【学界】Facebook AI实验室何恺明等人提出视频识别SlowFast网络
选自 arxiv
作者:Christoph Feichtenhofer、Haoqi Fan、Jitendra Malik、Kaiming He
来源:机器之心
在本文中,FAIR 何恺明等人介绍了用于视频识别的 SlowFast 网络,提出要分开处理空间结构和时间事件。该模型在视频动作分类及检测方面性能强大:在没有使用任何预训练的情况下,在 Kinetics 数据集上实现了当前最佳水平;在 AVA 动作检测数据集上也实现了 28.3 mAP 的当前最佳水准。
在图像识别中对称地处理图像 I(x, y) 中的空间维度 x、y 是约定俗成的做法,自然图像的统计数据证明了其合理性。自然图像在第一次近似时具备各向同性(所有方向具有相同的可能性)和平移不变性 [38, 23]。那么视频信号 I(x, y, t) 呢?动作是方向的时空对应 [1],但并非所有的时空方向都拥有相同的可能性。慢动作比快动作的可能性大(确实,我们所看到的世界在给定的时刻大多是静止的),这已经在使用贝叶斯模型描述人类如何感知运动刺激中得到利用 [51]。例如,如果我们看到一个孤立的移动边缘,我们认为它垂直于自身移动,尽管原则上它也可能有一个与自身相切的任意移动组件(光流中的孔径问题)。如果前者倾向于慢动作,这种感知就是合理的。
如果并非所有的时空方向都拥有相同的可能性,那么我们就没有理由像基于时空卷积的视频识别方法 [44, 3] 那样,对称地看待空间和时间。相反,我们需要「分解」该架构,分开处理空间结构和时间事件。将这一想法放到识别的语境中。视觉内容的类别空间语义变化通常非常缓慢。例如,挥手并不会在这个动作进行期间改变「手」的识别结果,某个人始终在「人」这一类别下,即使他/她从走路切换到跑步。因此类别语义(及其色彩、纹理和光线等)的识别可以以比较慢的速度进行刷新。另一方面,执行动作可以比其主体识别变化速度快得多,如鼓掌、挥手、摇头、走路或跳跃。需要使用快速刷新帧(高时间分辨率)来有效建模可能快速变化的运动。
基于这种直觉,本研究展示了一种用于视频识别的双路径 SlowFast 模型(见图 1)。其中一个路径旨在捕获图像或几个稀疏帧提供的语义信息,它以低帧率运行,刷新速度缓慢。而另一个路径用于捕获快速变化的动作,它的刷新速度快、时间分辨率高。尽管如此,该路径的体量却非常轻,例如,只占总计算开销的 20% 左右。这是因为第二个路径通道较少,处理空间信息的能力较差,但这些信息可以由第一个路径以一种不那么冗余的方式来提供。根据二者不同的时间速度,研究者将其分别命名为 Slow 路径和 Fast 路径。二者通过侧连接(lateral connection)进行融合。
这一概念为视频模型带来了灵活、高效的设计。由于自身较轻,Fast 路径不需要执行任何时间池化——它能以高帧率在所有中间层运行,并保持时间保真度。同时,由于时间速率较低,Slow 路径可以更加关注空间域和语义。通过以不同的时间速率处理原始视频,该方法允许两种路径以其特有的方式对视频建模。研究者在 Kinetics [27, 2] 和 AVA [17] 数据集上对该方法进行了全面评估。在 Kinetics 动作分类数据集上,该方法在没有任何预训练(如 ImageNet)的情况下达到了 79% 的准确率,大大超过了文献中的最佳水平(超出 5.1%)。控制变量实验证明了 SlowFast 概念带来的改进。在 AVA 动作检测数据集上,SlowFast 模型达到了新的当前最佳水平,即 28.3% mAP。
