10分钟入门推荐系统,这份有实战、有代码的资料火了!

如今推荐系统已经火爆到了什么程度?
几乎每个人手机中都至少有1款以推荐系统为核心的APP。
头条、抖音、知乎、淘宝等……
只要愿意去想,我估计在说出来20-30个顶级品牌也都不是问题。
为了帮助大家了解推荐系统。小七特意把《推荐系统实战》第一课的ppt呈现给大家。
推荐系统简介
一、what
分类⽬录(1990s):覆盖少量热门⽹站。例:Hao123 Yahoo
搜索引擎(2000s):通过搜索词明确需求。例:Google Baidu
推荐系统(2010s):不需要用户提供明确的需求,通过分析用户的历史⾏为给用户的兴趣进⾏建模,主动给用户推荐能够满⾜他们兴趣和需求的信息
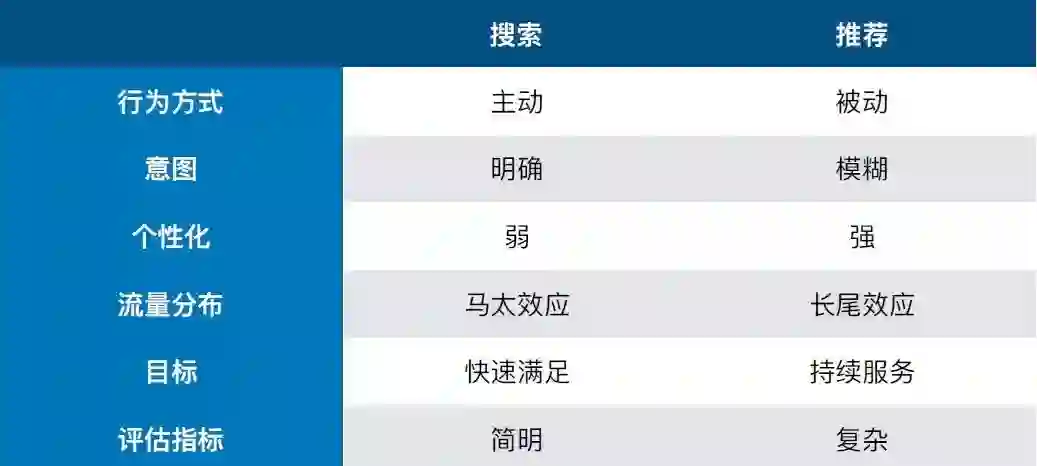
搜索vs推荐:
二、wht
1.推荐系统存在的前提:
信息过载
用户需求不明确
2.推荐系统的⽬标:
高效连接用户和物品,发现长尾商品
留住用户和内容生产者,实现商业目标
推荐系统评估
一、整体流程和常见指标
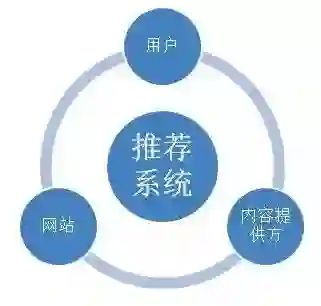
