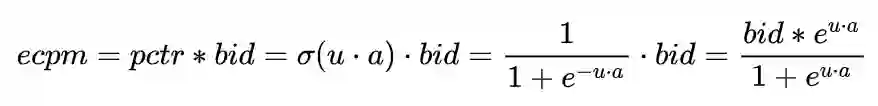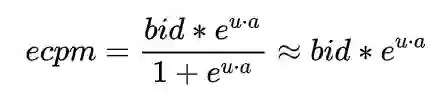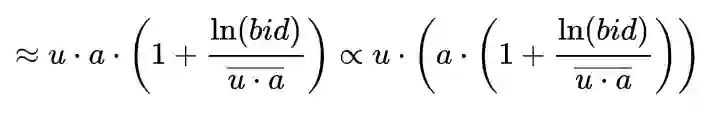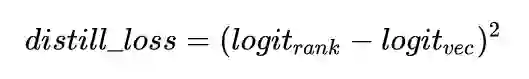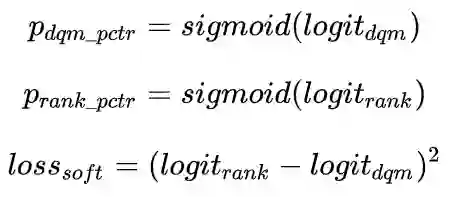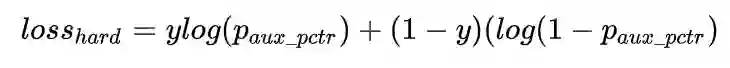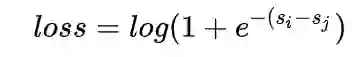| 作者:王哲
| 链接:https://zhuanlan.zhihu.com/p/413240790
深度学习时代的到来给搜推广业务带来了一波巨大的红利,一方面是深度学习模型带来的技术红利,另一方面是GPU/NPU等硬件带来的算力红利。但是随着业务的不断发展,技术水位的不断提高,深度学习时代的技术和算力红利也渐渐耗尽,级联排序系统的召回/粗排/精排/重排等各模块的独立迭代也逐渐遇到瓶颈。后深度学习时代如何进一步破局,技术如何进一步突破,成为很多团队亟待解决的问题。
我在2019年将阿里妈妈展示广告的粗排排序系统从向量内积模型升级成
实时深度全连接模型COLD之后 ,也遇到了同样的问题,粗排和精排PCTR模型的差距已经很小,进一步的优化升级难以取得进一步的线上收益。
为了解决这个问题,我站在整个系统链路的角度,在考虑模块自身特点和算力约束的情况下,提出了全链路联动这一全新的技术方向,解决了各模块因为目标不一致带来的链路损耗和目标对齐问题,同时解决各模块因为训练和在线推理不一致带来的的样本选择偏差问题。目前这个工作已经在阿里妈妈展示广告主要业务落地全量,给阿里广告收入带来了10%以上的巨大增长。
2. 背景及现状
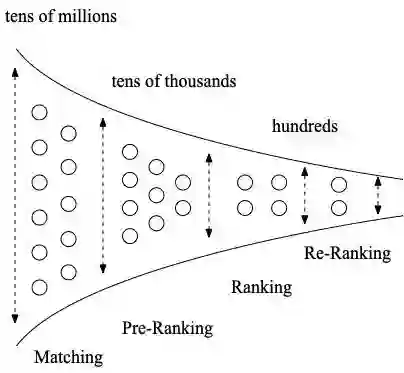
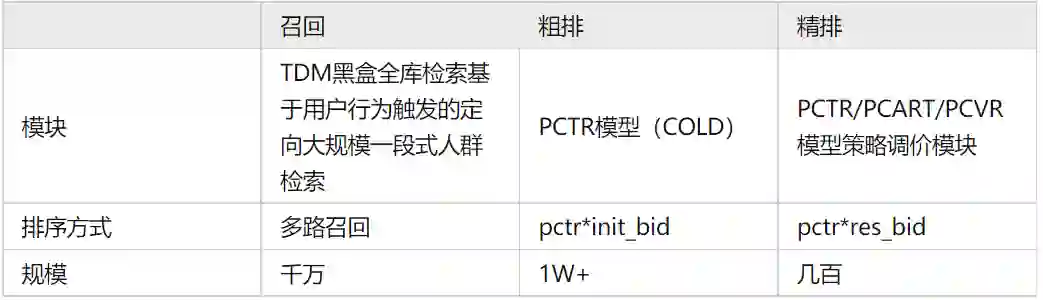
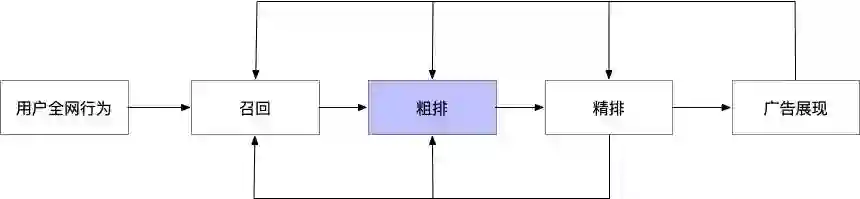
阿里妈妈展示广告采用多阶段级联排序架构,对于前链路系统(召回/粗排)来说,需要在满足算力RT约束的情况下,选出满足后链路需求的集合,各模块情况如下:
近些年,深度学习技术在搜索推荐广告等场景取得巨大成功。技术和算力上的红利极大的促进了业务的发展。但是随着存量红利逐渐消耗殆尽,很多模块的单点迭代和技术创新都逐渐进入深水区,逐渐遇到瓶颈。
3. 问题和挑战
我在2019年推动将阿里妈妈展示广告的粗排排序系统从向量内积模型升级成
实时深度全连接模型COLD ,在引入交叉特征的基础上可以进行实时训练,实时打分。此后因为粗排和精排PCTR模型能力差距得到显著缩小,粗排PCTR主模型在技术上的单点迭代升级开始遇到瓶颈。为了给粗排以及整个展示广告技术打开发展空间,我的目光从粗排转向整个级联排序系统,站在全链路的视角重新审视整个展示广告的技术,我发现因为打分规模/算力RT/独立迭代等因素影响,各模块存在技术水位差以及目标不一致带来的链路损耗问题:
同时整个级联排序系统还存在明显的样本选择偏差问题(SSB,Sample Selection Bias):因为模型训练基于的展现反馈样本空间和线上打分样本空间存在较大的分布差异,影响了模型的推理效果。越靠近前链路,这个问题就越严重。
4. 技术方案概述
解决技术水位差和目标不一致问题的一条传统技术路线,是将精排的精准值预估能力向前链路迁移。粗排的发展历史很好的诠释了这条路线:从LR等传统机器学习模型到向量内积模型,再到现在的实时全连接结构COLD,这些技术均先在精排落地,后面再结合粗排的算力RT特点进行迁移适配。
但是随着迭代进入深水区,这种方式的弊端也逐渐显现。一方面是因为精排内部逐渐复杂化(预估目标越来越多,模型越来越复杂,调价策略等逻辑也越来越多)。另一方面是越往前面临的打分规模也越大,特别是召回阶段打分规模在千万级别。将精排技术向前链路迁移面临的算力RT代价及维护成本越来越高,边际效应递减也越来越明显,导致很多精排技术难以直接落地。如果继续沿着这条技术路线迭代,是否存在新的破局空间?
沿着
精准值预估的技术路线 ,我在召回提出了新的可以
面向任意目标的全库向量召回技术PDM(Point based Deep Match Model) 。在粗排提出了解决粗排样本选择偏差问题的
粗排ESDM (Entire Space Domain Adaptation Model) 模型 。
除了精准值预估技术路线之外,是否存在另外一条算力RT代价较低,迁移成本可控的技术路线呢?
