用TensorFlow开发问答系统
一个问答系统是被设计用来回答用自然语言提出的问题的系统。一些问答系统从诸如文本和图片这样的“源”里获得信息来回答特定的问题。这些依赖“源”的系统可以基本被分为两类:开放话题的,它需要回答的可能是任何问题,不限于特定的领域;特定话题的,它回答的问题是有特定限制的,因为它们是与一些预先定义的“源”相关,比如有给定上下文或是特定领域(如医学等)。
这篇博文会带领你完成一个使用TensorFlow来创建和开发问答系统的任务。我们会构建一个基于神经网络的问答系统,并基于一个特定话题的源信息。为了完成这个任务,我们会使用一个简化版的叫做动态记忆网络(Dynamic Memory Network,DMN)的模型。这个模型是Kumar等人在他们的论文《Ask Me Anything: Dynamic Memory Networks for Natural Language Processing》里给出的。
开始前的准备工作
除了要安装Python 3.0版本和TensorFlow 1.2版以外,确保你还安装了下面这些软件和Python库:
Jupyter
Numpy
Matplotlib
你也可以选择性地安装TQDM来观看训练过程并得到训练速度指标,但这不是必须的。这篇文章里的代码和Jupyter Notebook文件都可以在GitHub里找到。我建议你把它们下载下来并使用。如果这是你第一次使用TensorFlow,我建议你先看看Aaron Shumacher的《Hello, TensorFlow》这篇文章来对什么是TensorFlow以及它是如何运作的获得一个初步的概念。如果这是你第一次使用TensorFlow来解决自然语言的问题,我也会建议你先看看《Textual Entailment with TensorFlow》这篇文章。因为它里面介绍了一些对本文里构建神经网络有帮助的概念。
让我们首先导入所有的相关的库:
%matplotlib inline
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import urllib
import sys
import os
import zipfile
import tarfile
import json
import hashlib
import re
import itertools
探索bAbI数据集
对于这个项目,我们将会使用由Facebook构建的bAbI数据集。与所有的问答数据集类似,这个数据集里包括了问题。bAbI数据集里的问题都非常直接明了,尽管有些比别的要难一点。这个数据集里的所有问题都有相关的上下文,即一些句子。这些句子里面肯定包括了回答问题所需要的细节。另外,这个数据集也会提供每个问题的正确答案。
基于回答问题所需要的技能,bAbI数据集里的问题被分成了20类任务。每种任务都有它自己的用于训练的问题和测试的问题。这些任务测试了多种标准的自然语言处理的能力,包括时间的推理(任务#14)和归纳逻辑(任务#16)。为了能对这些任务有更好的理解,让我们看一个我们的问答系统将需要回答的问题。如图1所示。

图1. bAbI数据集里的一个例子。上下文在蓝色框内,问题在金色框内,答案在绿色框内。来源:Steven Hewitt
这个#5号里面的任务要测试神经网络理解三个对象之间动作的关系的能力。语法上讲,这个任务是在测试问答系统是否能区分主语、直接宾语和间接宾语。在这个例子里,问题问的是最后一个句子里的间接宾语,即谁从Jeff手里接收了牛奶。神经网络必须能找出Bill是主语而Jeff是间接宾语所在的第五个句子,和Jeff是主语的第六个句子。当然我们的神经网络没有得到任何明确的训练来找到什么是主语或宾语,而是必须通过训练数据里的例子来推测出这个理解。
另外一个系统必须解决的小问题就是数据集里的各种同义词。Jeff把牛奶“递给”Bill,但他也可以是简单地“给”或是“交”给Bill。考虑这些,我们的神经网络并不是从零创建的,它会得到词向量的帮助。词向量会存储对词的定义以及词与词之间的关系。类似的词有相似的向量,这意味着神经网络可以认为它们是相同的词。我们会使用Stanford大学的GloVe词向量库。关于这个部分,我在之前的这篇文章里有更详细的介绍。
大部分任务都有限制,要求上下文里包含能回答问题的确切文字。在我们上面的例子里,答案“Bill”就可以在上下文里找到。我们会利用这一限制,从而在上下文里搜索和我们最终结果意思最相近的词。
注意:下载和解压缩数据可能会需要几分钟。因此尽早运行下面三段代码来开始。这些代码会下载bAbI和GloVe数据,并从中解压出需要的文件来用于我们的神经网络。
glove_zip_file = “glove.6B.zip”
glove_vectors_file = “glove.6B.50d.txt”
# 15 MB
data_set_zip = “tasks_1-20_v1-2.tar.gz”
#Select “task 5”
train_set_file = “qa5_three-arg-relations_train.txt”
test_set_file = “qa5_three-arg-relations_test.txt”
train_set_post_file = “tasks_1-20_v1-2/en/”+train_set_file
test_set_post_file = “tasks_1-20_v1-2/en/”+test_set_file
try: from urllib.request import urlretrieve, urlopen
except ImportError:
from urllib import urlretrieve
from urllib2 import urlopen
#large file – 862 MB
if (not os.path.isfile(glove_zip_file) and
not os.path.isfile(glove_vectors_file)):
urlretrieve (“http://nlp.stanford.edu/data/glove.6B.zip”,
glove_zip_file)
