独家 | 25道SVM题目,测一测你的基础如何?(附资源)

翻译:张逸
校对:韩海畴
本文共3163字,建议阅读8分钟。
本测试共25道题,帮助你检验对SVM原理和应用的掌握程度。
介绍
在某种意义上,你可以把机器学习算法看作有很多刀剑的军械库。里边有各种各样的工具,你要做的,就是得学会在对的时间使用对的工具。举个例子,如果把“回归”看作是一把剑,它可以轻松地将一部分数据大卸八块,但面对高度复杂的数据时却无能为力。相反,支持向量机就像一把锋利的小刀--它适用于规模更小的数据集,这并不代表这把刀威力不够,相反的,它在构建模型时表现的非常强大。
这个测试就是帮助你检验对SVM原理和应用的掌握程度。已经有超过550个人参加了这个测试。如果你当时错过了也没关系,我们在这篇帖子中整理了所有的问题和答案。
相关资源
这里有一些更深入的资源:
Essentials of Machine Learning Algorithms (with Python and R Codes)
Understanding Support Vector Machine algorithm from examples (along with code)
测试开始!
阅读下面的文字,回答1-2题:
假设有一个线性SVM分类器用来处理二分类问题,下图显示给定的数据集,其中被红色圈出来的代表支持向量。
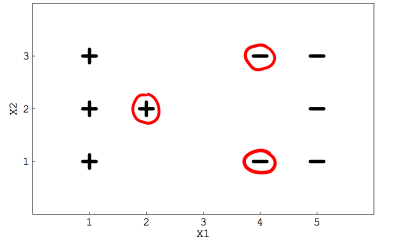
1. 若移动其中任意一个红色圈出的点,决策边界是否会变化?
会
不会
答案:A
这三个支持向量确定决策边界的位置,如果它们中的任意一个被改变,决策边界一定会变化。
2. 若移动其中任意一个没有被圈出的点,决策边界会发生变化?
正确
错误
答案:B
支持向量以外的点并不会影响决策边界。
3. SVM中的泛化误差代表什么?
分类超平面与支持向量的距离
SVM对新数据的预测准确度
SVM中的误差阈值
答案:B
泛化误差在统计学上的意义是“样本外误差”。这是一种模型在未知的新数据上预测准确性的度量。
4. 若参数C(cost parameter)被设为无穷,下面哪种说法是正确的?
只要最佳分类超平面存在,它就能将所有数据全部正确分类
软间隔SVM分类器将正确分类数据
二者都不对
答案:A
在如此高的误分类惩罚下,不会存在软间隔分类超平面,因为一点错误都不可能发生。
5. 怎样理解“硬间隔”?
SVM只允许极小误差
SVM允许分类时出现一定范围的误差
二者都不对
答案:A
硬间隔表明SVM对分类正确性的要求非常严格,所以模型会尽力在训练集上表现的更好,这通常会造成过拟合。
6. SVM算法的最小时间复杂度是O(n²),基于此,以下哪种规格的数据集并不适该算法?
大数据集
小数据集
中等数据集
不受数据集大小影响
答案:A
除了规模要小,具有明显分类边界的数据集也更适合SVM算法。
7. SVM算法的性能取决于:
核函数的选择
核函数的参数
软间隔参数C
以上所有
答案:D
上述三点都会影响到算法的表现,应尽量选择最佳的参数,以最大限度提高效率、减少误差以及避免过拟合。
8. 支持向量是最靠近决策表面的数据点
正确
错误
答案:A
支持向量是最接近超平面的点,这些点也最难分类,他们会直接影响决策边界的位置。
9. 以下哪种情况会导致SVM算法性能下降?
数据线性可分
数据干净、格式整齐
数据有噪声,有重复值
答案:C
当数据集有大量噪声和重叠点时,要想得到一个清晰的分类超平面非常困难。
10. 假设你选取了高Gamma值的径向基核(RBF),这表示:
建模时,模型会考虑到离超平面更远的点
建模时,模型只考虑离超平面近的点
模型不会被数据点与超平面的距离影响
答案:B
Gamma参数会调整远离超平面的数据点对模型的影响。
Gamma值较低,模型受到很多约束,会包含训练集中所有数据点,并不会捕捉到真正的模式。
Gamma值较高,模型对数据集形状的勾勒更加有效。
11. SVM中的代价参数C表示什么?
交叉验证的次数
用到的核函数
在分类准确性和模型复杂度之间的权衡
以上都不对
答案:C
代价参数的大小决定了SVM能允许的误分类程度。
C的值小:优化的目标是得到一个尽可能光滑的决策平面。
C的值大:模型只允许出现很小数量的误分类点。
它可以简单的看做是对误分类的惩罚。
阅读下面的文字,回答12-13题:
假定有一个数据集S,但该数据集有很多误差(这意味着不能太过依赖任何特定的数据点)。若要建立一个SVM模型,它的核函数是二次多项式核,同时,该函数使用变量C(cost parameter)作为一个参数。
12. 若C趋于无穷,以下哪种说法正确?
