论文浅尝 | 融合多层次领域知识的分子图对比学习
笔记整理 | 方尹,浙江大学在读博士,研究方向:图表示学习

论文地址:https://arxiv.org/pdf/2106.04509.pdf
动机
目前基于图的对比学习有以下几个问题:
不同领域的图,(比如social network和分子图)它们的图结构信息和图的semantics是不同的,因此很难设计一个通用的、适用于所有场景的数据增强方法;大多数方法只关心局部结构而忽略了全局结构,比如结构相似的两个图在embedding space也会更接近;对比的scheme不是单一的,对比可以发生在节点-图,节点-节点,图-图之间。
对比学习本身也有一些待解决的问题,之前很多对比学习方法是通过最大化一对graph augmentation之间的互信息来实现的:在高维情况下正确估计互信息很困难;最大化互信息和对比学习之间的联系尚不明确。
贡献
提出了一种基于局部领域知识的分子图augmentation方法;
提出了一种全局的对比损失,并将局部对比损失和全局对比损失线性组合作为总体损失。
模型与算法
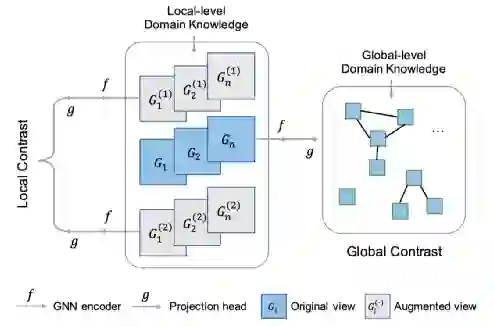
局部水平:在graph augmentation中注入了领域知识
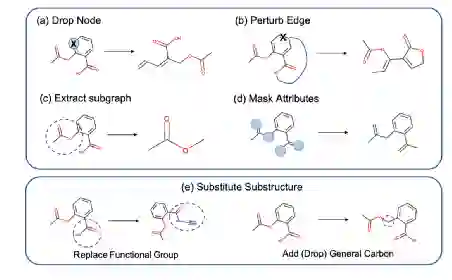
1.图上半部分为传统的图增强方法:丢掉节点、移动边、提取子图、mask属性,下半部分为提出的增强方法。把重要的子结构替换掉,但仍保持相似的性质。这里是替换了官能团,加上或去除普通的C原子,不影响替换前后分子图的性质。这一步引入了领域知识。
2.局部对比最大化两个augmented views的互信息。
3.每个样本的对比学习损失,其中s是衡量两个embedding相似度的函数。

全局水平:考虑了整体的graph semantic
1.定义了两个分子图之间的相似性,再最大化两个相似图之间的互信息。定义分子图相似性这一步用到了领域知识,因为分子的相似性就是分子指纹的谷本系数。
2.两种计算全局损失的方法:

Connection to Metric Learning

MoCL的损失是局部损失和全局损失的加和。引理设定了一些前提,比如分子相似度函数、参数,最终损失可以表示为三个triplet loss之和。因此,MoCL的优化目标是拉近正样本对,同时从局部和全局角度推开负样本对。
实验与结果
Q1:注入局部领域知识的对比学习是否学到了比普通augmentation方法更好的图表示?不同的图增强组合表现如何?
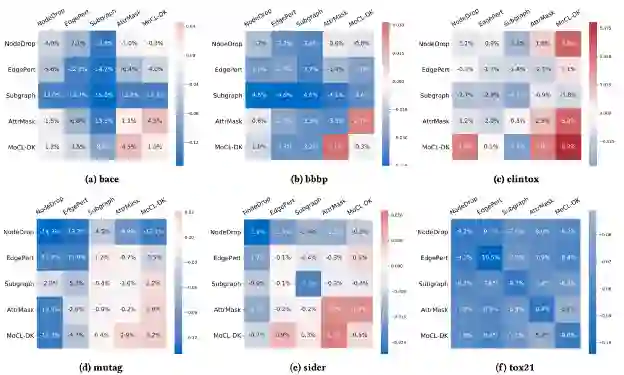
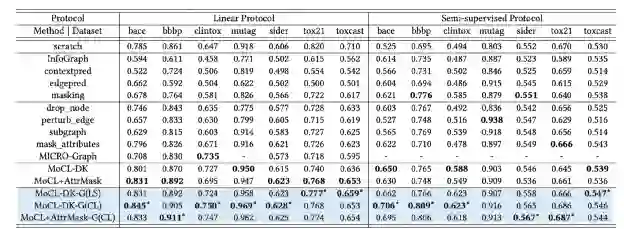
每个cell表示从头训练的GNN与用不同的augmentation组合方法训练的模型在linear protocol下的performance有多少进步。蓝色代表负值,红色代表正值。MoCL-DK得到的表示加上线性分类器产生的预测准确率与GNN效果(bace、bbbp、sider)相当,甚至比它更好(clintox , mutag)。可以看到包含MoCL-DK 的行和列的值通常更高 ,因此MoCL-DK 与其他augmentation方法相结合几乎总是能产生更好的结果。属性屏蔽和 MoCL-DK 通常在所有场景中都有效,将它们结合起来通常会有更好的性能。这验证了我们之前的假设,即 MoCL-DK 和属性屏蔽不违反生物学假设,因此比其他增强效果更好。
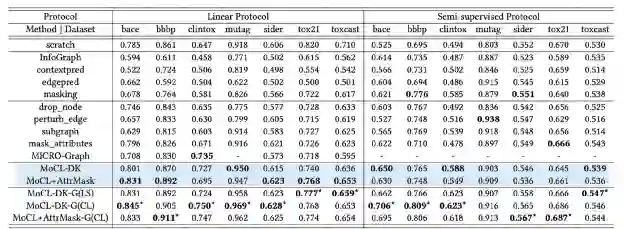
分别在linear protocol和semi-supervised protocol下进行了实验。跟其他用到data augmentation和对比学习的方法做了比较,在大部分数据集上超过了sota。

比较了不同augmentation强度情况下的效果,强度指的是增强几次,比如替换后再替换一次,就是增强两次。对于大多数数据集,随着增强次数越多,性能先上升后下降。 MoCL-DK3 通常能取得更好的结果。
Q2:注入全局领域知识是否进一步提升了图表示?计算全局损失的两个策略表现分别如何?
LS是第一种策略,CL是第二种策略。加上了全局领域知识进一步提升了模型的性能。
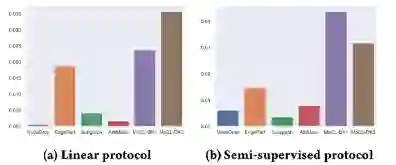
加入全局领域知识后不同augmentation方法的性能提升 。可以看到全局信息的引入会提升所有方法。
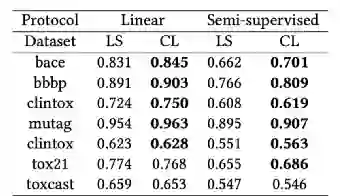
比较了两种protocol下,采用不同的策略的全局损失函数所获得的性能。可以看到,全局相似性的对比损失(CL)比最小二乘损失(LS)的策略获得了更好的结果。
Q3:超参数如何影响模型的性能?

相对较小的neighbor size和相对较大的全局损失占比会获得最佳结果。
欢迎有兴趣的同学阅读原文。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。


