深度总结 | 推荐算法中的特征工程
分享嘉宾:杨旭东 阿里巴巴 算法专家
编辑整理:杨佳烨 电子科技大学
出品平台:DataFunTalk
导读:深度学习时代,某些领域,如计算机视觉、自然语言处理等,因为模型具有很强的特征表达能力,特征工程显得不那么重要了。但在搜推广领域,特征工程仍然对业务效果具有很大的影响,并且占据了算法工程师很多精力。数据决定了效果的上限,算法只能决定逼近上限的程度,而特征工程则是数据与算法之间的桥梁。今天将和大家分享推荐场景下的特征工程,主要围绕下面四点展开:
为什么要精做特征工程
何谓好的特征工程
常用的特征变换操作
搜推广场景下的特征工程
01
为什么要精做特征工程

特征工程就是将原始数据通过一系列变换映射到新的向量空间,使算法模型能够在新的向量空间中更好地学习数据中的规律。在完整的机器学习流水线中,特征工程占据了数据科学家很大一部分的精力,主要原因是特征工程能够显著提升模型性能,大大简化模型复杂度,降低模型的维护成本,高质量的特征在简单的线性模型上也能表现出不错的效果。在机器学习领域,“Garbage In, Garbage Out”是业界的共识,特征工程处于机器学习流水线的上游位置,处理结果的好坏关系到后续模型的效果。
关于特征工程的三个误区:
1. 误区一:深度学习时代不需要特征工程
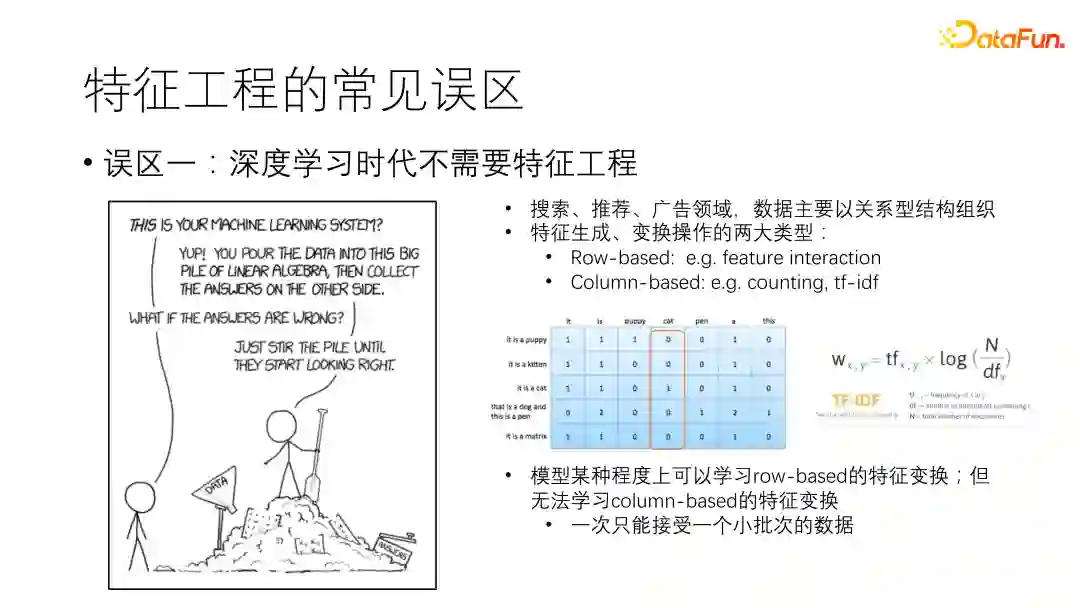
近些年,深度学习在计算机视觉、自然语言处理等领域取得巨大成功。这种end-to-end的学习方式使得在这些领域手工做特征工程的重要性大大降低,因此可能会有人觉得深度学习时代不再需要人工做特征工程。然而,在搜索、广告、推荐等领域,特征工程依然是非常重要的,因为这些领域的特征数据主要以关系型结构组织和存储。数据行记录不同的样本,数据列记录样本的不同特征,以表格形式存储在数据库中。所以在关系型数据上的特征生成和变换操作主要有以下两大类型:
基于行的特征变换(row-based):新的特征是由同一样本的其他特征变换得到的,比如数值型特征的缩放变换。
基于列的特征变换(column-based):对所有样本数据做统计、聚合才能得到,如最大值、最小值、平均值等。
深度学习模型在一定程度上可以学习到row-based的特征变换,比如PNN、DCN、DeepFM等都可以建模特征的交叉组合操作。然而,其很难学习到column-based的特征变换,这是因为深度模型一次只能接受一个小批次的样本,无法建模到全局的统计聚合信息,而这些信息通常是十分重要的。因此即使是深度学习模型也是需要精做特征工程的。
2. 误区二:有了AutoFE工具就不需要手工做特征工程

我认为AutoFE的研究尚处于初级阶段,在使用效率上的问题还没有得到很好的解决。另外,特征工程非常依赖于数据科学家的业务知识、直觉和经验,通常带有一定的创造性和艺术性,因此很难被AutoFE工具取代。
3. 误区三:特征工程没有技术含量

