![]()
近日,
CMU
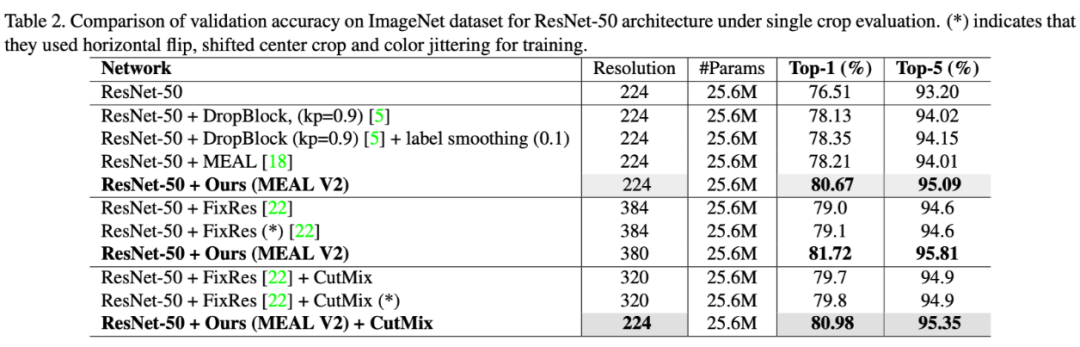
的研究人员在 arXiv 上放出了一份技术报告,介绍他们如何通过蒸馏(distillation)训练一个强大的小模型。所提出方法使用相同模型结构和输入图片大小的前提下,在 ImageNet 上的性能远超之前 state-of-the-art 的 FixRes 2.5% 以上,甚至超过了魔改结构的 ResNeSt 的结果。
这也是第一个能在不改变 ResNet-50 网络结构和不使用外部训练数据的前提下,将 ImageNet Top-1 精度提升到 80% 以上的工作,同时对训练要求也不是很高,一台 8 卡 TITAN Xp 就可以训练了。
![]()
论文标题:
MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks
论文链接:
https://arxiv.org/abs/2009.08453
代码链接:
https://github.com/szq0214/MEAL-V2
在介绍这个
工作之前,首先要简单回顾一下它的最初版本 MEAL,其基本的也是核心的思想是将多个 teacher 网络的知识通过蒸馏的方式压缩进一个 student 里面,同时它提出使用辨别器(discriminators)作为正则模块(regularization)防止 student 的输出跟 teacher 过于相像,从而防止 student 过拟合到训练集上。
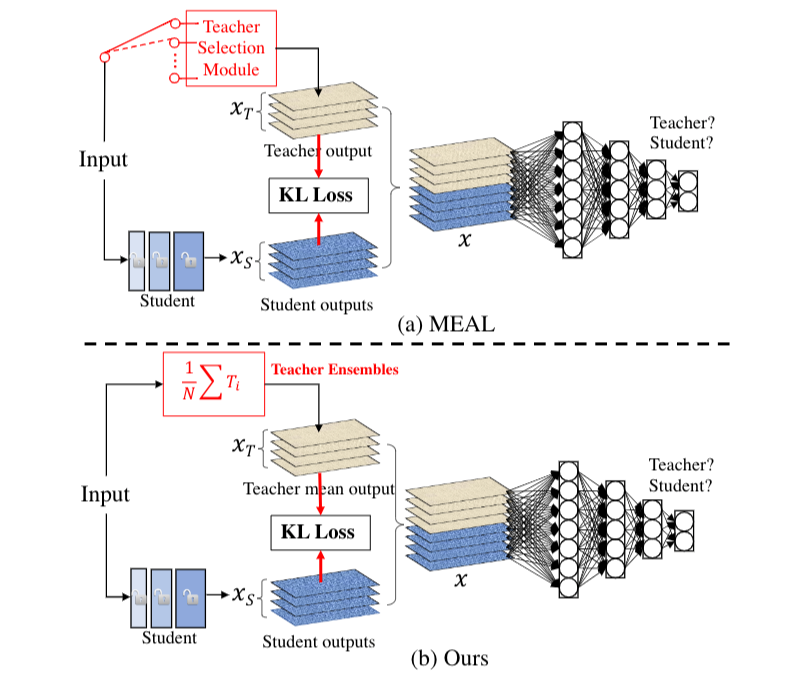
MEAL 当时在 ImageNet 上就取得了 78.21% 的结果,超过原版 ResNet-50 1.7% 个点。MEAL V2 跟 MEAL 最大的区别在于监督信号的产生方式,如下图:
![]()
具体而言,MEAL 在每次训练迭代的时候会通过一个 teacher 选择模块随机选择一个teacher产生监督信号,而在 V2 中,这个模块被替换成所有 teacher 的集成,因此每次迭代 student 接收到的监督信号将会更加强大。同时,V2 简化了 V1 里面的中间层 loss,只保留最后一个 KL-loss 和辨别器,使得整个框架变得更加简单,直观和易用。
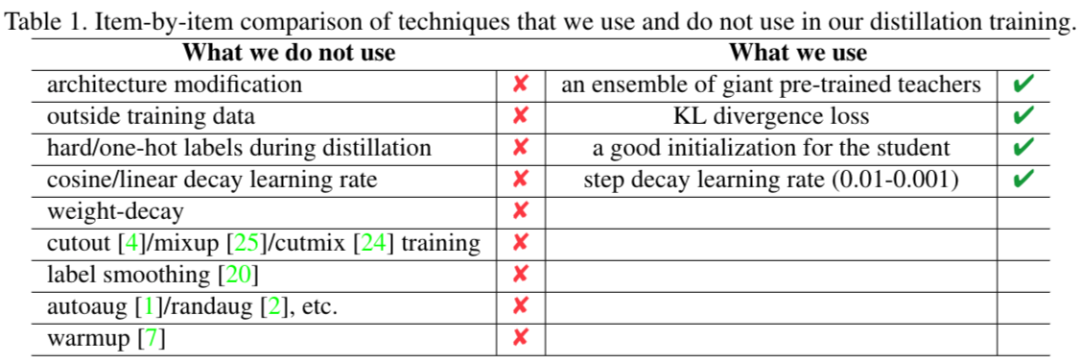
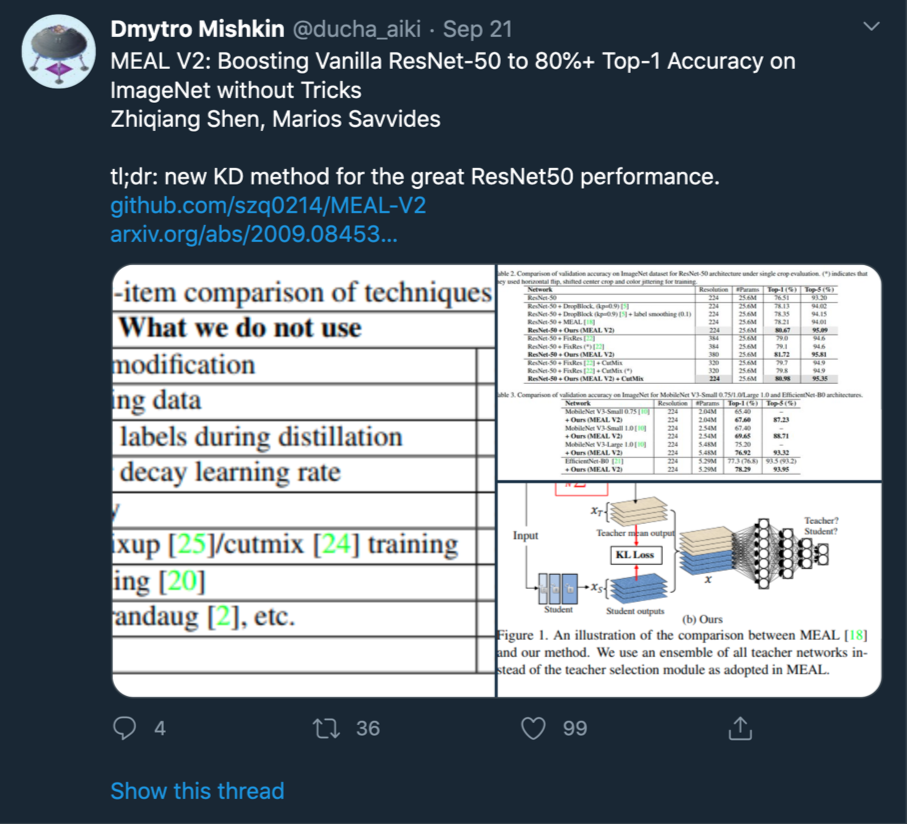
通常我们在训练网络的时候会用到很多技巧(tricks),但是在 MEAL V2 中,这些都是不需要的,作者罗列了他们使用到的和未使用到的一些训练手段,如下表格所示:
![]()
从上面表格可以看出来一些常用的数据增强和学习率调节他们都没用到,说明这个框架非常鲁棒和强大,同时也说明了这个框架其实还有很大的提升空间,比如作者进一步加入 CutMix 数据增强的方法来训练,性能得到了进一步的提升。
![]()
![]()
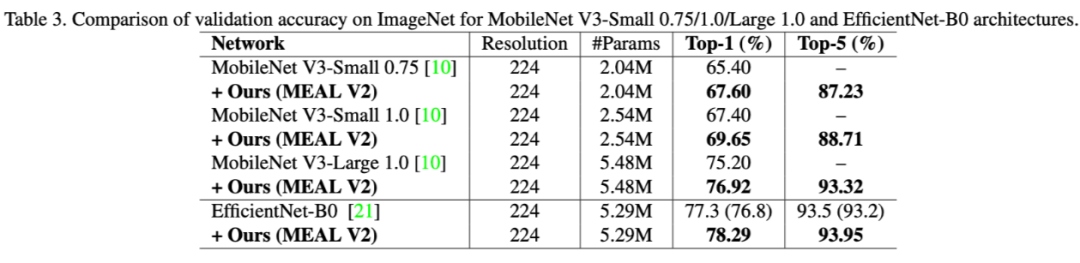
作者在论文中展示了如何提升不同网络结构的性能
,包括 MobileNet V3,EfficientNet-B0 等等,从表格 3 我们可以看到基本在这些网络上都能有 2 个点以上的提升,所以 MEAL V2 整个框架其实可以看成是一个后增强的过程,即我们可以先设计和训练一个自己的模型,然后放入 MEAL V2 的框架中进一步提升它的性能。
文章最后作者给出了一些相关的讨论,包括为什么在做蒸馏的时候不需要使用 hard label,辨别器如何帮助优化过程等等,有兴趣的同学可以去看他们的论文原文,这里就不一一赘述了。
