「虎卷er」开启!50道年度复习题带你重温去年国际AI顶会、重要SOTA工作,你能答出几道?
发论文、搞项目、赶DDL,忙碌了一年,想好好歇歇了?进入春节长假「休闲模式」才没两天,居然有点忍不住想要给安排点啥为几天后回归「奋斗模式」的自己找找感觉?
正月初二起,连续五天解锁 1套年度习题 + 4套复习资料!机器之心「虎卷er行动」深谙在「休闲模式」与「奋斗模式」之间犹豫不决、反复徘徊的你,这个春节从初二开始,一起轻松、欢乐地「来一卷er」吧~
「虎卷er」解锁日历
「虎卷er」由一套「年度习题」及四套「复习资料」构成,内容涵盖2021年度 ——
国际A类顶会最佳论文:ICCV、AAAI、ACL、CVPR、ICML、IJCAI、NeurIPS 等
国内外知名 SOTA 工作
国内外知名 AI研究组提出,并引起广泛关注的工作
国内外广泛引起关注的特大号模型
因刷爆 Leaderboard 引起广泛关注的国内外优质技术工作
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
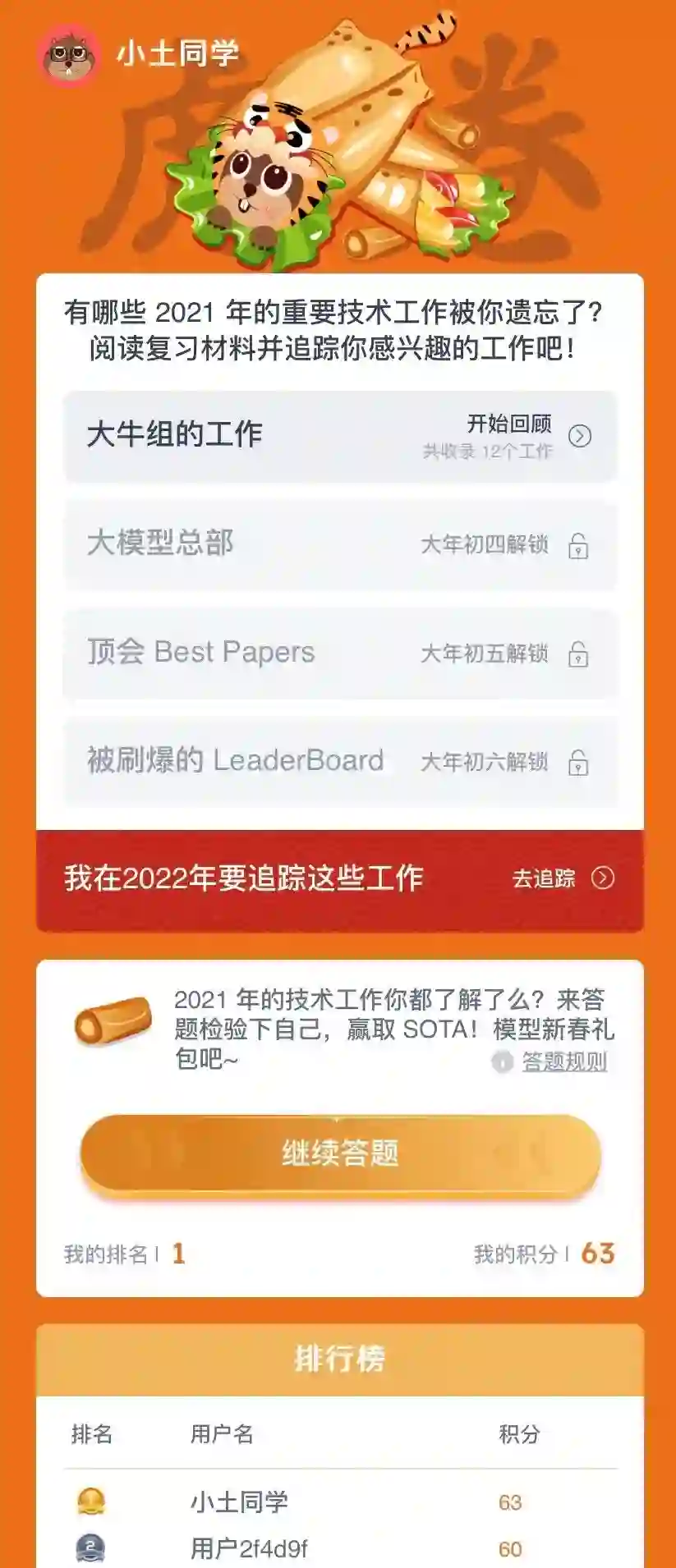
「虎卷er」年度习题全集 · 共五十道 ·
我们基于2021年度国际AI顶会「Best Papers」、重要SOTA工作,形成总计五十道年度习题。具体分布如下:
「Best Papers」:共 7 题
「大牛组的工作」:共 12 题
「大模型」:共 19 题
「刷爆基准的SOTA工作」:共 12题
以下为完整习题全集,共 50 道 ——
| 1 | 浪潮发布的 2457 亿参数模型叫什么? | |||
| 源1.0 | 潮1.0 | 涌1.0 | 浪1.0 | |
| 2 | 1350 亿参数的大规模稀疏模型 MEB 是谁推出的? | |||
| 清华大学 | 微软 | 百度 | DeepMind | |
| 3 | 百度与鹏城实验室联合发布 2600 亿参数模型鹏城 - 百度 · 文心版本为? | |||
| ERNIE 1.0 | ERNIE 2.0 | ERNIE 3.0 | ERNIE 3.0 Titan | |
| 4 | Quoc Le 等来自谷歌的研究者发布的模型 FLAN,零样本性能超越小样本,它的参数量是多少? | |||
| 1070 亿 | 1370 亿 | 1730 亿 | 2370 亿 | |
| 5 | 阿里达摩院提出半监督视频目标分割新算法 LCM,在 DAVIS 2016 数据集以多少 Overall Score 超过先前 SOTA? | |||
| 90.30% | 90.70% | 91.20% | 91.30% | |
| 6 | 谷歌、罗格斯大学提出 NesT,凭借多少参数取得了超越 Swin Transformer 的性能? | |||
| 62M | 64M | 66M | 68M | |
| 7 | 谷歌大脑提出全新图神经网络 GKATs,它没有结合以下哪种方法? | |||
| Graph Kernels | Attention-based Networks with Structural Priors | Efficient Transformers Architectures | Dueling Network | |
| 8 | 百度提出的跨模态文档理解模型,登顶 DocVQA 榜首,该模型名称是? | |||
| ERNIE-UNIMO | ERNIE-ViLG | ERNIE-Layout | ERNIE-TITAN | |
| 9 | 微软提出的 Florence 在 ImageNet-1K 零试分类任务中 Top-1 准确率以多少的分数取得了 SOTA? | |||
| 79.82 | 83.74 | 88.69 | 91.82 | |
| 10 | 哪个大厂提出适用于视觉任务的大规模预训练方法 iBOT,刷新十几项 SOTA,部分指标超 MAE | |||
| 阿里达摩院 | 字节跳动 | 腾讯 | 美团 | |
