论文浅尝|简单高效的知识图谱表示学习负样本采样方法
笔记整理 | 陈名杨,浙江大学在读博士生,主要研究方向为知识图谱表示学习

NSCaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding
论文来源:ICDE 2019
论文链接:https://arxiv.org/pdf/1812.06410.pdf
Introduction
研究知识图谱表示学习(KnowledgeGraph Embedding)可以解决当前很多应用的基本问题,这些方法旨在将知识图谱中的实体(Entity)和关系(Relation)都映射到低维向量空间中,并且捕获实体和关系之间的语义信息。当前很多知识图谱表示学习的方法都着重于设计新的得分函数(Score Function)从而可以捕获实体和关系之间复杂的交互。
然而在知识图谱表示学习的过程中,一个重要的部分——负采样(Negative Sampling)并没有被足够的重视。在知识图谱中,负样本采样的需求来源于KG中仅包含真实的正样本三元组,而在训练知识图谱表示的过程中,每个正样本需要对应相应的负样本。当前很多方法都使用均匀采样(Uniform Sampling)的方式,然而这样的方式很容易造成训练过程中的梯度消失,也就是很多负样本都是很容易被划分为负样本的简单样例,得分函数很自然的对这一类负样本给出较低的分数,从而导致训练过程中梯度为零。
所以高质量的负样本应该是得分函数给出较高分数(被误认为是正样本)的负样本,这篇文章探讨了在知识图谱表示学习模型的学习过程中(1)如何捕获并且建模负样本的动态分布,以及(2)如何有效地进行负样本的采样。
作者发现负样本的分数分布是高度偏斜的(Skewed),也就是说只有少量的负样本的分数较高,其余的分数较低的负样本的对后续的训练几乎无用。这个发现促使作者设计模型来维护这部分高质量的负样本三元组,并且在训练的过程中动态地更新。
Proposed Model
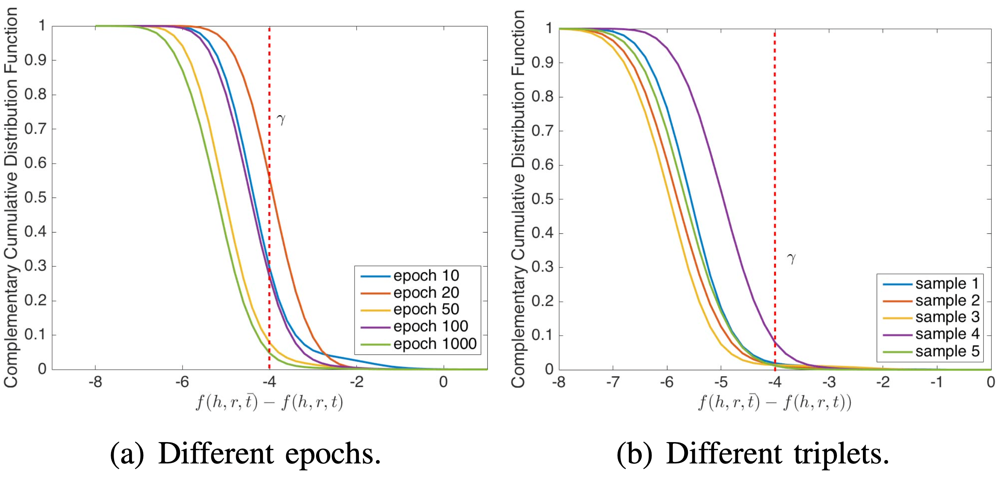
图1. 负样本的分数分布举例
图1(a)中展示了某一个三元组在训练过程中,负样本分布的变化;图1(b)中展示了在训练完成后,不同三元组的负样本分布情况。最终得出的结论是,负样本分数的分布是高度偏斜的,并且只有很少一部分的负样本有较大的分数。是否可以设计一个模型直接监控那些分数较高的负样本。这篇文章提出了NSCaching的方法,该方法只要解决了以下两个问题:
1、如何建模负样本的动态分布?
模型设计了一个缓存机制,保存了知识图谱中每个三元组对应的分数较高的负样本三元组,Algorithm2中展示了基于该缓存机制的知识图谱表示学习模型的学习过程。

对于步骤8,这里采用重要性采样(Importance Sampling,IS)。首先从所有的三元组中均匀采样一部分实体,然后把这部分实体和原本缓存的实体放在一起,并计算分数,利用如下公式计算每个负样本三元组的重要性,也就是被采样进入更新后的缓存的概率。
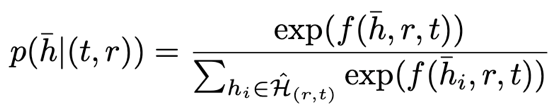
完整的缓存更新算法如下:

Experiments
作者在多个标准数据集上进行了实验,如下图是在利用TransE,在不同标准数据集上,和其他负采样方法对比的结果(更多利用其余KGE的实验结果请参考原文),可以看出这里提出的NSCacheing优于其他的负采样方法。
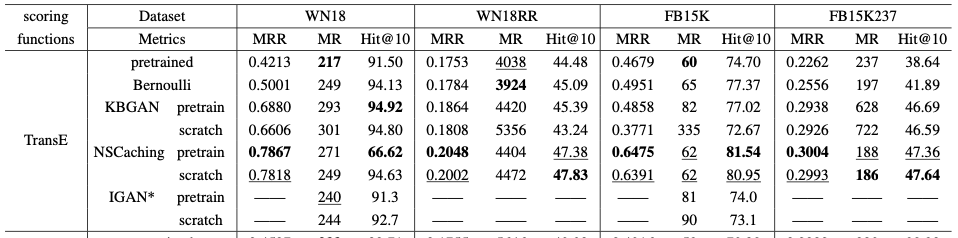
图2. 在不同标准数据集上的结果
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


