深度点击率预估模型趋势总结
分享嘉宾:张伟楠 上海交通大学
出品平台:DataFunTalk
导读:针对点击率预估场景,整个领域的技术演进经历了从早期大量人工特征工程到基于因子分解机的模型变种,再到深度神经网络进行自动特征学习的趋势,整体上模型能力越来越强,手工特征和数据处理的比重也逐渐降低。然而,近年来业界又重新开始关注数据本身的交互和处理,针对该新趋势,今天和大家分享上海交通大学张伟楠副教授基于数据交互的点击率预估模型的研究。
今天的介绍会围绕下面五点展开:
深度点击率模型回顾
基于数据交互的点击率模型RIM
实验小结
总结展望
精彩问答
01
深度点击率模型回顾
我们主要关注的领域是搜广推(搜索、广告、推荐),目标是在这样的场景下去预测一个展示广告如何能获取用户点击。基本逻辑可以转化为多域的数据类型建模,比如获取了时间、地点、网页类型、链接地址、广告类型、用户标签等信息后,去预测用户最终点击与否,这是一个二分类问题,最终给出预测反映点击的概率(CTR)。在CTR预估的问题上,数据基本以类别型数据为主,虽然有少部数值型字段,一般采用分桶操作转化为类别型来处理。由于采用二分类方式建模,所以常用的损失函数设计为交叉熵损失。
1. 点击率模型技术演进

点击率预估模型从早期的LR (逻辑回归)结合大量人工特征工程处理,过渡到通过因子分解形式实现二阶或高阶特征交叉,后面开始利用AutoML和深度神经网络技术实现自动特征构建。整个技术演进中模型的能力和复杂度越来越高,而特征和数据处理的比重经历了下降又上升的阶段。本次报告从已经走入深度学习阶段的点击率模型开始,讲解前期从特征交互到后期数据交互的过渡过程,并重点针对数据交互相关的RIM模型进行介绍。
2. 基于特征交互建模

多域类别型数据使用One-Hot Encoding的方式可以将数据转化为高维稀疏向量,标签为0(不点击)或1(点击),使用最简单的逻辑回归模型即可实现最基本的CTR建模,通过随机梯度下降进行参数的更新实现模型的学习。
