微软开源项目提供企业级可扩展推荐系统最新实践指南

编者按:推荐系统是在网络上最常见的服务之一,但在企业级服务的开发和落地过程中却往往遇到很多阻力。为了解决这些问题,微软云计算和人工智能开发团队与微软亚洲研究院团队深度合作,基于多年来各类大型企业级客户的项目经验以及最新学术研究成果,开源发布搭建完整推荐系统的最新实操技巧。该项目将大大降低企业开发大规模复杂推荐系统的时间,帮助更多企业部署推荐系统。
随着互联网技术的普及,越来越多的行业受惠于网络流量带来的经济效益。在互联网技术对各个行业的重塑过程中,人工智能算法发挥了至关重要的作用,推荐系统就是其中一个极具代表性的具象化应用。时至今日,推荐系统在电商、媒体等多个行业中展现了巨大的流量带动作用。人们越来越频繁地在网页和手机上看到基于推荐系统产生的信息,这些推送提高了用户在海量信息中筛选有效内容的效率,同时也增强了企业在相关业务上的用户细分。据麦肯锡报道,用户在亚马逊上购买的35%的商品以及在网飞(Netflix)上观看的75%的视频,都来自于两家公司各自算法的推荐。
虽然推荐系统对企业业务发展有着强大的推动作用,但在开发和落地的过程中却往往遇到来自不同维度的阻力,这使得推荐系统为企业创造价值的过程变得尤为缓慢。从工程的角度讲,定制和搭建企业级推荐系统的难点主要来自以下几个方面:
大多数学术研究成果或开源社区提供的范例并不适用于企业级应用。其主要原因是,符合生产落地标准的推荐系统对于实用性、可扩展性、鲁棒性等方面有着严格要求,大多数学术算法旨在深入研究推荐任务中的某些细分问题,而对于工业应用的支持十分有限。
对推荐系统的研究很多,但现有的学习指导资源极度碎片化。某一个推荐算法的实现很容易获得,但基于该算法搭建全链路系统的方案却少之又少,这对从业人员深入理解并实际搭建完整推荐系统构成巨大挑战。
新颖算法层出不穷,企业级应用实践者难以对各种算法进行比较和选择。如何选择最优算法以应对具体应用场景是个难题。

为解决以上痛点,微软云计算和人工智能开发团队与微软亚洲研究院团队深度合作,基于多年来各类大型企业级客户的项目经验以及最新学术研究成果,将搭建完整推荐系统的最新实操技巧开源并发布于Microsoft Recommenders。
GitHub链接:https://github.com/Microsoft/Recommenders
(扫描下方二维码或点击阅读原文,即可访问)

