SFFAI 16 报名通知 | 视频生成

关注文章公众号
回复"视频生成"获取本主题精选论文

论坛主题
视频生成
论坛讲者

黄怀波,中国科学院自动化研究所在读博士,本科和硕士分别毕业于西安交通大学和北京航空航天大学,目前主要研究兴趣在生成模型的改进和应用。在ICCV,NIPS和AAAI等顶级会议发表多篇论文。
题目:高分辨率真实视频生成研究
摘要:图像和视频等视觉数据的生成在很多领域有着广泛的应用。近年来随着生成对抗网络等生成模型的提出和发展,图像生成领域取得了突飞猛进的发展。由于视频数据比图像维度更高,结构更复杂,视频数据的生成目前仍然是机器学习和计算机视觉领域的重要研究问题和前沿方向。和图像生成类似,视频生成可以分成无条件生成和条件生成两类。本次报告将会对视频生成的研究现状进行简要的介绍,并对视频生成中的难点和可能的解决方法展开讨论。
Spotlight:
1、视频生成研究进展概述;
2、视频生成中的难点和可能的解决方法讨论。

杨凌波,北京大学数字媒体研究所博士生,本科毕业于北大数学系数学与应用数学专业。目前主要研究方向为骨架引导下的人物图像/视频生成。
题目:“多姿多彩”的人物动作视频生成
摘要:合成特定姿态下的人物图像,并进一步让人物动起来,做出逼真,连贯的动作,是多媒体领域颇具趣味的研究方向。近年来,图像生成及图像翻译领域快速发展,为人物动作视频合成问题提供了有效的实现路径。目前学界基本形成利用骨架+纹理特征合成视频帧的研究范式,并在若干方向上取得了显著突破。本次讲座将带大家一同回顾人物动作视频的发展历程,解读若干最新的重要成果,并同大家共同探讨未来的发展趋势。
Spotlight:
1、视频合成领域研究思路简析;
2、视频合成目前面临哪些困难;
3、(待定)简要介绍本人ICME投稿工作。

图像和视频等视觉数据的生成是机器学习和计算机视觉领域的重要研究问题。近几年随着生成对抗网络的提出和发展,人们已经可以通过深度生成模型合成真实、多样化的清晰图像。作为一种结构更加复杂,应用也更广的数据类型,视频的生成即将成为人工智能领域的下一个热点问题。
由SFFAI16分享嘉宾杨凌波同学和黄怀波同学精选出来的7篇有关视频生成的论文,将使你全面了解视频生成的历史和最新进展。你可以先仔细阅读,并带着问题来现场交流哦。
1
🌟🌟🌟🌟🌟

Everybody Dance Now
Demo(https://www.youtube.com/watch?v=PCBTZh41Ris)
Implementation(https://github.com/Lotayou/everybody_dance_now_pytorch)
推荐理由:Berkeley AI Lab在Siggraph2018上发表的最新工作,代表了目前单个人物视频生成的最高水平。该文章在Nvidia pix2pixHD图像生成工作的基础上,引入了骨架尺寸归一化,时域连续性约束,人脸残差增强后处理三个模块,并通过大量人物真实动作视频加以训练,使机器自主学习人物骨架姿态到视频帧的对应关系,合成清晰自然的人物舞蹈视频(见demo)。
该文章提出的方法基本代表了目前视频生成领域的主流。
推荐理由来自:杨凌波
2
🌟🌟🌟🌟🌟

