阿里广告技术最新突破:全链路联动-面向最终目标的全链路一致性建模
©作者 | 王哲
单位 | 阿里妈妈展示广告算法专家
研究方向 | 广告/推荐/深度学习/NLP

引言

背景及现状

问题和挑战
-
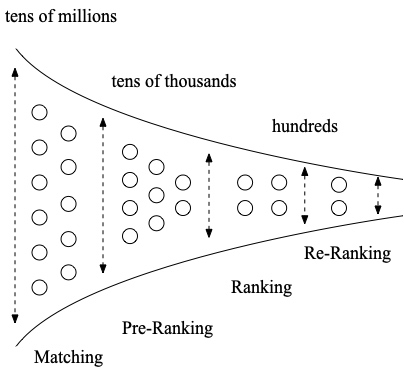
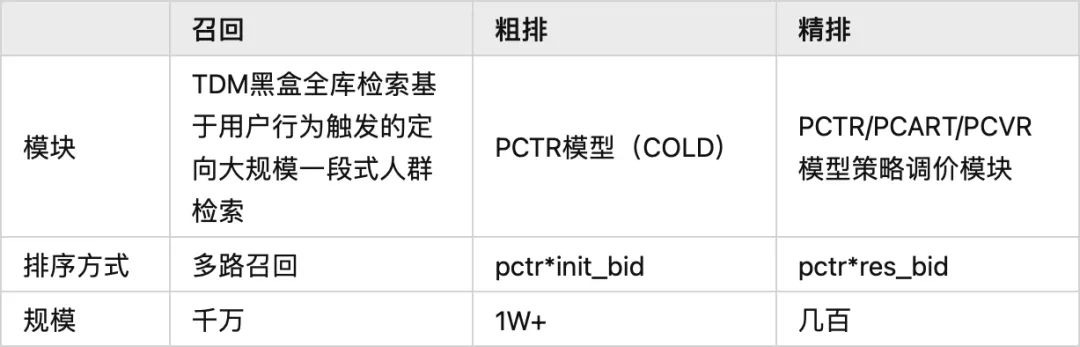
召回:很多召回通道都是先兴趣最大化再 RPM 最大化,和系统平台侧的主要目标 RPM 存在 gap,有可能会导致一些中低兴趣但是高 RPM 的广告无法进入到后链路。 粗排:按照 ecpm=pctr*init_bid 的方式进行排序,粗排使用的是广告主的原始 bid,但是精排会基于多目标模型打分(点击率/收藏加购率/成交率模型)以及策略调价模块(基于广告主和平台诉求对广告出价进行调整)对广告主出价进行调整,因为在 bid 上和精排存在 gap,同时粗排在 pctr 模型能力上和精排也存在差距。

技术方案概述
-
前链路的目标是选择满足后链路需要的集合。是否可以放弃对值的精准预估,以集合选择为目标,从而释放一部分算力? 精排阶段的排序结果,是通过用户反馈数据->模型训练->多目标模型打分->策略调价这样一条复杂路径处理之后得到的。是否可以跳过精排内部复杂的处理过程,以排序结果本身为学习样本和目标,直接进行端到端的学习?这种精排加工处理后的数据,和用户反馈数据相比,学习难度可能更低。
提升前链路模块和精排模型在自身打分空间上的打分一致性。
解决精排的样本选择偏差问题。

精准值预估技术
5.1 面向任意目标的全库向量召回技术PDM
-
直接目标:如 CTR。这类目标一般可以直接基于线上的 feedback 反馈数据用全库召回的模型进行预估。例如对 CTR 来说,因为仅仅需要保证点击样本排到未点击样本前面,甚至不需要保证模型的 PCTR 预估准度,在构造样本的时候一般可以用点击样本作为正样本,随机采样作为负样本。 间接目标:如 RPM(RPM=CTR*Bid),GMV(GMV=CTCVR*Price)等。这类目标的排序公式,往往存在一个或多个加权因子,难以直接用线上的反馈数据(点击,转化等)表示。这个给召回建模带来了很大的困难。
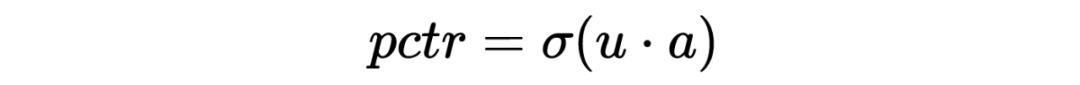

