图像大面积缺失,也能逼真修复,新模型CM-GAN兼顾全局结构和纹理细节
机器之心报道
来自罗彻斯特大学和 Adobe Research 的研究者提出了一种新的生成网络 CM-GAN,很好地合成了整体结构和局部细节,在定量和定性评估方面都显著优于现有 SOTA 方法,如 CoModGAN 和 LaMa。
图像修复是指对图像缺失区域进行补全,是计算机视觉的基本任务之一。该方向有许多实际应用,例如物体移除、图像重定向、图像合成等。
早期的修复方法基于图像块合成或颜色扩散来填充图像缺失部分。为了完成更复杂的图像结构,研究人员开始转向数据驱动的方案,他们利用深度生成网络来预测视觉内容和外观。通过在大量图像上进行训练,并借助重建和对抗损失,生成式修复模型已被证明可以在包括自然图像和人脸在内的各种类型输入数据上产生更具视觉吸引力的结果。
然而,现有工作只能在完成简单的图像结构方面显示出良好的结果,生成整体结构复杂和细节高保真的图像内容仍然是一个巨大的挑战,特别是当图像空洞(hole)很大的时候。
从本质上讲,图像修复面临两个关键问题:一个是如何将全局上下文准确地传播到不完整区域,另一个是合成与全局线索一致的真实局部细节。为了解决全局上下文传播问题,现有网络利用编码器 - 解码器结构、空洞卷积、上下文注意力或傅里叶卷积来整合长程特征依赖,扩大有效感受野。此外,两阶段方法和迭代空洞填充依靠预测粗略结果来增强全局结构。然而,这些模型缺乏一种机制来捕获未掩码区域的高级语义,并有效地将它们传播到空洞中以合成一个整体的全局结构。
基于此,来自罗彻斯特大学和 Adobe Research 的研究者提出了一种新的生成网络:CM-GAN(cascaded modulation GAN),该网络可以更好地合成整体结构和局部细节。CM-GAN 中包括一个带有傅里叶卷积块的编码器,用于从带有空洞的输入图像中提取多尺度特征表征。CM-GAN 中还有一个双流解码器,该解码器在每个尺度层都设置一个新型级联的全局空间调制块。
在每个解码器块中,研究者首先应用全局调制来执行粗略和语义感知的结构合成,然后进行空间调制来进一步以空间自适应方式调整特征图。此外,该研究设计了一种物体感知训练方案,以防止空洞内产生伪影,从而满足现实场景中物体移除任务的需求。该研究进行了广泛的实验表明,CM-GAN 在定量和定性评估方面都显著优于现有方法。

论文地址:https://arxiv.org/pdf/2203.11947.pdf
项目地址:https://github.com/htzheng/CM-GAN-Inpainting
我们先来看下图像修复效果,与其他方法相比,CM-GAN 可以重建更好的纹理:

CM-GAN 可以合成更好的全局结构:

CM-GAN 具有更好的物体边界:

下面我们来看下该研究的方法和实验结果。
方法
级联调制 GAN
为了更好地建模图像补全的全局上下文,该研究提出一种将全局码调制与空间码调制级联的新机制。该机制有助于处理部分无效的特征,同时更好地将全局上下文注入空间域内。新架构 CM-GAN 可以很好地综合整体结构和局部细节,如下图 1 所示。