最后我们不得不感叹一下,一个四五年前提出的 ResNet-50 网络居然还能有如此巨大的潜力,性能可以被提升到超越最近很多新设计的网络结构,作者还发现他们最强的 student 模型的性能其实跟使用的 teacher 已经非常接近了,这是一个非常神奇的地方,因为 student 的网络规模要比 teacher 小很多,但是它居然可以容纳全部 teacher 的知识(knowledge),这也是一个值得继续讨论和研究的地方。
同时我们也不得不反思一下,是否一些新设计的网络结构真的有那么大的进步和贡献,毕竟从 MEAL V2 的实验结果来看,到目前为止原生的 ResNet-50 的性能都还没有完全饱和,这也促使我们更理性、客观的去评价其他一些看上去性能很好的模型结构。
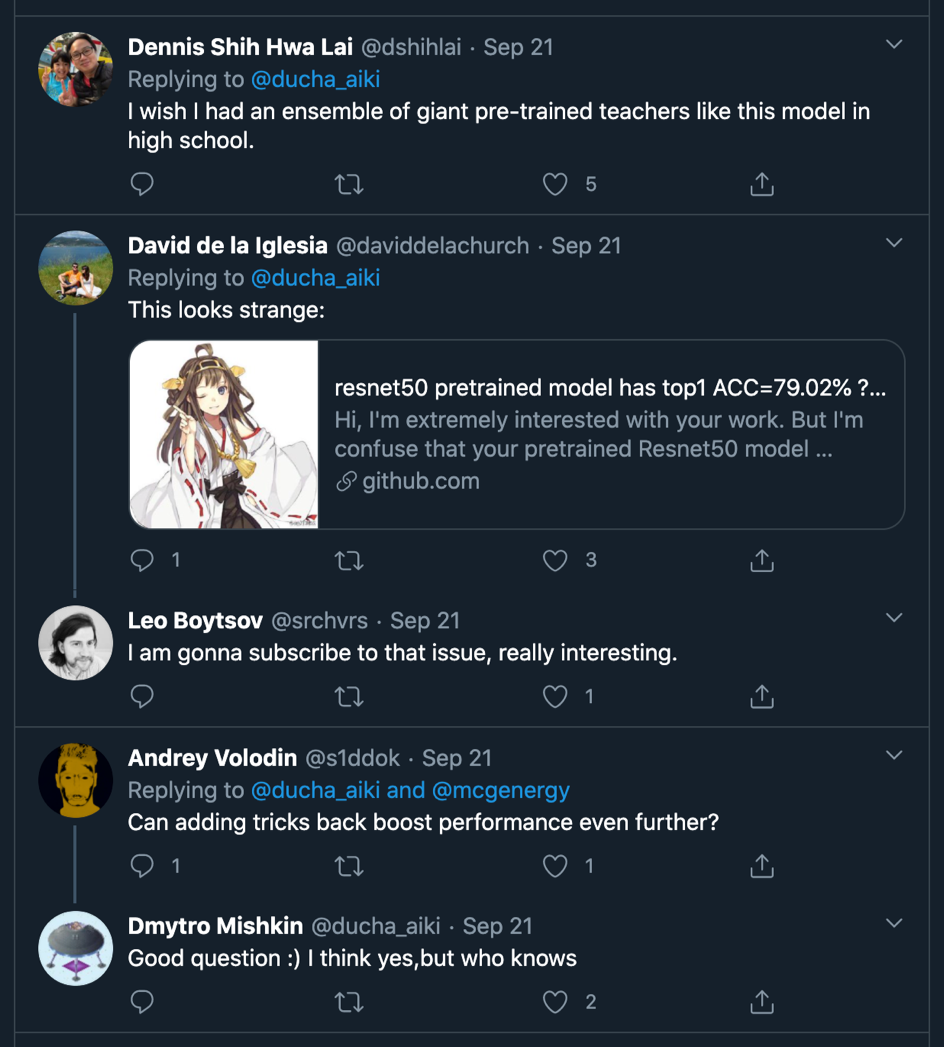
最后,Twitter 大佬 Dmytro Mishkin 也转发了这篇文章,同时还有一些有意思的讨论,关注他的人包括深度学习第四巨头 Andrew Ng,英伟达 AI 和机器学习负责人,同时也是加州理工大学教授的 Anima Anandkumar,还有 timm 库的作者 Ross Wightman 等等。
![]()
同时上面还有一些比较有意思的评论,比如有个
Twitter
网友就说 “
I wish I had an ensemble of giant pre-trained teachers like this model in high school.
” 真是太有爱了。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()