很多初学者都有一种偏见,认为算法模型才是高大上的技术,特征工程是脏活累活,没有技术含量。因此,很多人把大量精力投入到算法模型的学习和积累中,而很少花时间和精力去积累特征工程方面的经验。事实上,算法模型的学习过程就好比是西西弗斯推着石头上山,石头最终还会滚落下来,这是因为算法模型的更新迭代速度太快了,总会有效率更高、效果更好的模型被提出,从而让之前的积累变得无用。而另一方面,特征工程的经验沉淀就好比是一个滚雪球的过程,雪球会越滚越大,最终我们会成为一个业务的领域专家,对业务贡献无可代替的价值。
02
何谓好的特征工程

高质量的特征应具有区分度,相互独立,简单可解释性强等特点,对所有的机器学习任务都适用。
在推荐领域,我们对特征工程有一些其他要求。首先特征工程的伸缩性要强,支持高基数特征,支持大数据场景下的推荐任务;其次特征的设计还要让模型在线预测的时候支持高并发度,预测效率高;并且特征的设计要具有灵活性,一个好的特征工程应该适用于多个模型任务;最后也是最重要的,特征工程要对数据分布变化有一定的鲁棒性,因为在真实的场景中,数据分布变化在某种程度上来说是难以避免的,比如电商场景下经常会有些大促活动,这些活动的举办就会对数据分布产生影响,能够适应这种变化的特征才称之为一个好特征。
03
常用的特征变换操作
1. 数值型特征的常用变换
(1)特征缩放

特征缩放就是把一些取值范围较大的特征缩放到较小的范围内。如果不做特征缩放,较大值的特征会支配梯度更新的方向,导致梯度更新在误差超平面上不断震荡,模型学习效率变低。另外,一些基于距离度量的算法,如KNN,K-means等也很大程度上会受到是否进行特征缩放的影响。不做特征缩放,取值范围较大特征会支配距离函数的计算,导致其他特征失去作用。常用的特征缩放方法包括Min-Max、Z-score、Log-based、L2-normalize、Gauss-Rank等,其原理都比较简单,关键在于如何根据不同场景选择最适合的方法,下面我们通过几个思考题来具体说明一下:
思考题1:如何量化短视频的流行度(假设以播放次数来衡量)?
参考答案:短视频的播放次数在整个样本空间中服从幂律分布,即长尾分布,少量的热门视频播放次数会很高,大量的长尾视频播放次数都相对较少。这个时候最好采用Log-based变换,即先对播放次数取log,取完log之后的值做Z-score标准化处理,最终得到的值分布比较均匀。如果不做log变换直接用Z-score处理,会导致大部分特征值被压缩到一个非常窄的区域。
思考题2:如何量化商品“贵”或“便宜”的程度?
参考答案:首先商品的价格不能量化商品“贵”或“便宜”的程度,因为不同品类的商品价格区间本来差异就很大。比如,1000块钱买到一部手机,顾客感觉很便宜;但同样1000块钱买一只鼠标,顾客就会觉得这个商品的定价很贵。因此,量化商品“贵”或者“便宜”的程度时就必须要考虑商品的类目,这里推荐的做法是做Z-score标准化。要注意的是Z-score的均值和标准差的计算都要限制在同类商品集合内,而不是对整个数据集,并且最好采用叶子类目,即最细一层的类目,但如果叶子类目的商品种类太少,回溯一层也是可以的。
思考题3:如何量化用户对新闻题材的偏好度(假设以阅读次数来衡量)?
