FCN 的简单实现

本文作者Sherlock,本文首发于知乎专栏【深度炼丹】,AI 研习社获其授权转载。
学习了沐神的 gluon 课程,觉得里面有关于 fcn 的课程(http://t.cn/RQI7iD7 ) 特别有用,于是总结一下,同时使用 pytorch 重新实现,不仅实现 gluon 教程中的部分,同时实现论文中更精细的形式。
介绍
语义分割是一种像素级别的处理图像方式,对比于目标检测其更加精确,能够自动从图像中划分出对象区域并识别对象区域中的类别,比如下面这个效果

上面是输入的图片,下面是希望得到的效果,也就是希望能够对区域进行像素级别的划分
在 2015 年 CVPR 的一篇论文 Fully Convolutional Networks for Semantic Segmentation(https://arxiv.org/abs/1411.4038 )这篇文章提出了全卷积的概念,第一次将端到端的卷积网络推广到了语义分割的任务当中,随后出现了很多基于 FCN 实现的网络结构,比如 U-Net 等。
数据集
首先我们需要下载数据集,这里我们使用 PASCAL VOC 数据集(http://t.cn/RQI7TCf ),其是一个正在进行的目标检测, 目标识别, 语义分割的挑战,我们可以进行数据集的下载(http://t.cn/RQI7nhr )。
下载完成数据集之后进行解压,我们可以在 ImageSets/Segmentation/train.txt 和 ImageSets/Segmentation/val.txt 中找到我们的训练集和验证集的数据,图片存放在 /JPEGImages 中,后缀是 .jpg,而 label 存放在 /SegmentationClass 中,后缀是 .png
我们可以可视化一下

首先输出图片的大小,左边就是真实的图片,右边就是分割之后的结果
然后我们定义一个函数进行图片的读入,根据 train.txt 和 val.txt 中的文件名进行图片读入,我们不需要这一步就读入图片,只需要知道图片的路径,之后根据图片名称生成 batch 的时候再读入图片,并做一些数据预处理。
voc_root = './data/VOCdevkit/VOC2012'def read_images(root=voc_root, train=True): txt_fname = root + '/ImageSets/Segmentation/' + ('train.txt' if train else 'val.txt') with open(txt_fname, 'r') as f: images = f.read().split() data = [os.path.join(root, 'JPEGImages', i+'.jpg') for i in images] label = [os.path.join(root, 'SegmentationClass', i+'.png') for i in images] return data, label
数据预处理
可能你已经注意到了前面展示的两张图片的大小是不一样的,如果我们要使用一个 batch 进行计算,我们需要图片的大小保持一致,在前面使用卷积网络进行图片分类的任务中,我们通过 resize 的办法对图片进行了缩放,使得他们的大小相同,但是这里会遇到一个问题,对于输入图片我们当然可以 resize 成任意我们想要的大小,但是 label 也是一张图片,且是在 pixel 级别上的标注,所以我们没有办法对 label 进行有效的 resize 似的其也能达到像素级别的匹配,所以为了使得输入的图片大小相同,我们就使用 crop 的方式来解决这个问题,也就是从一张图片中 crop 出固定大小的区域,然后在 label 上也做同样方式的 crop。
使用 crop 可以使用 pytorch 中自带的 transforms,不过要稍微改一下,不仅输出 crop 出来的区域,同时还要输出对应的坐标便于我们在 label 上做相同的 crop
def rand_crop(data, label, height, width): ''' data is PIL.Image object label is PIL.Image object ''' data, rect = tfs.RandomCrop((height, width))(data) label = tfs.FixedCrop(*rect)(label) return data, label
下面我们可以验证一下随机 crop

上面就是我们做两次随机 crop 的结果,可以看到图像和 label 能够完美的对应起来
接着我们根据数据知道里面有 21 中类别,同时给出每种类别对应的 RGB 值
classes = ['background','aeroplane','bicycle','bird','boat', 'bottle','bus','car','cat','chair','cow','diningtable', 'dog','horse','motorbike','person','potted plant', 'sheep','sofa','train','tv/monitor']# RGB color for each classcolormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128], [128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0], [64,128,0],[192,128,0],[64,0,128],[192,0,128], [64,128,128],[192,128,128],[0,64,0],[128,64,0], [0,192,0],[128,192,0],[0,64,128]]len(classes), len(colormap)
接着可以建立一个索引,也就是将一个类别的 RGB 值对应到一个整数上,通过这种一一对应的关系,能够将 label 图片变成一个矩阵,矩阵和原图片一样大,但是只有一个通道数,也就是 (h, w) 这种大小,里面的每个数值代表着像素的类别
cm2lbl = np.zeros(256**3) # 每个像素点有 0 ~ 255 的选择,RGB 三个通道for i,cm in enumerate(colormap): cm2lbl[(cm[0]*256+cm[1])*256+cm[2]] = i # 建立索引def image2label(im): data = np.array(im, dtype='int32') idx = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2] return np.array(cm2lbl[idx], dtype='int64') # 根据索引得到 label 矩阵
定义完成之后,我们可以验证一下
label_im = Image.open('./data/VOCdevkit/VOC2012/SegmentationClass/2007_000033.png').convert('RGB')label = image2label(label_im)label[150:160, 240:250]

array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
可以看到上面的像素点由 0 和 1 构成,0 表示背景,1 表示 飞机这个类别
接着我们可以定义数据预处理方式,之前我们读取的数据只有文件名,现在我们开始做预处理,非常简单,首先随机 crop 出固定大小的区域,然后使用 ImageNet 的均值和方差做标准化。
def img_transforms(im, label, crop_size): im, label = rand_crop(im, label, *crop_size) im_tfs = tfs.Compose([ tfs.ToTensor(), tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) ]) im = im_tfs(im) label = image2label(label) label = torch.from_numpy(label) return im, label
最后我们定义一个 COVSegDataset 继承于 `torch.utils.data.Dataset` 构成我们自定的训练集
class VOCSegDataset(Dataset): ''' voc dataset ''' def __init__(self, train, crop_size, transforms): self.crop_size = crop_size self.transforms = transforms data_list, label_list = read_images(train=train) self.data_list = self._filter(data_list) self.label_list = self._filter(label_list) print('Read ' + str(len(self.data_list)) + ' images') def _filter(self, images): # 过滤掉图片大小小于 crop 大小的图片 return [im for im in images if (Image.open(im).size[1] >= self.crop_size[0] and Image.open(im).size[0] >= self.crop_size[1])] def __getitem__(self, idx): img = self.data_list[idx] label = self.label_list[idx] img = Image.open(img) label = Image.open(label).convert('RGB') img, label = self.transforms(img, label, self.crop_size) return img, label def __len__(self): return len(self.data_list)
# 实例化数据集input_shape = (320, 480)voc_train = VOCSegDataset(True, input_shape, img_transforms)voc_test = VOCSegDataset(False, input_shape, img_transforms)train_data = DataLoader(voc_train, 64, shuffle=True, num_workers=4)valid_data = DataLoader(voc_test, 128, num_workers=4)
```
fcn 模型
fcn 模型非常简单,里面全部是由卷积构成的,所以被称为全卷积网络,同时由于全卷积的特殊形式,因此可以接受任意大小的输入,网络的示意图如下
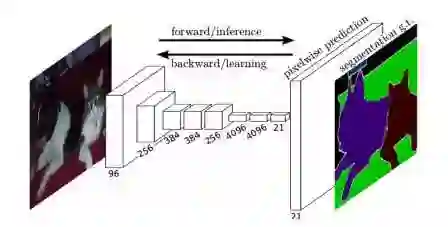
对于任何一张输入图片,由于卷积层和池化层的不断作用,得到的输出形状会越来越小,但是通道数会越来越大,比如 ResNet18,会将输入的长宽减小 32 倍,由 3x244x244 变成 512x7x7,也就是上图的第一部分,得到的特征图会特别小,最后通过一个转置卷积得到一个和输入形状一样的结果,这里我们引入了转置卷积的概念,下面我们讲一讲什么是转置卷积
转置卷积
我们首先可以看看下面的动画
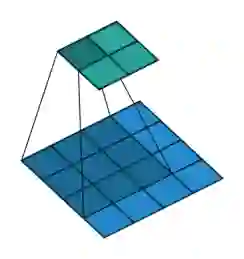
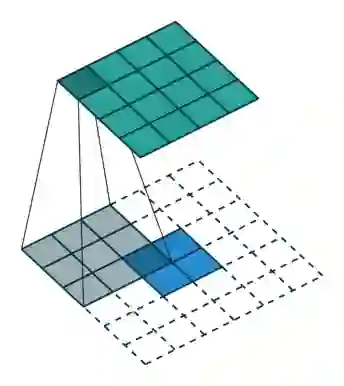
第一张就是我们常说的卷积的效果,而转置卷积就是下面这个操作,相当于卷积的逆过程,将卷积的输入和输出反过来,卷积的正向传播相当于图片左乘一个矩阵 c,反向传播相当于左乘 $c^T$,而转置卷积的正向过程相当于左乘 $c^T$,反向过程相当于左乘 $(c^T)^T = c$,详细的推导可以看看论文(https://arxiv.org/pdf/1603.07285.pdf )。
而转置卷积的计算公式也非常简单,对于卷积
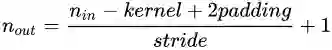
转置卷积就是将输入和输出反过来,即
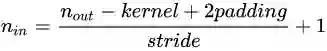
如果我们希望输出变成输入的两倍,那么 stride 取 2,kernel 和 padding 可以对应着取,比如 kernel 取 4,那么 padding 就取 1