① FM (Factorization Machines,因子分解机)
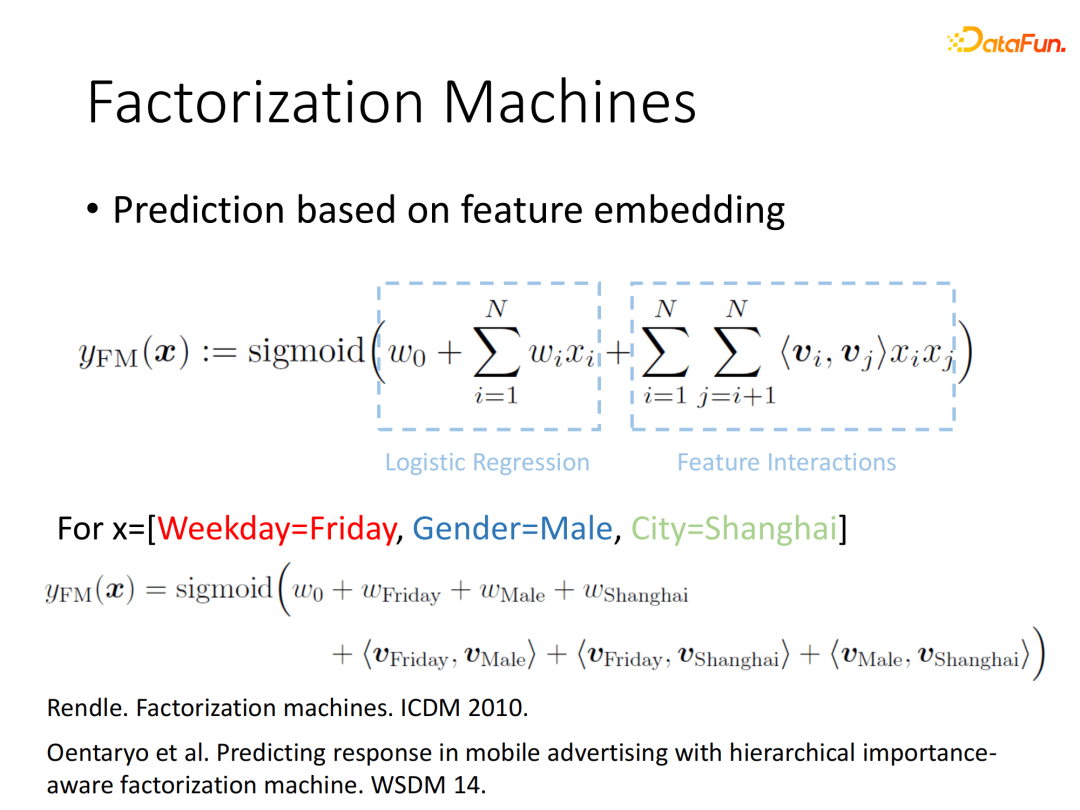
发展到2010年之后,因子分解机(Factorization Machine,FM)被提出。FM是一个影响力极大的模型,可看作传统逻辑回归加上高阶特征交叉项,其中二阶交叉使用最为普遍。通过因子分解的机制将高阶交叉项的参数转换为隐向量的内积,达到降低参数量并自动学习的目的。其中某一组交叉特征对模型影响较大,对应的隐向量内积也会较大。
② FNN (Factorization-machine supported Neural Networks)
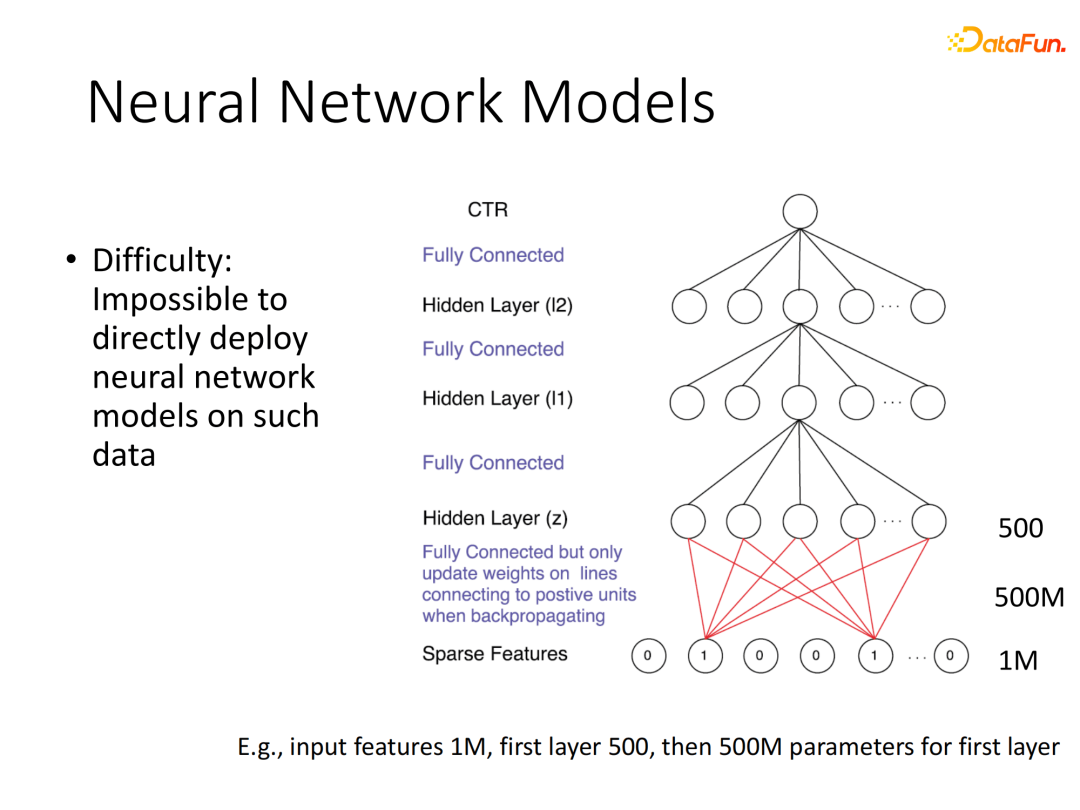
当深度学习开始变得火热之后,人们惊讶于深度神经网络自动学习数据有效表征的能力,从事信息检索相关研究工作的学者都开始考虑能否将深度学习用于CTR的建模。比如直接将稀疏表示的多域信息输入全连接网络,这个方法理论上可行,但是实际上难以满足需求,因为输入维度太高会导致网络参数量爆炸。
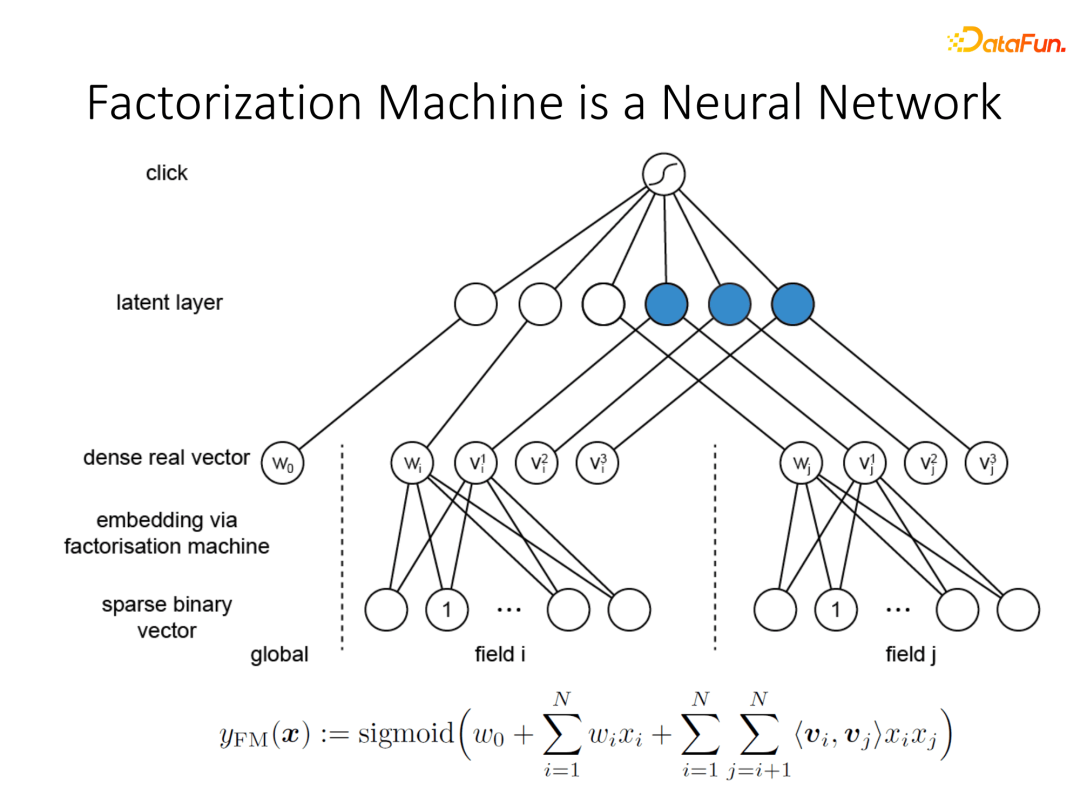
于是学者们把FM依照神经网络计算图的形式进行思考,期望通过定义一些神经网络节点和一些边的取值去模拟FM的结构,比如通过神经元进行二阶交叉的隐向量之间对位相乘后相加,最后加上偏置量和各个域的一阶权重值。但是当时的神经网络设计还没有乘法项,所以无法完全模拟。
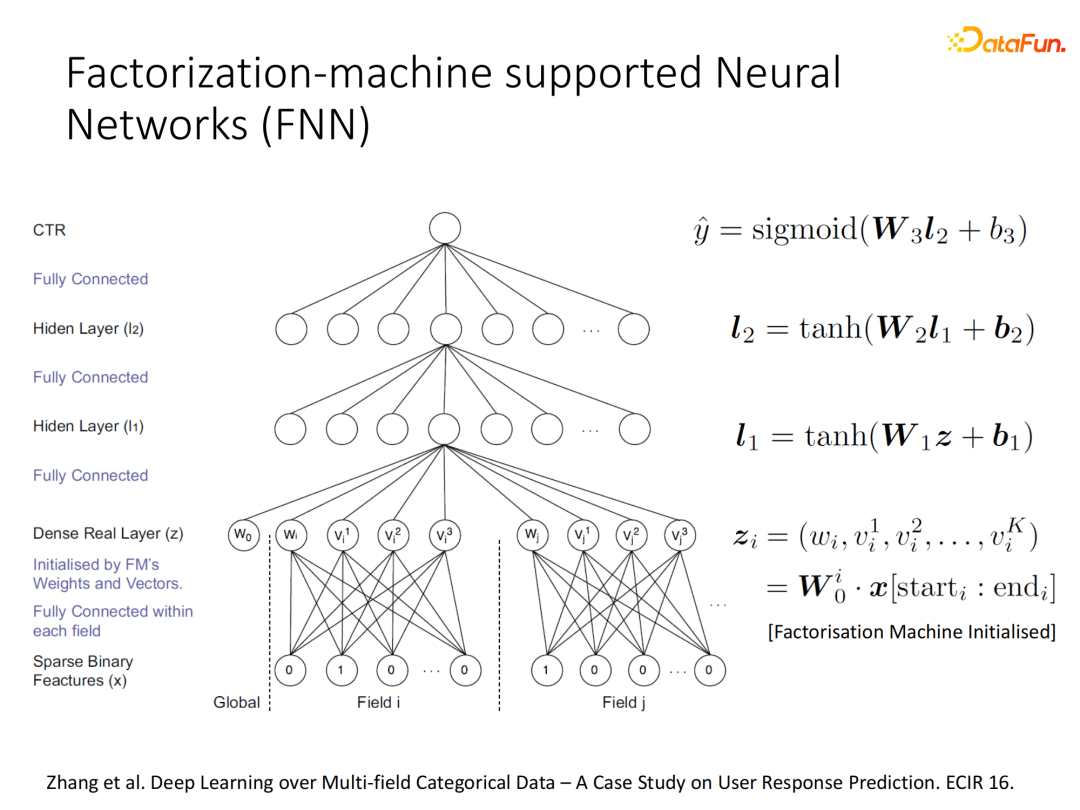
在2016年时我们就设计了这样一个神经网络FNN,网络第一层的输入是使用学习好的FM的各个域隐向量去初始化,此时输入的向量已经非常具有结构化信息了,后续通过多层全连接的方式去进一步进行交叉达到建模目的。通过使用各个域独立的稠密向量表示,可以避免输入维度过高,避免参数量爆炸。