参考答案:不同用户的活跃度是不同的,有些高活跃用户可能对多个题材的阅读量都比较大,而一些低活跃用户对可能只对某几个题材有中等的阅读量。我们不能因为高活跃度的用户对某题材的阅读量大于低活跃度用户对相同题材的的阅读量,就得出高活跃度用户对这种类型的偏好度大于低活跃度用户对同类型题材的偏好度,这是因为低活跃度用户的虽然阅读量较少,但却几乎把有限精力全部贡献给了该类型的题材,高活跃度的用户虽然阅读量较大,但却对多种题材“雨露均沾”。所以建议对这种问题先按照用户分组,组内再做Min-max归一化。
最后介绍一下Gauss Rank,是推荐系统中效果比较好的一个特征变换操作。首先我们对数据的统计值做一个排序,从小到大或从大到小都可以,得到数据的Rank值,然后将Rank值缩放到(-1,1)区间,最后调用erfinv逆误差函数,就可以将变换后的Rank值分布调整为高斯分布。深度学习模型偏好高斯分布的数据输入,这也是为什么深度学习中经常使用的一个操作是Batch Normalization。
(2)对异常值的处理
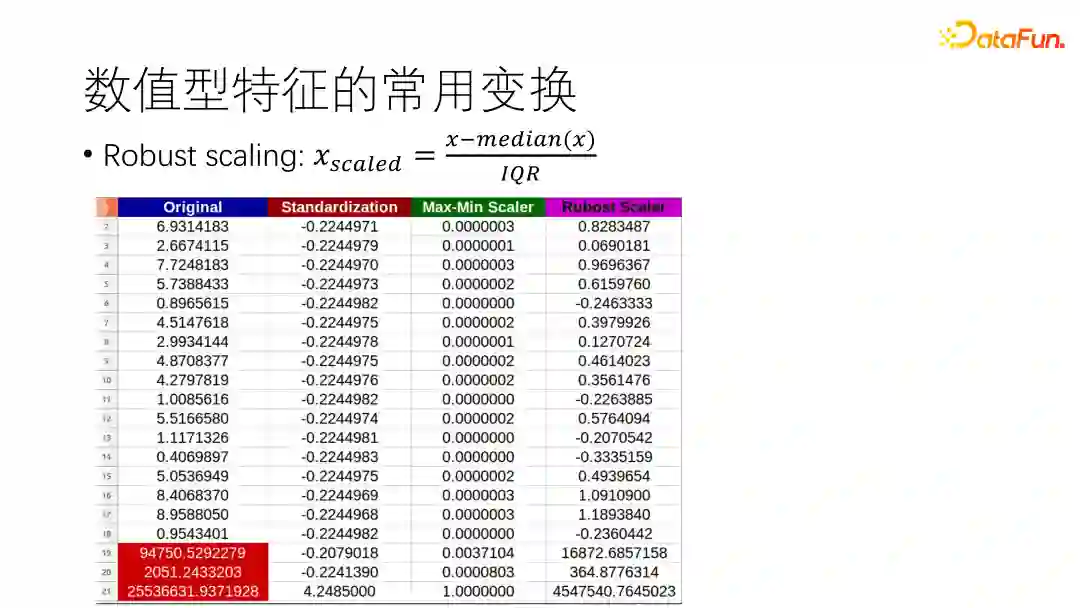
数据中存在异常值(上图中红色区域)时,用Z-score、Min-max这类特征缩放算法都可能会把转化后的特征值压缩到一个非常窄的区间内,从而使这些特征失去区分度。这里介绍一种新的特征变化方法:Robust scaling,其中median(x)是x的中位数;IQR为四分差,等于样本中75%分位点的值减去25%分位点的值。经过Robust scaling变换,如上图最后一列数据所示,数据中较小的值依然有一定的区分性。然而,对于这种存在异常值的数据,最好的处理方法还是提前将异常值识别出来,然后对其做删除或替换操作。
(3)分箱处理(Binning)

分箱就是将连续的特征离散化,以某种方式将特征值映射到几个箱(bin)中。比如预测电商场景下用户的点击率,其中有一个特征是时间特征,即一天24小时,但并不是说时间值越大点击率就会越高。通过历史数据显示,深夜事件段用户点击率都比较低,午饭和晚饭后用户比较活跃,点击率较高,依靠这些经验将一天划分为不同时间段再输入给模型可以增加模型的表达能力。
为什么要做特征分箱?