1.用户:满足需求、扩展视野、获得快乐。
2.内容提供方:获得长尾流量、获得认可和互动、收益。
3.网站:留住用户、实现商业目标。
4.常见评估指标:
准确性、满意度、覆盖率、多样性、新颖性、惊喜度、信任度、实时性、鲁棒性、可拓展性、商业目标、用户留存。
二、如何获得用户反馈
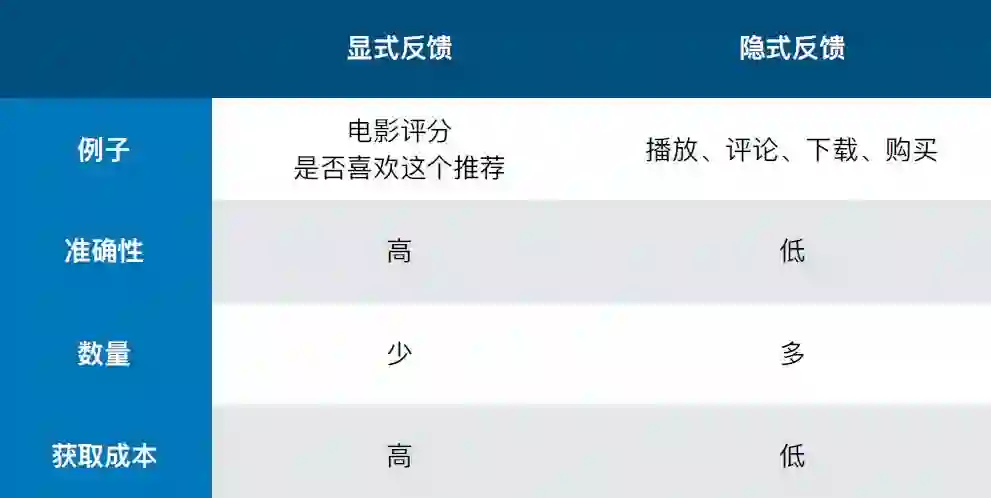
Explicit vs Implicit:
三、指标举例
1.准确性(学术界)
评分预测:
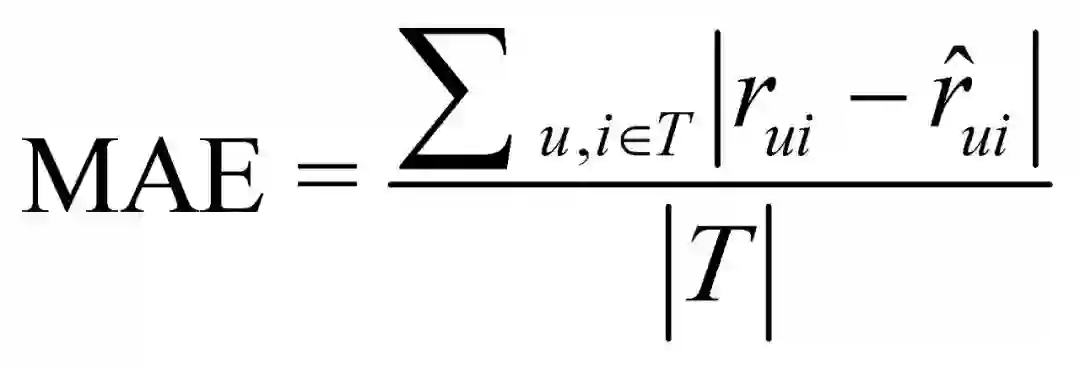

topN推荐:
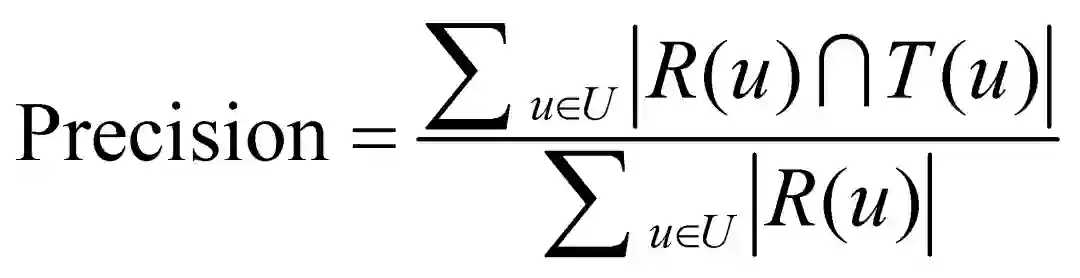
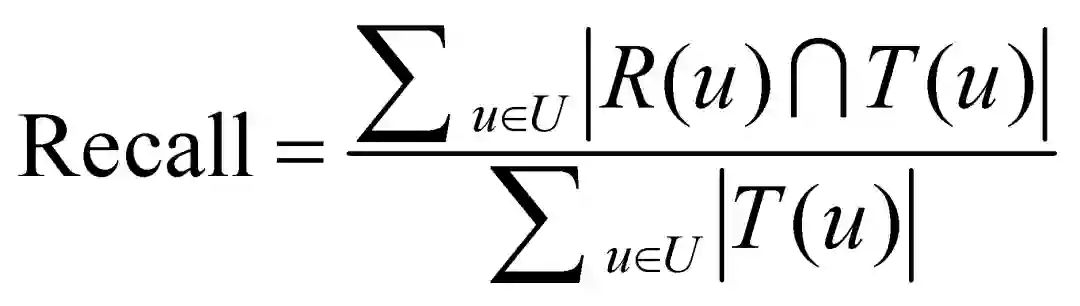
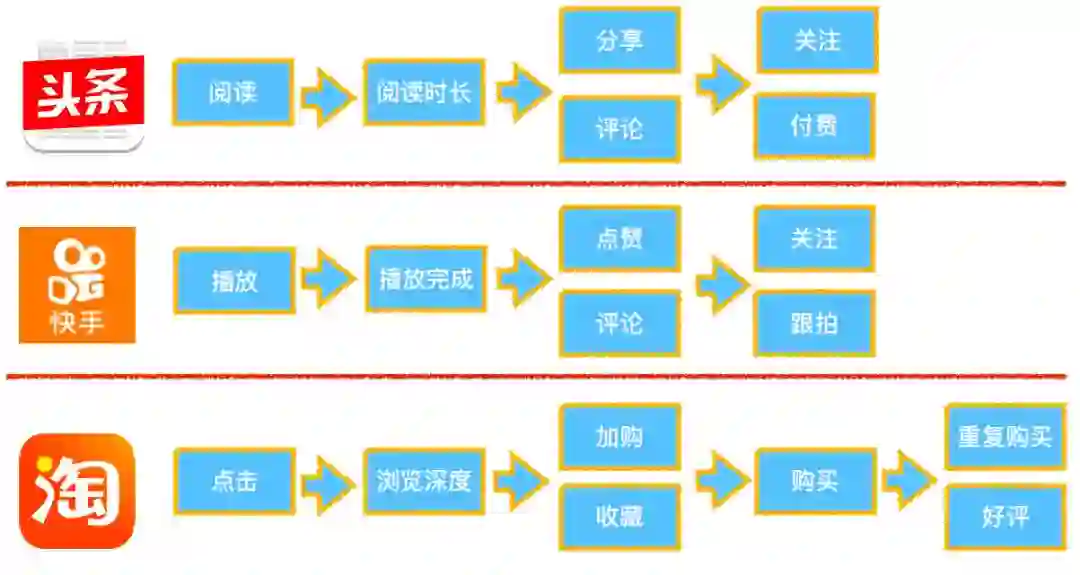
2.准确性(工业界):
3.覆盖度:
覆盖率:
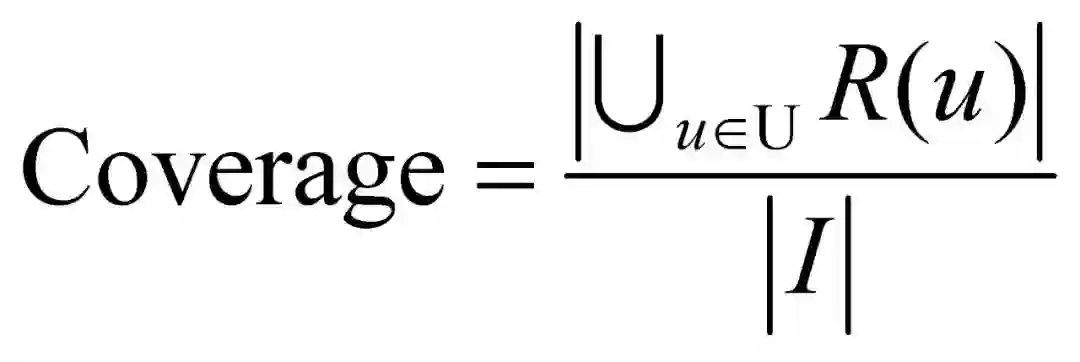
信息熵:
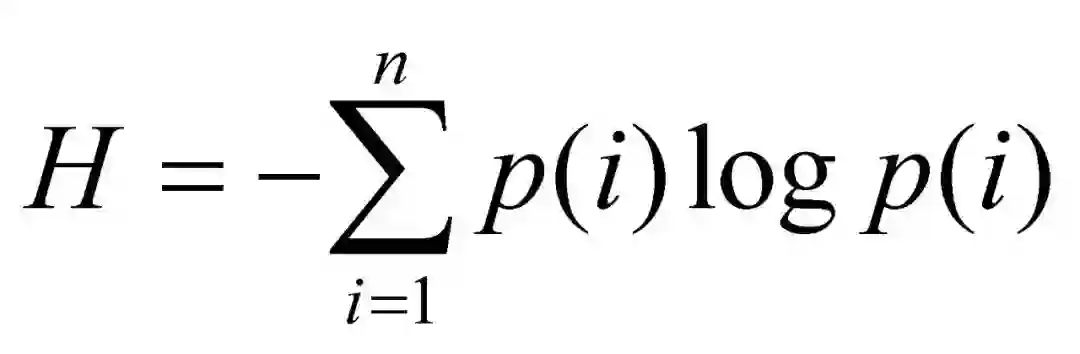
