CCAI 2017 | 香港科技大学计算机系主任杨强:论深度学习的迁移模型

作者 | 贾维娣
7月23日,由中国人工智能学会、阿里巴巴集团 & 蚂蚁金服主办,CSDN、中国科学院自动化研究所承办的第三届中国人工智能大会(CCAI 2017)在杭州国际会议中心盛大开幕。大会第一天上午,香港科技大学计算机与工程系主任、AAAI Fellow杨强教授发表了《深度学习的迁移模型》主题报告。
杨强从深度学习模型的共性问题谈起,深度剖析如何使深度学习模型变得更加可靠,在数据变化的情况下,模型持续可用。
报告谈到,迁移学习有小数据、可靠性、个性化等优点,虽然深度学习模型已在语音、图像、推荐等众多领域非常有影响力,但是在如医疗、教育等领域还无法运用,究其原因,主要存在这样三点:
我们遇到的数据往往都是小数据,而不是大数据;
深度学习模型非常脆弱,稍微移动、离开现有场景,其效果便会大打折扣;
再有就是应用问题。
由此,杨强教授与学生一起,将迁移学习与深度学习相结合进行了探索实践,在现场通过解决大额消费金融的困境、跨领域舆情分析、互联网汽车分类问题等多个实际应用案例多角度地展示了迁移学习的深度模型所带来的优点。
以下内容根据杨强教授主题演讲编写,略微有所删减。
大家好!今天很高兴跟大家分享我和研究生同学在研究当中的一些心得,总结起来叫深度学习的迁移模型。
首先讲一下我们的出发点,我们知道AlphaGo很厉害,但是它还有哪些点不够呢?它不会举一反三。你让它下一盘棋,它不会利用前面的知识来帮助自己很快地学习新的棋艺,更不会利用下棋的知识做一些其他事,比如说自动驾驶。我们人是有这个能力的,如何能够赋予计算机做这件事,这就是我们研究的一条主线。
由此引入我们的研究方向就是迁移学习(Transfer Learning),我们知道人能很自然地做这件事,从自行车迁移到摩托车,生活中还有很多的例子。这也从某种程度上解释了我们看到小孩子在学习中并不需要上千万的正例和负例帮助他学习,他往往用很少的例子就能学会一个很复杂的概念。同时学术界、工业界现在也认为迁移学习是下一个研究和应用的重点。去年Andrew Ng(前百度公司首席科学家 吴恩达)就讲了迁移学习下一步将被大量应用。