引入非线性变换,增强模型性能。因为原始值和目标值之间可能并不存在线性关系,所以直接使用模型预测起不到很好的效果。
增强模型可解释性。通过分箱可以得到一个分段函数,模型可解释性更强。
对异常值不敏感,防止过拟合。异常值最终也会被分到一个箱里面,不会影响其他箱内正常特征值,分箱的在一定程度上也可以防止过拟合。
最重要的是分箱之后我们还可以对不同的箱做进一步的统计和特征组合。比如按年龄段分箱后对不同年龄段的人群做一个CTR统计。
分箱有无监督和有监督两种方法。无监督方法包括固定宽度分箱、分位数分箱、对数转换并取整等,实际中应用较多,有监督的方法应用较少。下面再做两个思考题来说明一下分箱的具体应用:
思考题1:如何衡量用户的购买力?如何给用户的购买力划分档位?
背景:电商场景下用户的购买力是一种很好的属性,可以反映用户的消费倾向,用户是倾向于高质量消费还是高性价比消费。购买力是长期的稳定的用户画像,与用户近期的消费金额无关。
参考答案: 首先要划分商品的价格档位,根据商品类目分组,组内按价格升降排序,利用等宽分箱方法得到价格档位。然后根据用户的历史消费行为把其购买过的商品的价格档位聚合到用户身上,注意同一个用户对不同类商品的购买力也是不同的,比如有的用户愿意花高价购买电子产品,对其他种类的商品的购买力一般,因此可以针对每个类目计算购买力。
思考题2:经纬度如何分箱?
参考答案:经纬度是一个整体,不能把其拆开成多个独立变量来单独做分箱,而是要把这些变量当做一个整体来考虑。经常用到的一个方法是GeoHash,简单来说就是把地图划分成一个二维网格,不同的网格有唯一的hash编码,代表不同的区域。
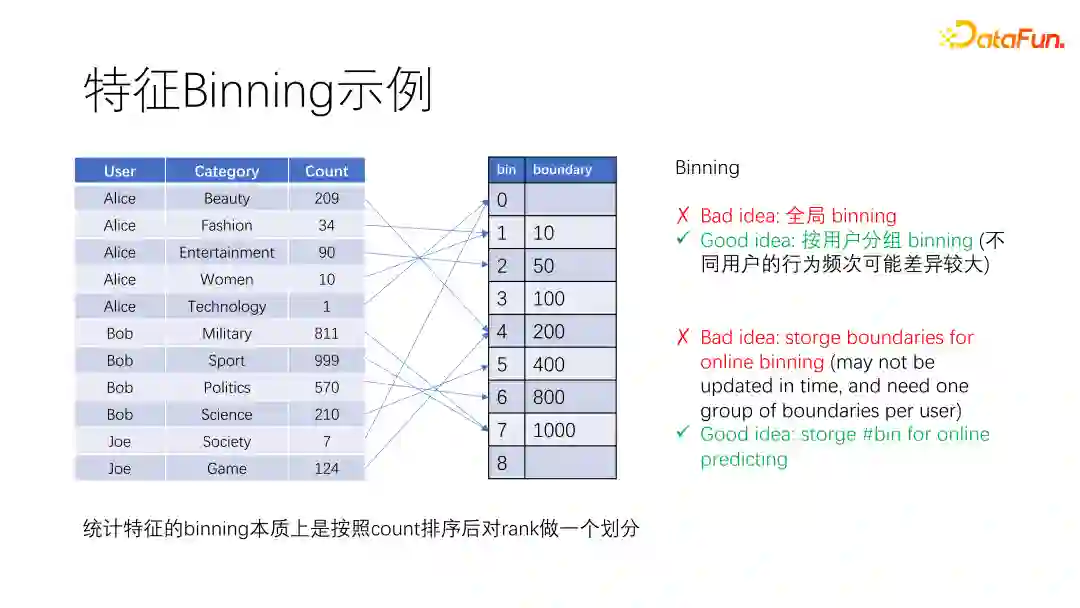
上图是用户在不同类目下行为的统计值,如果做全局分箱会导致活跃度高的用户浏览过的类目都被分到高桶号中,活跃度低的用户都被分到低桶号,这并不能很好地区分用户的偏好程度。比如Alice对Beauty类目的偏好程度与Bob对Sport类目的偏好程度是差不多的,这两个类目都是彼此的首选,采用全局分箱无法反映出这种相似性。因此推荐场景下,用户的统计特征需要先按照用户分组后再做分箱,不建议全局做分箱。并且我们分箱后要保存的应该是箱号,而不是具体范围值。