if (not os.path.isfile(data_set_zip) and
not (os.path.isfile(train_set_file) and os.path.isfile(test_set_file))):
urlretrieve (“https://s3.amazonaws.com/text-datasets/babi_tasks_1-20_v1-2.tar.gz”,
data_set_zip)
def unzip_single_file(zip_file_name, output_file_name):
“””
If the output file is already created, don’t recreate
If the output file does not exist, create it from the zipFile
“””
if not os.path.isfile(output_file_name):
with open(output_file_name, ‘wb’) as out_file:
with zipfile.ZipFile(zip_file_name) as zipped:
for info in zipped.infolist():
if output_file_name in info.filename:
with zipped.open(info) as requested_file:
out_file.write(requested_file.read())
return
def targz_unzip_single_file(zip_file_name, output_file_name, interior_relative_path):
if not os.path.isfile(output_file_name):
with tarfile.open(zip_file_name) as un_zipped:
un_zipped.extract(interior_relative_path+output_file_name)
unzip_single_file(glove_zip_file, glove_vectors_file)
targz_unzip_single_file(data_set_zip, train_set_file, “tasks_1-20_v1-2/en/”)
targz_unzip_single_file(data_set_zip, test_set_file, “tasks_1-20_v1-2/en/”)
解析GloVe和处理未知的词条
在《Textual Entailment with TensorFlow》里,我介绍了sentence2sequence函数。这是一个基于GloVe定义的映射把字符串转换成矩阵的功能。它把字符串分成词条。这些词条是更小的词片段,大致类似于标点、词或词的一部分。例如“Bill traveled to the kitchen.”里包含6个词条,对应于5个单词和最后的那个句号。每个词条独立地被向量化,就形成了和这个句子相对应的向量列表。如图2所示。
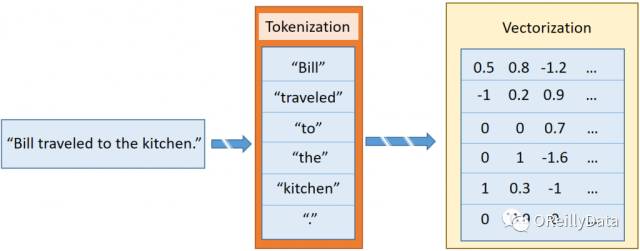
图2 把句子变成多个向量的过程。来源:Steven Hewitt
在bAbI的一些任务里,问答系统将会碰到GloVe的词向量化里没有的词。为了让我们的神经网络能处理这些未知的词条,我们需要维护一个这些词的一致的向量。常见的动作是把所有的这些未知词条替换成一个单一的<UNK>向量,但这并不总是有效。这里,我们使用随机化的方法来为每一个未知的词条新建一个向量。
当我们首次碰到一个未知的词条,我们就从最初的GloVe向量化的分布(近似高斯分布)里获取一个新的向量,然后把这个向量放回到GloVe的词映射里。想获得分布的超参数,Numpy有可以自动计算方差和均值的函数。
下面的fill_unk函数会在我们需要时给出一个新的词向量。
# Deserialize GloVe vectors
glove_wordmap = {}
with open(glove_vectors_file, “r”, encoding=”utf8″) as glove:
for line in glove:
name, vector = tuple(line.split(” “, 1))
glove_wordmap[name] = np.fromstring(vector, sep=” “)
wvecs = []
for item in glove_wordmap.items():
wvecs.append(item[1])
s = np.vstack(wvecs)
# Gather the distribution hyperparameters
v = np.var(s,0)
m = np.mean(s,0)
RS = np.random.RandomState()
def fill_unk(unk):
global glove_wordmap
glove_wordmap[unk] = RS.multivariate_normal(m,np.diag(v))
return glove_wordmap[unk]
已知还是未知
bAbI任务里有限的词汇表意味着我们的神经网络即使在不知道词的意思的情况下也可以学习词之间的关系。不过,为了加快学习的速度,我们会尽量选择有意思的向量。为了实现它,我们使用贪婪搜素策略,查找Stanford的GloVe词向量数据集里已经存在的词。如果不存在,则把整个词用一个未知的随机生成的新的向量表示替换掉。
使用这一词向量的模型,我们可以定义新的sentence2sequence函数:
def sentence2sequence(sentence):
“””
– Turns an input paragraph into an (m,d) matrix,
where n is the number of tokens in the sentence
and d is the number of dimensions each word vector has.