在 pytorch 中转置卷积可以使用 torch.nn.ConvTranspose2d() 来实现,下面我们举个例子
x = torch.randn(1, 3, 120, 120)conv_trans = nn.ConvTranspose2d(3, 10, 4, stride=2, padding=1)y = conv_trans(Variable(x))print(y.shape)
torch.Size([1, 10, 240, 240])
可以看到输出变成了输入的 2 倍
模型结构
最简单的 fcn 前面是一个去掉全连接层的预训练网络,然后将去掉的全连接变为 1x1 的卷积,输出和类别数目相同的通道数,比如 voc 数据集是 21 分类,那么输出的通道数就是 21,然后最后接一个转置卷积将结果变成输入的形状大小,最后在每个 pixel 上做一个分类问题,使用交叉熵作为损失函数就可以了。
当然这样的模型是特别粗糙的,因为最后一步直接将图片扩大了 32 倍,所以论文中有一个改进,就是将网络中间的输入联合起来进行转置卷积,这样能够依赖更多的信息,所以可以得到更好的结果,可以看看下面的图示
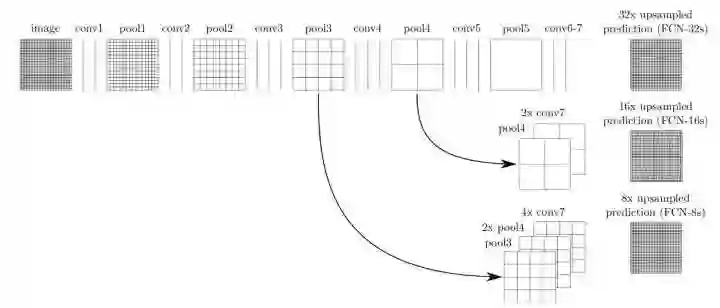
fcn-32s 就是直接将最后的结果通过转置卷积扩大 32 倍进行输出,而 fcn-16x 就是联合前面一次的结果进行 16 倍的输出,fcn-8x 就是联合前面两次的结果进行 8 倍的输出,我们用上图中 fcn-8x 举例,就是先将最后的结果通过转置卷积扩大 2 倍,然后和 pool4 的结果相加,然后在通过转置卷积扩大 2 倍,然后和 pool3 的结果相加,最后通过转置卷积扩大 8 倍得到和输入形状一样大的结果。
bilinear kernel
通常我们训练的时候可以随机初始化权重,但是在 fcn 的网络中,使用随机初始化的权重将会需要大量的时间进行训练,所以我们卷积层可以使用在 imagenet 上预训练的权重,那么转置卷积我们使用什么样的初始权重呢?这里就要用到 bilinear kernel。
我们可以看看下面的例子
# 定义 bilinear kerneldef bilinear_kernel(in_channels, out_channels, kernel_size): ''' return a bilinear filter tensor ''' factor = (kernel_size + 1) // 2 if kernel_size % 2 == 1: center = factor - 1 else: center = factor - 0.5 og = np.ogrid[:kernel_size, :kernel_size] filt = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor) weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype='float32') weight[range(in_channels), range(out_channels), :, :] = filt return torch.from_numpy(weight)x = Image.open('./data/VOCdevkit/VOC2012/JPEGImages/2007_005210.jpg')x = np.array(x)plt.imshow(x)print(x.shape)
(281, 500, 3)

x = torch.from_numpy(x.astype('float32')).permute(2, 0, 1).unsqueeze(0)# 定义转置卷积conv_trans = nn.ConvTranspose2d(3, 3, 4, 2, 1)# 将其定义为 bilinear kernelconv_trans.weight.data = bilinear_kernel(3, 3, 4)y = conv_trans(Variable(x)).data.squeeze().permute(1, 2, 0).numpy()plt.imshow(y.astype('uint8'))print(y.shape)
(562, 1000, 3)

可以看到通过双线性的 kernel 进行转置卷积,图片的大小扩大了一倍,但是图片看上去仍然非常的清楚,所以这种方式的上采样具有很好的效果
下面我们使用 resnet 34 代替论文中的 vgg 实现 fcn
# 使用预训练的 resnet 34pretrained_net = model_zoo.resnet34(pretrained=True)num_classes = len(classes)
这里我们去掉最后的 avgpool 和 fc 层,使用 list(pretrained_net.children())[:-2] 就能够取到倒数第三层
下面我们开始定义我们的网络结构,就像上面显示的一样,我们会取出最后的三个结果进行合并
class fcn(nn.Module): def __init__(self, num_classes): super(fcn, self).__init__() self.stage1 = nn.Sequential(*list(pretrained_net.children())[:-4]) # 第一段 self.stage2 = list(pretrained_net.children())[-4] # 第二段 self.stage3 = list(pretrained_net.children())[-3] # 第三段 self.scores1 = nn.Conv2d(512, num_classes, 1) self.scores2 = nn.Conv2d(256, num_classes, 1) self.scores3 = nn.Conv2d(128, num_classes, 1) self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False) self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16) # 使用双线性 kernel self.upsample_4x = nn.ConvTranspose2d(num_classes, num_classes, 4, 2, 1, bias=False) self.upsample_4x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用双线性 kernel self.upsample_2x = nn.ConvTranspose2d(num_classes, num_classes, 4, 2, 1, bias=False) self.upsample_2x.weight.data = bilinear_kernel(num_classes, num_classes, 4) # 使用双线性 kernel def forward(self, x): x = self.stage1(x) s1 = x # 1/8 x = self.stage2(x) s2 = x # 1/16 x = self.stage3(x) s3 = x # 1/32 s3 = self.scores1(s3) s3 = self.upsample_2x(s3) s2 = self.scores2(s2) s2 = s2 + s3 s1 = self.scores3(s1) s2 = self.upsample_4x(s2) s = s1 + s2 s = self.upsample_8x(s2) return s
接着我们定义一些语义分割常用的指标,比如 overal accuracy,mean IU 等等,下面这个是参考 wkentaro 的 pytorch-fcn(http://t.cn/RQIZIH8 ) 得到的
def _fast_hist(label_true, label_pred, n_class): mask = (label_true >= 0) & (label_true < n_class) hist = np.bincount( n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class) return histdef label_accuracy_score(label_trues, label_preds, n_class): """Returns accuracy score evaluation result. - overall accuracy - mean accuracy - mean IU - fwavacc """ hist = np.zeros((n_class, n_class)) for lt, lp in zip(label_trues, label_preds): hist += _fast_hist(lt.flatten(), lp.flatten(), n_class) acc = np.diag(hist).sum() / hist.sum() acc_cls = np.diag(hist) / hist.sum(axis=1) acc_cls = np.nanmean(acc_cls) iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)) mean_iu = np.nanmean(iu) freq = hist.sum(axis=1) / hist.sum() fwavacc = (freq[freq > 0] * iu[freq > 0]).sum() return acc, acc_cls, mean_iu, fwavacc
然后我们定义 loss,这里使用 torch.nn.NLLLoss2d(),其实这和交叉熵一样,都是处理分类问题的 loss,只是这个 loss 需要在最后一层输出加上 torch.nn.functional.log_softmax,但是这个 loss 可以作用在 2d 的输出上,于是我们就选择这个 loss
# 定义 loss 和 optimizerfrom mxtorch.trainer import ScheduledOptimcriterion = nn.NLLLoss2d()basic_optim = torch.optim.SGD(net.parameters(), lr=1e-2, weight_decay=1e-4)optimizer = ScheduledOptim(basic_optim)
训练
for e in range(80): if e > 0 and e % 50 == 0: optimizer.set_learning_rate(optimizer.learning_rate * 0.1) train_loss = 0 train_acc = 0 train_acc_cls = 0 train_mean_iu = 0 train_fwavacc = 0 prev_time = datetime.now() net = net.train() for data in train_data: im = Variable(data[0].cuda()) label = Variable(data[1].cuda()) # forward out = net(im) out = F.log_softmax(out, dim=1) # (b, n, h, w) loss = criterion(out, label) # backward optimizer.zero_grad() loss.backward() optimizer.step() train_loss += loss.data[0] label_pred = out.max(dim=1)[1].data.cpu().numpy() label_true = label.data.cpu().numpy() for lbt, lbp in zip(label_true, label_pred): acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes) train_acc += acc train_acc_cls += acc_cls train_mean_iu += mean_iu train_fwavacc += fwavacc net = net.eval() eval_loss = 0 eval_acc = 0 eval_acc_cls = 0 eval_mean_iu = 0 eval_fwavacc = 0 for