| 11 | 35 亿参数文本生成图像新模型 GLIDE 是哪个机构推出的? | |||
| Nvidia | Megvii | OpenAI | ||
| 12 | MIT 韩松团队提出 MUCNetV2,极大程度上解决了内存瓶颈源于什么设计导致的内存分布不平衡问题? | |||
| RNN | DNN | CNN | GNN | |
| 13 | 描绘了因果对机器学习的影响,并提出了该交叉领域的核心研究方向是来自哪一个团队的论文? | |||
| Geoffrey Hinton | Yoshua Bengio | Yann LeCun | John Hopcroft | |
| 14 | Facebook 提出的 13 亿参数 CV 新模型 SEER 采用以下哪种方法训练? | |||
| 强化学习 | 无监督 | 自监督 | 半监督 | |
| 15 | 何恺明团队提出的 Random Patch Projection 是针对 Transformer 在什么学习框架中存在的训练不稳定问题? |
|||
| 半监督 | 自监督 | 强化学习 | 无监督 | |
| 16 | 全球首个百亿参数中英文对话预训练生成模型 PLATO-XL 是基于以下哪个平台所研发的? | |||
| TensorFlow | PyTorch | PaddlePaddle | MindSpore | |
| 17 | 达摩院推出十万亿参数超大规模通用性人工智能大模型 M6-10T,该模型使用 512 GPU 在多少天内即训练出具有可用水平的 10 万亿模型? | |||
| 5天 | 10天 | 20天 | 30天 | |
| 18 | 清华刘知远、黄民烈提出的新框架 PPT 代表了什么? | |||
| Pre-trained Prompt Tuning | PowerPoint | Percentage Points | Precision Pressure Transducer | |
| 19 | DeepMind 提出 2800 亿参数的 Gopher,以下哪个说法是错误的? | |||
| Gopher 以自回归 LSTM 架构为基础 | DeepMind 采用 JAX 来构建训练和评估的代码库 | DeepMind 结合了 bfloat16 数字格式来减少内存并增加训练吞吐量 | DeepMind 使用了 Adam 优化器,所有模型的训练共有 3000 亿个 token | |
| 20 | 何恺明一作论文提出 Masked Autoencoders(MAE),该论文试图从下面哪几个角度研究导致自编码器在 CV 与 NLP 中表现的差异? | |||
| 架构差异 | 信息密度差异 | 自编码器的解码器在文本和图像重建任务中的不同作用 | 以上都是 | |
| 21 | 李飞飞等 100 多位研究者系统阐述了大规模预训练模型背后的机遇与风险,并统一给这些模型取名为? | |||
| Foundation Model | Active Model | Zero-Shot Model | Supervised Model | |
| 22 | 谷歌推出的视觉 Transformer 模型 ViT-G/14 的参数量属于哪种模型规模? | |||
| M(亿级) | L(百亿级) | XL(千亿级) | XXL(万亿级) | |
| 23 | 华为联合鹏城实验室开源的中文预训练模型盘古α 参数量属于哪种模型规模? | |||
| S(千万级) | M(亿级) | L(百亿级) | XL(千亿级) | |
| 24 | 生成流网络 GFlowNets 是谁提出的? | |||
| Geoffrey Hinton | Yoshua Bengio | Yann LeCun | John Hopcroft | |
| 25 | 谷歌推出的 Switch Transformer 参数量属于哪种模型规模? | |||