基于上面的特点,我提出了一条全新的以学习后链路为目标的集合选择技术路线,改变了全链路技术体系只依赖用户展示反馈数据的现状,将精排阶段的排序样本引入到前链路召回和粗排的模型学习过程中,在基本不增加算力RT的情况下提升了全链路的目标对齐能力。我在召回提出了通过端到端Learning to Rank的方式,以学习后链路的序为目标的
召回技术LDM(Learning to Rank based Deep Match Model) ,并在一定程度上解决了召回阶段的样本选择偏差问题。
召回LDM的成功证明了以精排阶段的序为目标,通过LTR技术端到端进行学习,在在展示广告业务是可行的,也给粗排的进一步迭代打开了思路。因此我进一步提出了通过端到端Learning to Rank方式,以学习后链路的序为目标的
粗排LBDM(Learning to Rank based and Bid-Sensitive Deep Pre-Ranking Model)模型 ,同时创新性地解决了LTR技术在bid敏感性上的问题,保证了广告主bid对排序的单调翘动能力。
对于
样本选择偏差(Sample Selection Bias,SSB) 问题,在缺乏监督信号的情况下想要完全解决是很难的。同时精排模型由于模型能力更强,对于未曝光样本的打分更准确。
对于样本选择偏差问题来说,
如何定义问题比解决问题更为重要 !
对于级联排序系统中的前链路模块来说(召回/粗排),样本选择偏差问题可以拆解成两个子问题:
这里先解决第一个子问题,即提升前链路模型和精排模型在模块自身打分空间上的一致性问题,这样可以在不动精排的情况下也能拿到线上收益。后面再集中精力攻克精排的样本选择偏差问题。
5 精准值预估技术
5.1 面向任意目标的全库向量召回技术PDM
召回阶段需要对齐的目标,按形式往往可以拆分成两种:
RPM是一个很典型的间接目标,也是展示广告在平台侧最重要的指标之一。如何在千万召回规模下,在满足算力RT约束的情况下,找到RPM最大的广告是一个业界技术难点。这里我突破了这个技术难点,提出了新的可以
面向任意目标的向量召回技术PDM(Point based Deep Match Model) ,不仅可以解决召回阶段的RPM最大化问题,也可以用于GMV等其他间接指标。
首先引入向量内积最大化检索技术。这里选择ALSH(Asymmetric LSH for Sublinear Time Maximum Inner Product Search)算法,因为该方法无需训练,并且效果更好。后面的技术难点就转化成了如何将eCPM(eCPM=PCTR*BID)表达成两个向量内积的形式,对于PCTR部分,训练了一个双塔结构的向量PCTR模型,对于bid部分使用广告主的原始bid,所以:
eCPM可以表示成:
sigmoid函数有一个特点,在值比较少的时候(一般是少于0.1的时候), 公式可以进一步近似成:
对两边同时取对数,可得:
为了进一步将公式表达成两个向量内积的形式,这里用ua的期望来代替ua:
经过转换,最终将eCPM表达成了两个向量内积的形式。后续通过向量内积最大化检索算法,即可以较低的算力和RT,在全库召回RPM最大的广告集合。这种技术不仅可以用于eCPM最大化召回,也可以用于任意目标,例如要实现GMV最大化召回,只需训练一个PCTCVR向量模型,并用价格进行加权,即可召回GMV最大的商品。
