我很喜欢科幻小说中常出现的「宇宙是台计算机」这个意象。在以 Disco Diffusion、Stable Diffusion 等为代表的扩散模型大火之后,我常常要面对很多人的疑问——扩散模型的原理是什么?为什么会画出惊人的画面?又为什么很多时候会出现一些不知所云的画面? 我发现,要解释清楚这个问题是一个很难的事情——你不能对着一位艺术家讲马尔科夫过程、采样、参数估计;所以,我想写一篇文章,从「宇宙计算机」的 idea 出发,试图形象地解释扩散模型是什么、发生了什么、如何进行训练的。希望这篇文章能够对大家(直观地)理解扩散模型有所帮助。 相关:文章中的示意图大部分通过站酷 AI 实验室 [1] 生成。少部分来自 Illustrated Stable Diffusion [2]。
A Big Bang——从无到有
根据宇宙学的理论,均匀各向同性的宇宙从一个「奇点」膨胀出来,这个膨胀的过程被称为 The Big Bang —— 宇宙大爆炸 [3]。在大爆炸之后很短的时间内,由于具备随机性的量子涨落 [4] 的影响,构成物质的各种基本粒子逐渐从各向同性的能量中沉淀出来;接下来,在四种基本力:强力、弱力、电磁力、引力的作用下,弥散在空间中的基本粒子逐步汇聚形成原子、分子、分子团,继而构成了星云、恒星、行星。 而当物质出现之后,稳定的物质结构和物理定律开始主导宇宙,量子涨落的随机性效应逐步退场,这意味着,你将不会走在街上胸口突然出现一个大洞,或者被凭空出现的一块大石头砸成肉泥。
▲ 图1:宇宙的演化过程 如果大家对 Diffusion Model 有一定的理解,那么我们可以发现,上面的图和 Diffision Model 中的去噪过程惊人地相似:
▲ 图2:扩散模型生成图片的过程 所以,我们也可以将 Diffusion Model 生成图的过程同样视为一种「创世演化」模型:从一张空白的图片,通过随机的采样(量子涨落)生成无意义的噪点(基本粒子);由模型提供「物理定律」的引导,从噪点逐步演化出颜色、线条、纹理,进而构成物体、人脸、意象、场景、画面。从这个层面来说,Diffusion Model 的运行原理和人类的思维是完全不同的,Diffusion Model 作画是一个 down-top 的过程。 人类作画则是 top-down 的:先有场景——如「一个美丽的少女走在森林中」,有经验的画师会勾勒出只有几条线的再逐步细化画面中的每一个元素:少女在哪里,森林里有几棵树,然后少女是什么面容、穿什么衣服,森林里的树是哪些种类;而 Diffusion Model 则是:先随机地生成像素,然后从这些像素中慢慢浮现出人物、场景等。 下图是经过 50 步迭代生成「少女在森林中」的一个过程,右下角是最原始的噪声图像,从右到左、从下到上依次迭代;每一步的生成都和上一步的结果相关(一阶马尔科夫链)。 可以看到,一开始,图像是完全的噪声,什么都看不出来;经过十几步的迭代后,如果有足够的想象力,应该可以联想到,中间浮现出的一片白色似乎可以绘制成一个人影,后面杂乱无章的大片绿色纹理经过细化应该可以画成森林背景;再经过十几步的迭代,图像已经基本定型,人和森林的轮廓都出现了;经过多次迭代,最终生成了一张合乎逻辑和语义的图片。
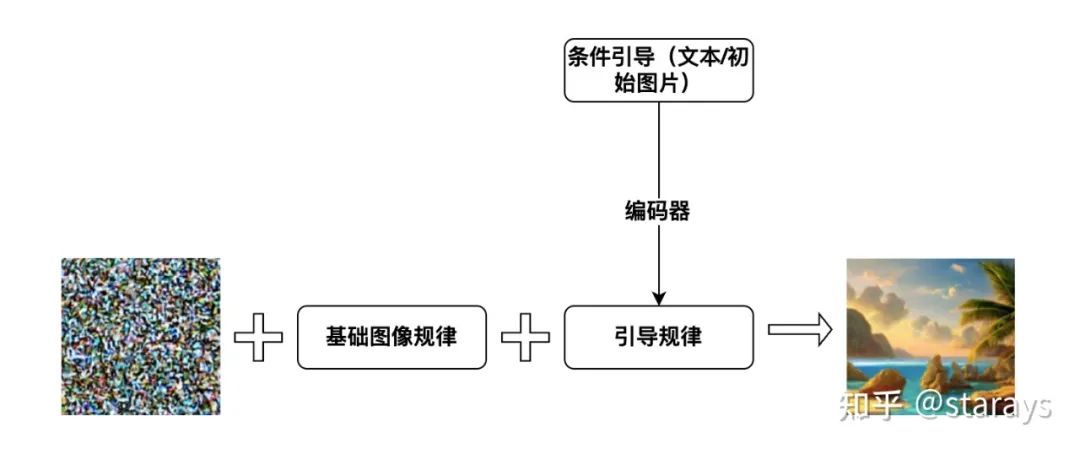
在类比创世游戏的图像生成过程中,我们知道,「物理定律」是「宇宙生成游戏」中的一个重要组成部分。缺乏物理定律的约束,完全随机的量子涨落会产生一个即使是在微观尺度上也是各向同性的、充满了躁动的虚粒子的宇宙;类似地,如果在图像生成过程中缺少规则的约束,那么,图像将永远是一堆噪点。 在 Diffusion Model 中的「物理定律」包括两个部分,分别对应生成的两种模式:无引导的生成和条件引导的生成。 我们先看无引导的生成。无引导的生成以创世游戏来类比,对应的是「基本物理规则」:假如我们在 Big Bang 之后产生的空间中划定一块,只规定基本的物理法则,那么这块空间中,通过随机量子涨落和物理法则的共同作用,可能产生星云,也可能产生恒星、黑洞,甚至是一个生命聚集的群落。 而在图像生成过程中,生成的结果如何,则决定于初始的规则和模型从「样本构成的数据宇宙」中学习到的知识:如果数据集中只有人脸的图片,那么通过无引导的生成过程,绝不会产生一只狗的照片,而是会生成一张人脸,因为模型只能从这些数据中学习到「如何生成人脸」的「物理定律」。而对于一个包罗万象的数据集训练出来的模型,做这个实验则有意思的多:
在一般的神经网络模型中,「预测」或者「推理」的部分通常是端到端的——输入被送入模型,经过模型的一次运行和处理,能够直接生成结果。而在 Diffusion Model 中,这个过程则通过几十到几百个时间步来完成。这是为什么呢? 如同我们在创世游戏中要生成一个岩石行星一样,从 Big Bang 的开始,到行星的生成,经过了数十亿年的演化。我们如果将这数十亿年的演化历程按照「年」拆成无数的时间片,那么物理规则的归纳将比较简单——比如造物主告诉一位神明,给你一堆样本,每个样本中包含数亿个粒子构成的粒子动力系统及该系统在一秒钟前和一秒钟后的状态,你去总结粒子的动力学法则,这是相对比较简单的。 而如果想要直接从 0 时间点直达最终当前的时间点,那么「物理规则」的总结将变得极其复杂:
岩石行星的地壳、地幔和地核都是由什么元素构成?遵循什么样的规律?
大气由什么元素构成?是否会散逸?
有没有生物圈?生物圈的构成是什么?
等等等等。 虽然神明没有学过地质学和生物学,但凭借总结出来的粒子动力学法则,及近乎无限的计算能力和漫长的时间,这位神明仍然能够从一堆星际粒子中演化出一颗岩石行星。 对于神经网络模型也是如此。神经网络模型本质上是对「规则」的编码,需要编码的规则越简单,意味着神经网络的训练越容易,计算效率也会更高。在实践中,Diffusion Model 的训练过程是「迭代式」的。在 Diffusion Model 的训练中,训练的样本是 形式的样本对。Diffusion Model 学习到的是:
这些学习到的规律编码在神经网络的参数中。Stable Diffusion 和 Disco Diffusion 数 G 体积的模型(如果大家在自己的电脑上跑模型,势必需要下载这些模型参数),就是训练得到的、固定和存储下来的对这些规律的编码。 相对应的,生成也是一种迭代式的反演。Diffusion Model 的每一步迭代只根据「当前图像的状态」和「模型中编码的规则约束」考虑下一步的状态会怎样。经过数十次的迭代后,也许生成的图像和初始状态千差万别,但其仍然是图像,并且符合语义引导。
神经网络机制问题。神经网络模型偏向于「记忆」而不是「推演」,对人类来说因为 A 所以 B 的简单逻辑,对神经网络来说,只能通过大量数据样本的训练,尝试记住「若 A 出现则有 B 出现」;而这种记忆是无法「衍生」的,比如「因为 A,所以 B,因为 B,所以 C」,对人类来说也很容易推导出「因为 A 所以 C」,而对神经网络无法组合两条规则得到「若 A 出现则有 C 出现」;
数据的问题。最常见的「手部画不好」的问题,很多人推测这是由于在数据中,不同视角、不同场景下的照片,人的手部形态看起来差异非常大(如握拳、握手、五指张开、比 V 字手势),在对应的文本中都是「手」;而且一些动漫人物(常常 4 个手指、甚至没有手指)的图片,也让神经网络对「手」的概念极端困惑;
神经网络注意力的问题。神经网络的梯度反向传播训练机制会让模型把注意力放在整体的画面感上。「整体画面 OK 而局部细节错误」相对应于「整体画面错误而局部细节完美」,其损失函数取值较小,意味着模型能够得到更多的奖赏和更少的惩罚,模型在做不到「整体画面和局部细节都完美」的情况下,往往更倾向于追求整体画面感;这也造成了「画人物肖像精美,但一个宏大场景下的人脸往往形同鬼魅」的现象;
除了这些问题之外,由于数据偏见,也常常导致模型的输出有偏差。例如,研究机构发现,当输入「CEO」的时候,Diffusion Model 有极大概率生成「一张西装革履的白人中年/老年男性」的形象,而不是女性、有色人种、少年人的形象,甚至在输入「黑人少年 CEO」的情况下也有不小的概率出现。这是因为在训练模型的样本中,「CEO」这个词汇往往和「西装革履的白人中年/老年男性」同时小出现,模型错误地学习了这种偏见。