升级版StarGAN来袭!你想要的多目标域多风格图像变换它都有

作者丨武广
学校丨合肥工业大学硕士生
研究方向丨图像生成
论文引入



设计了 Mapping Network 用于生成风格编码,摆脱了标签的束缚;
用风格编码器指导 Mapping Network 进行目标风格学习,可以实现目标域下多风格图像的转换;
公开了动物面部数据集 AFQH,实现了图像翻译下较好的结果。
模型结构
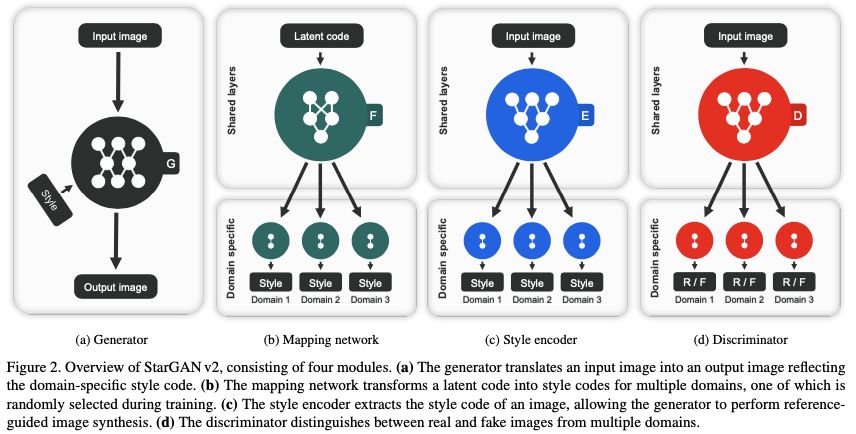
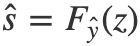 ,其中
,其中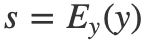 ,得到了风格编码 。这样生成出的图像就是指定的风格了,这里可以理解为风格编码器在测试阶段就是一个在线标签生成器,用来指定生成器要按照什么风格进行转换。
,得到了风格编码 。这样生成出的图像就是指定的风格了,这里可以理解为风格编码器在测试阶段就是一个在线标签生成器,用来指定生成器要按照什么风格进行转换。
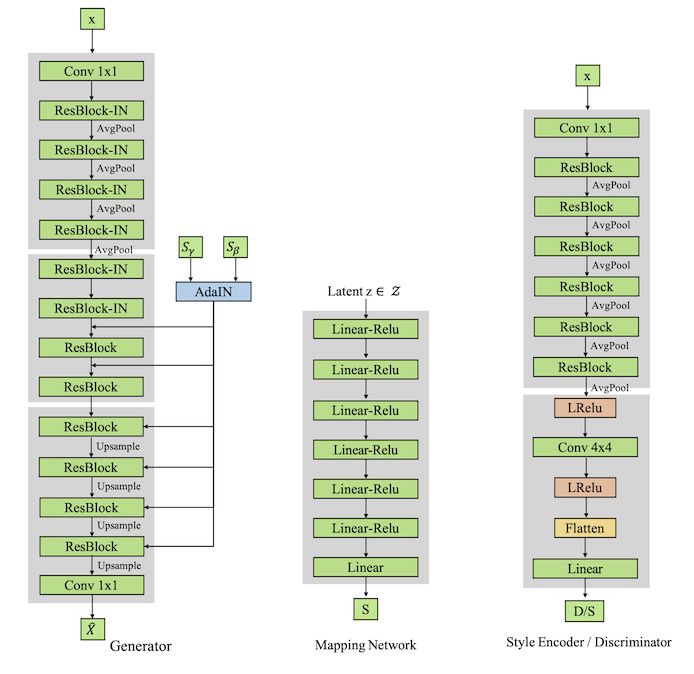
▲ 图3. StarGAN v2模型设计结构
损失函数
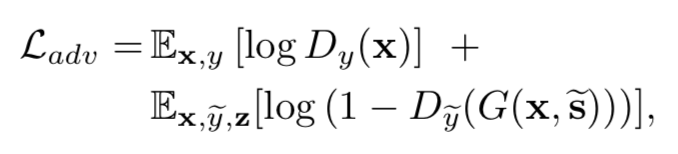
这里提一下,虽然公式前半部分写的是 x,但是在训练阶段肯定是参照的是目标域图像作为真实的,当然,可以设计双向网络,也就是源域和目标域可以实现相互转换。
为了优化映射网络,设计了风格重构损失:
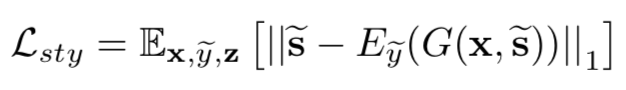
为了让映射网络可以学习到更多的目标域下的不同风格,也就是让风格更加的多样化,设计了距离度量损失,也就是希望每次得到的风格表示尽量的不一致,这样风格就会更加丰富,所以是最大化:
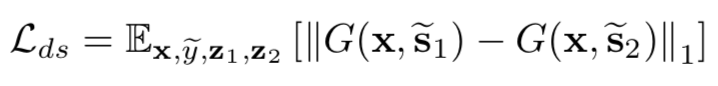
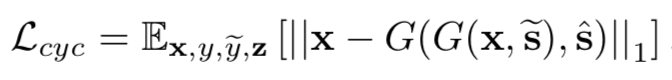
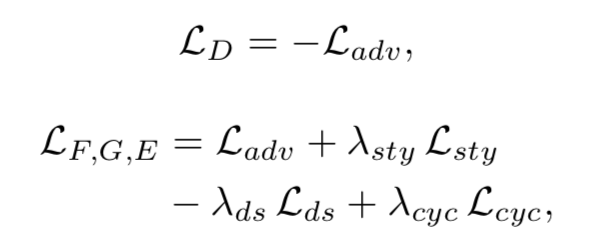
实验

在有参照的测试结果也同样展示了优越的结果。

▲ 图5. StarGAN v2在有参照图像下定性实验结果
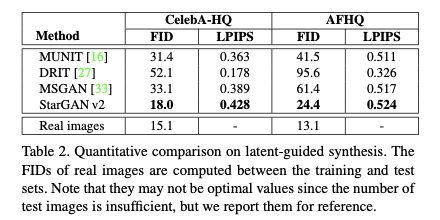
▲ 图6. StarGAN v2定量实验结果
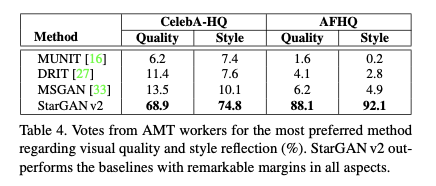
▲ 图7. StarGAN v2人力评估下实验结果
总结
参考文献
[1] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multidomain image-to-image translation. In CVPR, 2018. 2, 3, 4
[2] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[3] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz. Multimodal unsupervised image-to-image translation. In ECCV, 2018. 2, 3, 4, 6, 7, 8, 12
[4] H.-Y. Lee, H.-Y. Tseng, J.-B. Huang, M. K. Singh, and M.-H. Yang. Diverse image-to-image translation via disentangled representations. In ECCV, 2018. 2, 3, 4, 6, 7, 8
[5] Q. Mao, H.-Y. Lee, H.-Y. Tseng, S. Ma, and M.-H. Yang. Mode seeking generative adversarial networks for diverse image synthesis. In CVPR, 2019. 2, 3, 4, 6, 7, 8
[6] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018. 4, 9

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码


