一步一步带你用TensorFlow玩转LSTM
全球人工智能:一家人工智能技术学习平台。旗下有:Paper学院、商业学院、科普学院,技术学院和职业学院五大业务。拥有十几万AI开发者和学习者用户,1万多名AI技术专家。
LSTM,全称为长短期记忆网络(Long Short Term Memory networks),是一种特殊的RNN,能够学习到长期依赖关系。LSTM由Hochreiter & Schmidhuber (1997)提出,许多研究者进行了一系列的工作对其改进并使之发扬光大。
了解LSTM请前往——LSTM的“前生今世”
LSTM在解决许多问题上效果非常好,现在被广泛使用。它们主要用于处理序列数据。这个博客的主要目的是让读者了解在TensorFlow中,如何实现基本的LSTM网络并掌握实现的细节。为了实现这一目标,我们把MNIST作为我们的数据集。
MNIST数据集:
MNIST数据集由手写数字及其相应标签的图像组成。我们可以借助TensorFlow的内置功能下载和读取数据:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)数据分为三部分:
训练数据(mnist.train)-55000个图像的训练数据。
测试数据(mnist.test)-10000个图像的测试数据。
验证数据(mnist.validation)-5000个图像的验证数据。
数据形状:
接下来我们介绍一下MNIST数据集的训练数据的形状。
训练集包括55000个28×28像素的图像。这些784(28X28)像素值以单个维度向量的形式被平坦化。所有这样的55000个像素向量(每个图像一个)的集合被存储为numpy阵列的形式(55000,784),并被称为mnist.train.images。
这些55000个训练图像中的每一个与表示该图像属于的类的标签相关联。一共有10个这样的类(0,1,2 ... 9)。标签以一种热编码形式的表示。因此标签被存储为numpy形状阵列的形式(55000,10)被称为mnist.train.labels。
为什么是MNIST?
LSTM通常用于解决复杂序列的相关问题,如NLP领域的实验:语言建模、字嵌入,编码器等。MNIST给了我们解决这类问题的机会。这里的输入数据只是一组像素值。我们可以轻松地格式化这些值,并集中应用到问题细节上。
实现
在我们没有展示代码之前,让我们先来看一下这个实验的实现方式。这会使编码部分更加容易理解。
A vanilla RNN
经常性的神经网络,通过时间展开,一般可以被图像化视为:
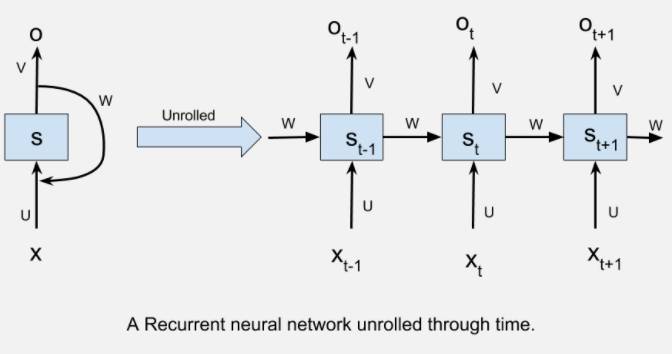
1.Xt是指时间步长t的输入。
2.St是指时间步长t处的隐藏状态。它可以被可视化为网络的“内存”。
3.Ot指的是输出在时间步长t。
4.U,V和W是所有时间步长共享的参数。该参数共享的意义在于,我们的模型在不同输入的时间步长可以执行相同的任务。
我们通过展开RNN想要介绍的是,在每个时间步骤中,网络可以被视为前馈网络,同时要考虑到前一个时间步长的输出(由时间步长之间的连接表示)。
两个警告:
我们的实现将取决于两个主要概念。
1.TensorFlow中LSTM细胞的解释。
2.将输入格式化,然后将其输入到TensorFlow RNNs中。
TensorFlow中LSTM细胞的解释:
基本的LSTM细胞单元在TensorFlow中声明为:
tf.contrib.rnn.BasicLSTMCell(num_units)
这里的num_units指的是LSTM单元中的单位数。
num_units也可以解释为前馈神经网络隐藏层的类比。前馈神经网络隐层中的节点num_units数目等于LSTM网络每个时间步长的LSTM单元的数量。以下图片应该可以帮助你理解:
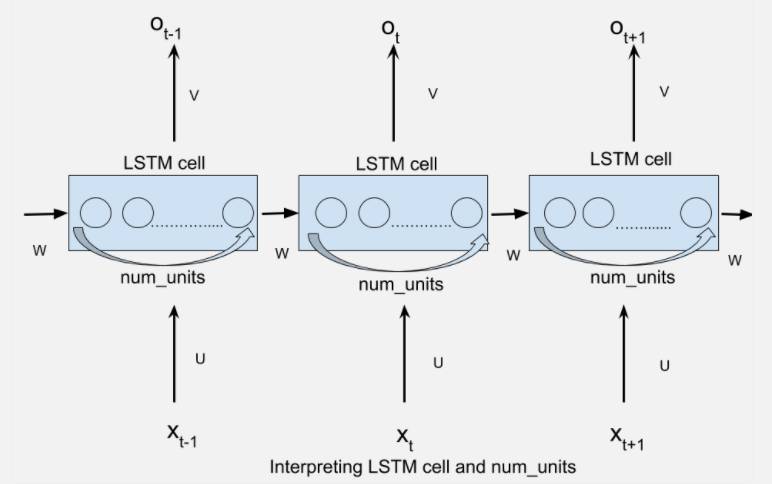
每个num_units,LSTM网络都可以将它看作是一个标准的LSTM单元。
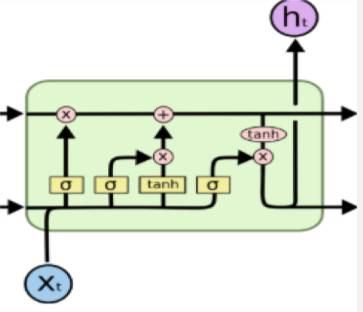