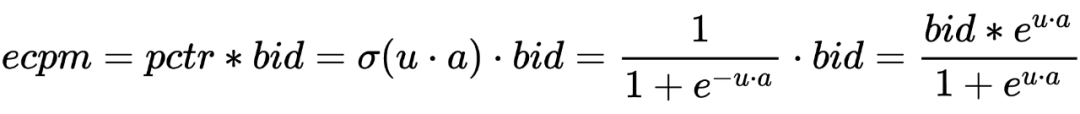
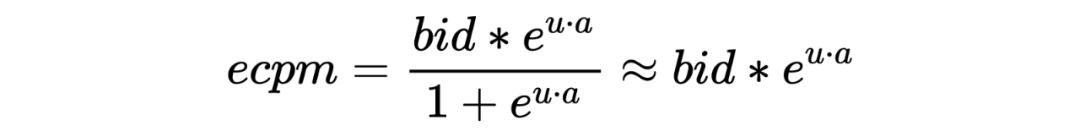
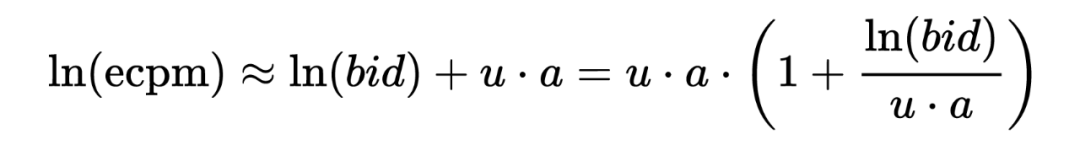
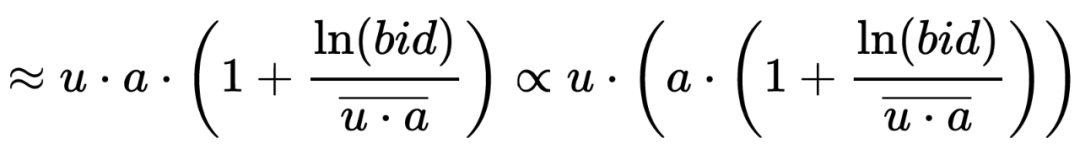
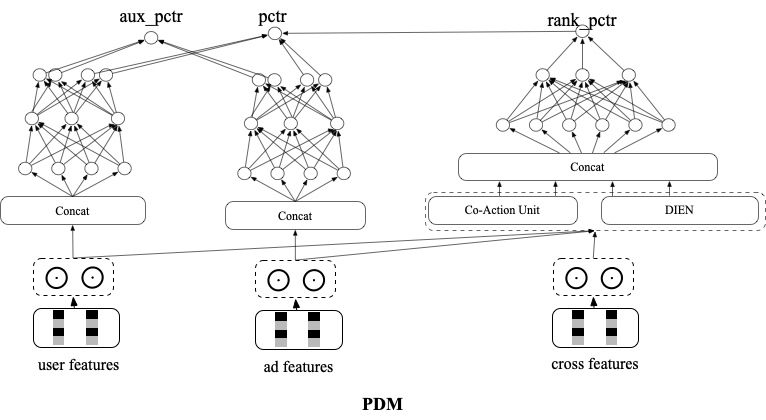
-
向量模型和精排模型联合训练:向量模型和精排模型共享部分 embedding,同时向量模型仅在展现样本上以交叉熵loss进行训练,精排模型也仅在展现样本上以交叉熵 loss 进行训练。 -
batch 内随机负采样:为了提升模型对简单样本的区分能力,缓解 SSB 问题,这里引入随机负样本。为了减少实现成本,这里给每条点击正样本在 batch 内随机选 k 个 ad 向量,和这条正样本的 user 向量拼在一起组成随机负样本。为了避免随机负样本影响 pctr 预估精度,这里在原有双塔网络基础上额外构建了一个双塔网络,新双塔网络和原双塔网络的前几层参数共享,输出为 aux_pctr。auc_pctr 会会引入随机负样本以交叉熵 loss 参与训练。 unpv 样本上的 distill:这里将精排未展现样本以 distill 方式用精排 rankpctr 对向量模型训练进行指导,通过这种方式来提升召回模型和精排模型在召回空间上的打分一致性,从而缓解召回阶段的 SSB 问题,同时训练过程中要通过 stop_gradient 的方式来屏蔽蒸馏 loss 对精排训练的影响:
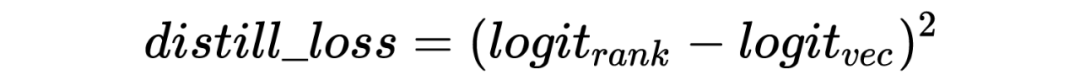
-
将 pctr 和 bid 进行了解耦,当广告主的 bid 发生变化以后,可以在不重新训练模型,不重新产出向量的基础上,通过对原广告向量进行实时 bid 加权,来生成新的广告向量,实现对广告主调价的分钟级响应。提升了召回阶段对广告主 bid 的敏感性。 -
可以实现策略的实时调控,通过调节 bid 权重来对 CTR 和 RPM 进行平衡,可控性强。 可以显式地对齐后链路的各种间接目标,可解释性强。
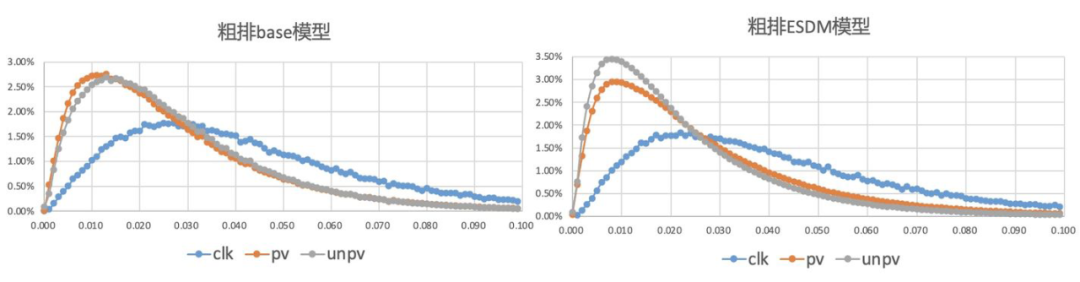
5.2 全空间粗排ESDM模型
-
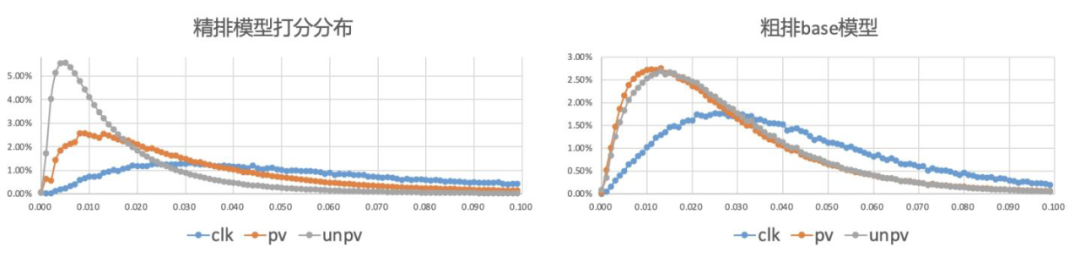
粗排模型和精排模型在粗排打分空间上的分布一致性问题。 精排的样本选择偏差问题。
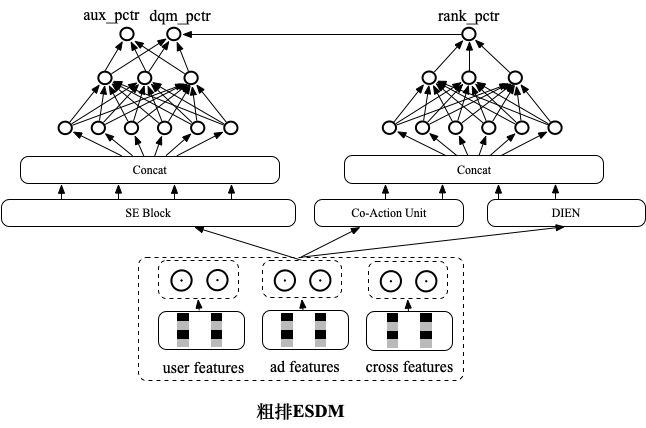
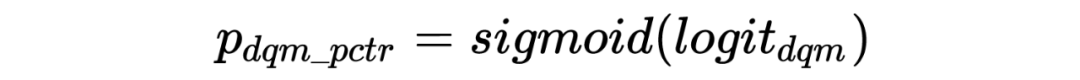
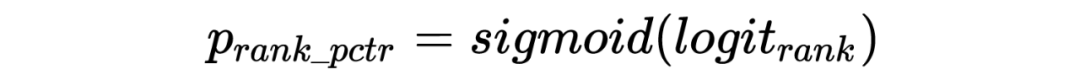
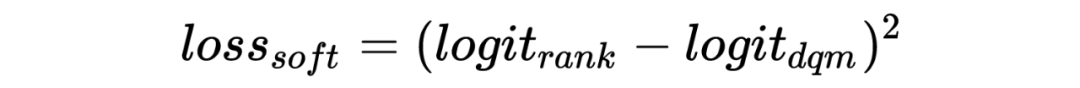
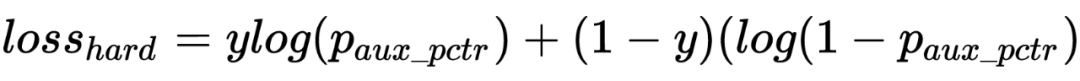
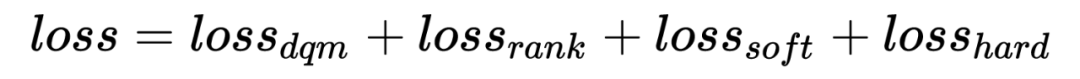