如下图 2(左) 所示,CM-GAN 基于一个编码器分支和两个并行级联解码器分支来生成视觉输出。编码器以部分图像和掩码为输入,生成多尺度特征图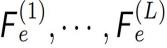
与大多数编码器 - 解码器方法不同,为了完成整体结构,该研究从全连接层的最高级别特征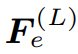
全局空间级联调制。为了在解码阶段更好地连接全局上下文,该研究提出了全局空间级联调制 (CM,cascaded modulation)。如图 2(右)所示,解码阶段基于全局调制块(GB)和空间调制块(SB)两个分支,并行上采样全局特征 F_g 和局部特征 F_s。
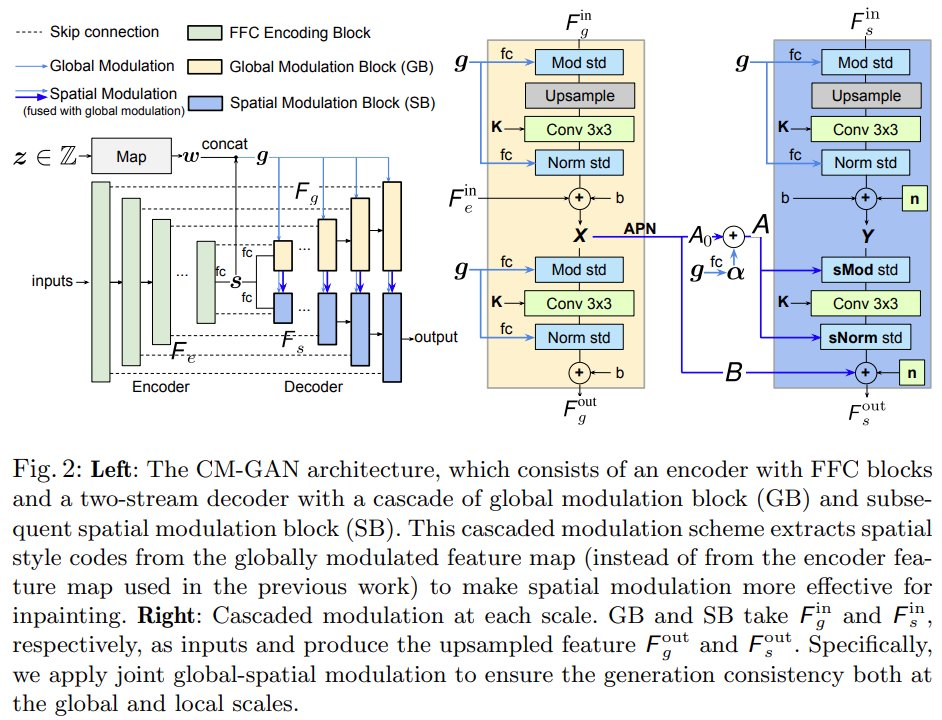
与现有方法不同,CM-GAN 引入了一种将全局上下文注入空洞区域的新方法。在概念层面上,它由每个尺度的特征之间的级联全局和空间调制组成,并且自然地集成了全局上下文建模的三种补偿机制:1)特征上采样;2) 全局调制;3)空间调制。

物体感知训练
为训练生成掩码的算法至关重要。本质上,采样的掩码应该类似于在实际用例中绘制的掩码,并且掩码应避免覆盖整个物体或任何新物体的大部分。过度简化的掩码方案可能会导致伪影。
为了更好地支持真实的物体移除用例,同时防止模型在空洞内合成新物体,该研究提出了一种物体感知训练方案,在训练期间生成了更真实的掩码,如下图 4 所示。

具体来说,该研究首先将训练图像传递给 全景分割网络 PanopticFCN 以生成高度准确的实例级分割注释,然后对自由空洞和物体空洞的混合进行采样作为初始掩码,最后计算空洞和图像中每个实例之间的重叠率。如果重叠率大于阈值,该方法将前景实例从空洞中排除;否则,空洞不变并模拟物体完成,其中阈值设为 0.5。该研究随机扩展和平移物体掩码以避免过度拟合。此外,该研究还扩大了实例分割边界上的空洞,以避免将空洞附近的背景像素泄漏到修复区域中。
训练目标与 Masked-R_1 正则化
该模型结合对抗性损失和基于分割的感知损失进行训练。实验表明,该方法在纯粹使用对抗性损失时也能取得很好的效果,但加入感知损失可以进一步提高性能。
此外,该研究还提出了一种专门用于稳定修复任务的对抗性训练的 masked-R_1 正则化,其中利用掩码 m 来避免计算掩码外的梯度惩罚。
实验
该研究在 Places2 数据集上以 512 × 512 分辨率进行了图像修复实验,并给出了模型的定量和定性评估结果。
定量评估:下表 1 为 CM-GAN 与其他掩码方法的比较。结果表明,CM-GAN 在 FID、LPIPS、U-IDS 和 P-IDS 方面明显优于其他方法。在感知损失的帮助下,LaMa、CM-GAN 比 CoModGAN 和其他方法获得了明显更好的 LPIPS 分数,这归功于预训练感知模型提供的额外语义指导。与 LaMa/CoModGAN 相比,CM-GAN 将 FID 从 3.864/3.724 降低到 1.628。
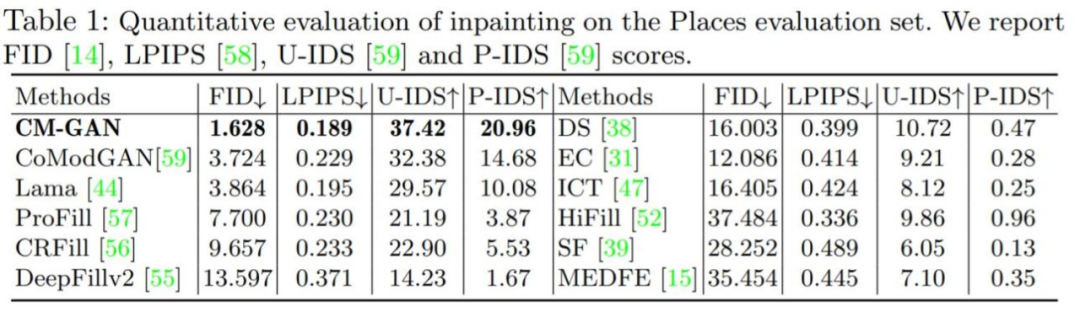
如下表 3 所示,在有无微调的情况下,CM-GAN 在 LaMa 和 CoModGAN 掩码上都取得了明显优于 LaMa 和 CoModGAN 的性能增益,表明该模型具有泛化能力。值得注意的是,在 CoModGAN 掩码,物体感知掩码上训练的 CM-GAN 性能依然优于 CoModGAN 掩码,证实了 CM-GAN 具有更好的生成能力。
定性评估:图 5、图 6、图 8 展示了 CM-GAN 与 SOTA 方法在合成掩码方面的可视化比较结果。ProFill 能够生成不连贯的全局结构,CoModGAN 产生结构伪影和颜色斑点,LaMa 在自然场景上容易产生较大的图像模糊。相比之下,CM-GAN 方法产生了更连贯的语义结构、纹理更清晰,可适用于不同场景。



