面向科研的推荐系统Benchmark诞生!

今天跟大家分享的是一篇发表在RecSys2020推荐系统年会上的关于推荐系统Benchmark的文章。你是否还记得关于MLP or IP:推荐模型到底用哪个更好?问题的激烈讨论,又或你是否还记得关于评论文本信息对推荐真的有用吗?问题的深入分析,再者你是否还记得知乎上关于深度学习对于推荐系统性能带来的都是伪提升问题的广泛质疑[1],这些问题之所以会存在的原因是:没有统一的标准,包括数据集的划分方式、统一的评价指标,相同的实验设置等。因此今天的这篇文章算是在这方面的一个进步。

论文地址:
动机:
推荐系统目前缺少一个基线标准用于任务评价。所以引发两个问题:模型的可复现性以及模型之间的公平对比,因此,本文针对隐式反馈Top-N推荐问题提出一种benchmark。
简介:
该文首先系统地回顾了85篇推荐论文,包括论文接收的年份和会议分布、常用的推荐系统数据集分布、所对比的基线模型的分布以及评价指标分布等。
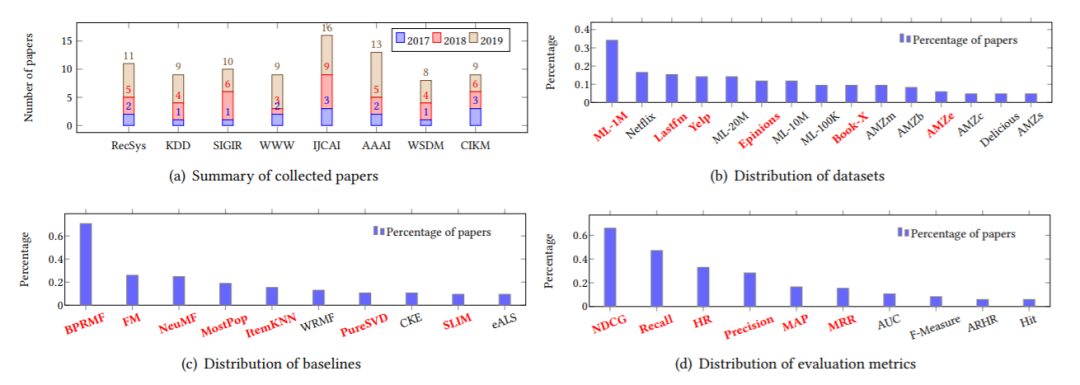
另外还总结出一些在对于模型评价具有重要影响的实验设置因素:数据处理,数据分割,超参数选择、负采样选择以及损失函数选择等。
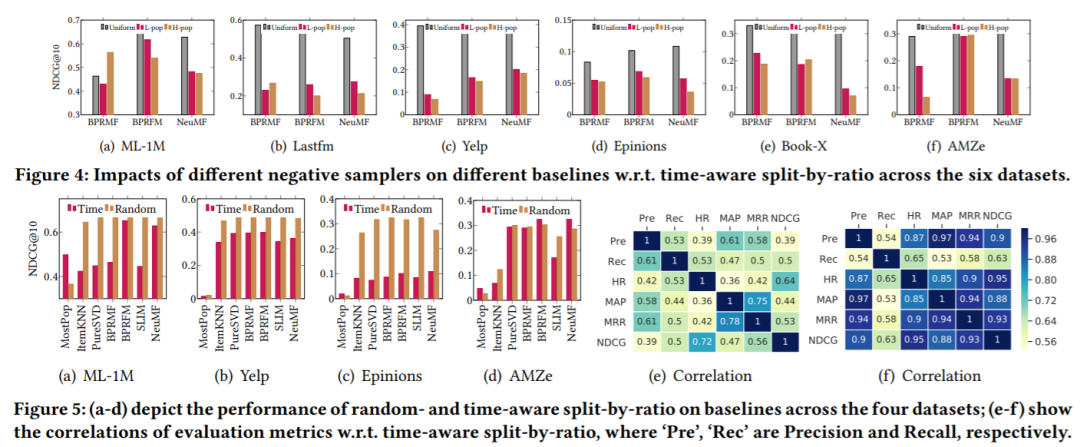
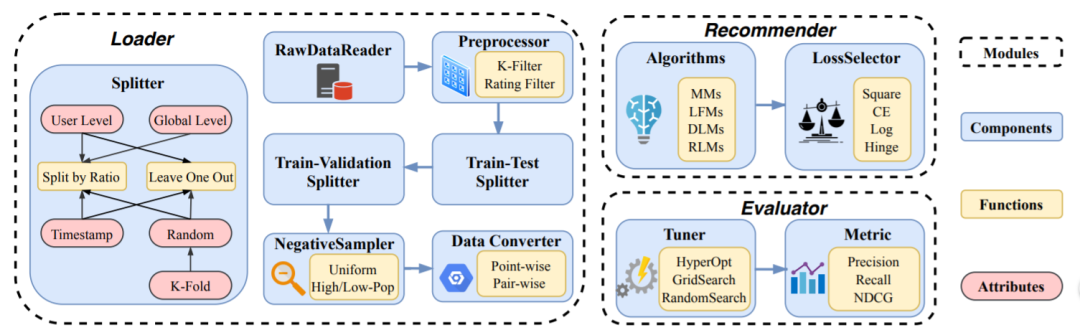
最后通过大量的实验说明这些实验设置给模型的表现带来的影响。接着提出benchmarks需要满足的一些条件,并基于此选择一些代表性的模型进行实验。除此之外,还发布了基于python的代码库。以下为该开源代码库的架构图,包括数据集的加载方式、预处理方式、对比方法选择等组件。
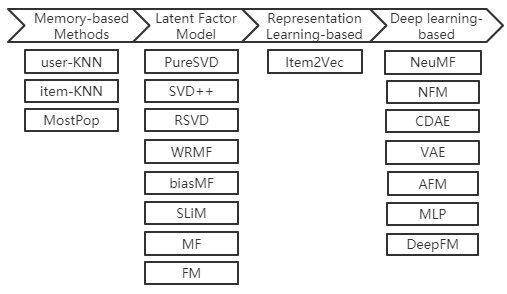
内含常用的基线和SOTA对比方法:
仓库地址:
希望未来的推荐算法能够良性对比,公平竞争。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏