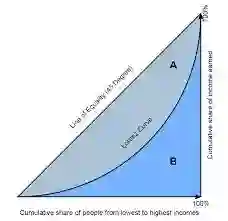
基尼系数:
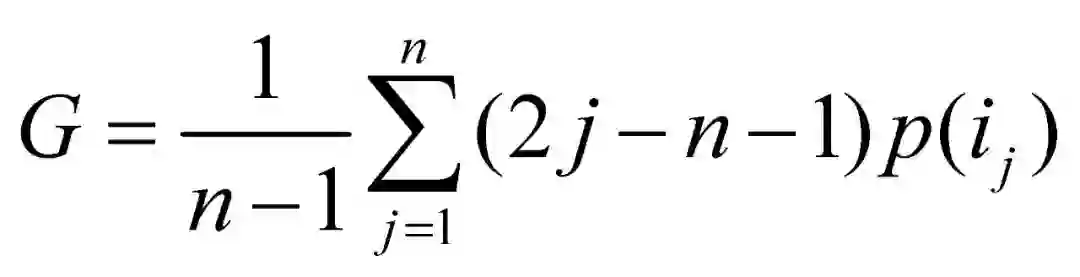
分层流量占比:
4.多样性:推荐列表中两两物品的不相似性。
5.新颖性:未曾关注的类别、作者;推荐结果的平均流⾏度。
6.惊喜性:历史不相似(惊),但很满意(喜)。
实现4、5、6这三点时玩玩会牺牲准确性。
四、如何平衡准确性和精准性
1.Exploitation & Exploration
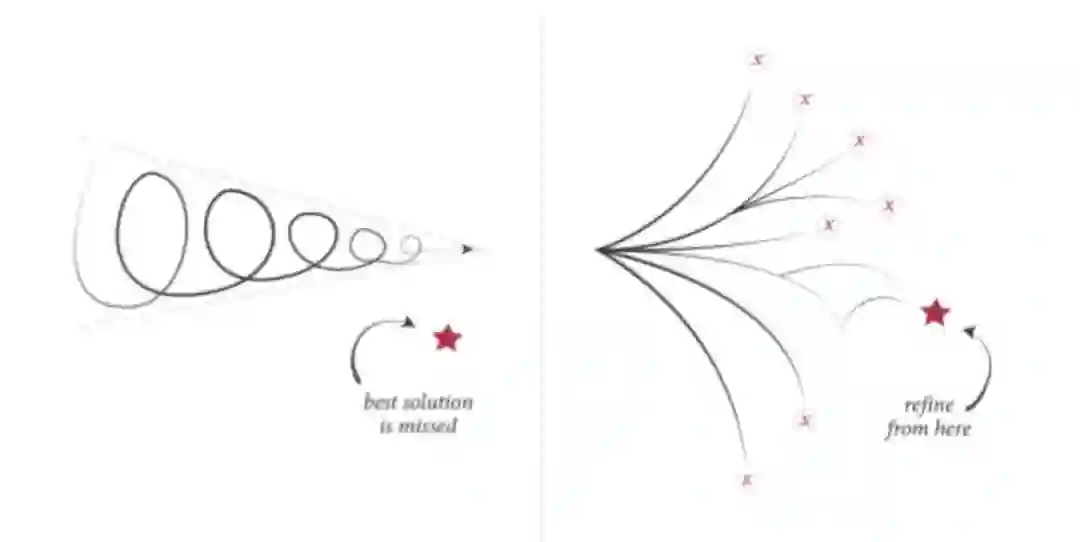
Exploitation:选择现在可能最佳的⽅案。
Exploration:选择现在不确定的⼀些⽅案,但未来可能会有⾼收益的方案。
总结:在做两类决策的过程中,不断更新对所有决策的不确定性的认知,优化长期的⽬标函数。
Multi-armed bandit problem:

2.Bandit算法
a.原理:
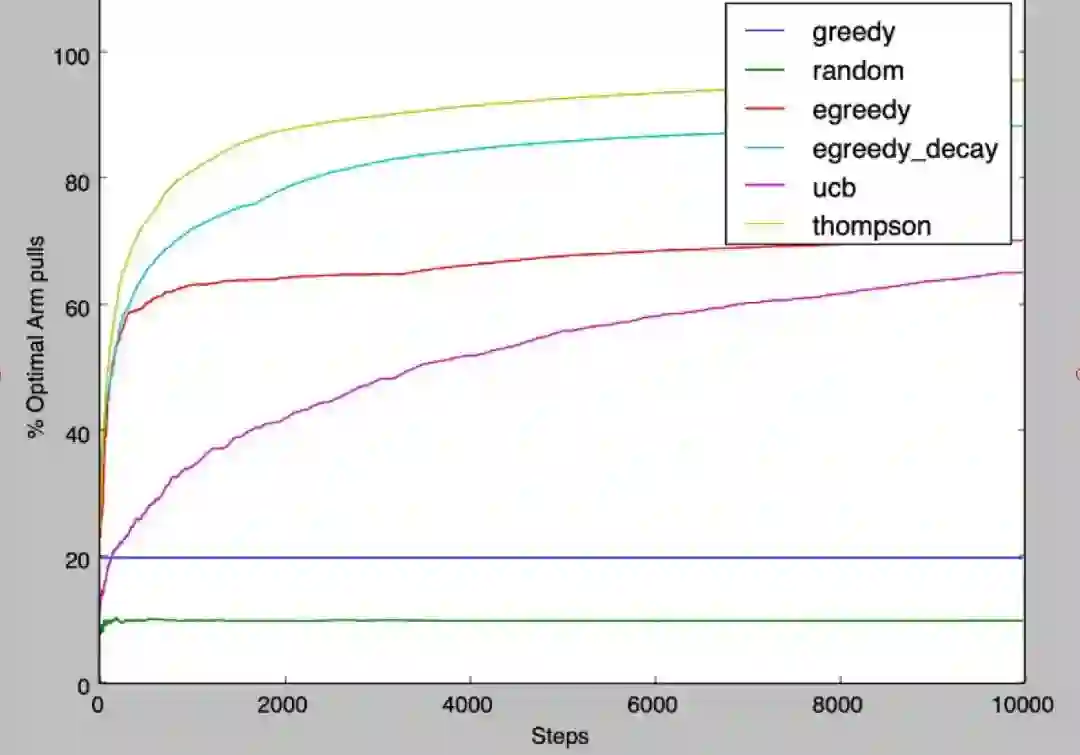
Epsilon-Greedy:以1-epsilon的概率选取当前收益最大的臂, 以epsilon的概率随机选取一个臂。