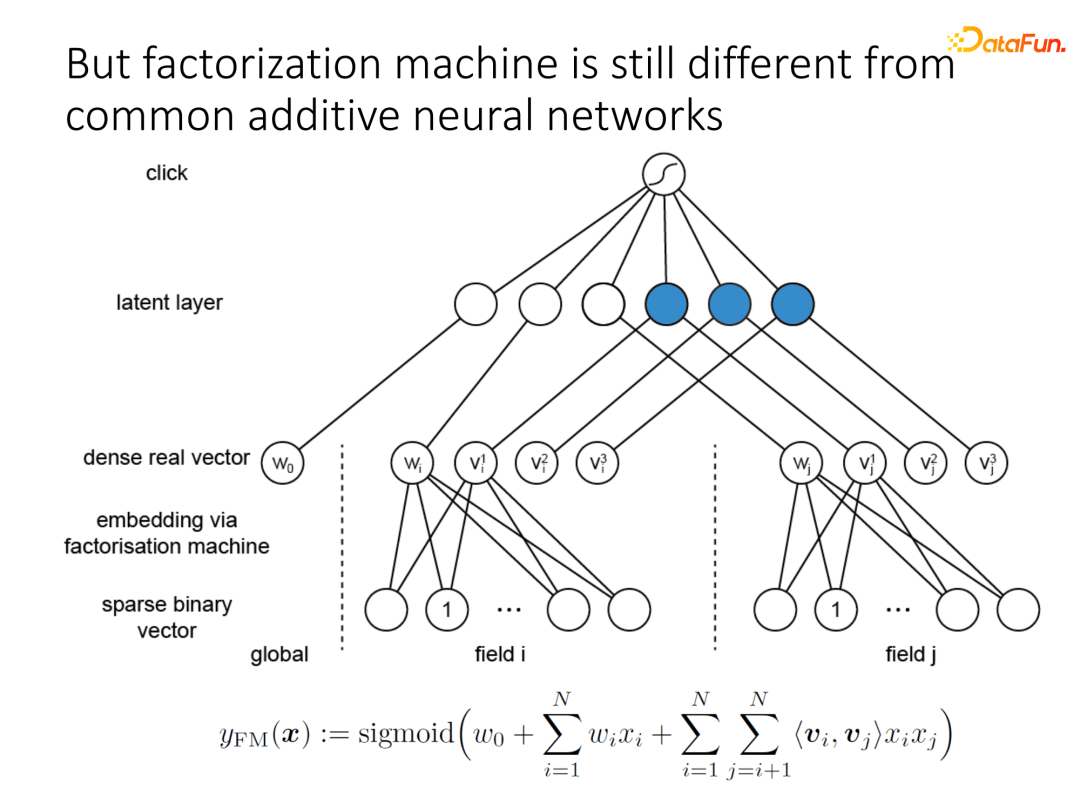
FNN的模型与FM的结构差异比较大,原因在于FNN所构建的交互信息只使用加法算子,只是利用了FM隐向量作为第一层信息,由于没有实现相关乘积操作,单纯通过多层全连接还是有所局限。而乘法算子(即上图中的蓝色节点)能够反映“且”的关系,是实现特征交互的重要操作。
① 基于乘法操作的特征交互
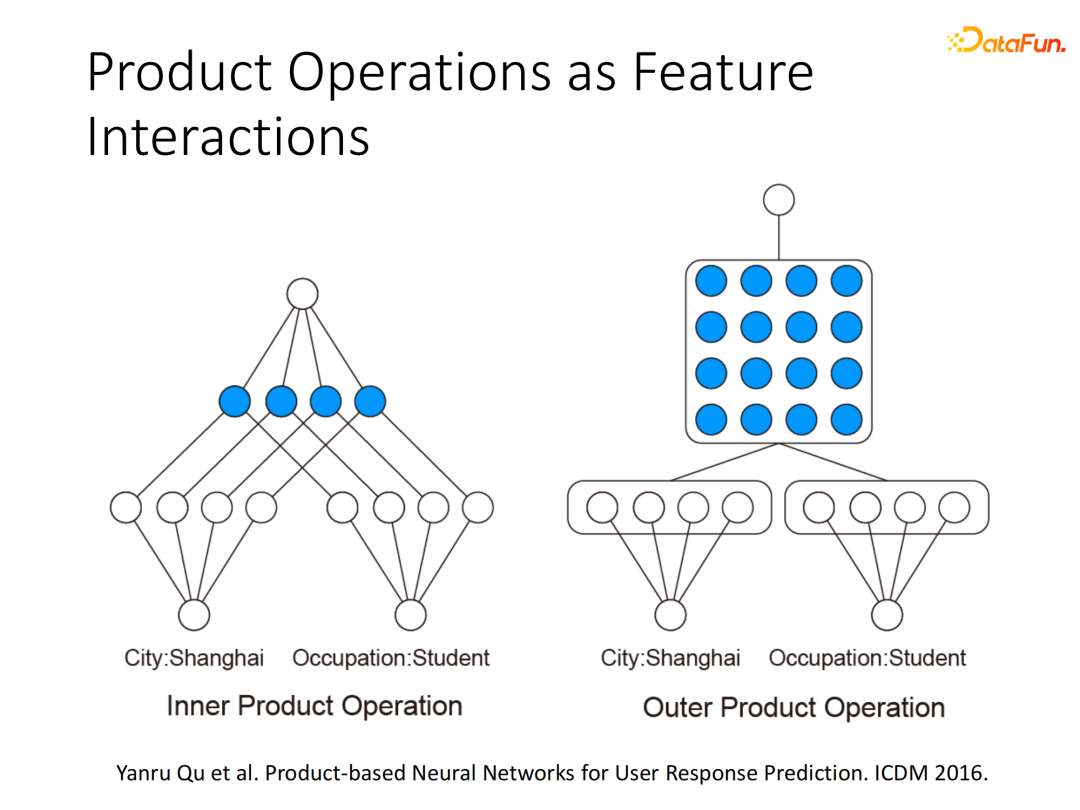
在2016年ICDM的论文里我们提出了显式构建基于内积(inner product)和外积(outer product)的乘法算子嵌入到深度点击率模型中。内积算子各个元素对位相乘后加在一起,外积算子将K维向量与K维向量乘积变为K×K的方阵后将元素加和。
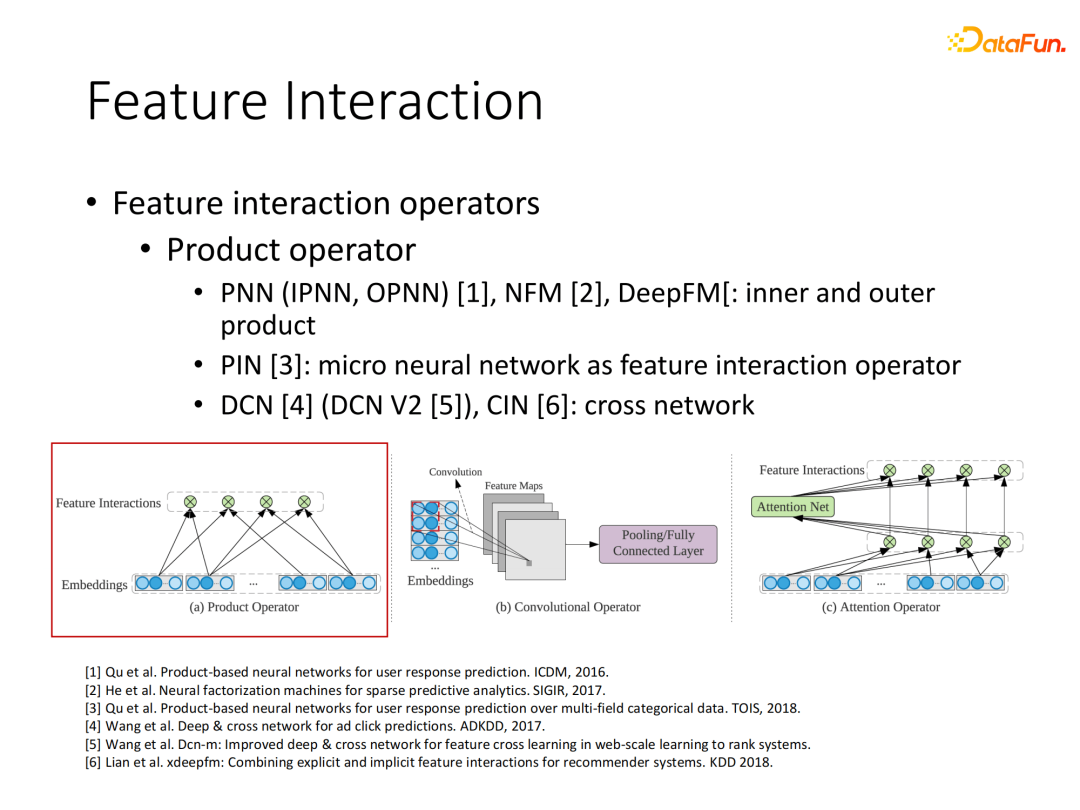
至此,一系列基于乘法操作的特征交互神经网络点击率模型陆续提出,我们总结了实现基于乘法算子的几类模型:基于内外积的结构,如PNN、华为提出的DeepFM模型等;将PNN扩展到更加网络化的结构PIN模型;基于层与层之间交叉的DCN结构。
② 基于卷积操作的特征交互
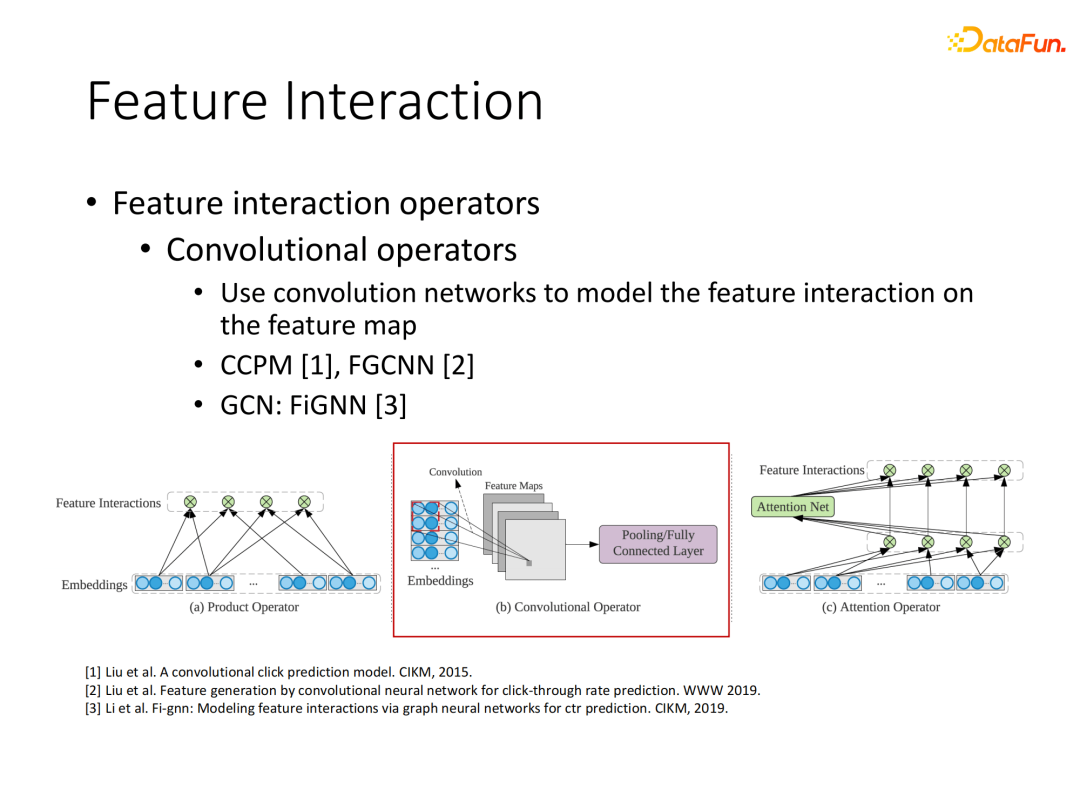
特征交互的另一类操作是使用卷积网络,比如先将原离散域特征映射到embedding空间,然后多个域的embedding合并到一起,可以形成参数矩阵的结构,至此可以借鉴CNN(卷积神经网络)对图像的处理来实现特征交互提取,典型的如早期模型CCPM。该操作的优点是能直接借鉴CNN结构,缺点是CNN只能针对相邻域内的参数进行交互,而原始特征之间是无固定顺序的,这种依赖特征顺序的操作在点击率预估场景有一定局限性。
③ 基于Attention(注意力)机制的特征交互