对于向量PCTR预估模型,实验发现直接使用曝光点击样本训练一个双塔结构的向量内积模型效果很差。因为曝光点击样本和召回面对的全库样本在分布上有很大的差异,即召回的样本选择偏差(SSB, Sample Selection Bias)问题。曝光点击样本属于较难分类的样本,模型能学会区分较难的样本,并不代表也能对简单样本进行很好的区分 。为了缓解模型在召回上的SSB问题,同时进一步提升和精排的对齐效果,这里做了如下技术改进:
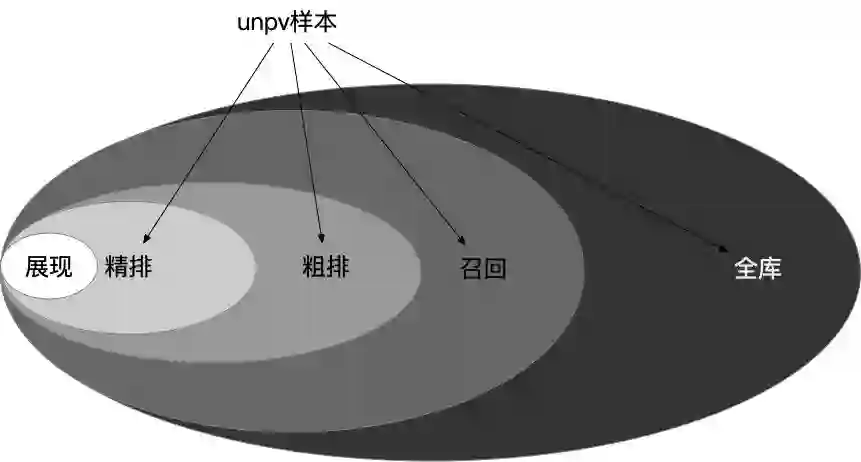
首先是样本层面,包含clk/pv/unpv样本,这里unpv样本指的是进入精排打分但是没有展现的样本。
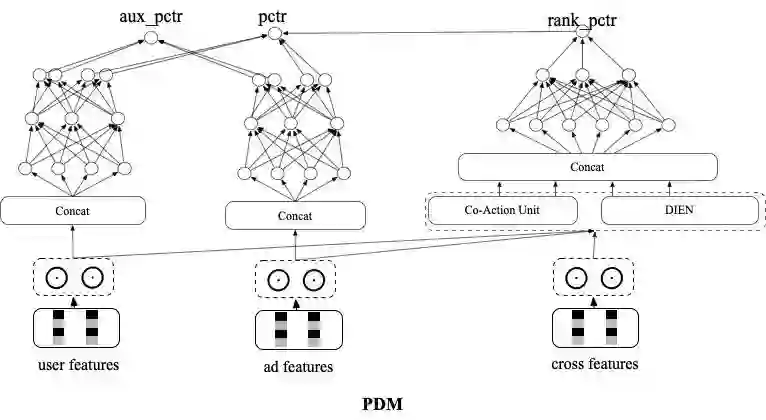
向量模型和精排模型联合训练:向量模型和精排模型共享部分embedding,同时向量模型仅在展现样本上以交叉熵loss进行训练,精排模型也仅在展现样本上以交叉熵loss进行训练。
batch内随机负采样:为了提升模型对简单样本的区分能力,缓解SSB问题,这里引入随机负样本。为了减少实现成本,这里给每条点击正样本在batch内随机选k个ad向量,和这条正样本的user向量拼在一起组成随机负样本。为了避免随机负样本影响pctr预估精度,这里在原有双塔网络基础上额外构建了一个双塔网络,新双塔网络和原双塔网络的前几层参数共享,输出为aux_pctr。auc_pctr会会引入随机负样本以交叉熵loss参与训练。
unpv样本上的distill:这里将精排未展现样本以distill方式用精排rankpctr对向量模型训练进行指导,通过这种方式来提升召回模型和精排模型在召回空间上的打分一致性,从而缓解召回阶段的SSB问题,同时训练过程中要通过stop_gradient的方式来屏蔽蒸馏loss对精排训练的影响:
PDM框架有如下优点:
将pctr和bid进行了解耦,当广告主的bid发生变化以后,可以在不重新训练模型,不重新产出向量的基础上,通过对原广告向量进行实时bid加权,来生成新的广告向量,实现对广告主调价的分钟级响应。提升了召回阶段对广告主bid的敏感性。
可以实现策略的实时调控,通过调节bid权重来对CTR和RPM进行平衡,可控性强。
可以显式地对齐后链路的各种间接目标,可解释性强。
线上效果:CTR+1.5% , RPM+2%
5.2 全空间粗排ESDM模型
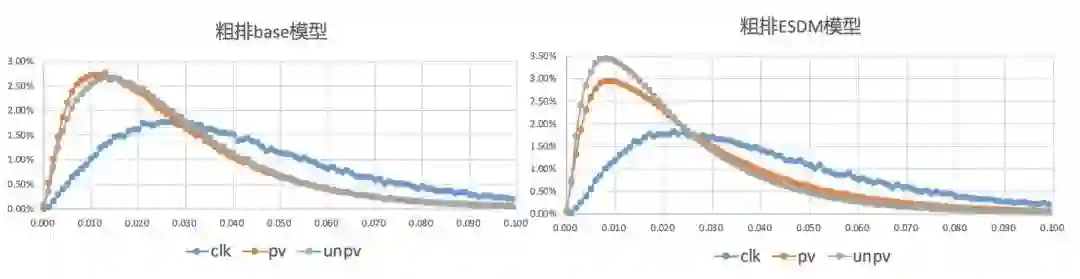
粗排模型往往使用pv/click样本训练,但是粗排在线推断空间远大于pv/click样本空间,展示广告目前粗排的打分量接近2W,两个空间样本分布存在很大差异,粗排阶段存在较严重的样本选择偏差(Sample Selection Bias,SSB)问题。
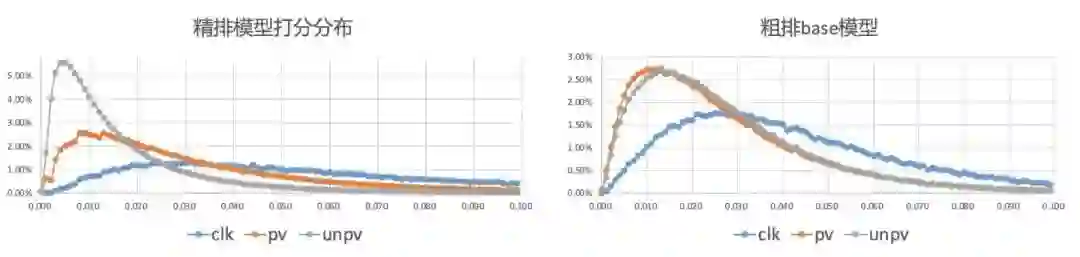
分析粗排和精排模型对unpv/pv/clk样本的打分分布,也可以看到,粗排模型对于pv/unpv样本的区分能力要弱于精排模型:
对于粗排打分空间中的unpv样本,要让粗排模型在缺乏监督label的情况下进行精准预估是很困难的。之前也尝试过通过引入外部样本来缓解粗排的SSB问题,但是并没有取得很好的效果。主要原因是因为外部样本存在大量噪音,外部样本去噪问题的解决难度并不比样本选择偏差问题低。
回到粗排的目标以及粗排精排的关系,重新思考样本选择偏差问题,这里我把粗排的SSB问题重新进行了定义,拆解成了两个子问题:
粗排模型和精排模型在粗排打分空间上的分布一致性问题。
精排的样本选择偏差问题。
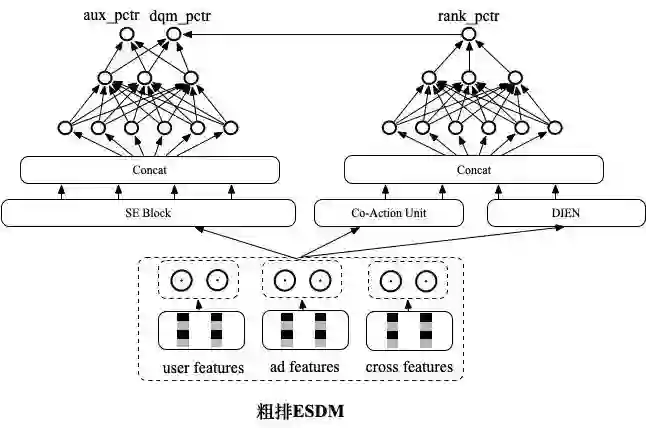
对于粗排模型和精排模型在粗排打分空间上的分布一致性问题,这里我提出了全空间粗排ESDM (Entire Space Domain Adaptation Deep Pre-Ranking Model) 模型来解决。而对于精排的样本选择偏差问题,可以考虑通过引入外部样本或者在本场景引入探索机制来获得无偏样本等方式,来解决这个问题。
样本上,首先构建了一条包含clk/pv/unpv样本的实时样本流。
训练上,粗排模型结构和
实时深度全连接模型COLD 保持一致,和精排模型一起进行联合训练,embedding共享,其中精排模型只基于展现样本通过交叉熵loss_rank进行训练。粗排模型除了在展现样本上以交叉熵loss_dqm进行训练之外,针对unpv样本,以知识蒸馏(Knowledge Distillation)的方式对精排模型pctr进行学习,通过soft loss的方式进行分布迁移:
为了提升模型对pv/unpv样本的区分能力,这里还将click作为正样本,pv和unpv作为负样本,以hard loss的方式引入进来,但是直接引入unpv样本,会导致粗排模型的pctr预估准度受到影响。因此在粗排主模型结构上,额外引入一个辅助网络,辅助网络前几层和主网络共享,只在最后几层有自己独立的参数,辅助网络输出为aux_pctr,将hard_loss作用到辅助网络aux_pctr上,通过参数共享的方式间接影响主网络:
最终loss为:
这里pctr得分,除了可以来自一起联合训练的精排模型之外,也可以使用线上精排模型打分的pctr分数,只不过考虑到在离线不一致等问题带来的分布差异,最好在粗排的aux_pctr上去distill。这样的好处是粗排可以跟随线上精排自动升级,维护成本较低,风险在于线上精排模型打分出现问题,也会影响到粗排训练。
下面对比了一下粗排ESDM模型和base模型的打分分布,可以看到粗排ESDM模型对pv/unpv的区分能力得到显著增强。同时在pcoc(精排pctr/粗排pctr)指标上,粗排模型在unpv样本上的pcoc从1.6降低到1.1。这些说明粗排模型和精排模型在粗排打分空间上的打分一致性得到了加强,样本选择偏差问题得到缓解。
线上效果:CTR+3% , RPM+1.5%
6. 集合选择技术
6.1 以学习后链路的序为目标的端到端召回技术LDM
基于精准值预估技术的召回PDM模型,使用的是广告主的原始bid,但是精排的策略调价模块会在广告主原始bid基础上考虑广告主和平台利益对bid进行调整,因此PDM仍然存在目标对齐上的问题。
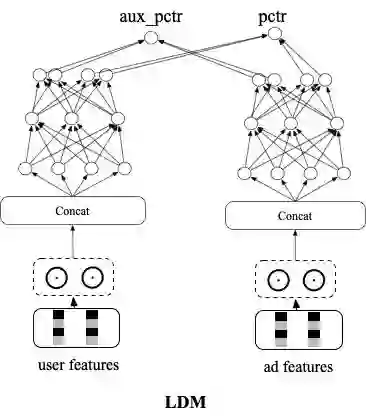