一、迁移学习的三大优点
为什么我们做迁移学习?我总结了三条原因:
小数据。我们生活当中大量遇见的是小数据而不是大数据,当数据很稀疏,看到不同的类别我们还是能在当中做出很靠谱的模型。这并不是空穴来风,而是之前我们有过很多大数据的经验可以去借鉴,站在大数据的巨人肩膀上,所以人工智能大量地应用,迁移学习这种模式是必不可少的。
可靠性。即使我们有一个大数据模型,我们也很关心它的可靠性。把一个模型迁移到不同的领域,就会发现它的准确率会大量下降,如何防止这一点,我们就需要模型本身具有自适应的能力,能够自带迁移能力。
个性化。我们整个的社会,我们的应用在向一个个性化的方向发展,有了云端,有了各种各样的终端,终端的操作者都是我们个性化的人。那么我们让一个模型、一个服务来适应我们每个人的特性,迁移学习是必不可少的。
迁移学习的难点在于找出不变量
迁移学习又是很难的。教育学有一个概念叫“学习迁移”,就是说如果一个学生学到了很靠谱的知识,怎样检测呢,就是看看他有没有能力迁移到未来的场景,再学一门新课他就发现学得容易,但是这种学习迁移能力的传输又非常难。
我们来看看怎样找出不变量。在国内和世界很多地方,驾驶员都是坐在左边,但是去香港驾驶员就是在右边,很多人不会开车了,就会出现危险,但是用迁移学习教你一招马上可以开,而且很安全,就是找出一个不变量。这个不变量就是司机的位置总是靠路中间最近的,你就保持司机的位置离中线最近就可以了。
找出不变量很难,但是在其他的领域已经大量出现。最近Yann LeCun提出一个问题:机器学习的热力学模型是什么?我的回答是迁移学习,把一个领域里面的知识、也就是“能量”,转化到另外一个领域,这和热力学把两个物质放在一起,然后研究热是如何能量是如何在物质间传播的,是类似的概念。区别是,在我们这里的知识比物理里的能量复杂很多倍。所以这个问题在科学上也是有深远意义的。
二、如何实现迁移学习:深度学习+迁移学习
今天我讲的是如何实现迁移学习中的一个方面。从单层次来看一个东西,把一个领域里的模型和知识通过层次分解,就好比杭州有雷锋塔,我们可以从一个古典的建筑发展到像雷锋塔这样有层次的建筑,一层一层分析,深度学习恰恰为我们提供了分层和层次。