数据仍可正确分类
数据无法正确分类
不确定
以上都不对
答案:A
若变量C的值很大,说明误分类的惩罚项非常大,优化的目标应该是让分类超平面尽量将所有的数据点都正确分类。
13. 若C的值很小,以下哪种说法正确?
会发生误分类现象
数据将被正确分类
不确定
以上都不对
答案:A
因为误分类的惩罚项非常小,模型得出的分类面会尽可能将大多数数据点正确分类,但有部分点会出现误分类现象。
14. 若训练时使用了数据集的全部特征,模型在训练集上的准确率为100%,验证集上准确率为70%。出现的问题是?
欠拟合
过拟合
模型很完美
答案:B
在训练集上准确率高,但在测试集上表现差是典型的过拟合现象。
15. 下面哪个是SVM在实际生活中的应用?
文本分类
图片分类
新闻聚类
以上都对
答案:D
SVM在实际生活中的应用领域非常广泛,从分类、聚类到手写字体识别都有涉及。
阅读下面这段文字,回答16-18题
假定你现在训练了一个线性SVM并推断出这个模型出现了欠拟合现象。
16. 在下一次训练时,应该采取下列什么措施?
增加数据点
减少数据点
增加特征
减少特征
答案:C
最好的选择就是生成更多的特征。
17. 假定你上一道题回答正确,那么根本上发生的是:
1 偏差(bias)降低
2 方差(variance)降低
3 偏差增加
4 方差增加
1和2
2和3
1和4
2和4
答案:C
如果要使得模型性能更好,就要在偏差和方差之间做出权衡。
【补充】
泛化误差 = 偏差+方差+误差
误差:由数据本身或模型本身的问题引起,是期望泛化误差的下界。
偏差:描述预测值的期望和真实值之间的差距,度量模型本身拟合能力。
方差:描述预测值的变化范围,离散程度。度量了同样大小的训练集的变动导致的学习性能的变化。度量模型对学习样本的依赖性。
一般模型越复杂,学习能力越强,误差会越小但方差越大。反之模型越简单,对数据的拟合能力越弱,误差大同时方差小。
18. 还是上面的问题,如果不在特征上做文章,而是改变一个模型的参数,使得模型效果改善,以下哪种方法是正确的?
增加代价参数C
减小代价参数C
改变C的值没有作用
以上都不对
答案:A
增加参数C的值会确保得到正则化的模型。
19. 在应用高斯核SVM之前,通常都会对数据做正态化(normalization),下面对特征正态化的说法哪个是正确的?
1 对特征做正态化处理后,新的特征将主导输出结果
2 正态化不适用于类别特征
3 对于高斯核SVM,正态化总是有用
1
1和2
1和3
2和3
答案:B
阅读下面这段文字,回答20-22题:
假定现在有一个四分类问题,你要用One-vs-all策略训练一个SVM的模型。请看下面的问题:
20. 由题设可知,你需要训练几个SVM模型?
1
2
3
4
答案:D
多分类问题中,One-vs-all策略要求为每一个类建立唯一的分类器,属于此类的所有样例均为正例,其余全部为负例。
21. 假定数据集中每一类的分布相同,且训练一次SVM模型需要10秒,若完成上面的任务,共花费多少秒?
20
40
60
80
答案:B
花费时间为10*4=40秒。
22. 现在问题变了,如果目前只需要将数据集分为2类,需要训练多少次?
1
2
3
4
答案:A
该情况下训练SVM一次就能获得满意的结果。
阅读下面的文字,回答23-24题:
假定你使用阶数为2的线性核SVM,将模型应用到实际数据集上后,其训练准确率和测试准确率均为100%。
23. 假定现在增加模型复杂度(增加核函数的阶),会发生以下哪种情况?
过拟合
欠拟合
什么都不会发生,因为模型准确率已经到达极限
以上都不对
答案:A
增加模型的复杂度会导致过拟合现象,这与模型当前的状态无关。
24. 在增加了模型复杂度之后,你发现训练准确率仍是100%,原因可能是?、
1 数据是固定的,但我们在不断拟合更多的多项式或参数,这会导致算法开始记忆数据中的所有内容
2 由于数据是固定的,SVM不需要在很大的假设空间中搜索
1
2
1和2
二者都不对
答案:C
25. 下面关于SVM中核函数的说法正确的是?
1 核函数将低维空间中的数据映射到高维空间
2 它是一个相似度函数
1
2
1和2
以上都不对
答案:C
来看看大家答题情况的统计结果吧
结语
如果对帖子的内容有什么问题,可以在下面的评论区跟我交流。
原文标题:
25 Questions to test a Data Scientist on Support Vector Machines
原文链接:
https://www.analyticsvidhya.com/blog/2017/10/svm-skilltest/
译者简介

张逸,中国传媒大学大三在读,主修数字媒体技术。对数据科学充满好奇,感慨于它创造出来的新世界。目前正在摸索和学习中,希望自己勇敢又热烈,学最有意思的知识,交最志同道合的朋友。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织