为了解决这个问题,我在召回阶段提出了以精排阶段的序为学习目标,通过端到端Learning to Rank的方式进行学习的召回技术LDM(Learning to Rank based Deep Match Model):
首先引入同一次请求内,精排阶段的参竞日志,在构造样本pair的时候把展现样本做为正样本,参竞未展现样本作为负样本,让模型学习将展现集合排在最前面,通过交叉熵loss进行学习。
这里仍然存在SSB问题,为了保证模型对简单样本的区分能力,同样引入了随机负采样loss,以展现作为正样本,batch内随机采的作为负样本。和召回PDM模型类似,同样额外构建了另外一个双塔网络,和原双塔网络前几层参数共享,新网络以交叉熵loss的方式进行学习。
后面进一步尝试了,将同一个session内的样本,按最终系统目标排序后,进行分段,段间组pair并通过pairwise loss进行学习,但是没有取得进一步的效果提升。推测原因是因为召回阶段的精度需求没有那么高。
线上效果:CTR+3% , RPM+4%
6.2 以学习后链路的序为目标的端到端粗排LBDM模型
展示广告的粗排阶段按照=pctr*init_bid的方式进行排序,而精排阶段会基于多目标打分(点击率/收藏加购率/成交率)的分数,通过策略调价模块对bid进行调整。因此粗排在bid部分的和精排存在较大差异。而如果沿着精准值预估路线,直接将精排阶段的多目标打分能力和策略调价能力迁移到粗排,会面临巨大的算力RT开销。
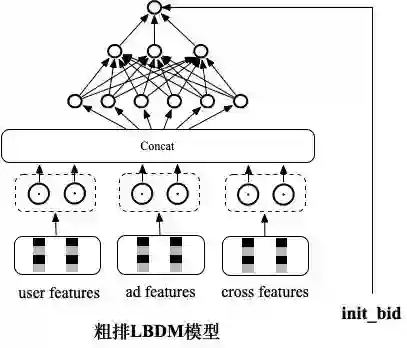
召回LDM模型的成功,证明了引入精排参竞日志进行学习这条技术路线是可行的。因此我提出从集合选择视角出发,在粗排阶段通过端到端Learning to Rank的方式,以精排阶段最终的序为学习目标进行建模的
粗排LBDM模型(Learning to Rank based and Bid-Sensitive Deep Pre-Ranking Model) 。这种方式彻底改变了原有的数据循环链路,改变了原有只依赖广告曝光展示样本的方式,新增了从精排到粗排的数据循环通路。
具体来说,这里首先构建了一条包含精排参竞样本的实时ODL数据流。
然后取同一个session下的精排参竞样本,按最终排序进行分档
档间样本两两组成pair,档内样本不组pair。因为粗排阶段只需要选出top k集合,并不关心集合内的顺序,因此通过这种构建pair的方式,来使粗排模型更贴近自己的实际目标。
模型结构上,和原来的
实时深度全连接模型COLD 保持一致,也包含用户特征,广告特征,交叉特征,实时特征等,整个模型实时训练,实时打分。后面进一步尝试了通过listwise loss的方式进行建模,但是没有进一步的收益,因此最终线上仍然基于pairwise的loss。
广告bid是广告主的重要抓手,广告主通过对出价的调整参与到广告系统的博弈中,保证广告主出价对排序的单调翘动能力和敏感性至关重要,传统的pairwise loss无法保证这一点。为了解决这个问题,我提出了新的bid单调型pairwise loss:
新的loss可以保证,广告主出价对排序的翘动能力是线性单调递增的,同时和其他方式相比对训练收敛的影响也比较小。