集合选择技术
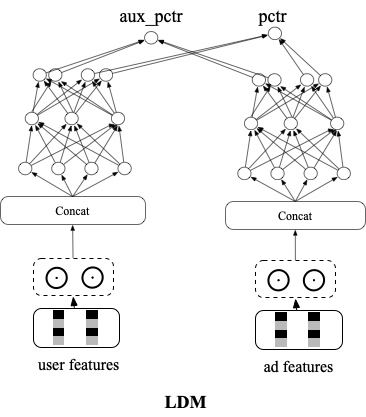
6.1 以学习后链路的序为目标的端到端召回技术LDM
-
通过端到端 LTR 的方式隐式地学习了后链路多目标打分和调价模型的信息,兼顾了平台,广告主及用户诉求。 后链路升级后,通过精排参竞日志样本回流即可实现自行升级,维护成本较低。
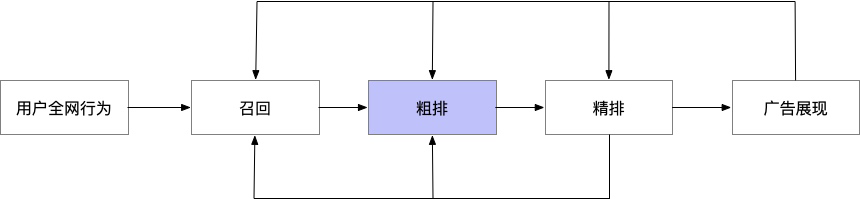
6.2 以学习后链路的序为目标的端到端粗排LBDM模型
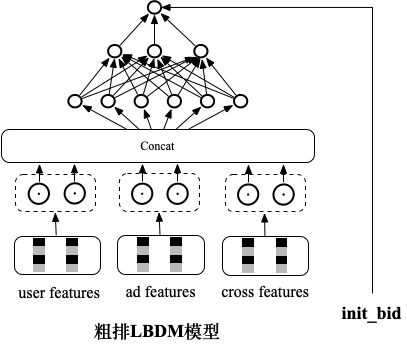