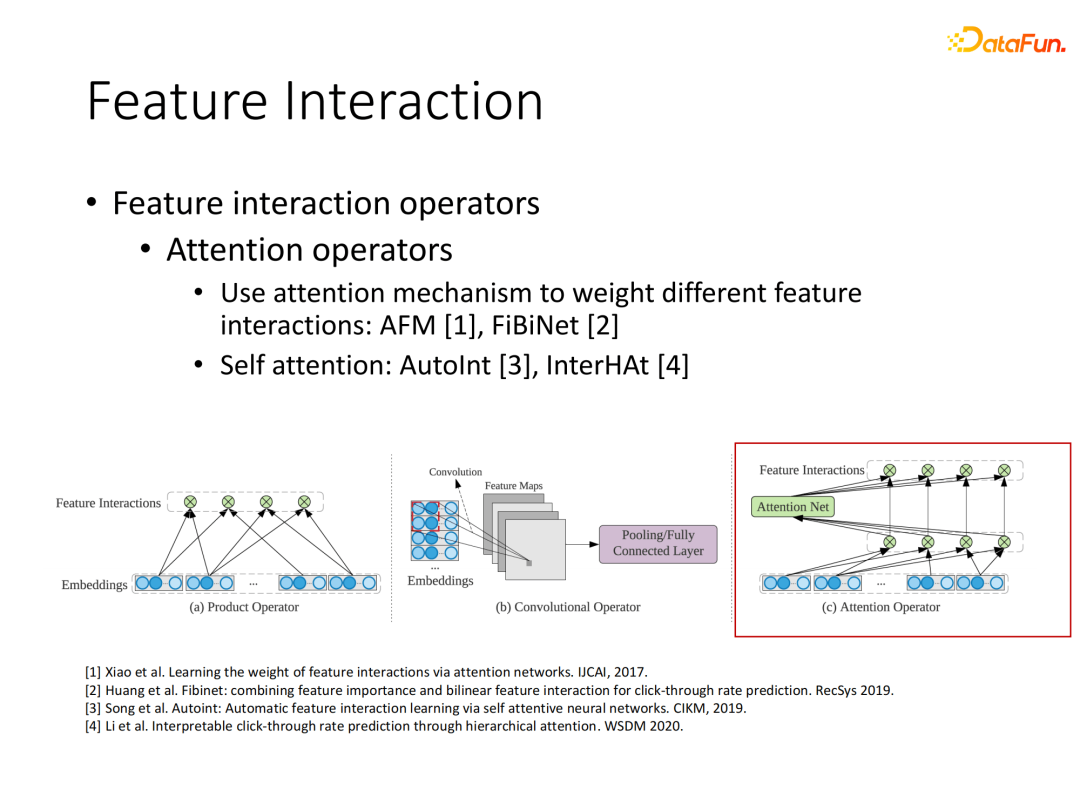
另一类重要的特征交叉是使用Attention机制,在2017年开始通过Attention的计算来让模型自主学习不同交互信息的权重,实现加权聚合,这样对模型越重要的向量就能施加更大的影响力。
3. 基于用户行为序列建模
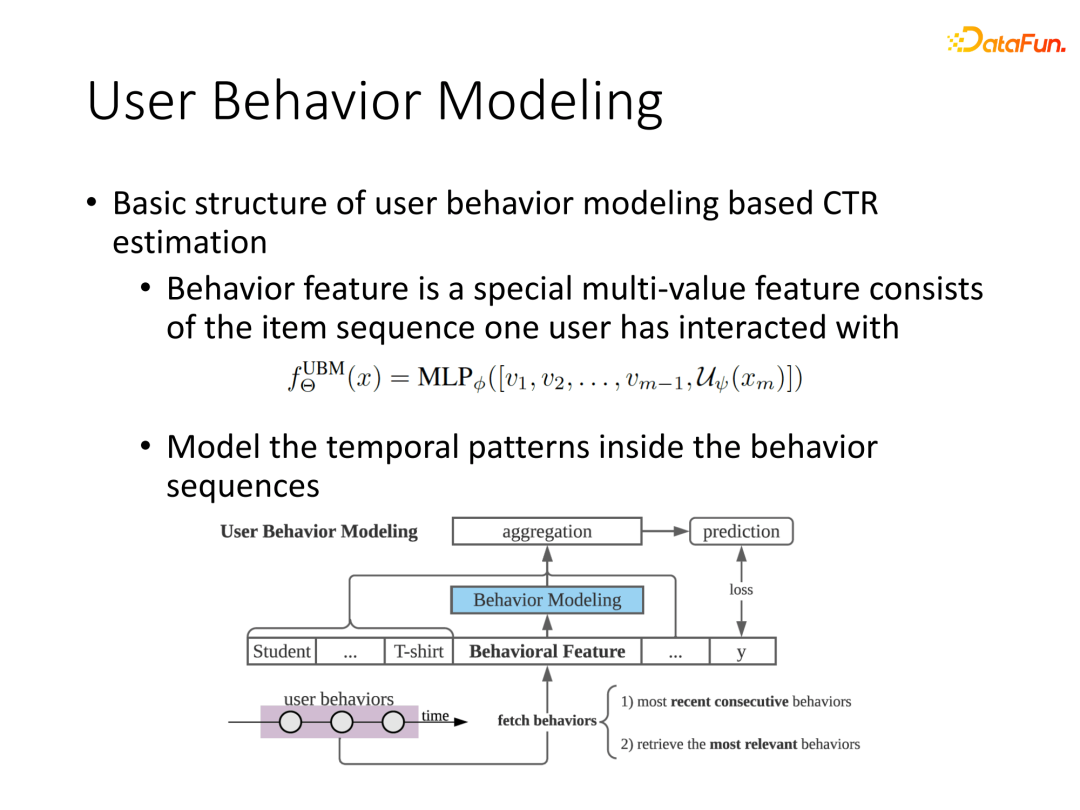
以上内容都只是针对单点的数据进行特征交互提取,而用户历史一系列行为数据是非常丰富的,通过学习用户历史行为信息能较好提高建模效果。放到现在深度神经网络时代,将用户一系列行为进行表征可以作为新增域加入原有多域信息中,最后接入一些交叉网络实现建模。
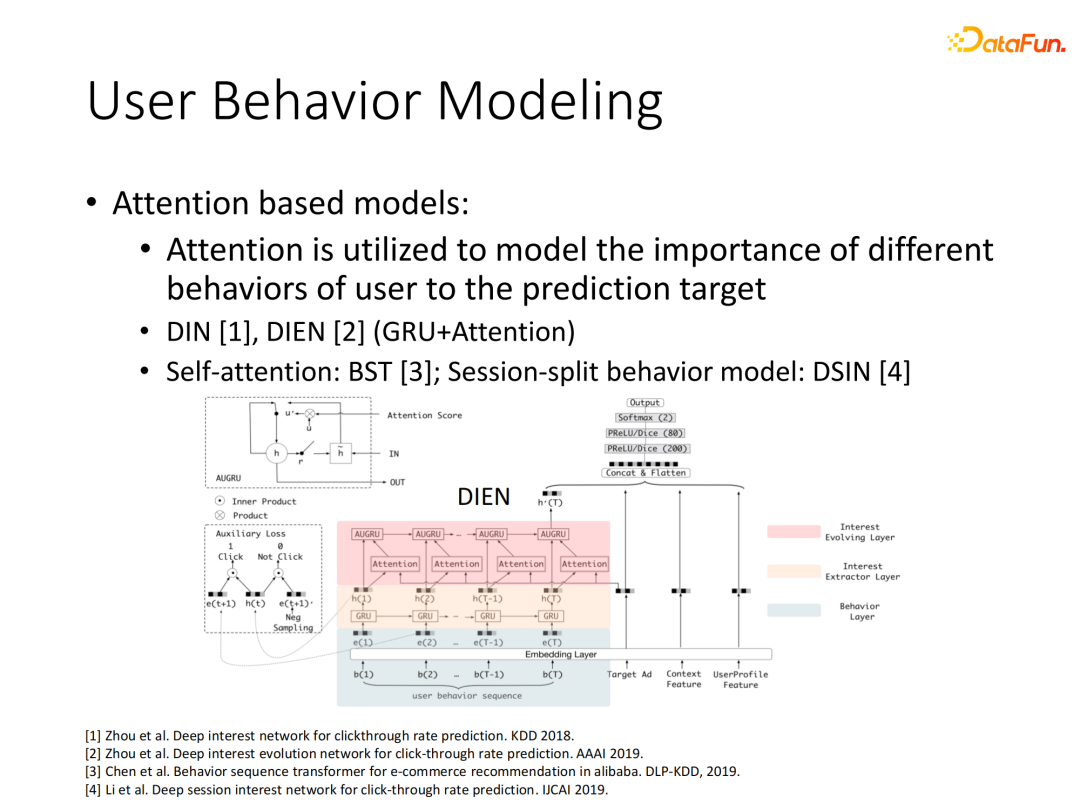
像阿里的一些工作,因为行为数据积累比较丰富,充分挖掘行为的表征能够极大提升推荐的精度,DIN、DIEN就是典型的基于Attention机制的模型。以DIEN为例,使用当前target item作为query,来对历史行为在第一层循环网络的隐向量进行Attention计算,最后将Attention权值加入第二层循环网络的计算中来实现历史行为的整体表征。该处理的好处是能够让模型较好地关注与当前行为相关的历史行为,提高模型效果。
后续我们关注序列建模中超长序列的问题,直接使用传统RNN模型来提取超长序列的有效信息几乎不太可能,我们考虑使用一种类似层次结构的网络。初始每个时刻的行为均输入到第一层循环层,从后面层开始每次跳过一个时刻输入网络,比如:2、4、8间隔时刻,越上层网络的间隔周期越长。最后在每个时刻可以获取多种周期的循环层信息表征进行拼接,来提高建模效果。
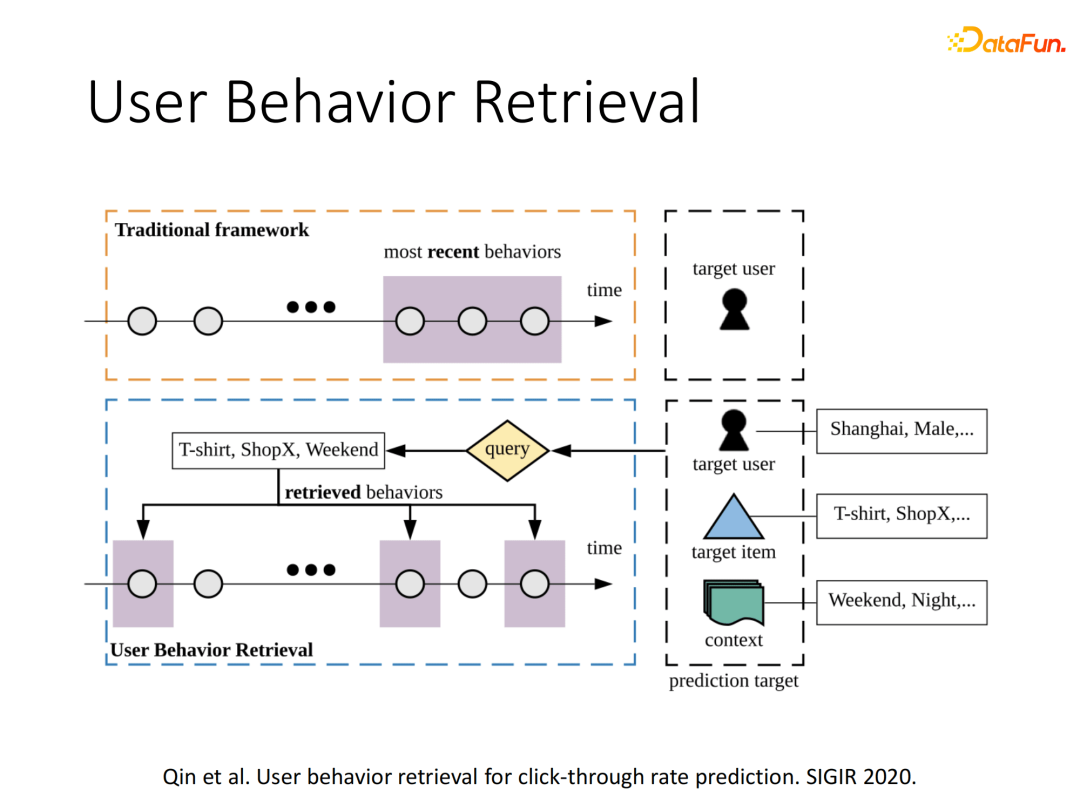