该来源项目包含了基于Jupyter notebook的搭建完整推荐系统的详细教程以及基于Python的推荐系统常用“工具箱”:
基于Jupyter notebook的搭建完整推荐系统的详细教程
GitHub链接:https://github.com/Microsoft/Recommenders/tree/master/notebooks
这其中包括
推荐算法的深度探索
除了经典的矩阵分解(Matrix Factorization)以及基于Apache Spark实现的最小二乘法矩阵分解算法(Spark ALS)之外,这些算法深度探索教程还包括了微软的Smart Adaptive Recommender(SAR)算法,微软亚洲研究院的eXtreme Deep Factorization Machine(xDeepFM)和Deep Knowledge-aware Network (DKN)算法(图1展示了DKN在新闻推荐中的应用),以及其它基于深度学习的前沿算法。每个算法的深度探索教程都充分介绍了该算法的基本理论和逻辑,并对算法参数的选择、具体应用环境的考量、以及对扩展性的支持等工程应用的细节进行深入探讨。
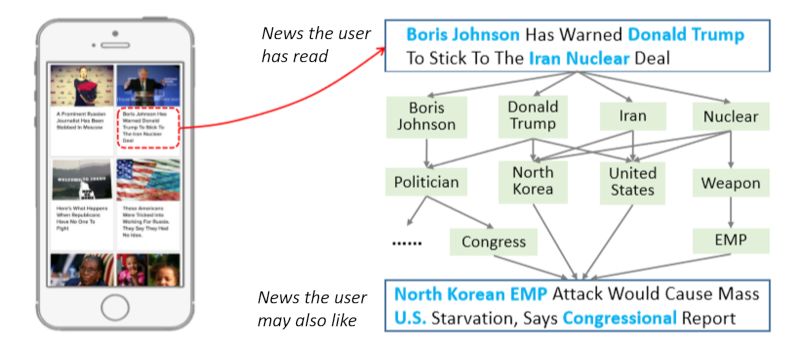
图1 Deep Knowledge-aware Network 算法在新闻推荐中的应用
数据准备、模型选择、模型评估的深度探索
除推荐算法之外,在实际推荐系统的搭建和应用中,数据处理模型验证等关键步骤往往耗费大量时间。这部分教程着重探讨在不同应用场景下不同数据和模型所需要的不同应对方案,例如,显式和隐式反馈数据的整理技巧,基于不同架构(如Spark分布式环境、GPU训练环境等)的数据准备技巧,常用离线推荐系统评估指标的选择和比较等等。
基于微软云平台Azure的全链路推荐系统部署
对于绝大多数推荐系统的开发和研究人员来说,完整搭建生产环境耗时耗力,为此,Azure云平台提供了方便高效的工具和服务来搭建完整系统。这部分教程详解了如何使用基于Azure的大数据处理平台(如Azure Databricks)、Azure机器学习服务(Azure Machine Learning Services)和Azure全球分布式数据库(Azure Cosmos DB)等工具开发企业级规模的可扩展推荐系统。
图2展示了如何使用上述服务搭建一个完整的实时推荐系统,该系统基于用户历史数据建立模型,并利用分布式数据库和基于容器服务的高并发性实现实时推荐。这其中,Azure大数据处理平台实现了Spark环境下的大规模数据预处理和模型训练,这保证了即使在海量用户历史数据的情况下,基于Spark的推荐算法依然可以得到可靠的训练结果。其后,基于训练得到的模型产生的结果存放于Azure全球分布式数据库上以用于实时推荐。同时,模型本身亦可部署在Azure的容器服务上为下游的服务端使用。开发者可以方便地调节分布式数据库和容器服务的参数来满足实时推荐的工程指标。部署在云端的整个模型训练、模型管理、以及模型部署的生产线流程都可以使用Azure机器学习服务来协调。除此之外,Azure机器学习服务的一些模块可以帮助模型开发人员进行高效调参以优化推荐模型性能。这部分的细节内容也可以在相应的实践方案中找到。
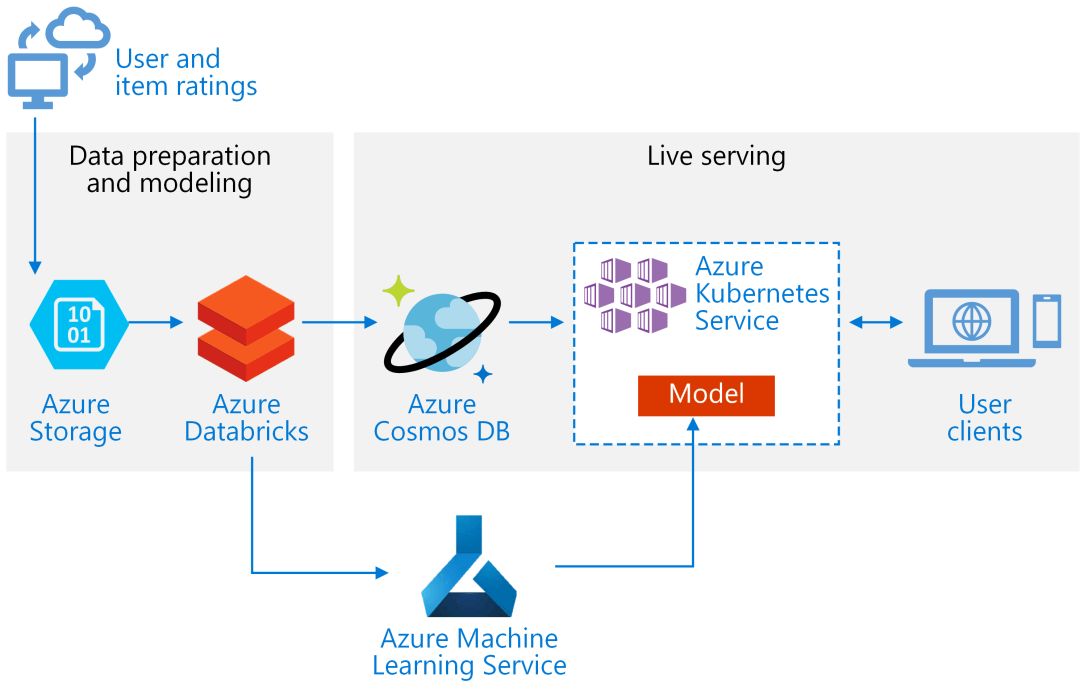
图2 基于微软Azure云平台的推荐系统
基于Python的推荐系统常用“工具箱”
GitHub链接:https://github.com/Microsoft/Recommenders/tree/master/reco_utils
搭建和实现推荐系统的代码通常需要复用,以满足开发效率的需求。除以上提到的基于Jupyter Notebook的教程式指导方案之外,该项目中还包含了一系列常用的工具函数,包括使用推荐算法实现的一些基本操作(如数据格式转换)、数据切分、模型评估指标等等。这些工具函数将大大节省技术人员的开发时间,同时也在最大程度上将推荐系统不同层面的具体实现模块化。
截至目前,该项目在多个基于微软Azure平台的产品和服务中得到了充分应用,为企业开发大规模复杂推荐系统节省了大量时间。在采用这套最新实践范例之后,几周之内即可完成原来需要数月时间的推荐系统开发工作。
在提供企业级最前沿技术的同时,项目的开发团队鼓励和期待广大开源社区的贡献和反馈。希望这套推荐系统最新实践方案能让越来越多关注推荐系统及其相关应用的企业和个人感受到人工智能对行业变革产生的积极效应,同时,也让智能推荐这项技术为更多人所熟知和应用,让更多的企业和个人可以参与其中。
作者简介

张乐,微软云和人工智能事业部数据科学家,Microsoft Recommenders项目负责人之一。张乐和所在团队帮助微软云平台Azure的战略级客户研发和部署端到端的人工智能解决方案。他曾为多个领域(如制造业、电商、金融等)的大型企业和初创公司开发场景相关的人工智能模型。他专注于最新算法的研究和生产用解决方案的落地。
本文贡献者还包括:
邬涛,微软云和人工智能部主任数据科学经理
谢幸,微软亚洲研究院首席研究员
练建勋,微软亚洲研究院副研究员
邢晔,微软云和人工智能部高级数据科学家
你也许还想看:
● KDD 2018 | 推荐系统特征构建新进展:极深因子分解机模型

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。