2. 类别型特征的常用变换
(1)交叉组合

如上图,当特征f1和f2单独存在时都不具备很好的区分性,组合为一个整体就能够做出很好的预测。如上图右边的散点图,蓝色和黄色分别代表正负样本x1和x2,本身是线性不可分的,但我们引入一个特征组合x3=x1x2后就可以用sign(x3)来做预测。
(2)分箱处理
类别型的特征有时候也是需要做分箱的,尤其是存在高基数特征时,不做分箱处理会导致高基数特征相对于低基数特征处于支配地位,并且容易引入噪音,导致模型过拟合。类别型特征的分箱方法通常有以下3种:
基于业务理解。例如对userID分箱时可以根据职业划分,也可以根据年龄段来划分。
基于特征的频次合并低频长尾部分(Back off)。
基于决策树模型。
(3)统计编码

统计编码就是找到一个与类别本身以及目标变量相关的统计量来代替该类别特征,把类别特征转化为一个小巧、密集的实数型特征向量。
Count Encoding,统计某类别型特征发生的频次。一般需要做特征变换后才能输入给模型,建议的特征变换操作包括Gauss Rank、Binning。
Target Encoding,统计某类别特征的目标转化率。如目标是点击就统计点击率,目标是成交就统计购买率。同时目标转化率需要考虑置信度问题,比如10次浏览有5次点击和1000次浏览500次点击置信度是不一样的,所以对于小的点击次数我们需要用全局的点击率做一个平滑处理。
Odds Ratio,可以用来度量用户对某一类目商品的偏好程度相对于其他类目是什么样的水平。如上图所示,Alice对Bag类别的偏好程度相当于对其他类别偏好程度的0.7906。
Weight of Evidence,度量某类别特征不同分箱下取值与目标的相关程度。值为正表示正相关,值为负表示负相关。
3. 时序特征
时序特征包括统计过去1天、3天、7天、30天的总行为数或行为转化率,还可以对当前值和历史值做差异比较。比如在电商场景下,商品的价格相较于之前是升高了还是降低了可作为用户购买意愿的重要特征。另外还有行为序列特征,这是需要模型来配合的。
04
搜推广场景下的特征工程
推荐系统是关系型数据下的数据挖掘问题,面临的挑战主要有高基数特征、大数据样本、在线推理的实时性要求等。为了应对这些挑战,业界最常用的做法是大量使用统计特征。
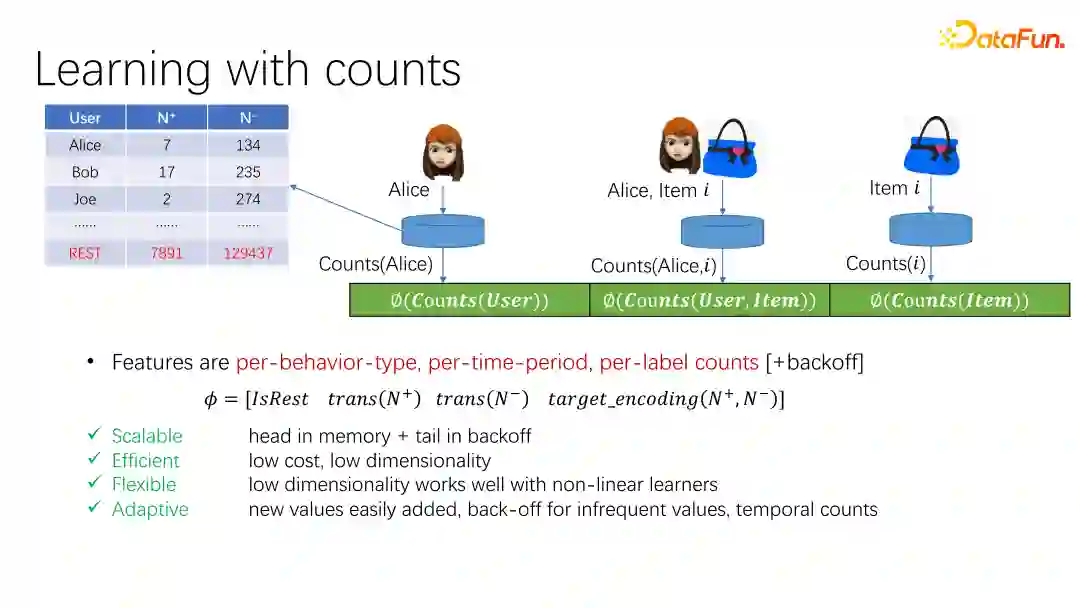
通过对用户或商品某些特征在不同的行为类型、不同时间周期、不同的标签上分别统计正负样本数量得到统计特征。其中不同的标签对应多目标推荐场景,例如既要做CTR预估又要做CVR预估,点击和转化是不同的目标,所以我们要分别统计正负样本。这些统计量经过特征变换,包括特征缩放、分箱和统计编码后作为最终特征向量的一部分。这里推荐使用Gauss Rank来做特征缩放,因为Gauss Rank对特征的分布变化具有一定的鲁棒性,不易收到流量波动的影响。

在统计正负样本数量之前,要先对推荐的实体(如用户、物品、上下文)进行分箱,称为bin counting,如上图所示。在得到用户和商品的分箱统计特征后,我们还可以对这些特征进行交叉组合得到新的统计量,称为cross counting,这些统计量最后都会转化为特征。
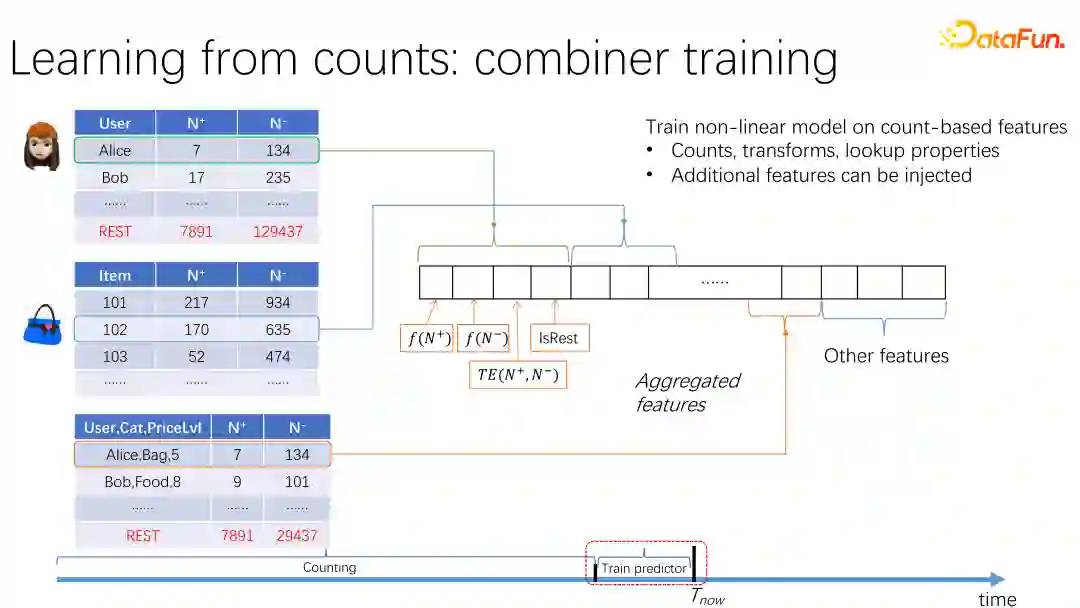
为防止出现特征穿越,各统计量的统计时间都要放在样本事件的业务时间之前,如上图时间轴所示,Train predictor阶段只能在其之前的Counting部分做统计计数。最终把各粒度的统计量特征变换后的值拼接为一整个特征向量。
那么如何能把所有的特征都考虑到,做到不重不漏呢?可以按照如下描述的结构化方法来枚举特征:
列存实体。推荐场景的实体主要是用户、商品和上下文;广告场景的实体主要是用户、广告、搜索词和广告平台。