下面我就仔细地描述一下,深度学习如果是从左到右,从输入到输出的变化过程,中间是有很多非线性地转化,我们可以忽略不计,但是这些层次我们要迁移到新的领域的话,知识的迁移就相当于参数的迁移,这些参数就是权重。
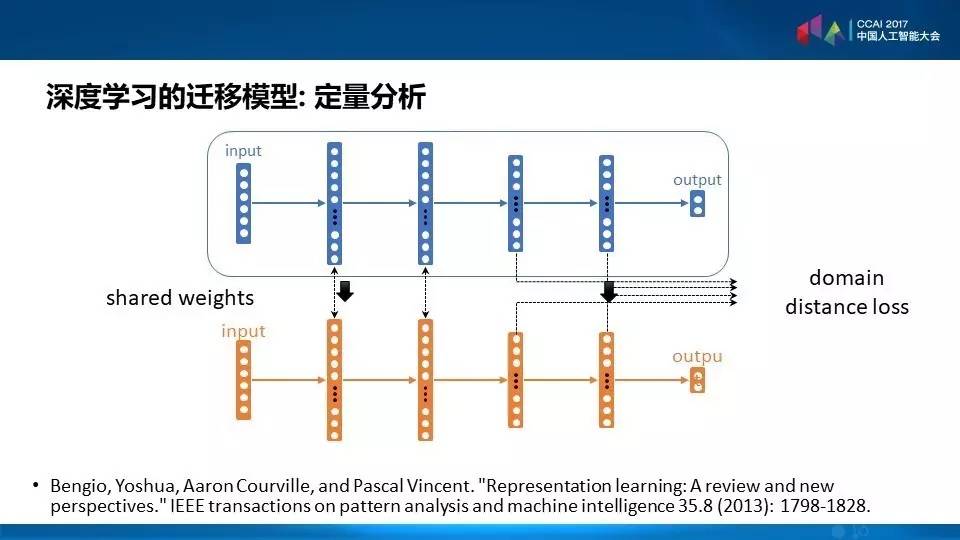
在这个里面我们可以看知识到底有多少可以从蓝色到橘色的,从源领域到目标领域,产生这样的迁移,我们可以看到中间层有很多层参数可以共享。另外层次越高的话,可能它关心的高层的概念离得越远。我们关心的是领域之间的距离,我们能否把领域之间的距离刻画出来,在深度学习的初创期,有很多启发式的做法,其实很多概念是和迁移学习不谋而合的。
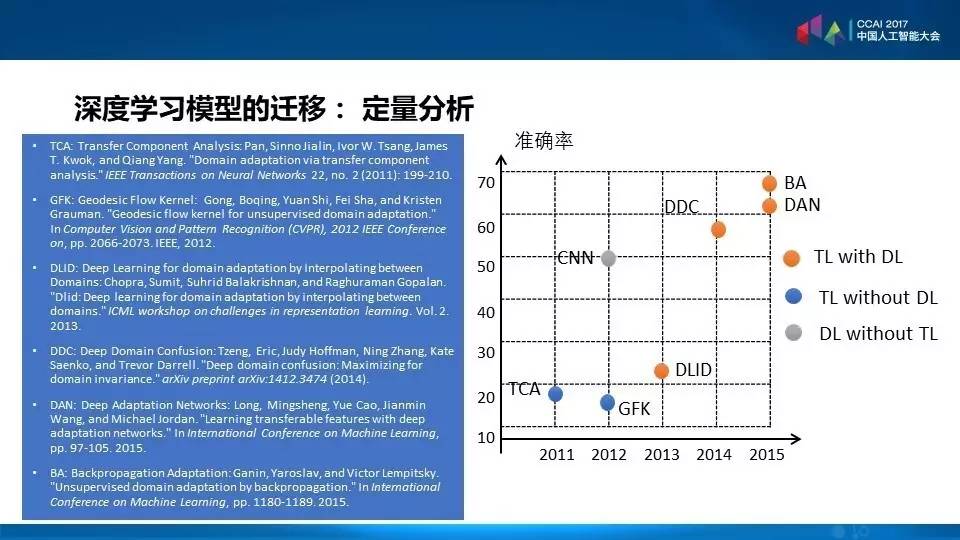
下面我们看看这样一种分层的研究对迁移学习到底产生了什么样的作用呢?我的学生魏颖就把最近的迁移学习和深度学习共同的工作画了表,这里面的名词像CNN、DDC都是最近发表的文章里面的系统名。横轴是年代,从2011年到最近,纵轴是准确率。左边是我一些学生做的工作,把迁移学习在不同领域里面的子空间,它们共享的知识找到,但是没有用到深度学习的概念,大概是2010年、2011年做的工作,叫TCA。
右边上面角是DAN,是深度学习加上迁移学习。我们看到深度学习加上迁移学习准确率大大提高,这不仅仅对理论有帮助,对工程的效率也是有帮助的。这里面用一个距离的表述,使用MMD发现两个领域两个数据集之间的距离,这个距离是在网络的上层,从左到右,从下到上,更重要的是发现并且尽量减少这样的距离。
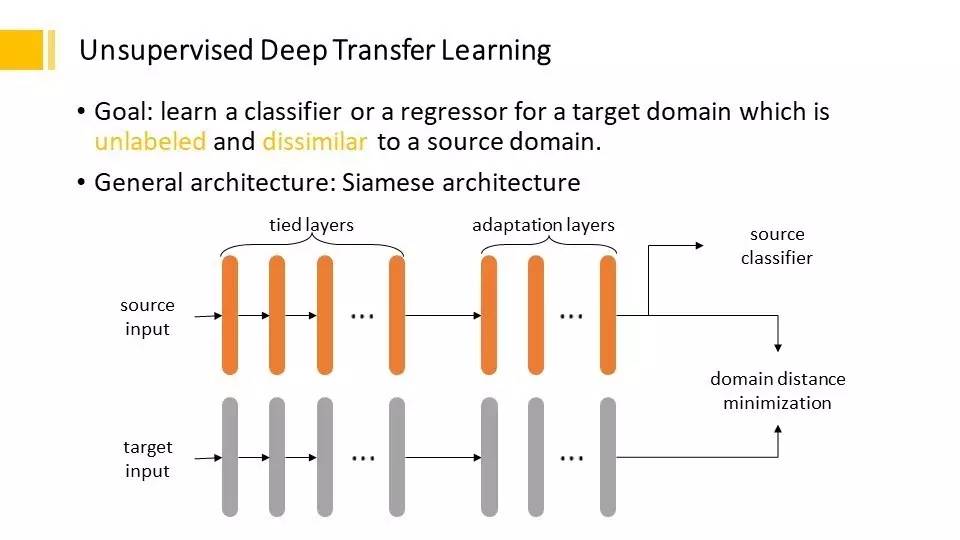
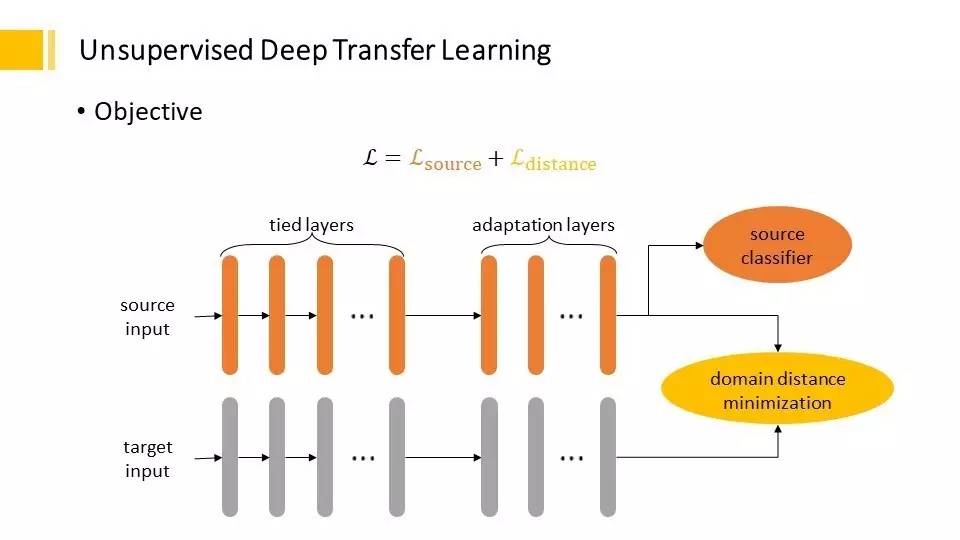
大家可以看到固定住,从一个领域迁移到另外一个领域,在下层比较容易迁移,在上层我们就关心领域之间的距离。
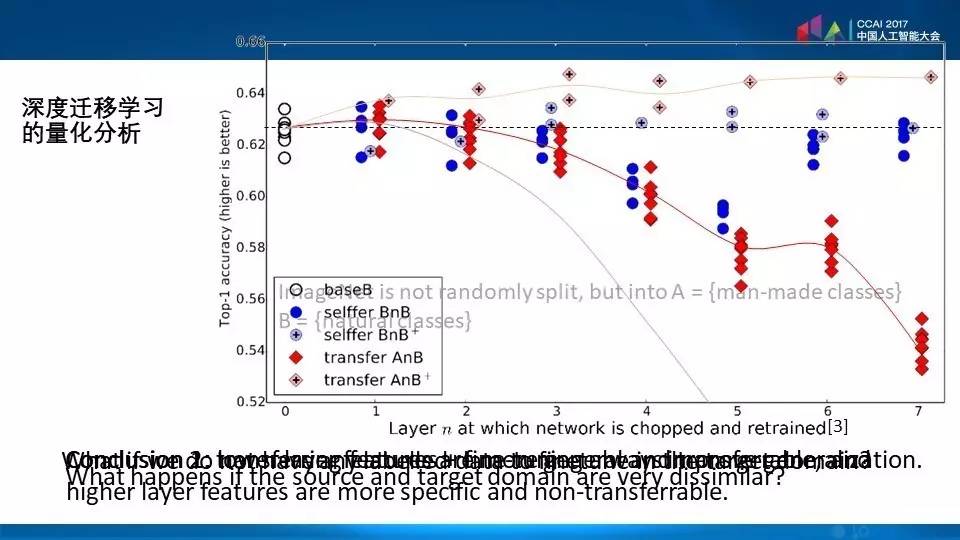