粗排LBDM模型线上打分阶段,也采取|ltr_score|*init_bid的方式,模型是实时训练,实时打分的,以保证对后链路分布的快速捕捉能力。这种方式完全兼容之前pctr*init_bid的排序方式,线上只需要把粗排PCTR模型替换成粗排LBDM模型即可,线上系统也不需要做任何改造。ltr_score本身没有物理含义,但是这种训练方式使模型学出来的是一个类似pctr*调价系数的分数,即一方面可以拟合精排pctr模型的信息,另一方面可以拟合策略调价模块的信息。
这里也从客户侧视角分析了一下粗排LBDM模型对不同行业和不同粒度广告主拿量能力和ROI的影响,发现和粗排PCTR模型相比拿量变化较小,ROI等客户侧指标均有提升。
考虑到粗排LBDM模型以后链路样本为学习目标的训练方式有可能加剧马太效应,因此也分析了粗排LBDM模型对不同曝光量广告的拿量影响,发现变化不大,说明粗排LBDM模型基本不会加剧马太效果,这个有可能是粗排打分集合以及广告主预算限制导致的。
7. 利用-探索(Exploit&Explore) 全链路通道
集合选择技术路线大大提高了整个系统链路的目标对齐能力和效果,但是由于依赖精排阶段的样本进行学习,有可能对整个系统的探索发现性造成影响。而精准值预估技术因为有更强的主动性和更少的数据依赖,在探索发现性上会有更好的表现,但是受限于自身复杂性,在同等算利力RT水平下和集合选择技术相比,对齐最终系统目标的能力往往比较有限。
在以往以精准值预估技术为主的的级联排序系统中,因为前链路各模块在目标和模型能力上和后链路往往存在gap,因此在一定程度上隐式地存在一个探索机制。但是这种探索机制是存在问题的:一方面以限制整个链路在记忆利用(Exploit)上的的能力为代价,牺牲了最终的系统目标和效果,另一方面由于探索(Explore)和利用(Exploit)耦合,也难以专门提升优化探索的效果。
全链路联动技术为了解决这些问题,结合精准值预估技术和集合选择技术两条路线各自的特点,将利用(Exploit)和探索(Explore)显式的拆分成两个全链路通道,分别进行极致的优化:
全链路利用通道:
全链路探索通道:
专注于长期系统生态优化,如新广告冷启和客户侧指标等。
以精度值预估技术为主。
利用-探索(Exploit&Explore) 全链路通道,一方面可以使整个全链路系统可以在没有干扰负担的情况下,去极致的优化对齐短期的系统目标。另一方面也可以从长期生态着眼,去心无旁骛进行探索上的优化提升并尽可能减少对系统效果的影响。探索通道的结果也可以快速被利用通道吸收放大,从而促进整个系统的良性循环。
当然,以集合选择技术为主的全链路利用通道,会不会造成整个系统的数据闭环和技术上的隐形死锁,仍然是一个需要持续研究和观察的事情。这里我们主要观察了两个指标:一个是统计头部top比例广告的展现占比变化,来判断是否加强了马太效应。另一个则是观察新广告的展现占比,来判断对新广告冷启的影响。
阿里妈妈展示广告在召回阶段落地的LDM模型,确实会在一定程度上加剧马太效应,但是因为多路召回的存在,因此对整个广告系统在数据闭环上的影响是可控的。