Upper Confidence Bound:均值越大,标准差越小,被选中的概率会越来越大。
Thompson Sampling:每个臂维护一个beta(wins, lose)分布,每次用现有的beta分布产生一个随机数,选择随机数最大的臂。
b.实现:

c.效果:
d.应用:兴趣探索、冷启动探索。
LinUCB:加入特征信息。用User和Item的特征预估回报及其置信区间,选择置信区间上界最⼤的Item推荐,观察回报后更新线性关系的参数,以此达到试验学习的目的。
COFIBA:bandit结合协同过滤。
基于⽤户聚类挑选最佳的Item(相似⽤户集体决策的Bandit)。
基于⽤户的反馈情况调整User和Item的聚类(协同过滤部分)。
3.EE实践
兴趣扩展:相似话题,搭配推荐。
⼈群算法:userCF、用户聚类。
Bandit算法。
graph walking。
平衡个性化推荐和热门推荐比例。
随机丢弃用户行为历史。
随机扰动模型参数。
4.眼前的苟且&远方的田野
探索伤害用户体验,可能导致⽤户流失。
探索带来的长期收益(留存率)评估周期长,KPI压力大。
如何平衡实时兴趣和长期兴趣?
如何平衡短期产品体验和长期系统生态?
如何平衡大众口味和小众需求?
如何避免劣币趋势良币?
评估方法
一、问卷调查
问题:成本高。
二、离线评估
问题:只能在用户看到过的候选集上做评估,和线上真实效果有偏差、只能评估少数指标。
特点:速度快,不损害用户体验。
三、在线评估
A/B testing。
四、实践
离线评估和在线评估相结合,定期做问卷调查。
五、AB testing
1.单层实验:以某种分流的方法(随机、uid%100),给每个实验组分配⼀定的流量。每个实验组配置不同的实验参数。
2.问题:
只能支持少量实验,不利于迭代。
实验之间不独立,策略之间可能相互影响。
分流方式不灵活。
六、多层重叠实验架构
1.特点:保留单层实验框架易用、快速的优点的同时,增加可扩展性、灵活性、健壮性。
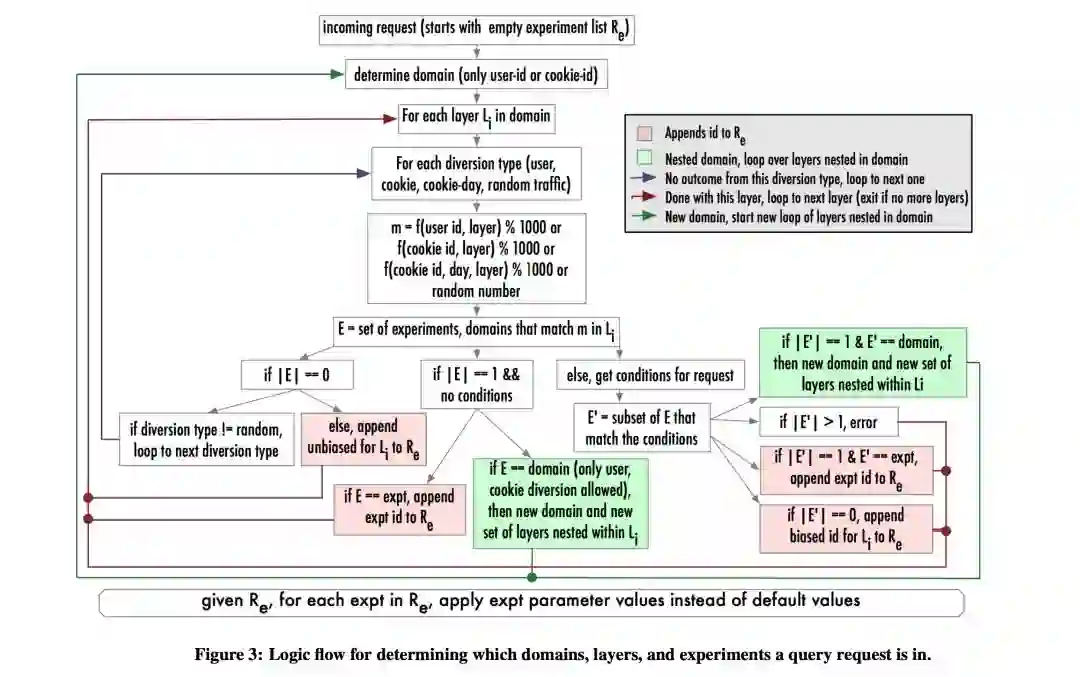
2.核心思路:将参数划分到N个⼦集,每个子集都关联⼀个实验层,每个请求会被N个实验处理,同一个参数不能出现在多个层中。
3.问题:
分配函数(流量在每层被打散的⽅法)如何设计?