也有人把这个工作系统地进行了比较,我们可以看到代表迁移能力的红色是逐层下降的,从左到右逐层加深,如果是以深度学习的模型,下层在图像上比较容易迁移,在上层就不容易。我们在当中也可以做各种各样的演算和变化,比如说我们可以让迁移过来的参数,让它在之后的领域里面再得到重新的训练,这样就会得到上面的这条线,我们这个线放得越宽迁移能力就会变得越强,如果两个领域之间相差太大了,那么这个迁移是没办法进行的,就像下面的这条蓝线直线下降,这个能力就不行。
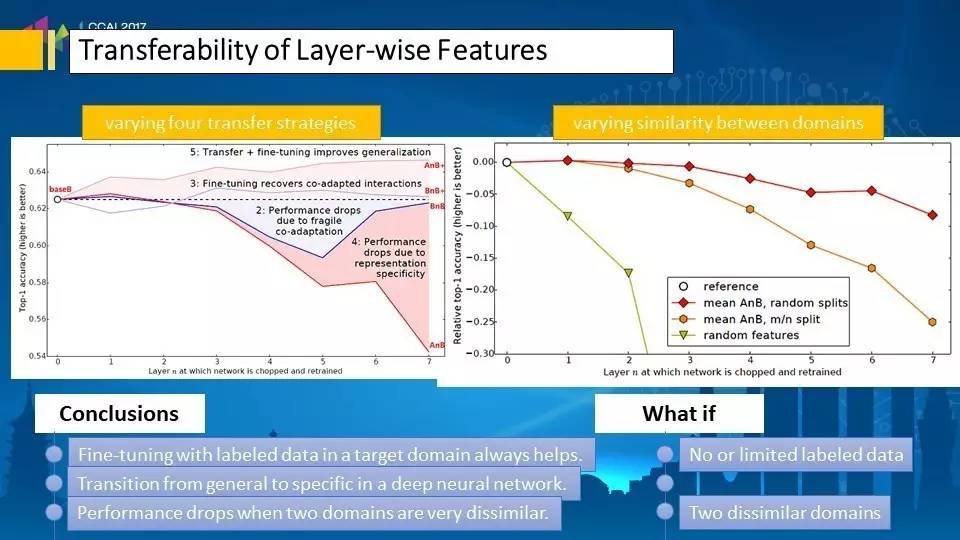
关于模型迁移,我们关心两点。
一是不同模型里面的一个层次,它的迁移量化。
二是两个领域的距离有没有一个很好的衡量,这也为我们的研究提供了一个很好的指引方向,像这里几条线就是更进一步地说明我刚才表明的观点,第一个是细微的调参,就是目标领域帮助我们继续调参是有帮助的。
另外从上层到下层是通用到个体的一种演化,大家看这些曲线是下降的。另外我们关心两个领域之间的距离。
下面我们就可以利用这个观点,对于不同的知识迁移的场景进行总结。
第一个是说我们在两个领域完全都没有标注的,目标和源数据都没有标注,这个时候我们就可以利用刚才的知识把下层固定住,直接迁移。在比较靠上层就可以放开,利用的方法是可以来减少两个领域之间的距离,这个距离虽然我们没有标注,我们还是可以把它衡量出来的,就像用刚才MMD的方法。
还有一个方法是就用一个Loss描述,这也有所不同,比如说两个领域之间的直接衡量,还有我们同时做两件事,第一件事是说利用两个领域之间的距离,我们要把这个距离尽量减少,同时我们让每个领域自己能够更好地表达它自己。
三、三种不同的迁移方法
将这些概念加起来,就可以总结出三个不同的迁移方法。
基于差异的方法
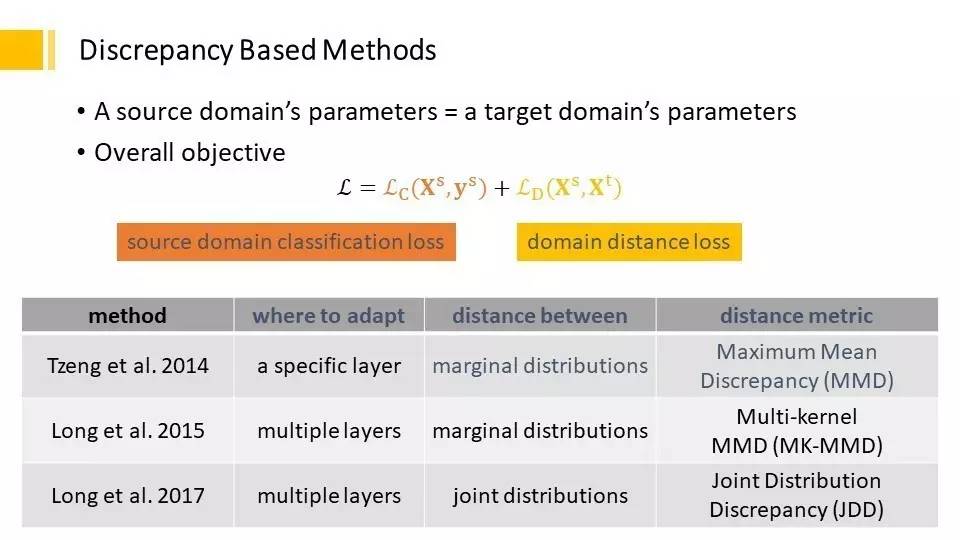
在哪里做迁移的转换、自适应。可以在某个层次来做,也可以在多个层次来做,如何来衡量两个领域之间的距离,可以用鲜艳的这种概率、模型,也可以用联合概率、模型,另外还可以将源领域的信息加进来,建立一个更准确的Loss。这都是图像领域获得的知识,那自然语言会不会有类似的方式呢?