| M(亿级) | L(百亿级) | XL(千亿级) | XXL(万亿级) | |
| 26 | 30 亿参数的 Swin Transformer V2 没有在哪个数据集下取得过 SOTA? | |||
| ImageNet | ImageNet V2 | COCO test-dev | ADE20K | |
| 27 | 智源发布的悟道 2.0 的参数量为? | |||
| 1.5 亿 | 1.75 亿 | 1.5 万亿 | 1.75 万亿 | |
| 28 | 阿里达摩院发布 270 亿参数支持小说续写、诗词生成等能力的中文预训练语言模型名字是? | |||
| PUBG | PLUG | BLUG | BUPG | |
| 29 | 字节跳动提出 GLAT(Glancing Transformer),获 WMT 2021 大语种德英自动评估第几名? | |||
| 第一名 | 第二名 | 第五名 | 第六名 | |
| 30 | 谷歌推出 Switch Transformer 的模型参数量? | |||
| 1.2 万亿 | 1.5 万亿 | 1.8 万亿 | 1.6 亿 | |
| 31 | FAIR 等提出能用于视频模型的预训练方法 MaskFeat 是采用了什么训练方式? | |||
| 半监督 | 强化学习 | 自监督 | 无监督 | |
| 32 | 在 Yann LeCun 团队提出端到端调制检测器 MDETR 的工作中,以下哪个损失函数没有被使用? | |||
| Soft Token Prediction Loss | Text-query Contrastive Alignment Loss | Hungarian Matching Loss | GAN Least Squares Loss | |
| 33 | Facebook 推出有史以来第一个赢得 WMT 的多语言模型,并击败了双语模型,该模型涵盖 14 种语言方向,其中不包括哪种语言? | |||
| German | Japanese | Korean | Chinese | |
| 34 | 谷歌推出通用稀疏语言模型 GLaM,小样本学习打败 GPT-3,GLaM 的模型参数量是多少? | |||
| 1.2 万亿 | 1.3 万亿 | 1.4 万亿 | 1.5 万亿 | |
| 35 | 微信 AI 开源的那个可以在 700 美元电脑上训练 7 亿参数的的超大预训练模型训练系统叫啥? | |||
| 派大星 | 海绵宝宝 | 哆啦 A 梦 | 章鱼哥 | |
| 36 | 基于对比学习的文本表示模型 ConSERT 是谁提出的? | |||
| 美团 | 百度 | 饿了么 | 滴滴 | |
| 37 | 微软更新 DeBERTa 模型,单个 DeBERTa 模型在 SuperGLUE 上以多少的宏平均得分首次超过人类的分值(89.8)? | |||
| 90.1 | 90.2 | 90.4 | 90.3 | |
| 38 | GitHub 联合哪个组织发布了 GitHub Copilot? | |||
| FAIR | OpenAI | 谷歌 | DeepMind | |
| 39 | 开悟 MOBA 多智能体强化学习大赛以哪款游戏为测试环境? | |||
| LOL | DOTA2 | 王者荣耀 | 决战平安京 | |
| 40 | DeepMind 开源的 AlphaFold2 在人类蛋白质结构上的预测率是多少? | |||
| 98.50% | 98.80% | 98.60% | 98.70% | |
| 41 | 微软亚研院、北大提出多模态预训练模型 Nüwa,在 8 种包含图像和视频处理的下游视觉任务上具有出色的合成效果,其中不包括哪一项? | |||
| Text-To-Video | Image Prediction | Image Completion | Sketch-To-Image | |
| 42 | 以下哪一个机构的学者没有参与 P-tuning 的设计? | |||