如何保证每层流量分配的均匀性和正交性?
如何处理实验样本的过滤(eg只选取某个地区的用户、只选取新用户)?
分配多⼤的流量可以使实验置信?
解决冷启动问题
一、冷启动
1.用户冷启动:如何为新用户做个性化推荐。
2.物品冷启动:如何将新物品推荐给用户(协同过滤)。
3.系统冷启动:用户冷启动+物品冷启动。
3.本质:推荐系统依赖历史数据,没有历史数据⽆法预测用户偏好。
二、用户冷启动:
1.收集用户特征:
用户注册信息:性别、年龄、地域。
设备信息:定位、手机型号、app列表。
社交信息:推广素材、安装来源。
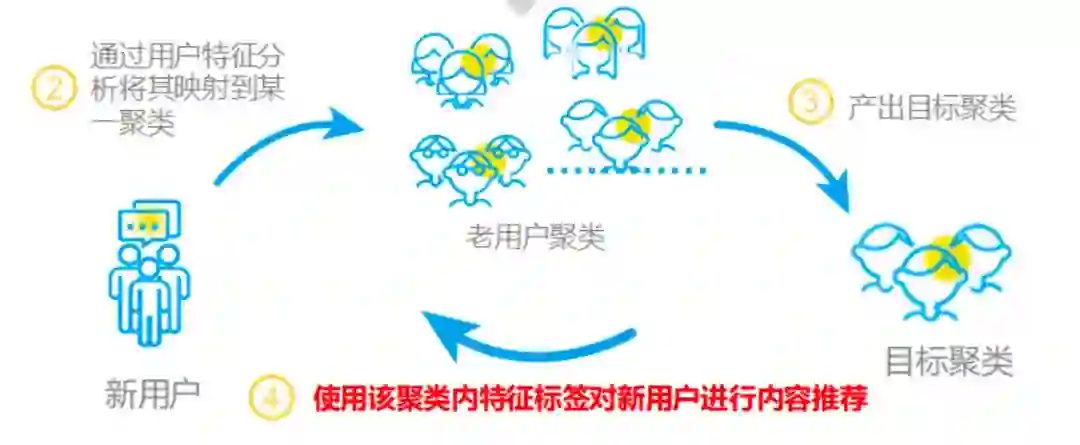
2.制造粗粒度选项,吸引用户填兴趣
3.transfer learning:使用其它站点的行为数据。如腾讯视频&QQ音乐,今日头条&抖音。
4.新老用户推荐策略的差异
新⽤户在冷启动阶段更倾向于热门排⾏榜,⽼⽤户会更加需要长尾推荐。
推荐候选的代表性&多样性。
Explore Exploit⼒度。
使⽤单独的特征和模型预估。
保护⽤户体验(物品冷启动探索、⼴告、推送)。
三、物品冷启动
物品冷启动时会遇到哪些问题?