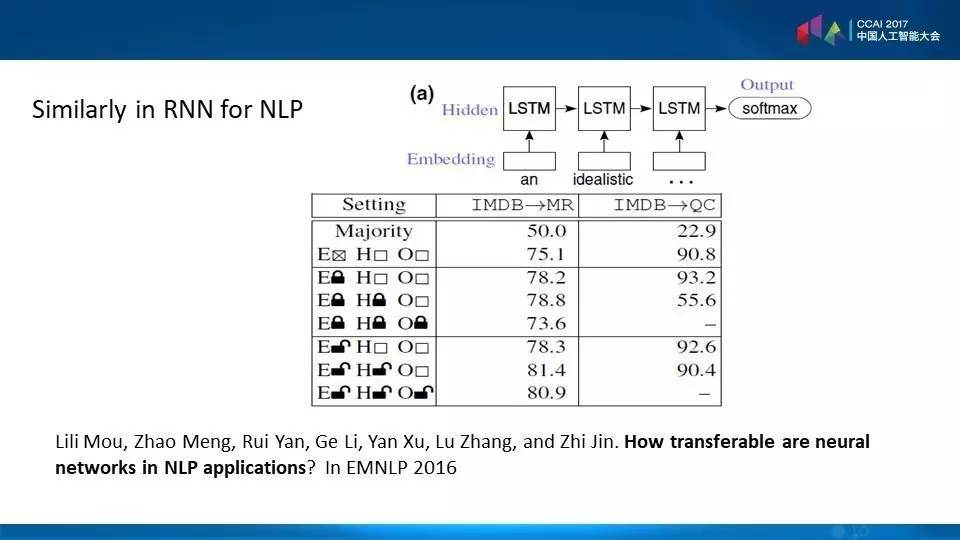
下面一篇描述NLP的文章也证明了这一点,假设我们把自然语言的深度处理分成三个层次,即E、H、O,如果我们锁定不变,而其他的层次有可能变化,也有可能不变化,这样可以发现,先迁移后微调的效果最好。
还有,在目标领域我们能够让它的再生后期做自适应的学习,就是开锁的这种,效果是最好的。
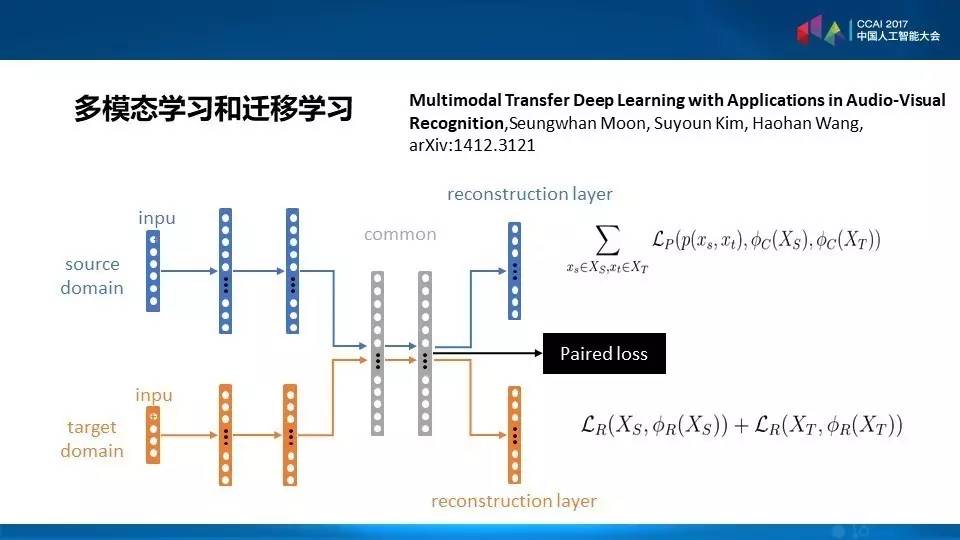
这个模型也可以发展到多模态,上面的源领域是图像,下面的可以是文字,可以让他们之间有一些层次可以分享。最后得到的系统就是既可以理解一个源领域,比如说图像可以转化为文字,又可以把文字转化成图像。另外还可以加入正则化,我们可以变化各种各样的正则,使得靠上层的层次之间互相靠拢。
传递式迁移学习
有了刚才的这些层次概念,可以将迁移学习进一步地发展,过去的迁移学习都是给一个源领域,一个目标领域,从源到迁移目标,现在我们可以多步迁移,从A到B,然后从B到C,就像石头过河一样的,这是我们最近做的工作,传递式的迁移学习。
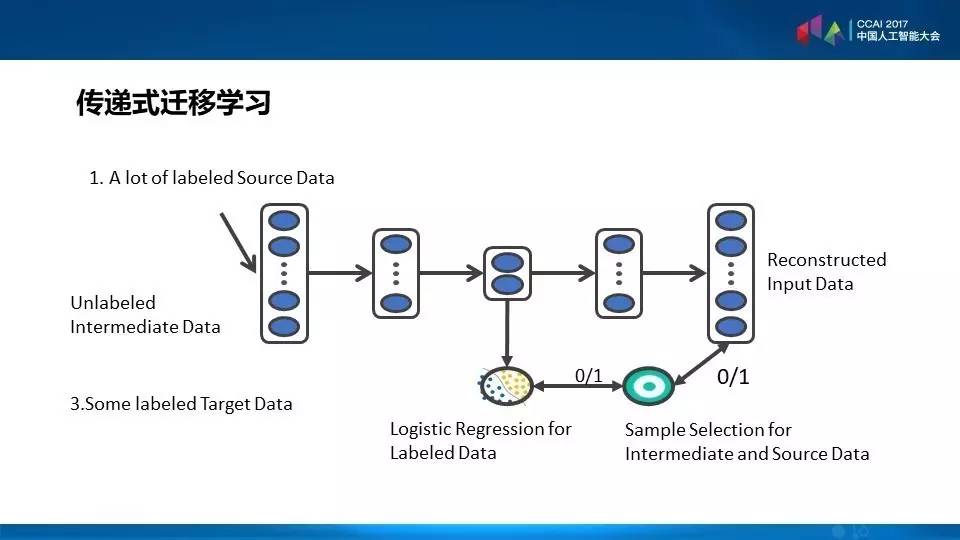
传递式的迁移学习也可以利用深度学习的分层这个概念进行。我们右边这里有三类数据,有一个是源领域的数据,比如图像,有一个是目标领域的数据,比如说文字,中间有很多文字和图像混杂在一起的领域。我们一个做法就是在中间领域挑一些样本,让它更好地帮助源领域迁移到目标领域,这些就像中间石头过河一样的。
如何得到这个,在训练目标模型的时候我们就有两个数据,一个是不断地检测在目标领域的分类效果,另外一个是不断地尝试新的样本,这些样本来自于中间领域和源领域,最后使整个不同的数据集之间形成一个新的数据集。