阿里妈妈展示广告在粗排阶段落地的LBDM模型,并没有观察到明显的马太效应,有可能是因为粗排只是一个中间模块,因此对马太效应的影响能力比较有限。在新广告冷启指标上,观察到粗排LBDM会降低1天内新广告的展现占比,但是提升7天内新广告的展现占比。这个说明集合选择技术会在前期样本缺乏的情况下打新广告形成打压,但是在新广告冷启后期数据充足的情况下,会迅速起到一个放大作用,帮助新广告更快的收敛。
另外广告系统存在bid和广告预算,广告主通过对bid的调整参与到整个数据循环中,变相的形成了一种动态的探索博弈机制,整个系统环境变化更为频繁,可能更难形成持续的稳态和数据闭环。集合选择技术在召回提升了bid敏感性,加强了bid对召回的影响能力,在粗排仍然保持了和之前相当的bid敏感性,因此甚至有可能加强bid对整个系统数据循环的扰动能力。广告主在拿量被削弱或者新广告冷启阶段,往往通过主动提升bid来获得竞争优势,拿到更多流量。而在广告流量过大的情况下,又往往因为广告预算限制,无法负担更多的流量投放,限制了马太效应的形成。
而全链路联动技术对搜索推荐等非广告场景来说,确实有更大的数据闭环风险,因此在探索通道的建设上也更为急迫,后面在全链路联动技术的落地过程中,需要设计更多指标,更长的观察周期和实验方式,来观察研究全链路联动技术对整个系统长期的影响。同时也需要进一步研究如何构建更好的探索机制,探索通道和利用通道如何更好的配合等等。
这篇文章的目的,除了向大家分享我在全链路联动技术上探索的经验成果之外,也希望能起到抛砖引玉的作用,吸引更多的人可以加入到这个新方向的探索研究过程中,以便推动这个方向更快更好的发展。
7. 业务效果
全链路联动技术已经在阿里妈妈展示广告主要业务场景落地全量,给阿里妈妈广告收入带来巨大增长。精准值预估技术:
集合选择技术:
8. 总结与展望
在技术算力红利逐渐消失,单模块技术迭代进入深水区的情况,全链路联动技术沿着精准值预估路线提出了召回PDM技术和粗排全空间ESDM模型,沿着集合选择技术路线提出了召回LDM技术和粗排LBDM模型,革新了整个阿里妈妈展示广告的排序体系,使整个系统在理论上具备了对齐最终系统目标的能力,减少了系统的链路损耗,使整个系统的算力分配更为合理,打开了全新的技术增长空间,给阿里妈妈展示广告带来了一波巨大的技术红利,也给阿里大盘广告收入带来了10%以上的巨大增长。
如果把级联排序的过程比做射击的话,全链路联动技术做的事情就是去提升瞄准能力,让枪打的更准。在打准的情况下去选择威力更强的武器,才能取得更好的杀伤效果。否则枪再好,打不准,一切都是徒劳。因此通过全链路联动技术,去对齐最终系统目标以后,如果存在算力富余,那么可以进一步对全链路各个模块进行模型复杂度升级和算力倾斜,这样有可能存在一波新的技术红利。
正所谓合久必分,分久必合。早期的级联排序架构,很大程度上是算力RT不足的无奈之举。现在随着算力的提升以及对算力的运用更加纯熟,可以进一步探索能否突破级联架构限制,实现模块间以及模块内部的进一步联动融合,甚至是实现多模块一体化的端到端排序新体系。这个有可能带来新的革命性成果。
同时也可以考虑进一步探索精准值预估技术和集合选择技术发展融合的可能,使整个排序系统兼具二者的优点。
9. 关于
王哲,阿里妈妈展示广告算法专家,曾负责蚂蚁金服跨境游业务推荐营销算法,目前在阿里妈妈展示广告负责手淘信息流广告排序模型和全链路联动相关工作。
PS:大家如果觉得文章写的还可以,欢迎给个赞,非常感谢!
推荐阅读