如何做物品冷启动推荐?和⽤户冷启动策略有哪些异同?
如何评估物品冷启动推荐的质量及带来的收益?
实验传统的ab testing⽅法是否能够验证冷启动优化效果?
推荐系统架构
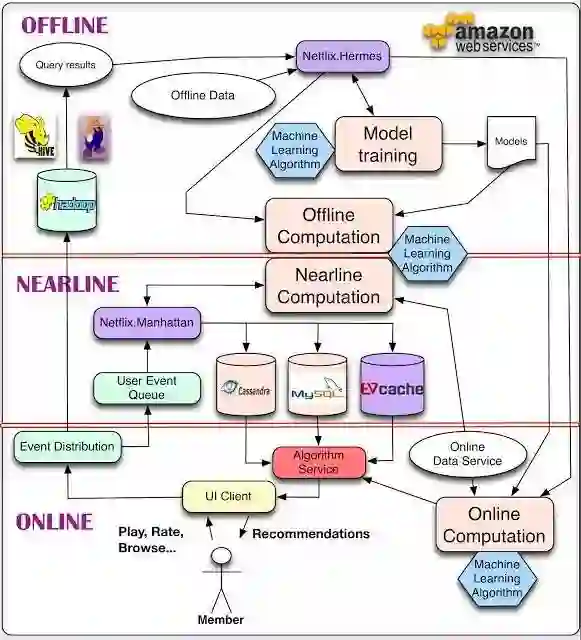
一、Netflix,2013
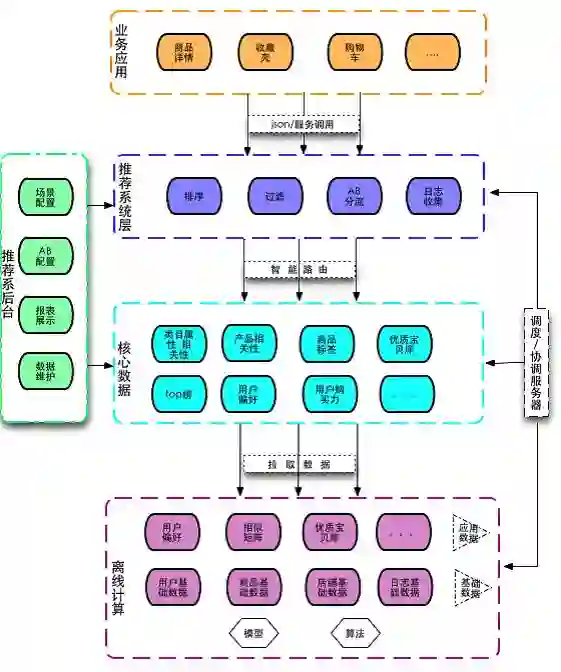
二、Taobao,2015
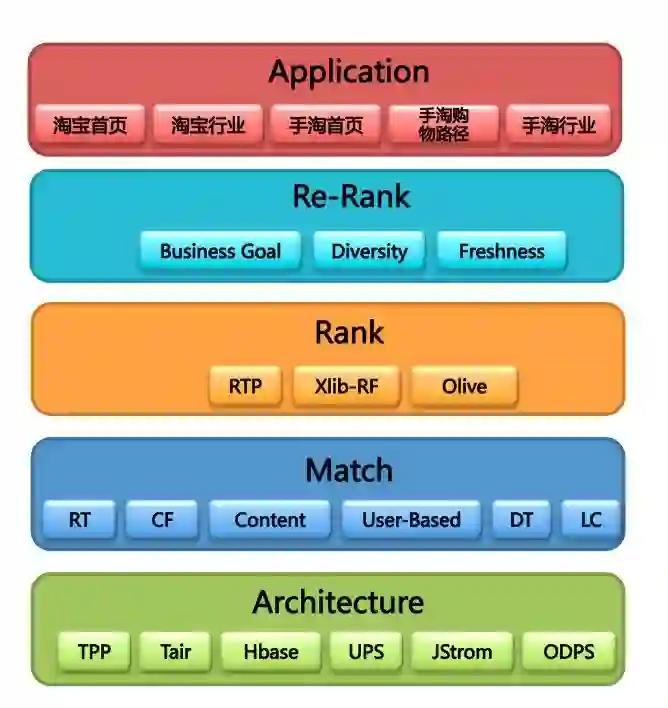
三、YouTube,2016
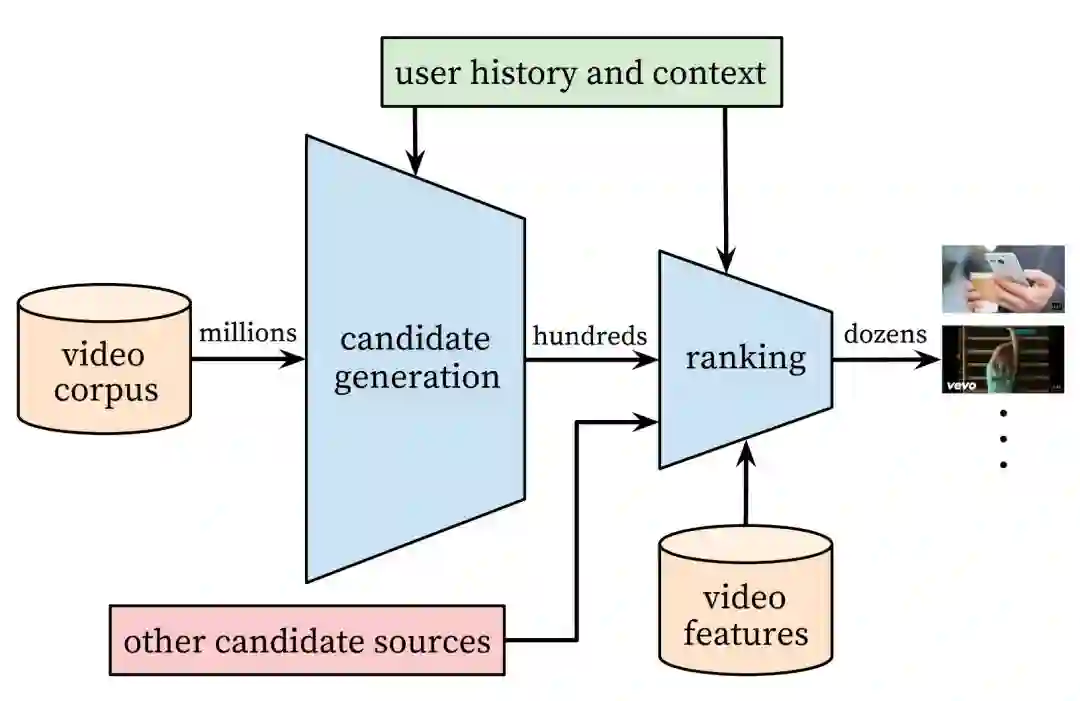
四、推荐系统的发展
1.发展阶段:
1.0:关联规则、热门推荐等统计⽅法。
2.0:矩阵分解等ML⽅法,离线计算推荐列表。
3.0:召回 + learning to rank重排序。
4.0:召回&排序实时化。
5.0:end2end深度学习,⼀切皆embedding。
6.0:智能化推荐系统。
2.发展趋势:

3.架构:
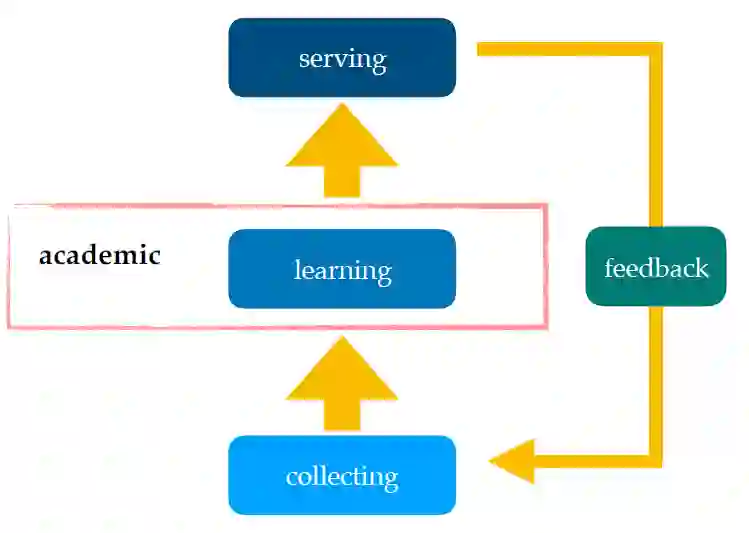
五、学术界和工业界之间的差别

《推荐系统实战》第一节课的ppt已经分享完毕了,感兴趣的话可以文末点击阅读原文,进行免费试听哦。
明天就是端午节了,小七提前祝大家端午安康,趁老板不在偷偷给大家发个福利。
现在可以点我,按规则留言,就有机会拿到李航博士的大作《统计学习方法》第2期。


就业班来了
依据个人情况定制化教学
名企面试官亲自辅导面试
让你“薪”满意足!
悄悄告诉大家
现在扫码咨询有神秘优惠哦