这样的一个理念在应用当中也非常有用,这是斯坦福大学最近做的一项工作,是从一个图像到卫星图像区分在非洲大陆上的贫困情况,最后就发现这种传递式的迁移方法效果确实和人为地去采样、标注效果差不多,一个是0.776,一个是0.761,而它中间人为的参与大大减少,因为它用了传递的过程。
生成对抗网络GAN
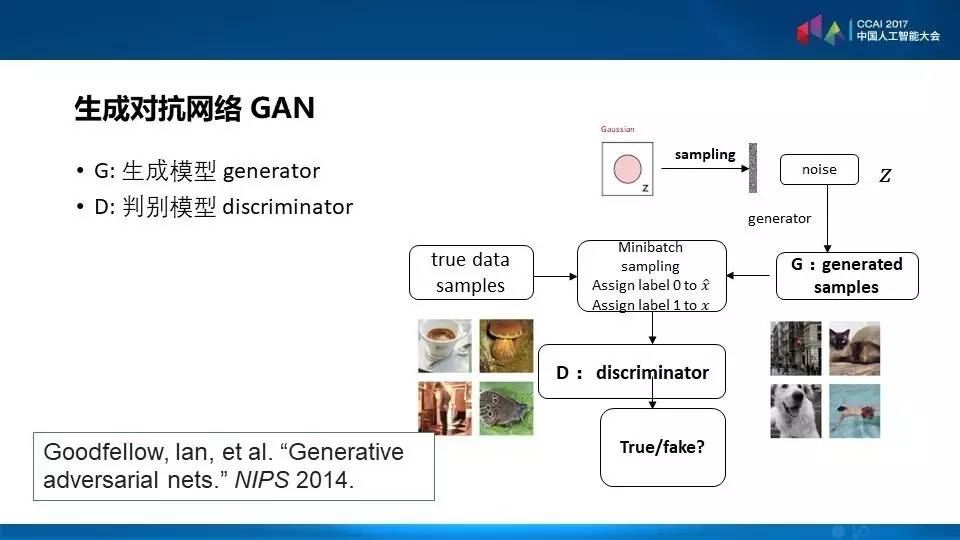
还有一种最近比较火的思想就是叫生成对抗网络GAN,它的思想来自两个模型交互,一个是生成模型,可以生成样板,就是右边的G模块,它一开始是非常粗糙的。还有是D模型,比较生成和真实的样本,它可以告诉你有没有被发现,你生成模型生成的样本够不够好,经过他们两者之间的博弈,最后就产生了学习的跃进,使得G和D两者都得到了改进。

很多学者也用这个方法来做迁移学习,比如说给两个数据集,我们一开始并没有一个数据,并不知道这个包对应这个鞋,系统通过深度网络,可以把这个Alignment模型生成出来,根据这个模型找到一个最匹配的鞋的模型,而且是完全生成的,在原数据,鞋的数据集是没有的,就像右边这里展示的。这种也是迁移学习的概念。
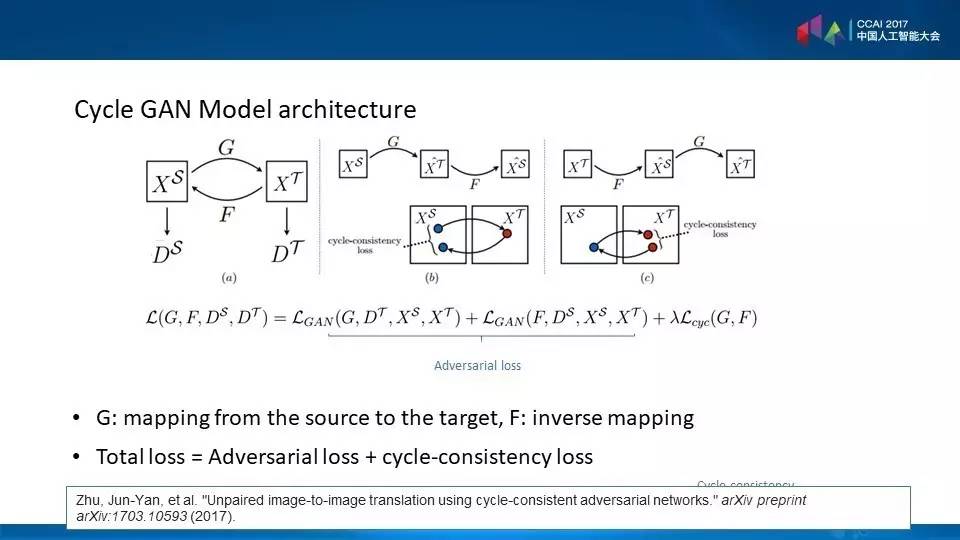
Cycle GAN的思想也非常有趣,一个源领域可以迁移到一个目标领域的话,我们同样也应该让一个目标领域的数据、知识迁移到源领域。如果是回来的话,如果还能返回原来的样本,那么就是说明迁移已经学得靠谱了。就像我们拿一首唐诗到机器翻译的软件翻译成英文,然后再拿同样的软件再翻译回中文,我们大家知道往往得到像乱码一样的东西,完全回不到原来的一首诗,如果能够回到原来的诗,那翻译就靠谱了,概念也是类似的。

GAN的模型确实带来了迁移的新意,让两个领域同时做两件事,这个图表示做的两件事。绿色部分是两者共享的深度学习的层次空间。我们如何找到这样的层次呢?就依靠第二件事,就是我们尽量地找到一个区分领域的模型,我们有源领域A和目标领域B,如果有一天模型发展到我们区分不了数据来自于哪个模型,那就说明共享的模型靠谱了,它就是抓住了两个领域之间的不变量,那就回到了左右开车的场景,那个不变量就找到了,这就可以用这部分做迁移了。最后得到的领域,准确率最高的就是通过刚才的模型得到的。