该方法部分受到灵长类视觉系统中视网膜神经节细胞的生物学研究启发 [24, 34, 6, 11, 46],尽管这种类比有些粗糙、不成熟。研究发现,在这些细胞中,~80% 是小细胞(P-cell),~15-20% 是大细胞(M-cell)。M-cell 以较高的时间频率工作,对时间变化更加敏感,但对空间细节和颜色不敏感。P-cell 提供良好的空间细节和颜色,但时间分辨率较低。SlowFast 框架与此类似:i)该模型有两条路径,分别以低时间分辨率和高时间分辨率工作;ii)Fast 路径用来捕捉快速变化的运动,但空间细节较少,类似于 M-cell;iii)Fast 路径很轻,类似于较小比例的 M-cell。研究者希望这些关系能够启发更多用于视频识别的计算机视觉模型。
论文:SlowFast Networks for Video Recognition

论文链接:https://arxiv.org/pdf/1812.03982.pdf
摘要:本文提出了用于视频识别的 SlowFast 网络。该模型包含:1)一个以低帧率运行、用来捕捉空间语义的 Slow 路径;2)一个以高帧率运行、以较好的时间分辨率来捕捉运动的 Fast 路径。我们可以减少 Fast 路径的通道容量,使其变得非常轻,但依然可以学习有用的时间信息用于视频识别。我们的模型在视频动作分类及检测方面性能强大,而且我们的 SlowFast 概念实现的巨大改进是对这一领域的重要贡献。我们在没有使用任何预训练的情况下在 Kinetics 数据集上实现了 79.0% 的准确率,远远超过此类问题的之前最佳水平。在 AVA 动作检测数据集上,我们实现了 28.3 mAP 的当前最佳水准。代码将会公开。
SlowFast 网络
这一通用架构包含一个 Slow 路径、一个 Fast 路径,二者由侧连接联系起来。详见图 1。
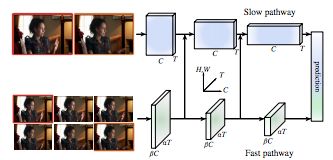
图 1:SlowFast 网络包括低帧率、低时间分辨率的 Slow 路径和高帧率、高时间分辨率(Slow 路径时间分辨率的 α 倍)的 Fast 路径。使用通道数的一部分(β,如 β = 1/8)来轻量化 Fast 路径。Slow 路径和 Fast 路径通过侧连接来连接。该样本来自 AVA 数据集 [17](样本标注是:hand wave)。
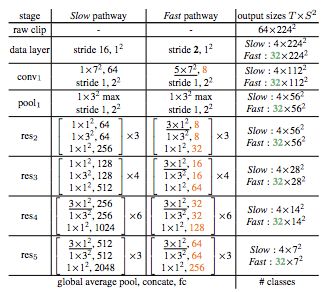
表 1:SlowFast 网络的实例化示例。内核的维度由 {T×S^2 , C} 表示,T 表示时间分辨率、S 表示空间语义、C 表示通道数。步长由 {temporal stride, spatial stride^2} 表示。此处 速度比例是α = 8,通道比例是 β = 1/8。τ = 16。绿色表示 Fast 路径较高的时间分辨率,橙色表示 Fast 路径较少的通道数。下划线为非退化时间滤波器(non-degenerate temporal filter)。方括号内是残差块。骨干网络是 ResNet-50。