Deformable GANs for Pose-based Human Image Generation
Implementation(https://github.com/AliaksandrSiarohin/pose-gan)
推荐理由:虽说是合成单帧图像的工作,但这篇文章的生成网络结构相当新颖,是文章一大亮点,对视频合成问题中特征估计的思路也有借鉴。该文章考虑给定单张人物图像和新的骨架,生成新姿态下同一人物图像的问题。要如何把给定图像中人物各部分的纹理“粘贴”到新的骨架上呢?这就要用到作者提出的“变形跳层连接(deformable skip connection)”了。
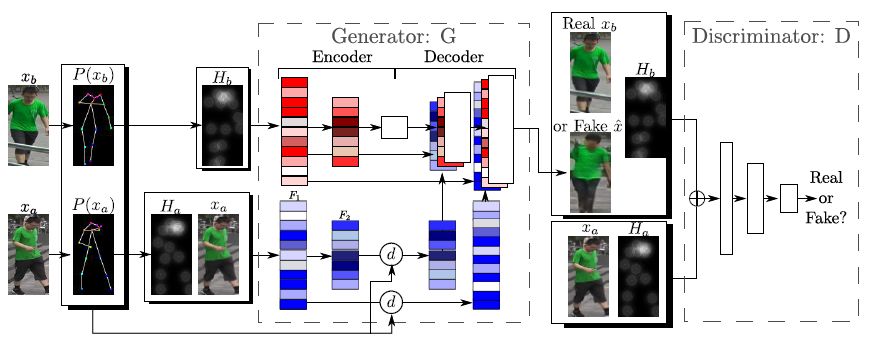
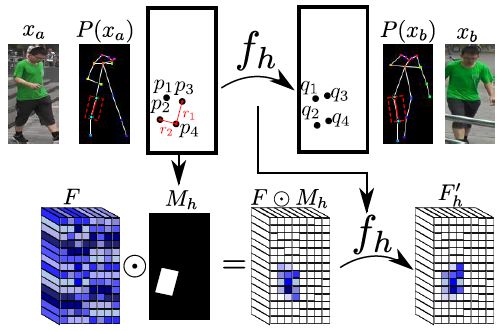
相比传统的跳层连接,作者提出的跳层连接可以在不同的位置间共享局部纹理信息,从而可以合成局部非常逼真的纹理细节(比如右图中女子上衣的花纹)。

推荐理由来自:杨凌波
3
🌟🌟🌟🌟

Pose-guided-person-image-generation
Implementation
(https://github.com/charliememory/Pose-Guided-Person-Image-Generation)
推荐理由:本领域的开山之作,首次提出了“骨架引导的人物图像生成”这一问题。作为当时还很困难的一个视觉任务,作者采用了两段式的生成策略,先预估一个大体轮廓,再合成精细的残差图去改善结果。虽然最后生成的图像分辨率不算很高,结果也比不过当今最好的Deformable-GAN,但作为一篇开创性的工作,这篇论文采用的许多设计思路都在之后的改进文章中有所体现,值得抱着考古的心态读一读一读。
推荐理由来自:杨凌波
4
🌟🌟🌟🌟

Video-to-video synthesis
Project Page (https://tcwang0509.github.io/vid2vid/)
推荐理由:Nvidia出品,必属精品。这篇video-to-video synthesis基本上涵盖了做视频生成领域的所有应用场景:从分割标签图到高清街景视频,从边缘图到电话会议视频,从骨架姿态到跳舞视频,甚至视频预测,语义属性编辑,而且效果都非常惊艳……sigh,有显卡真的是可以为所欲为啊!在增强时域一致性方面,英伟达采用了前后帧借助光流融合的策略,将前一帧合成的结果通过光流信息融合至下一帧,结合单帧生成器共同合成当前帧,显著提升了视频的时域连贯性。这篇文章和我们的讲座主题联系并不大,但是生成的人物跳舞视频效果确实很棒,大家有兴趣可以走马观花读一下吧。
推荐理由来自:杨凌波
5
🌟🌟🌟🌟

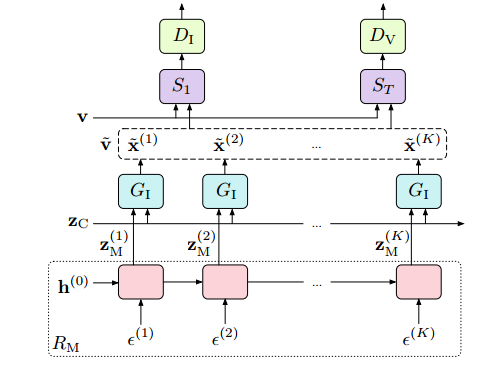
MoCoGAN: Decomposing Motion and Content for Video Generation (CVPR18)
Code: https://github.com/sergeytulyakov/mocogan
推荐理由:英伟达公司在CVPR2018提出的一种经典的无条件视频生成模型,可以从噪声通过生成器合成一段视频。相比之前的视频生成模型(比如VGAN和TGAN), 该文章将视频的输入隐码分成两部分,控制视频内容的Content Code 和控制动作的Motion Code,其中Motion Code 通过一个RNN网络来建模时序信息。对抗部分采用了两个判别器,一个用于判断每一帧图像的真实性,一个用于判断整段视频的真实性。
该方法比较直观,是基于GAN的无条件视频生成的一种经典范式。
推荐理由来自:黄怀波
6
🌟🌟🌟🌟