以上方式能够解决千级别的序列建模,但是我们在实际应用中发现,单纯的千级别的序列信息利用也是不够的。于是我们考虑去用户行为中进行有效行为搜索,同时针对单一用户序列过长的情况,我们思考是否可以使用其他用户的历史行为作参考,由此在SIGIR2020提出了UBR (User Behavior Retrieval)模型。传统方式是直接使用该用户最近N个行为来进行序列建模,而我们使用目标用户的信息、目标Item的信息和上下文信息作为query,去搜索用户全历史中的有效行为。
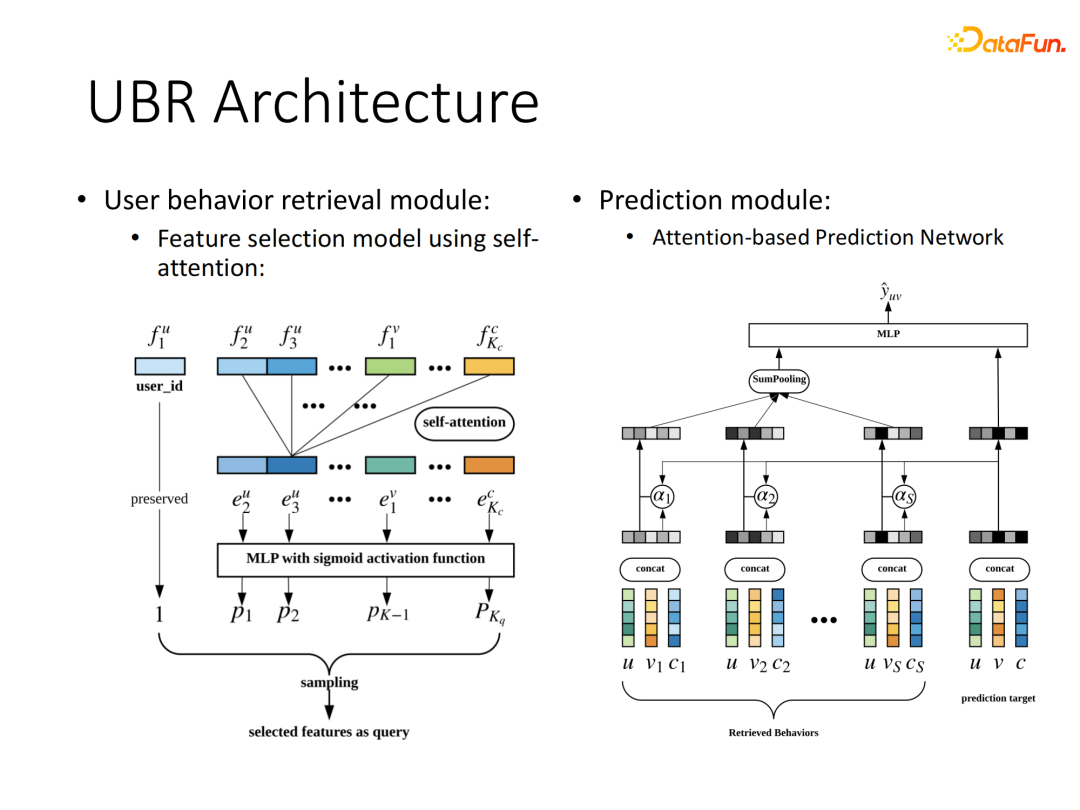
整个UBR架构包括核心的两部分模块:搜索模块和预测模块。
搜索模块重点在于query的设计处理,将query的多域信息通过self-attention方式处理后进行特征筛选,依据用户ID和每个筛选的重要特征去进行相似行为的倒排索引。
预测模块结构与DIN类似,利用检索得到的相关行为与目标item进行attention计算,最后对行为embedding进行加权聚合接入下游任务。搜索得到的相关行为可以远小于原序列长度,只要搜索的有效性得到保证,就能实现简单的序列建模网络达到较好的效果。
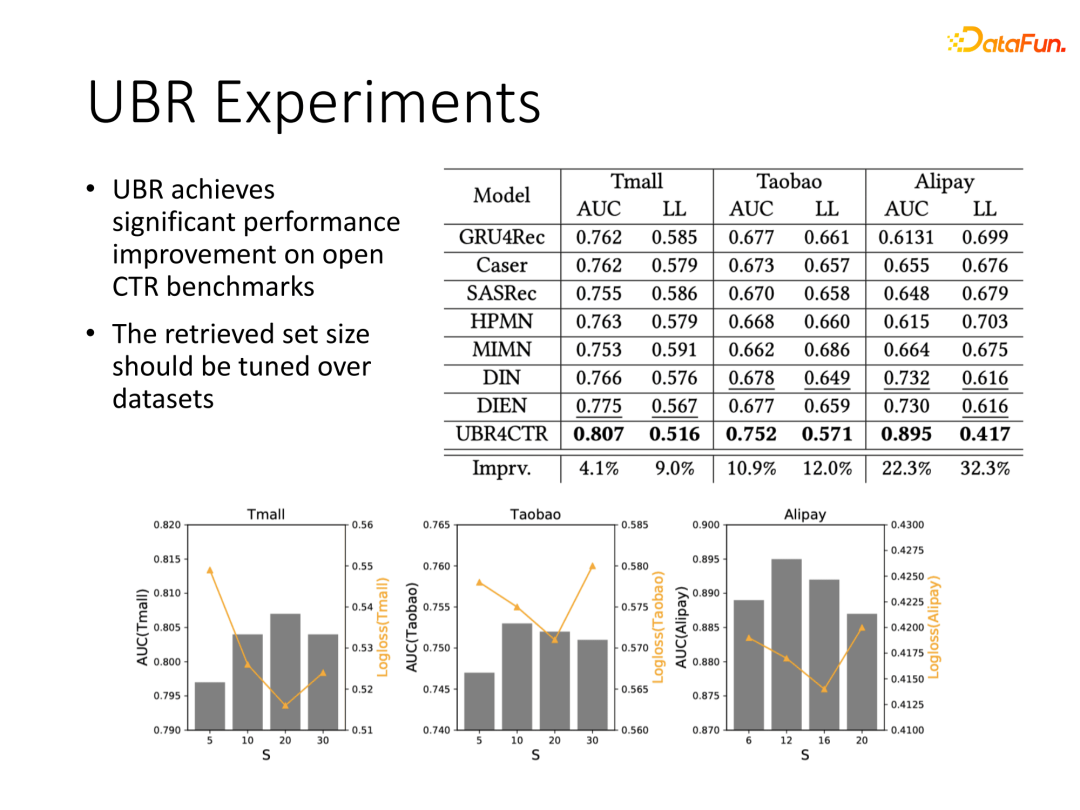
我们在阿里的公开数据集上对比了UBR与现有一些序列建模网络的效果,能够看到UBR是具有显著性能提升的,基本AUC都有百分位的提升。我们也对比了不同搜索长度的差异,这个依赖于数据本身的特性,结果上基本长度在20能得到不错的效果。同时期阿里的团队也发表了在DIEN架构上基于行为检索的工作SIM模型,并将这部分工作进行了上线,也得到了较好的线上效果提升。
02
基于数据交互的点击率模型RIM
1. 数据交互概念提出
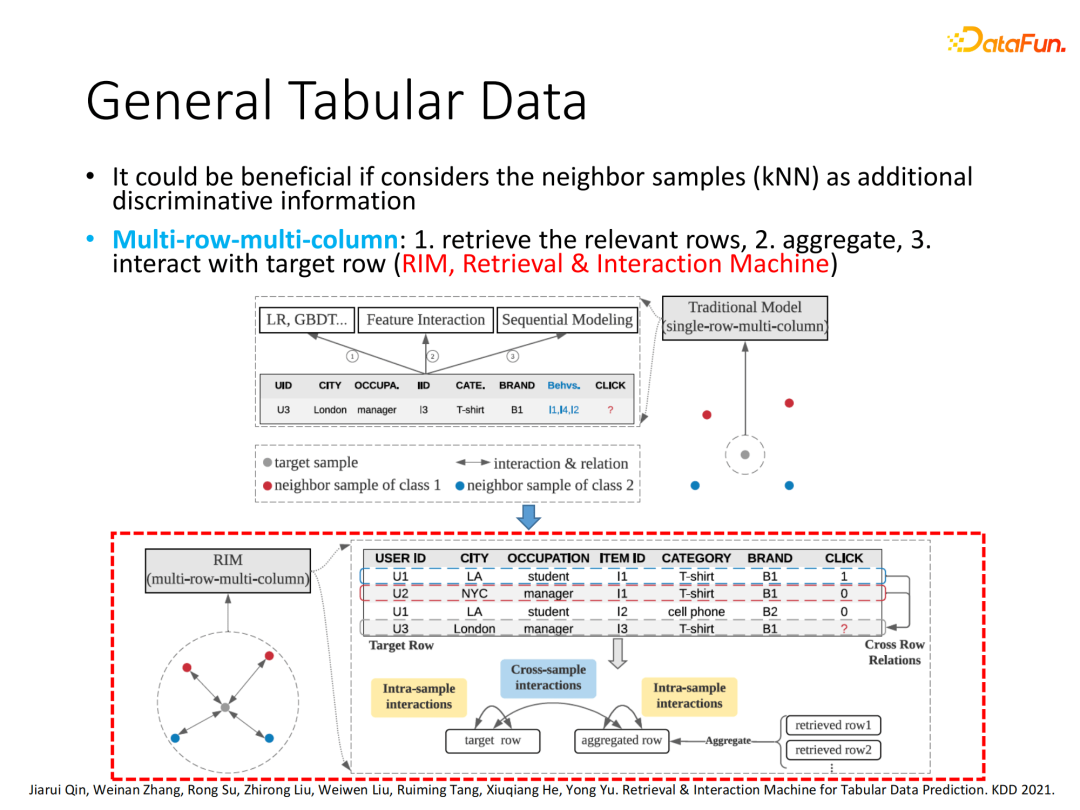
