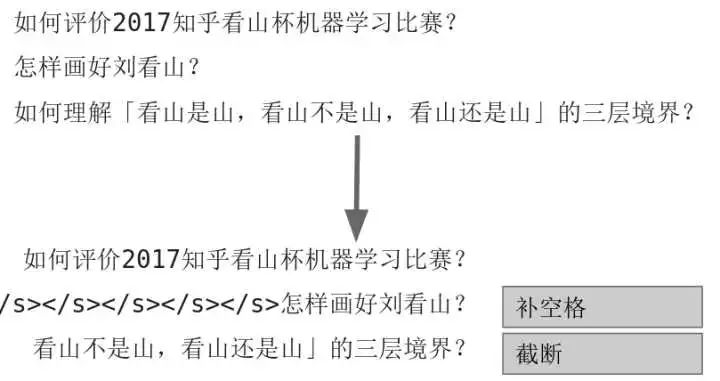
1.3 数据增强
文本中数据增强不太常见,这里我们使用了shuffle和drop两种数据增强,前者打乱词顺序,后者随机的删除掉某些词。效果举例如图:

1.4 评价指标
每个预测样本,提供最有可能的五个话题标签,计算加权后的准确率和召回率,再计算F1值。注意准确率是加权累加的,意味着越靠前的正确预测对分数贡献越大,同时也意味着准确率可能高于1,但是F1值计算的时候分子没有乘以2,所以0.5是很难达到的。
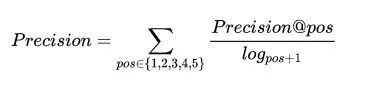
2 模型介绍
建议大家先阅读这篇文章,了解文本多分类问题几个常用模型:用深度学习(CNN RNN Attention)解决大规模文本分类问题
https://zhuanlan.zhihu.com/p/25928551
2.1 通用模型结构
文本分类的模型很多,这次比赛中用到的模型基本上都遵循以下的架构:
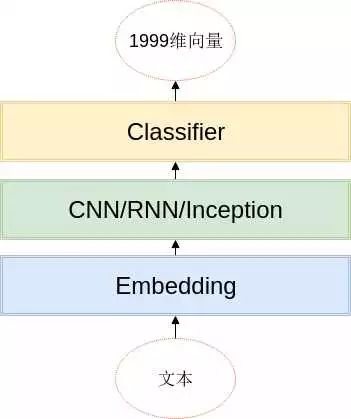
基本思路就是,词(或者字)经过embedding层之后,利用CNN/RNN等结构,提取局部信息、全局信息或上下文信息,利用分类器进行分类,分类器的是由两层全连接层组成的。
在开始介绍每个模型之前,这里先下几个结论:
如果你的模型分数不够高,试着把模型变得更深更宽更复杂
当模型复杂到一定程度的时候,不同模型的分数差距很小
当模型复杂达到一定程度,继续变复杂难以继续提升模型的分数
2.2 TextCNN
这是最经典的文本分类模型,这里就不细说了,模型架构如下图:
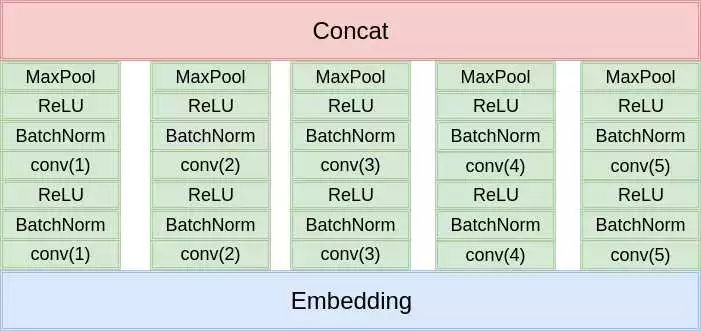
和原始的论文的区别就在于:
使用两层卷积
使用更多的卷积核,更多尺度的卷积核
使用了BatchNorm
分类的时候使用了两层的全连接
总之就是更深,更复杂。不过卷积核的尺寸设计的不够合理,导致感受野差距过大。
2.3 TextRNN
没找到论文,我就凭感觉实现了一下:
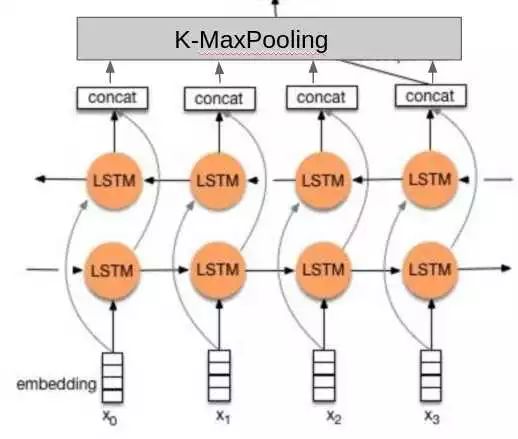
相比于其他人的做法,这里的不同点在于:
使用了两层的双向LSTM。
分类的时候不是只使用最后一个隐藏元的输出,而是把所有隐藏元的输出做K-MaxPooling再分类。
转自:大数据挖掘DT数据分析
完整内容请点击“阅读原文”