上图是从文章开头的博客中得到,它精准的描述了LSTM的概念。
将输入格式化,然后将其输入到TensorFlow RNNs中
张量流(tensorflow)中最简单的RNN形式是在static_rnn中定义:
tf.static_rnn(cell,inputs)
当然还有其他形式的定义方法,这里我们只需要用到最简单的定义方法。
该inputs参数是为了接受形状张量列表[batch_size,input_size]。该列表的长度是网络展开的时间步长数,即该列表的每个元素对应于我们展开网络的相应时间步长的输入。
对于我们的MNIST图像的情况,我们有大小为28X28的图像。它们可以被推断为具有28行28像素的图像。我们将通过28个时间步骤展开我们的网络,使得在每个时间步长,我们可以输入一行28像素(input_size),从而通过28个时间步长输入完整的图像。如果我们提供batch_size图像的数量,每个时间步长将提供相应的batch_size图像行。下图应该可以解释上述描述:
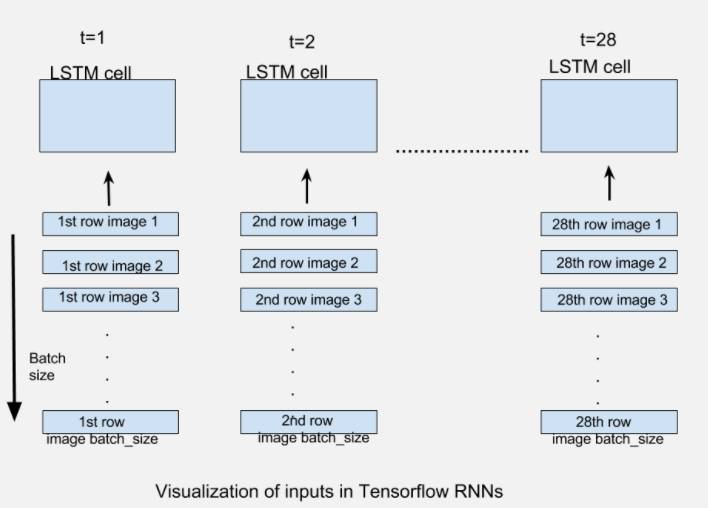
生成的输出static_rnn是形状的张量列表[batch_size,n_hidden]。列表的长度是网络展开的时间步长数,即每个时间步长的一个输出张量。在这个实现中,我们将只关注最后时间的输出,当图像的所有行被提供给RNN时,即在最后时间步长将产生预测。
我们已经准备好编写代码了。如果一旦上述概念很清楚,编写部分很简单。
Code
首先,可以导入必需的依赖项、数据集并声明一些常量。我们将使用batch_size=128和num_units=128。
import tensorflow as tf
from tensorflow.contrib import rnn#import mnist datasetfrom tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("/tmp/data/",one_hot=True)#define constants#unrolled through 28 time stepstime_steps=28#hidden LSTM unitsnum_units=128#rows of 28 pixelsn_input=28#learning rate for adamlearning_rate=0.001#mnist is meant to be classified in 10 classes(0-9).n_classes=10#size of batchbatch_size=128现在让我们来声明将其用于形状的输出转换占位符和权重及偏置变量[batch_size,num_units],[batch_size,n_classes]。
#weights and biases of appropriate shape to accomplish above task
out_weights=tf.Variable(tf.random_normal([num_units,n_classes]))
out_bias=tf.Variable(tf.random_normal([n_classes]))
#defining placeholders
#input image placeholder
x=tf.placeholder("float",[None,time_steps,n_input])
#input label placeholder
y=tf.placeholder("float",[None,n_classes])我们正在接收形状的输入[batch_size,time_steps,n_input],我们需要将其转换成长度形状[batch_size,n_inputs]的张量列表,time_steps是以便它可以被馈送到static_rnn。
#processing the input tensor from [batch_size,n_steps,n_input] to "time_steps" number of [batch_size,n_input] tensors