实体分箱。可以针对用户或物品的自然属性来分箱,例如用户可以针对每一个用户画像做分箱,物品可以基于类目、价格等做分箱,得到单维度的特征,利用历史行为信息对单维度特征做统计、编码。
特征交叉。在实体分箱的基础上做特征交叉,得到二阶、三阶或更高阶特征。
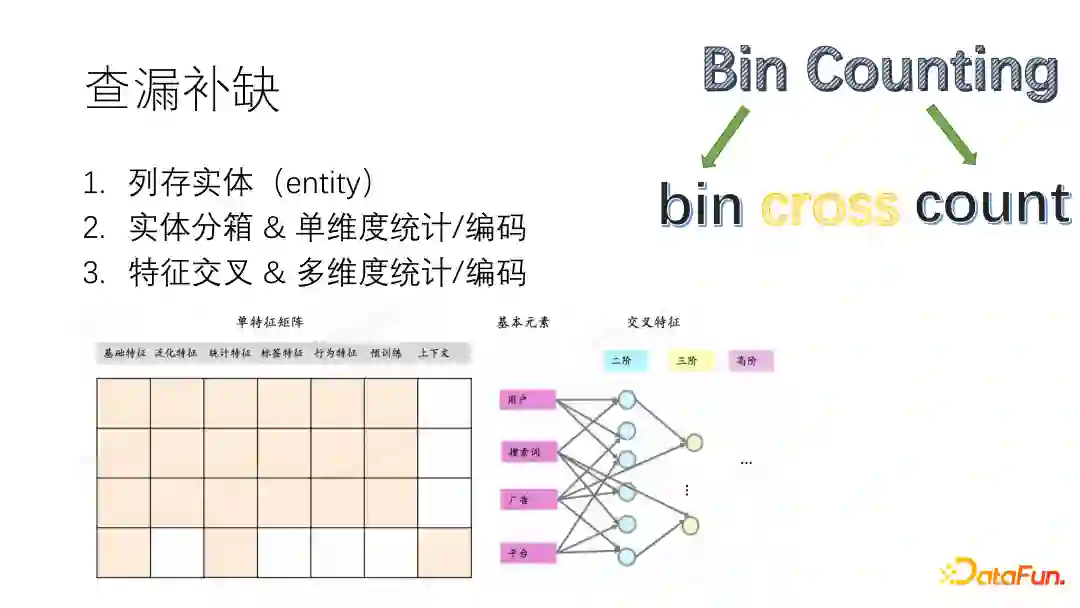
最后总结,搜推广场景下的常用特征工程套路可以总结为一个词“Bin&Counting”,也就是先做bin,再做counting,中间结合cross counting。
05
互动问答
Q1:手动做特征工程相比于XGBoost、LightGBM等可以自动分箱的方法有什么优点和缺点?
A1:XGBoost这类树模型就是我们之前提到的有监督分箱中基于决策树的方法。这类基于GBDT的模型很难处理高维度的特征,当特征维度比较高的时候,它的运行效率是比较低的。我们可以通过这类模型精选一些特征,然后再把这些特征输入给其他模型,如深度神经网络,LR等,相当于利用GBDT作为一个特征工程来初步提取特征。
Q2:特征工程这类经验性知识怎么获取和学习?
A2:学习特征工程的知识还是要深入理解业务。比如在某个场景下,我们认为年龄是一个比较重要的特征,但是现阶段用户画像里没有这个特征,那么我们首先要想办法通过一些现有特征,如用户的购买行为将年龄值预测出来。虽然预测出的年龄值与真实年龄值存在差异,但用户的真实年龄并不重要,重要的是他在平台上购物倾向所体现出的“购物年龄”,我们后续只会针对他的“购物年龄”做一个预测。此外,和有经验的人或团队交流也是可以收获很多特征工程经验的。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
分享嘉宾

杨旭东
阿里巴巴 算法专家
多年推荐算法从业经验,知乎专栏《算法工程师的进阶之路》作者。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。