| MIT | 清华大学 | 北京智源人工智能研究院 | 斯坦福 | |
| 43 | 以下哪个可能是 NLP 最新的范式? | |||
| Fully Supervised Learning, Non-Neural Network | Fully Supervised Learning, Neural Network | Pre-train, Fine-tune | Pre-train, Prompt, Predict | |
| 44 | 在多种翻译任务上取得了 SOTA 的词表学习方案 VOLT 是哪个机构提出的? | |||
| 百度 | 达摩院 | 腾讯 | 字节跳动 | |
| 45 | 为长序列时间序列预测(LSTF)设计的一个高效的模型 Informer 是基于以下哪个模型? | |||
| RNN | Transformer | GRU | LSTM | |
| 46 | Swin Transformer 获得了哪个顶会的奖项? | |||
| CVPR 2021 | AAAI 2021 | NeurIPS 2021 | ICCV 2021 | |
| 47 | 达特茅斯学院、德克萨斯大学奥斯汀分校等提出了一个基于哪种学习的框架来减轻生成文本中的政治偏见? | |||
| 强化学习 | 自监督学习 | 无监督学习 | 弱监督学习 | |
| 48 | 德国马克斯 · 普朗克智能系统研究所等提出 GIRAFFE 的工作在机器之心「Pop SOTA!List for AI Developers 2021」TOP 8 中的第几? | |||
| 第二 | 第四 | 第六 | 第八 | |
| 49 | IJCAI 2021 杰出论文奖之一是林雪平大学和庞培法布拉大学提出从广义规划的角度来处理经典规划问题,并学习描述整个规划领域不可解性的一阶公式。研究者是将该问题转换为什么任务进行分析? | |||
| 自监督分类任务 | 无监督分类任务 | 半监督分类任务 | 半监督回归任务 | |
| 50 | 比较模型生成的文本和人类生成的文本分布的散度测量方法 MAUVE 是哪个顶会的获奖论文? | |||
| ICML 2021 | AAAI 2021 | ACL 2021 | NeurIPS 2021 | |
答题通道现已开启!点击「阅读原文」,进入「机器之心SOTA!模型」服务号,点击菜单栏即可开始答题。
「虎卷er」年度复习题:答题须知
「虎卷er」年度复习题以帮助各位老伙计快速温故知新、了解过去一年的重要AI技术工作为目标。所有题目均已在正月初二公开,所有年度复习题答案均藏在「虎卷er」的4个复习材料分卷中。如果在查看过「虎卷er」年度复习题之后感觉比较陌生,我们鼓励你在认真完成复习后再来答题。
答题通道开放六天
答题通道将于 2022 年 2 月 2 日下午2点正式开放;于 2022 年 2 月 8 日 下午2点正式关闭。
可重复答题
在「虎卷er」年度复习题的答题过程中,老伙计们可对所有题目反复、多次进行回答。
首次答对分更高
首次答题答对,积 3 分;第二次回答答对了某题,积 2 分;三次及以上才回答对了某题,积 1 分。
4小时冷却「防沉迷机制」
为避免老伙计在春节期间「沉迷」于「虎卷er」刷分无法自拔错过与亲朋好友的聚会,我们设置了「4小时冷却」机制。在答完一轮全部50道题之后,需「冷却」4小时才能再次开始回答尚未回答正确的题。用这个时间,再去温习温习「复习材料」吧~
「虎卷 er 行动」新春「来一卷er」心意盲盒
答题通道将持续开放到 2 月 8 日 下午 2 点。参与答题的老伙计将有机会获得机器之心「SOTA !模型」、「机动组」及合作伙伴共同准备的「虎卷 er 行动」新春「来一卷er」心意盲盒~ 我们将基于所有「虎卷er」积分达到60分及以上的用户总量及分数分布,确定「来一卷er」心意盲盒内的礼品配置形式,并在2022年2月11日通过机器之心公众号及「SOTA!模型服务号」推送公布「来一卷er」心意盲盒发放形式,请务必关注!!!