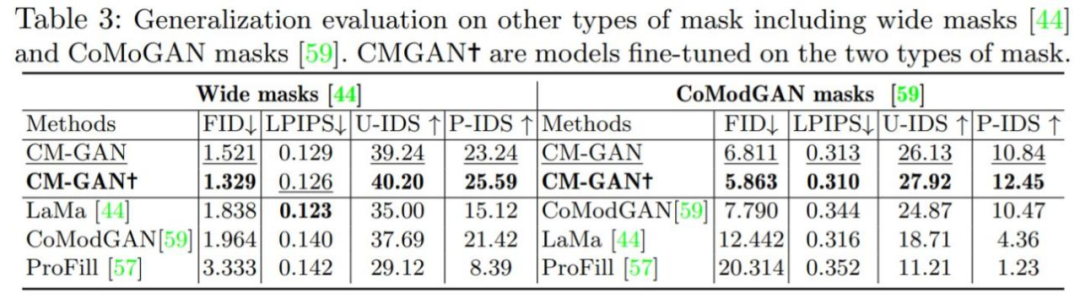
为了验证模型中每个组件的重要性,该研究进行了一组消融实验,所有模型都在 Places2 数据集上进行训练和评估。消融实验结果如下表 2 和图 7 所示。
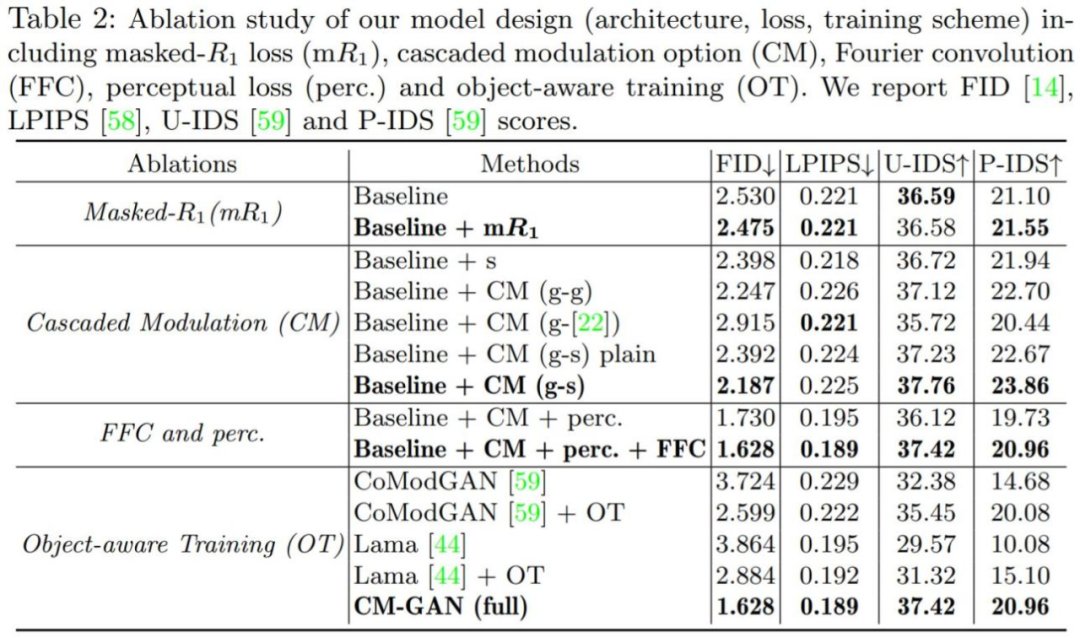

该研究还进行了用户研究,以更好地评估 CM-GAN 方法的视觉生成质量,结果如下表 5 所示。此外,附录提供了更多的视觉比较和实验分析以供读者参阅。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com