四、迁移学习应用案例
下面说一下我和我学生一起做的迁移学习的工作,尤其是跟深度学习结合。
一个叫戴文渊的学生,在第四范式这个公司做的工作就很有意义,他们为银行做一个大额产品的营销,比如说车贷,比较贵的车贷的样本非常少,少于一百个,这么少的数据是没办法建模型的,怎么办?去借助小微贷款的数据,比如说上亿的客户的交流,然后发现两个领域,一个是小微贷款,一个是大额贷款,他们之间的共性,把这个模型迁移过来,这就使得它的响应率提高了2倍以上。

另外是我们要去发表的一篇文章,做舆情分析。我们知道舆情分析是非常有用的,不管是在商业上还是在政府的服务上,大家都希望了解那么多的留言,是正向还是负向的?为什么是这样的?对哪些产品有兴趣?大家对哪个服务满意等。我这里给出两个不同的领域,如果我们在一个领域已经有像最左边这里给出的标注,比如说Great,这就是一个赞,说这个是Owful book,就给出一个差。我们的问题是能否借助相同领域的数据来减少我们的分量,使得我们建立一个靠谱的模型,在新的领域、目标领域。这是一个非常好的迁移学习的场景。
但是过去做迁移工作的时候,需要有一个概念叫Pivot,两个领域之间共享的关键词,这两个关键词对于指出这个是正向和负向也是非常有用的,像Great这个词,Boring和Awful,以前完全是靠人找到这两个词,我们知道这是不靠谱的。
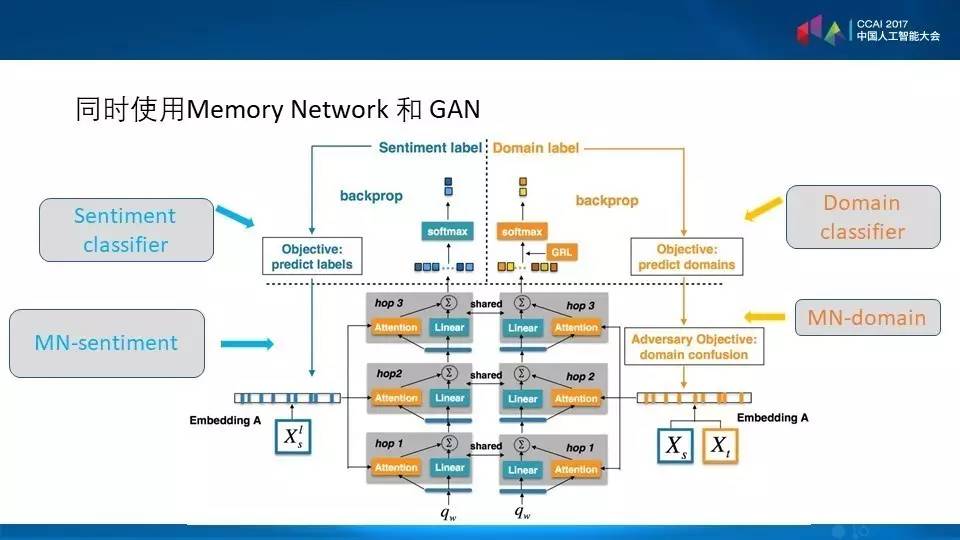