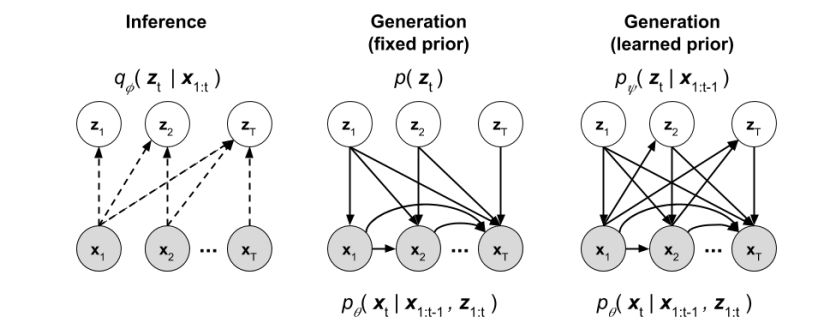
Stochastic Video Generation with a Learned Prior (ICML18)
推荐理由:这篇文章发表在ICML2018, 是使用VAE来进行视频预测的工作。和直接由噪声生成视频的无条件生成模型不同,视频预测是根据已有的若干帧图像预测未来帧的条件生成模型。使用VAE来进行视频预测可以增加预测的不确定性。本文提出了两种视频预测模型,一种对隐码使用固定的先验分布来进行拟合,另外一种使用了可以学习的先验分布。
视频预测任务也是一种常见的视频生成任务。
推荐理由来自:黄怀波
7
🌟🌟🌟🌟

Probabilistic Video Generation using Holistic Attribute Control (ECCV18)
推荐理由:这是发表在ECCV2018上,条件VAE(CVAE)模型在视频生成上的应用。和MoCoGAN类似,这篇文章也认为视频可以分解成两部分,一部分是时序无关的信息(相当于MoCoGAN的Content code),一部分是和时序相关的动态信息(相当于MoCoGAN的Motion code)。其中时序无关信息满足由单帧图像和属性共同编码的先验分布,时序相关信息利用LSTM进行编码。测试的时候通过改变条件信息可以控制合成视频的属性。
这篇文章提出了一种基于变分自编码器的条件视频生成模型。
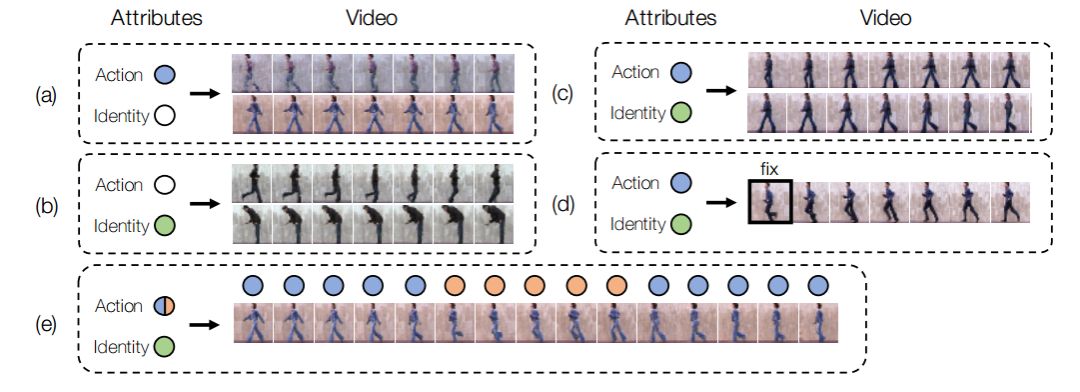
推荐理由来自:黄怀波

时间:
2019年1月6日(周日)
14:00 -- 17:00
地点:
中国科学院自动化研究所
报名方式
点击下方原文链接 或 扫描二维码报名

活动名额
1、为确保小范围深入交流,本次活动名额有限(不收取任何费用);
2、活动采取审核制报名,我们将根据用户研究方向与当期主题的契合度进行筛选,通过审核的用户将收到确认邮件;
3、 如您无法按时到场参与活动,请于活动开始前 24 小时在AIDL微信公众号后台留言告知,留言格式为放弃报名 + 报名电话。无故缺席者,将不再享有后续活动的报名资格。
SFFAI招募
现代科学技术高度社会化,在科学理论与技术方法上更加趋向综合与统一,为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!