input=tf.unstack(x ,time_steps,1)现在我们准备定义我们的网络。我们将使用一层BasicLSTMCell,使我们的static_rnn网络脱颖而出。
#defining the network
lstm_layer=rnn.BasicLSTMCell(n_hidden,forget_bias=1)
outputs,_=rnn.static_rnn(lstm_layer,input,dtype="float32")由于我们要的是预测的结果,所以我们只考虑最后一步的输入。
#converting last output of dimension [batch_size,num_units] to [batch_size,n_classes] by out_weight multiplication
prediction=tf.matmul(outputs[-1],out_weights)+out_bias定义损失、优化器和准确性。
#loss_function
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))
#optimization
opt=tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(loss)
#model evaluation
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))现在我们已经定义了图,我们可以运行它。
#initialize variables
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
iter=1
while iter<800:
batch_x,batch_y=mnist.train.next_batch(batch_size=batch_size)
batch_x=batch_x.reshape((batch_size,time_steps,n_input))
sess.run(opt, feed_dict={x: batch_x, y: batch_y})
if iter %10==0:
acc=sess.run(accuracy,feed_dict={x:batch_x,y:batch_y})
los=sess.run(loss,feed_dict={x:batch_x,y:batch_y})
print("For iter ",iter)
print("Accuracy ",acc)
print("Loss ",los)
print("__________________")
iter=iter+1这里要注意的一个关键点,我们的图像基本上是被平坦化为一个单一的维度矢量784。函数next_batch(batch_size)必然返回batch_size为784维度向量的批次,因此它们被重塑为[batch_size,time_steps,n_input]可以被占位符接受。
我们还可以计算我们的模型的测试精度:
#calculating test accuracy
test_data = mnist.test.images[:128].reshape((-1, time_steps, n_input))
test_label = mnist.test.labels[:128]
print("Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label}))运行时,模型运行测试精度为99.21%。
这个博客目的是让读者对张量流中RNN的实现细节有所了解。以便我们建立了一些更复杂的模型,以有效地在张量流中使用RNN。
《全球人工智能》开始招人啦!
招聘职位:1名中文编辑(深圳),1名英文编译(深圳),1名课程规划(深圳),4名导师管理(深圳),10名渠道商务 简历发送:mike.yu@aisdk.com