我们通过迁移学习把这个词找出来,在这里用的工具是Adversarial模型,在一堆摹本里面找出关注量比较大的词和词组,有了这一Adversarial模型,我们就可以自动打分,我们打的分数是否靠谱,可以用另外一个Domain Label的词告诉我们,什么样的词才有这样的特性呢?首先两个领域共享,能够帮助我们在新领域共同地指出舆情的趋向。同时希望模型越少越好,就是这三件事翻译成目标函数里面,就能建立模型。左边是舆情的Classifier,右边是领域的,我们同时希望领域的混淆度越大越好,同时我们希望Sentiment(舆情)的准确率越高越好,这两个之间形成博弈,就形成了GAN(生成网络)的概念,另外是多任务学习,就是两个任务共同进行,共同有一些共享。
最后我们在正确设定了一些距离函数和Loss以后,就可以学出来,效果非常好。
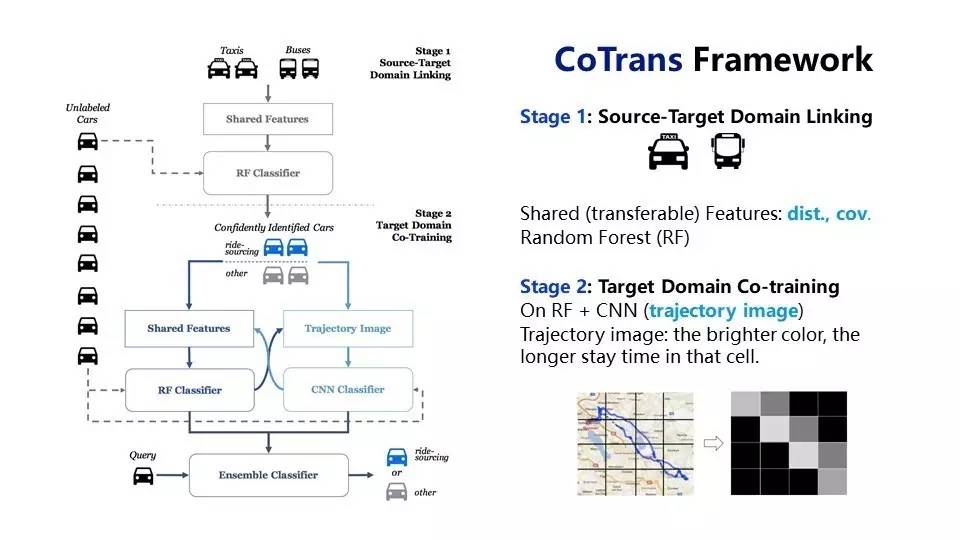
最后一个应用是和上海汽车做的研究,汽车在跑的时候能否根据它的路况分析车到底做什么?是共享还是私用的?我们很荣幸得到了一些数据,在这些数据里面我们可以同时进行两种分析,一种是图像分析,虽然我们本领域没有太多的标注数据,但是可以借用出租车来学习。左边的是同时做两个任务的学习,第一个是根据现在出租车的数据,来帮助我们标注互联网汽车的数据,但是这个当中可能会有错误,所以我们在本领域可以用一些图像分析来矫正这些错误,校正完再拿回来拓展这样的一个样本集。在这两个之间进行多次往返以后,我们就会得到一个很靠谱的模型,最后这样的一个算法我们就可以得到一个很不错的迁移效果。
最后总结一下,迁移学习和深度学习可以非常有机地结合,两个是可以互补的,深度学习帮助我们分非常细地层次,每一层我们可以进行量化的分析,迁移学习可以帮助深度学习变得更加靠谱,得到的一个结果就是深度学习的迁移模型,同时也应该说是迁移学习的一个深度模型。
谢谢大家!
CCAI 2017更多精彩内容,请关注微信公众号“AI科技大本营”,一次掌握“现场微信群”、“图文报道”、“视频直播”、“PPT下载”以及“大会期刊”所有入口!