data in valid_data: im = Variable(data[0].cuda(), volatile=True) label = Variable(data[1].cuda(), volatile=True) # forward out = net(im) out = F.log_softmax(out, dim=1) loss = criterion(out, label) eval_loss += loss.data[0] label_pred = out.max(dim=1)[1].data.cpu().numpy() label_true = label.data.cpu().numpy() for lbt, lbp in zip(label_true, label_pred): acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes) eval_acc += acc eval_acc_cls += acc_cls eval_mean_iu += mean_iu eval_fwavacc += fwavacc cur_time = datetime.now() h, remainder = divmod((cur_time - prev_time).seconds, 3600) m, s = divmod(remainder, 60) epoch_str = ('Epoch: {}, Train Loss: {:.5f}, Train Acc: {:.5f}, Train Mean IU: {:.5f}, \Valid Loss: {:.5f}, Valid Acc: {:.5f}, Valid Mean IU: {:.5f} '.format( e, train_loss / len(train_data), train_acc / len(voc_train), train_mean_iu / len(voc_train), eval_loss / len(valid_data), eval_acc / len(voc_test), eval_mean_iu / len(voc_test))) time_str = 'Time: {:.0f}:{:.0f}:{:.0f}'.format(h, m, s) print(epoch_str + time_str + ' lr: {}'.format(optimizer.learning_rate))
Epoch: 77, Train Loss: 0.23017, Train Acc: 0.92420, Train Mean IU: 0.64684, Valid Loss: 0.39680, Valid Acc: 0.87509, Valid Mean IU: 0.53005 Time: 0:0:41 lr: 0.001 Epoch: 78, Train Loss: 0.23212, Train Acc: 0.92334, Train Mean IU: 0.64237, Valid Loss: 0.39651, Valid Acc: 0.87538, Valid Mean IU: 0.52885 Time: 0:0:41 lr: 0.001 Epoch: 79, Train Loss: 0.23251, Train Acc: 0.92364, Train Mean IU: 0.64002, Valid Loss: 0.39242, Valid Acc: 0.87575, Valid Mean IU: 0.53311 Time: 0:0:41 lr: 0.001
可以看到,我们的模型在训练集上的 mean IU 达到了 0.64 左右,验证集上的 mean IU 达到了 0.53 左右,下面我们可视化一下最后的结果
# 定义预测函数cm = np.array(colormap).astype('uint8')def predict(im, label): # 预测结果 im = Variable(im.unsqueeze(0)).cuda() out = net(im) pred = out.max(1)[1].squeeze().cpu().data.numpy() pred = cm[pred] return pred, cm[label.numpy()]_, figs = plt.subplots(6, 3, figsize=(12, 10))for i in range(6): test_data, test_label = voc_test[i] pred, label = predict(test_data, test_label) figs[i, 0].imshow(Image.open(voc_test.data_list[i])) figs[i, 0].axes.get_xaxis().set_visible(False) figs[i, 0].axes.get_yaxis().set_visible(False) figs[i, 1].imshow(label) figs[i, 1].axes.get_xaxis().set_visible(False) figs[i, 1].axes.get_yaxis().set_visible(False) figs[i, 2].imshow(pred) figs[i, 2].axes.get_xaxis().set_visible(False) figs[i, 2].axes.get_yaxis().set_visible(False)

可以看到,通过训练,模型已经有了基本效果,但是离论文中的效果有差距,有可能是训练的问题,更多的原因应该是没有使用 caffe model 中的 vgg 模型,这里特别提醒一下,如果要使用 caffe model,那么图像预处理的时候要是 BRG 的格式,同时大小是 0 ~ 255,减去均值。
另外代码中使用的 mxtorch 可以在我的 github 主页看到:http://t.cn/RQIZlDB。

CCF ADL 系列又一诚意课程
两位全球计算机领域 Top 10 大神加盟
——韩家炜 & Philip S Yu
共 13 位专家,覆盖计算机学科研究热点
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
CNN 中千奇百怪的卷积方式大汇总
▼▼▼



