让数字人更接近真人质感,关键还要在头发丝上下功夫。
近年来,虚拟数字人行业爆火,各行各业都在推出自己的数字人形象。毫无疑问,高保真度的 3D 头发模型可以显著提升虚拟数字人的真实感。与人体的其他部分不同,由于交织在一起的头发结构极其复杂,因此描述和提取头发结构更具挑战性,这使得仅从单一视图重建高保真的 3D 头发模型极其困难。一般来说,现有的方法都是通过两个步骤来解决这个问题:首先根据从输入图像中提取的 2D 方向图估计一个 3D 方向场,然后根据 3D 方向场合成头发丝。但这种机制在实践中仍在存在一些问题。
基于实践中的观察,研究者们正在寻求一个完全自动化和高效的头发模型建模方法,可以从具备细粒度特征的单一图像重建一个 3D 头发模型(如图 1),同时显示出高度的灵活性,比如重建头发模型只需要网络的一个前向传递。
![]()
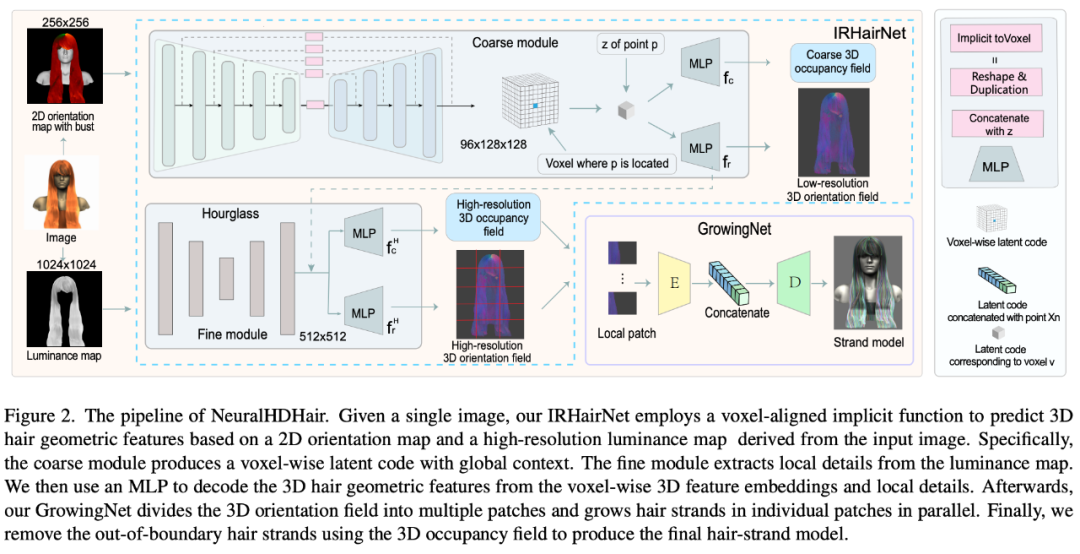
为了解决这些问题,来自浙江大学、瑞士苏黎世联邦理工学院和香港城市大学的研究者提出了 IRHairNet,实施一个由粗到精的策略来生成高保真度的 3D 方向场。具体来说,他们引入了一种新颖的 voxel-aligned 的隐函数(VIFu)来从粗糙模块的 2D 方向图中提取信息。同时,为了弥补 2D 方向图中丢失的局部细节,研究者利用高分辨率亮度图提取局部特征,并结合精细模块中的全局特征进行高保真头发造型。
为了有效地从 3D 方向场合成头发丝模型,研究者引入了 GrowingNet,一种基于深度学习利用局部隐式网格表征的头发生长方法。这基于一个关键的观察:尽管头发的几何形状和生长方向在全局范围内有所不同,但它们在特定的局部范围内具有相似的特征。因此,可以为每个局部 3D 方向 patch 提取一个高级的潜在代码,然后训练一个神经隐函数 (一个解码器) 基于这个潜在代码在其中生长头发丝。在每一个生长步骤之后,以头发丝的末端为中心的新的局部 patch 将被用于继续生长。经过训练后,它可适用于任意分辨率的 3D 定向场。
![]()
论文:https://arxiv.org/pdf/2205.04175.pdf
IRHairNet 和 GrowingNet 组成了 NeuralHDHair 的核心。具体来说,这项研究的主要贡献包括:
介绍了一种新颖的全自动单目毛发建模框架,其性能明显优于现有的 SOTA 方法;
介绍了一个从粗到细的毛发建模神经网络(IRHairNet) ,使用一个新颖的 voxel-aligned 隐函数和一个亮度映射来丰富高质量毛发建模的局部细节;
提出了一种基于局部隐函数的新型头发生长络(GrowingNet) ,可以高效地生成任意分辨率的头发丝模型,这种网络比以前的方法的速度实现了一定数量级的提升。
图 2 展示了 NeuralHDHair 的 pipeline。对于人像图像,首先计算其 2D 方向图,并提取其亮度图。此外,自动将它们对齐到相同的半身参考模型,以获得半身像深度图。然后,这三个图随后被反馈到 IRHairNet。
![]()
IRHairNet 设计用于从单个图像生成高分辨率 3D 头发几何特征。这个网络的输入包括一个 2D 定向图、一个亮度图和一个拟合的半身深度图,这些都是从输入的人像图中得到的。输出是一个 3D 方向字段,其中每个体素内包含一个局部生长方向,以及一个 3D 占用字段,其中每个体素表示发丝通过 (1) 或不通过(0)。
GrowingNet 设计用于从 IRHairNet 估计的 3D 定向场和 3D 占用字段高效生成一个完整的头发丝模型 ,其中 3D 占用字段是用来限制头发的生长区域。
在这一部分,研究者通过消融研究评估了每个算法组件的有效性和必要性 (第 4.1 节),然后将本文方法与当前的 SOTA(第 4.2 节) 进行比较。实施细节和更多的实验结果可以在补充材料中找到。
![]()
研究者从定性和定量的角度评估了 GrowingNet 的保真度和效率。首先对合成数据进行三组实验:1)传统的头发生长算法,2)没有重叠潜在 patch 方案的 GrowingNet,3)本文的完整模型。
如图 4 和表 1 所示,与传统的头发生长算法相比,本文的 GrowingNet 在时间消耗上具有明显的优势,同时在视觉质量上保持了相同的生长性能。此外,通过比较图 4 的第三列和第四列,可以看到,如果没有重叠潜在 patch 方案,patch 边界处的发丝可能是不连续的,当发丝的生长方向急剧变化时,这个问题就更加严重。不过值得注意的是,这种方案以略微降低精度为代价,大大提高了效率,提高效率对于其方便、高效地应用于人体数字化是有重要意义的。
![]()
![]()
为了评估 NeuralHDHair 的性能,研究者将其与一些 SOTA 方法 [6,28,30,36,40] 进行了对比。其中 Autohair 基于数据驱动的方法进行头发合成,而 HairNet [40]忽略头发生长过程来实现端到端的头发建模。相比之下,[28,36]执行一个两步策略,首先估计一个 3D 方向场,然后从中合成发丝。PIFuHD [30]是一种基于粗到细策略的单目高分辨率 3D 建模方法,可以用于 3D 头发建模。
如图 6 所示,HairNet 的结果看起来差强人意,但是局部的细节,甚至整体的形状与输入图像中的头发不一致。这是因为该方法用一种简单而粗糙的方式来合成头发,直接从单一的图像中恢复无序的发丝。
![]()
这里还将重建结果与 Autohair[6]和 Saito[28]进行了比较。如图 7 所示,虽然 Autohair 可以合成真实的结果,但结构上不能很好地匹配输入图像,因为数据库包含的发型有限。另一方面,Saito 的结果缺乏局部细节,形状与输入图像不一致。相比之下,本文方法的结果更好地保持了头发的全局结构和局部细节,同时确保了头发形状的一致性。
![]()
PIFuHD [30]和 Dynamic Hair [36]则致力于估计高保真度的 3D 头发几何特征,以生成真实的发丝模型。图 8 展示了两个有代表性的比较结果。可以看出,PIFuHD 中采用的像素级隐函数无法充分描绘复杂的头发,导致结果过于光滑,没有局部细节,甚至没有合理的全局结构。Dynamic Hair 可以用较少的细节产生更合理的结果,而且其结果中的头发生长趋势可以很好地匹配输入图像,但许多局部结构细节 (例如层次结构) 无法捕获,特别是对于复杂的发型。相比之下,本文的方法可以适应不同的发型,甚至是极端复杂的结构,并充分利用全局特征和局部细节,生成高保真、高分辨率的具有更多细节的 3D 头发模型。
![]()
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com