基于特征交互的模型基本只关注当前样本本身的处理,比如FM、DeepFM等只会在一行数据上多域信息跨列间进行交叉,我们定义为single-row-multi-column的方式。基于行为序列的模型虽然会关注多行样本,但是只局限于同一用户,将同一用户的历史行为压缩为一个向量表征。而使用整个数据库中其他样本,且不局限于同一用户范围,甚至包含其他数据的label信息,我们定义为multi-row-multi-column的方式。该方式通过全体数据范围的相关样本搜索,实现跨样本间的交互,而不局限在一行数据里面进行交互,即本次分享的主题基于数据交互的建模。
2. RIM整体结构
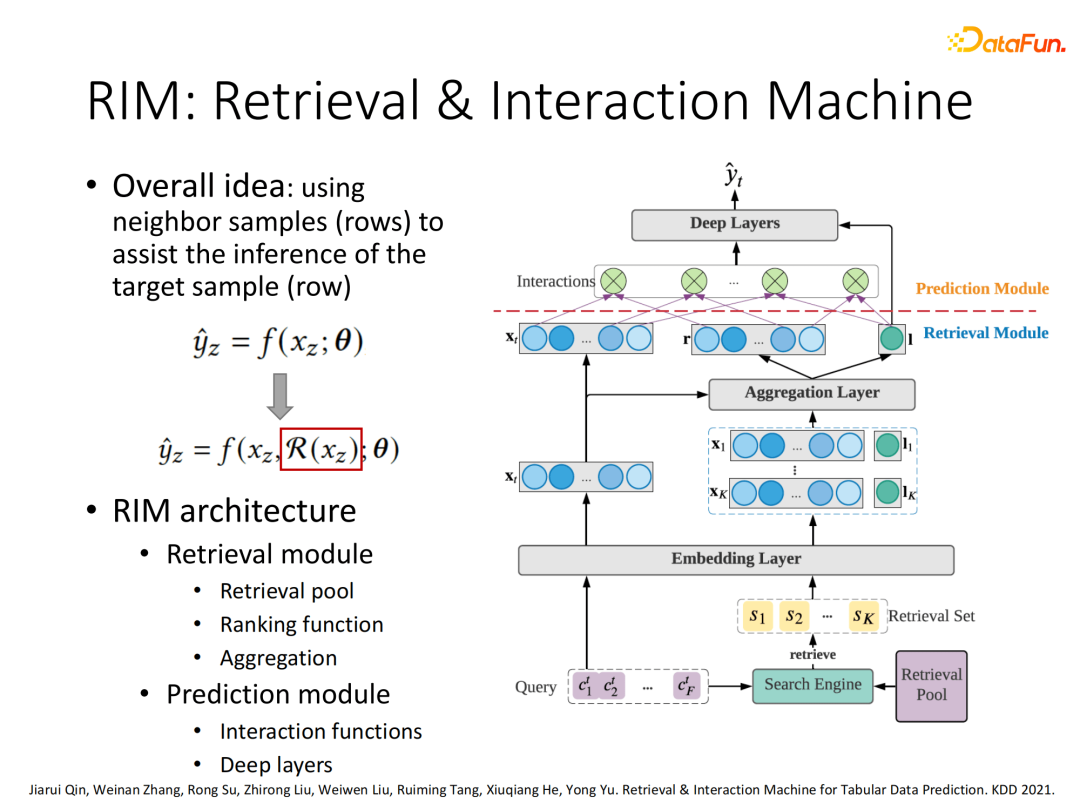
以我们在KDD2021发表的RIM (Retrieval & Interaction Machine)模型进行数据交互介绍。整个RIM的架构,将当前样本作为query,会先在全样本范围搜索当前样本相关的样本集合,然后针对相关样本集合进行信息聚合表征,最后将聚合信息与当前样本信息拼接进行多域交叉建模,输入下游任务。
3. RIM搜索模块
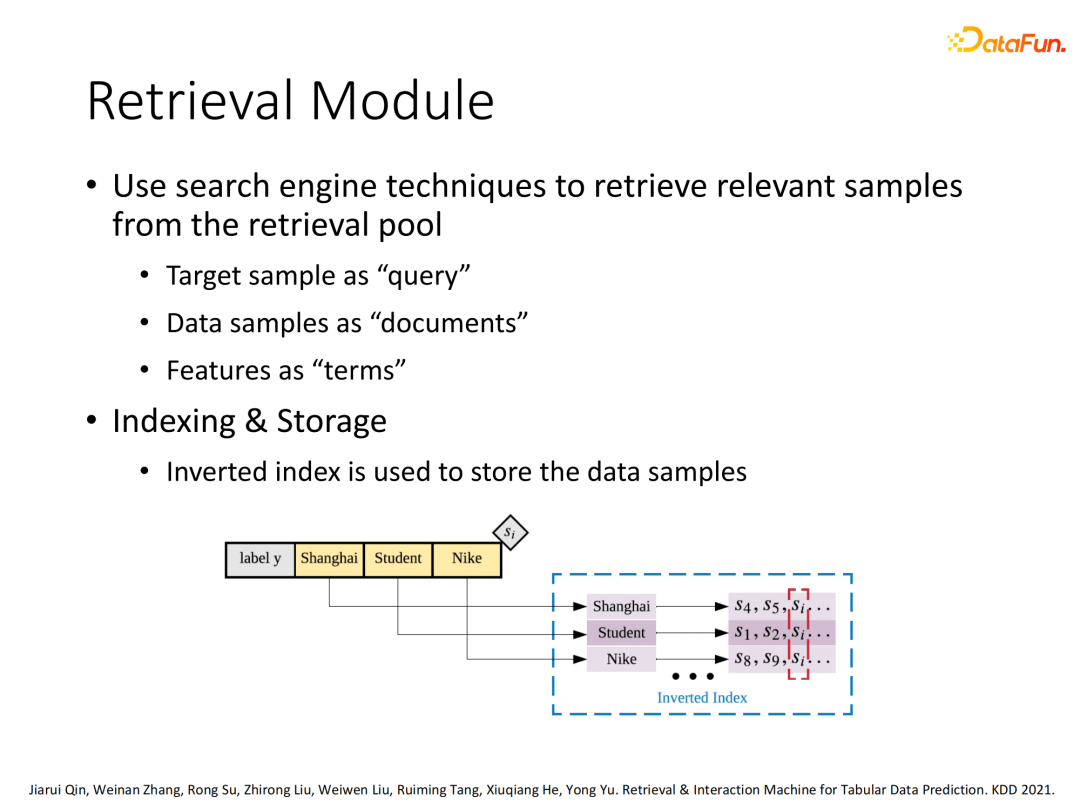
整个RIM架构是一个通用的框架,其中的每个模块都可以因人而异进行不同的设计。这里介绍我们搜索结构的设计,采用倒排索引去构建query中每个域的每个特征各自的相关搜索集合,出现在多个集合的元素就容易作为最终相关样本。
针对得到的多个搜索集合采用“或”的方式处理然后进行元素排序,其中排序策略采用BM25或其他排序算法,最后选择Top K个最相关样本。
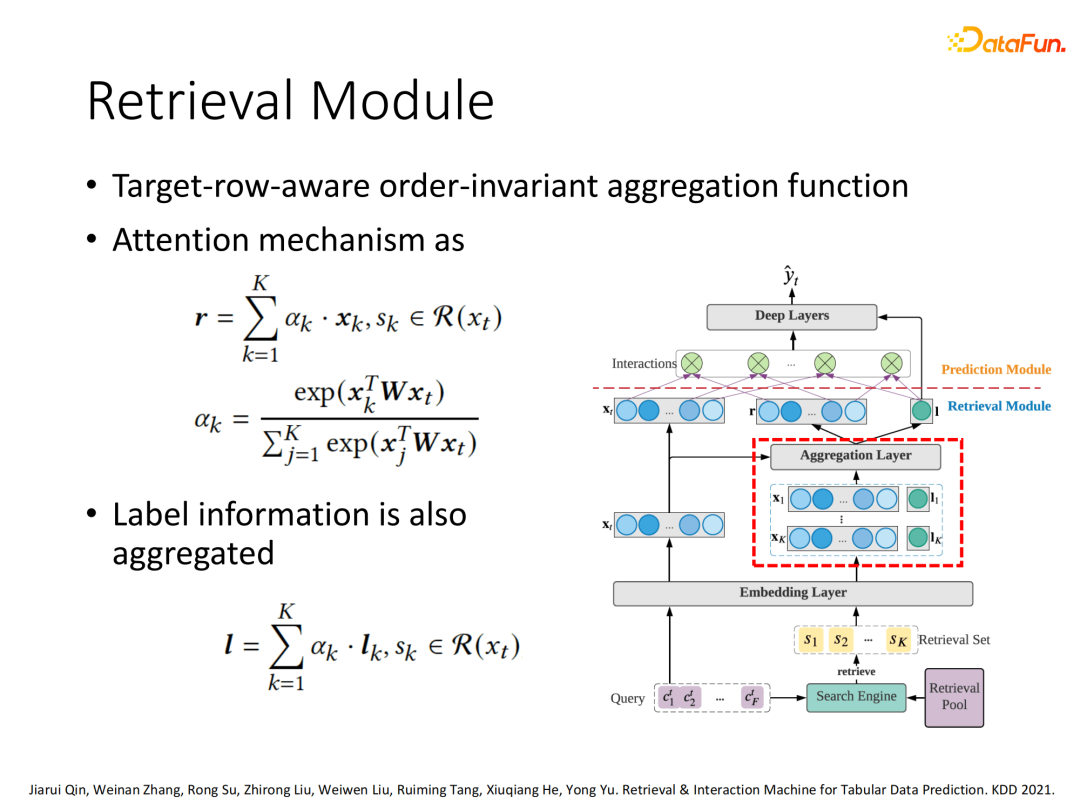
将搜索得到的K个相关样本采用Attention机制,通过目标样本和候选样本计算attention权值,进行加权聚合得到搜索向量汇聚表示。除了特征信息的聚合还会包含相关样本的label信息也会被聚合进来。
4. RIM预测模块
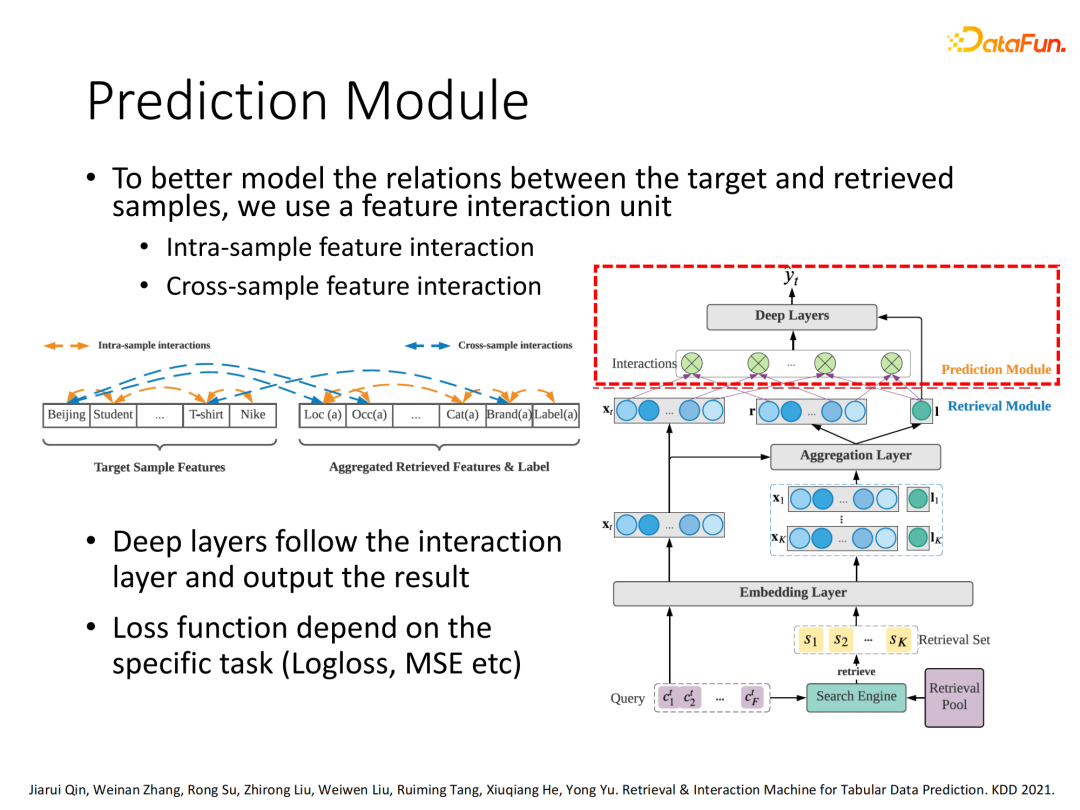