实验:Kinetics 动作分类
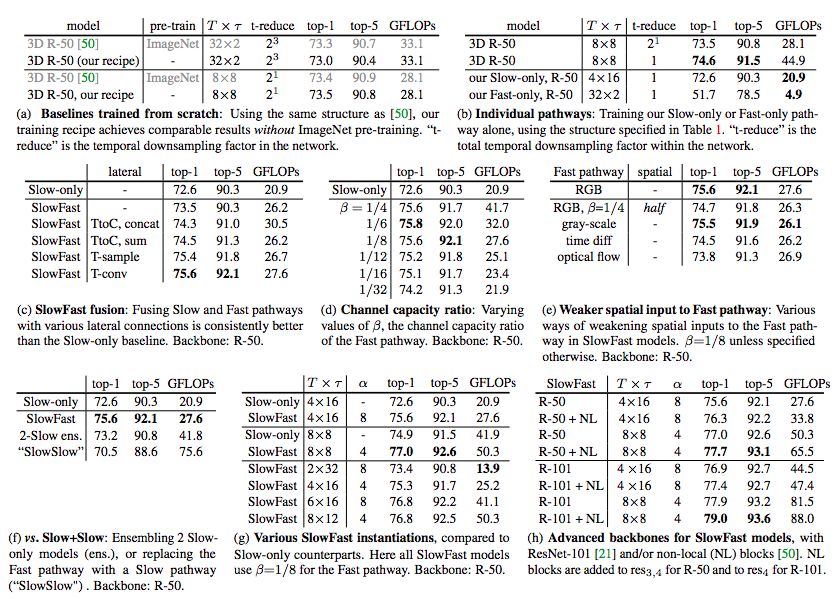
表 2:在 Kinetics-400 动作分类任务上进行的控制变量实验。上表展示了 top-1 和 top-5 分类准确率 (%),以及空间大小为 2242 的单 clip 输入的计算复杂度(单位为 GFLOPs)。
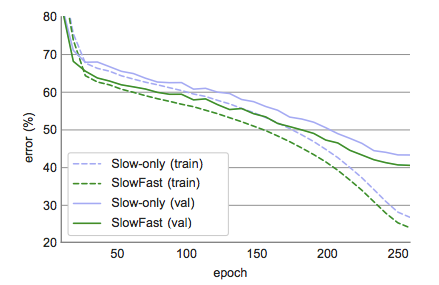
图 2:Slow-only(蓝色)vs. SlowFast(绿色)网络在 Kinetics 数据集上的训练过程。上图展示了 top-1 训练误差(虚线)和验证误差(实线)。这些曲线均为 single-crop 误差,视频准确率为 72.6% vs. 75.6%(见表 2c)。
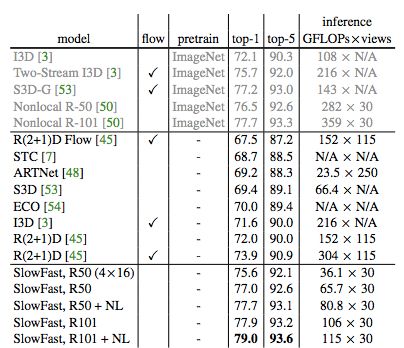
表 3:SlowFast 网络与当前最优模型在 Kinetics-400 数据集上的对比结果。
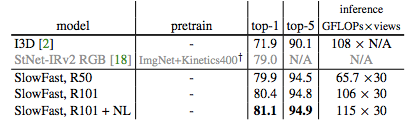
表 4:SlowFast 网络与当前最优模型在 Kinetics-600 数据集上的对比结果。
实验:AVA 动作检测
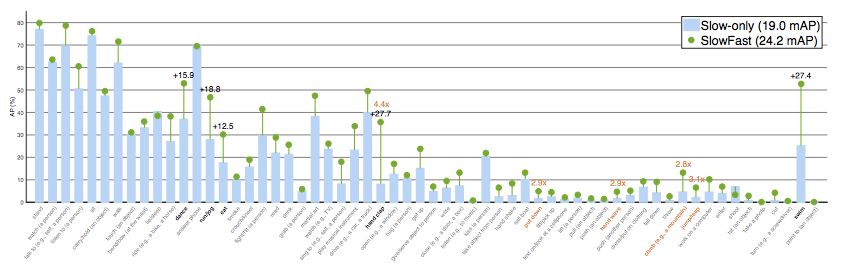
图 3:在 AVA 数据集上的 Per-category AP:Slow-only 基线模型 (19.0 mAP) vs. 对应的 SlowFast 网络 (24.2 mAP)。黑色加粗类别是净增长最高的 5 个类别,橙色类别是和 Slow-only AP > 1.0 对比相对增长最高的 5 个类别。类别按照样本数来排序。注意,该控制变量实验中的 SlowFast 实例并非我们的性能最优模型。
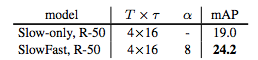
表 5:AVA 动作检测基线:Slow-only vs. SlowFast。
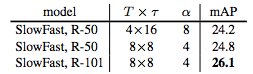
表 6:SlowFast 模型在 AVA 数据集上的更多实例。
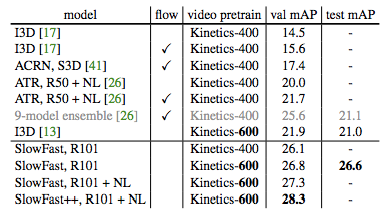
表 7:SlowFast 与当前最优模型在 AVA 数据集上的对比。++ 表示使用多尺度和水平翻转增强进行测试的 SlowFast 网络版本。

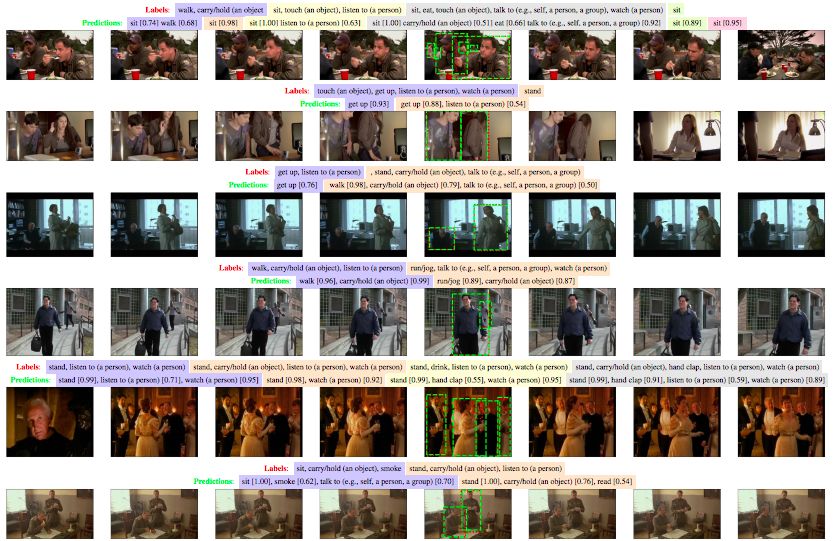
图 4:SlowFast 网络在 AVA 数据集上表现的可视化结果。SlowFast 网络在 AVA 验证集上的预测结果(绿色,置信度 > 0.5)vs. 真值标签(红色)。此处仅展示了中间帧的预测/标签。上图展示的是 T ×τ = 8×8 的 SlowFast 模型,获得了 26.8 mAP。

☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy