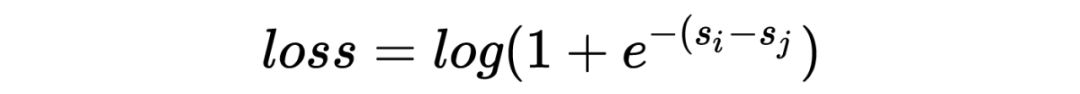
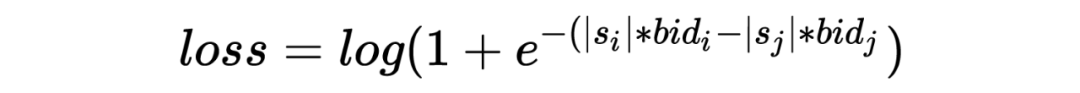
-
通过端到端建模技术,减少了精排阶段内部多个模块的误差传递问题 -
放弃了对值准度的要求,降低了学习难度,样本利用率更高,与粗排集合选择的目标也更为贴近。 -
基本不增加算力和 RT。 通过实时样本回流的方式,自动跟随后链路进行升级,极大的降低了维护迭代成本。

利用-探索(Exploit&Explore) 全链路通道
专注于最终系统目标对齐和优化。
以集合选择技术为主。
专注于客户侧指标优化,如新广告冷启。
以精度值预估技术为主。

业务效果
面向任意目标的全库向量召回技术 PDM:CTR+1.5% , RPM+2%
粗排全空间 ESDM 模型:CTR+3% , RPM+1.5%
-
以学习后链路的序为目标的端到端召回技术 LDM:CTR+3% , RPM+4% 以学习后链路的序为目标的端到端粗排 LBDM 模型:CTR+8% , RPM+5%