预测模块:使用目标样本向量和搜索样本聚合向量进行标准多域特征交互处理,最后输入下游任务实现预测。
5. RIM实操说明

因为每次要进行样本搜索,所以性能的瓶颈在于搜索的过程,可能需要使用硬盘的操作,相比直接在内存或显存计算会慢一些。但是这里的计算加速效果是能看得见的,比如我们将UBR上线时搜索的耗时已经非常可控了,时间基本不会超过整个CTR任务耗时的50%,我们相信在未来的加速过程中实用性会越来越好。
03
实验小结
1. 多数据集多任务效果对比
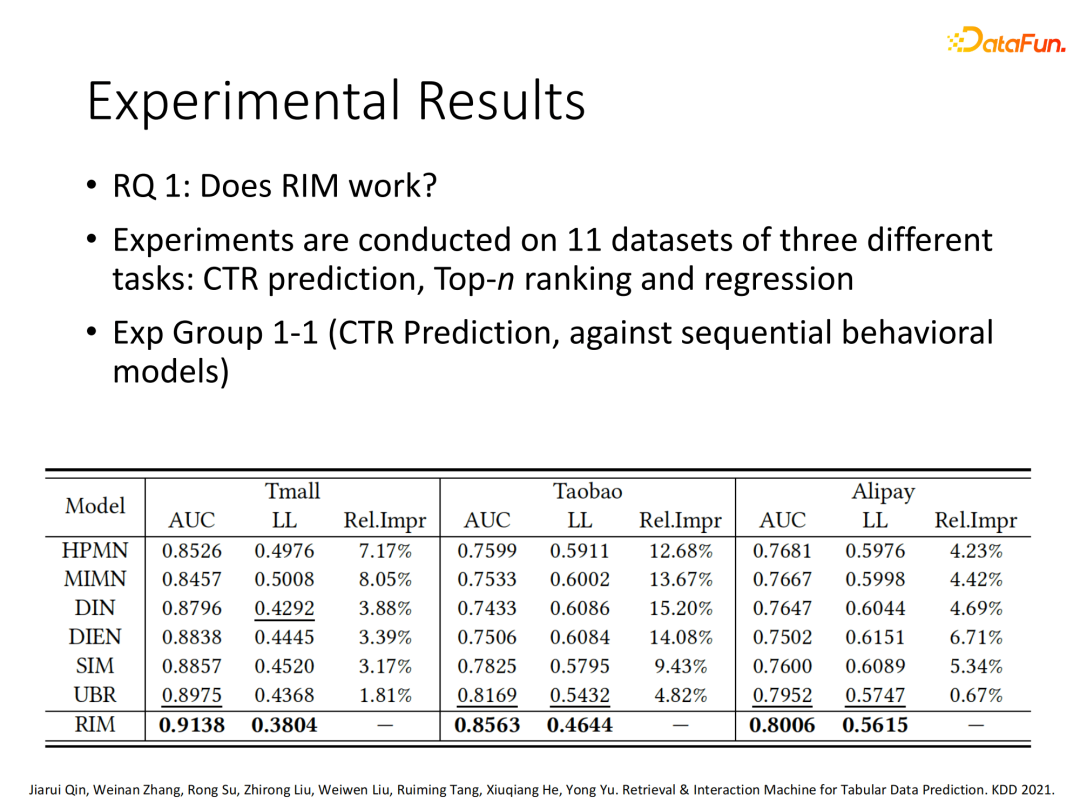
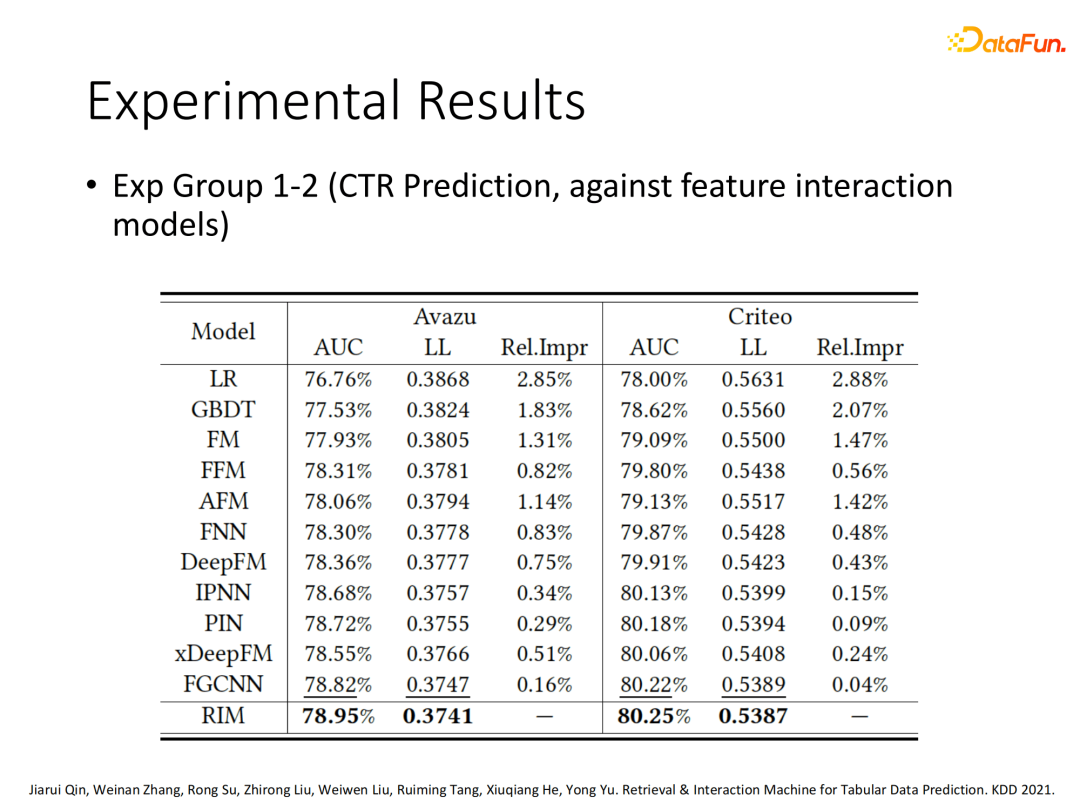
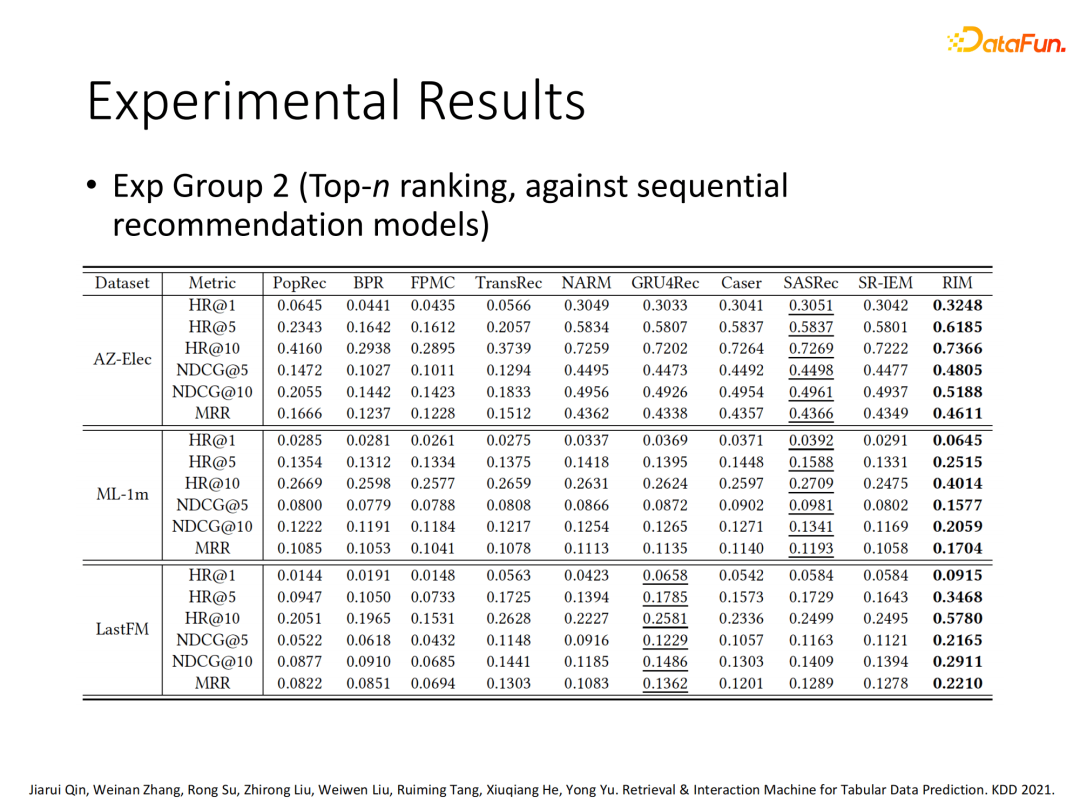
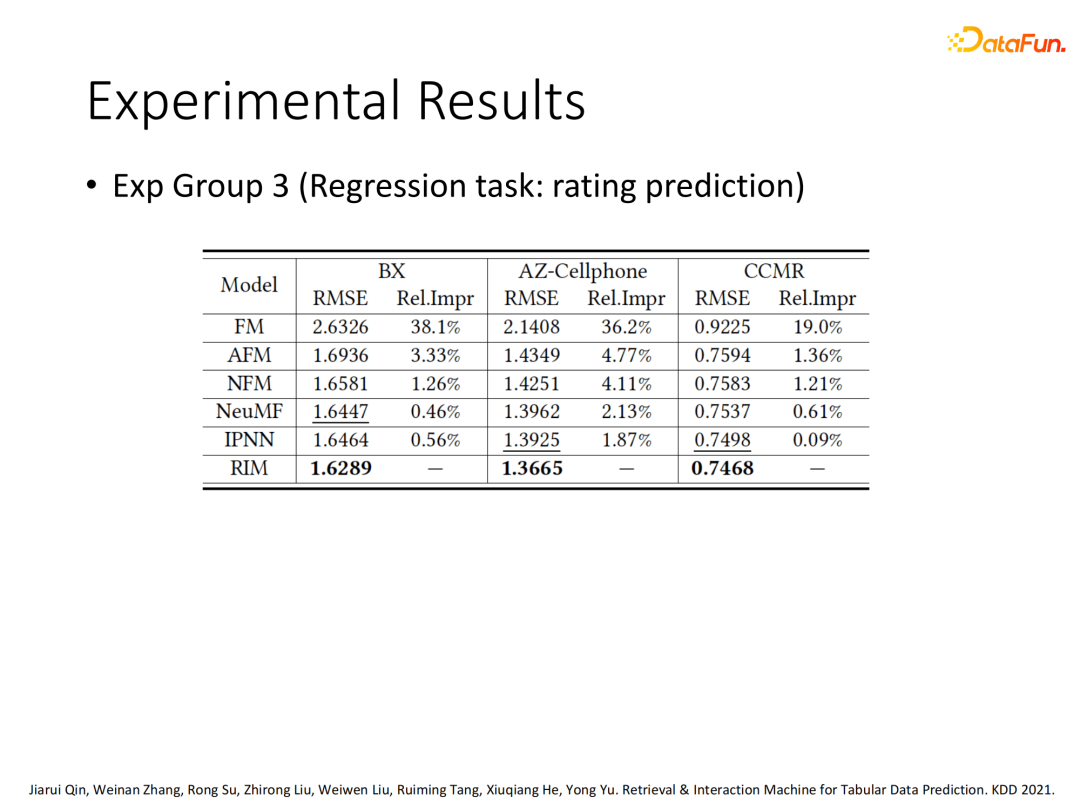
我们在多个数据集和多种任务类型(CTR、Top n ranking、rate prediction regression)上对RIM的效果进行了评估,可以看出对比现有模型,RIM在多种任务类型上基本能稳定在百分位有性能提升。
2. 搜索策略影响对比

另一方面,我们测试了采用不同搜索策略的RIM的效果:直接随机搜索、采用同一用户的样本范围搜索、直接全样本范围搜索(完整版RIM)。可以看出完整版的RIM效果最佳。
3. 其他影响因子对比
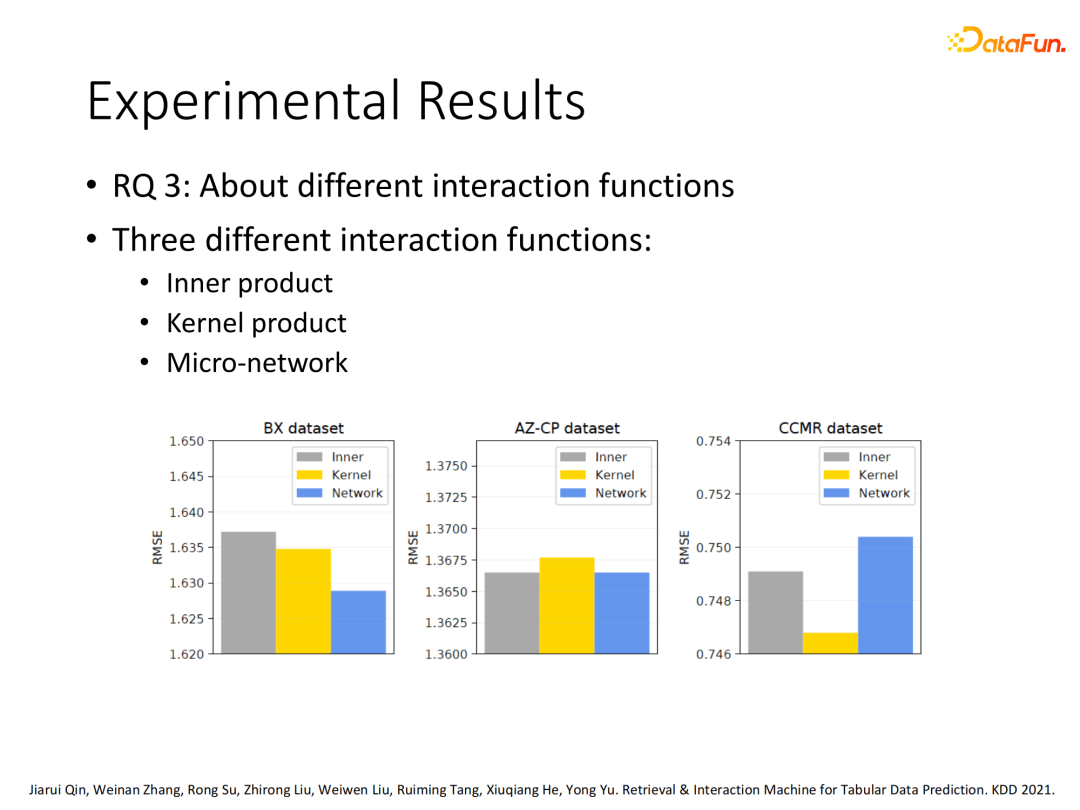
除此以外我们测试了RIM在特征交互层采用不同交互函数(inner product、kernel product、Micro-network)的差异,不同数据集的表现不同,暂无统一结论。
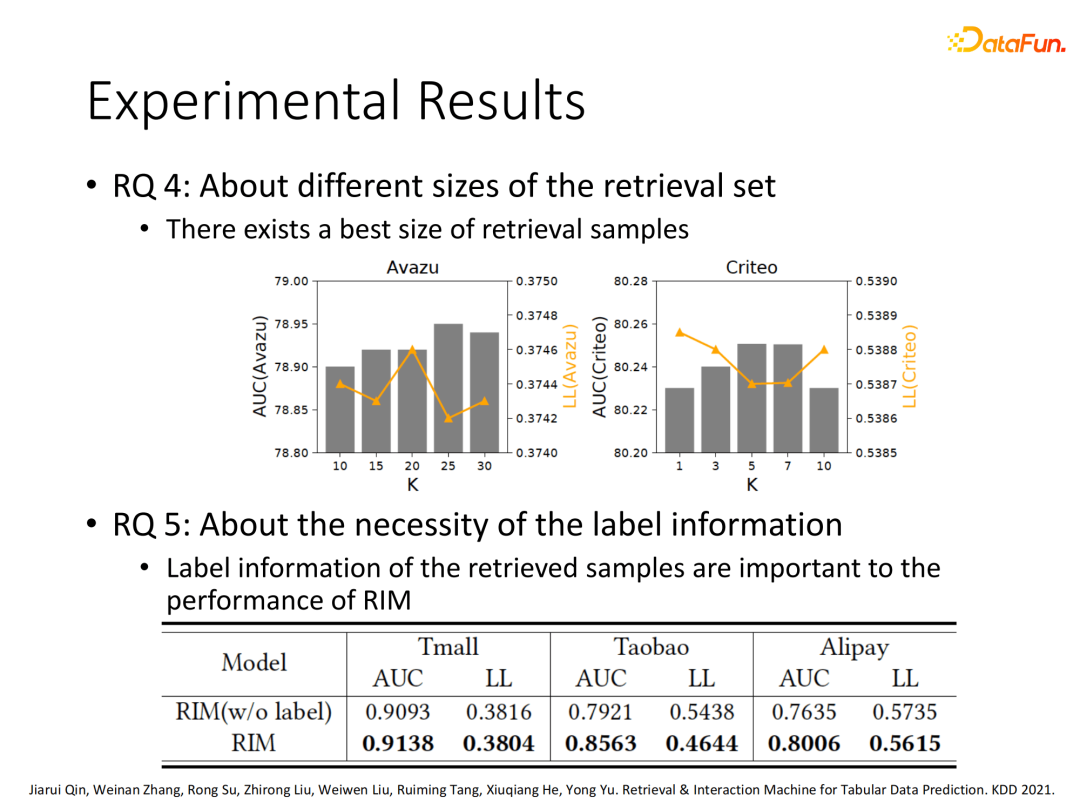
更进一步探索了搜索样本数量对于模型效果的影响,在不同数据集上表现出的最优效果数量也不同。最后我们测试了搜索相关样本是否带上label信息的差异,发现带上label信息的搜索样本建模效果更好。
04
总结展望
关于未来方向的展望,我们关注如下几个方面:
是否能更近一步优化搜索策略,得到更精细化的搜索函数
如何在生产系统数据库上提高搜索效率
探索更复杂有效的样本相关性计算方法
考虑其他数据聚合方式,比如采用GNN策略进行信息聚合
总结下来,过去的二十年是推荐系统模型快速发展的二十年。2000年到2015年经历了逻辑回归到因子分解的发展阶段,2015年-2019年进入深度学习大爆发的时代。最近两年的趋势则是使用AutoML相关技术自动化建模以及特征交互到数据交互的演进阶段,后者也是本次分享的主题,希望能给大家提供新的思路。
Q:RIM对行为序列怎么处理?
A:没有处理,即便用户在数据集中留下一系列历史行为,也只是看作一行行独立数据,直接基于搜索策略进行相关样本搜索,并不会基于是否同一用户进行预判的。此外,RIM是一个面向表格型数据的通用预测模型,并不只针对用户点击率预测任务。
Q:和ranking listwise的对比?
A:本研究并不相关,RIM实际是一个单点预测的问题,所有的loss function 实际是cross-entropy,但是RIM可以通过loss function的设计来适配listwise。
Q:RIM寻找相似样本怎么样保证不会有时间穿越?
A:如果是离线数据集训练,一点要切分检索集和训练集,两者不能共享数据实例。实际处理时保证永远只搜索当前样本时间戳之前的样本,故不会有时间泄露。
Q:模型上线会不会很耗时?
A:目前UBR上线还只是简单的定好的几个域进行搜索,而RIM目前还没上线。提升RIM的在线效率,这也是我们接下来的研究方向。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾:

欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