TensorFlow doesn’t need to be used here, as simply
turning the sentence into a sequence based off our
mapping does not need the computational power that
TensorFlow provides. Normal Python suffices for this task.
“””
tokens = sentence.strip(‘”(),-‘).lower().split(” “)
rows = []
words = []
#Greedy search for tokens
for token in tokens:
i = len(token)
while len(token) > 0:
word = token[:i]
if word in glove_wordmap:
rows.append(glove_wordmap[word])
words.append(word)
token = token[i:]
i = len(token)
continue
else:
i = i-1
if i == 0:
# word OOV
# https://arxiv.org/pdf/1611.01436.pdf
rows.append(fill_unk(token))
words.append(token)
break
return np.array(rows), words
现在我们可以把每个问题需要的数据给打包起来了,包括上下文、问题和答案的词向量。在bAbI里,上下文被我们定义成了带有序号的句子。用contextualize函数可以完成这个任务。问题和答案都在同一行里,用tab符分割开。因此在一行里我们可以使用tab符作为区分问题和答案的标记。当序号被重置后,未来的问题将会指向是新的上下文(注意:通常对于一个上下文会有多个问题)。答案里还有另外一个我们会保留下来但不用的信息:答案对应的句子的序号。在我们的系统里,神经网络将会自己学习用来回答问题的句子。
def contextualize(set_file):
“””
Read in the dataset of questions and build question+answer -> context sets.
Output is a list of data points, each of which is a 7-element tuple containing:
The sentences in the context in vectorized form.
The sentences in the context as a list of string tokens.
The question in vectorized form.
The question as a list of string tokens.
The answer in vectorized form.
The answer as a list of string tokens.
A list of numbers for supporting statements, which is currently unused.
“””
data = []
context = []
with open(set_file, “r”, encoding=”utf8″) as train:
for line in train:
l, ine = tuple(line.split(” “, 1))
# Split the line numbers from the sentences they refer to.
if l is “1”:
# New contexts always start with 1,
# so this is a signal to reset the context.
context = []
if “\t” in ine:
# Tabs are the separator between questions and answers,
# and are not present in context statements.
question, answer, support = tuple(ine.split(“\t”))
data.append((tuple(zip(*context))+
sentence2sequence(question)+
sentence2sequence(answer)+
([int(s) for s in support.split()],)))
# Multiple questions may refer to the same context, so we don’t reset it.
else:
# Context sentence.
context.append(sentence2sequence(ine[:-1]))
return data
train_data = contextualize(train_set_post_file)
test_data = contextualize(test_set_post_file)
final_train_data = []
def finalize(data):
“””
Prepares data generated by contextualize() for use in the network.
“””
final_data = []
for cqas in train_data:
contextvs, contextws, qvs, qws, avs, aws, spt = cqas
lengths = itertools.accumulate(len(cvec) for cvec in contextvs)
context_vec = np.concatenate(contextvs)
context_words = sum(contextws,[])
# Location markers for the beginnings of new sentences.
sentence_ends = np.array(list(lengths))
final_data.append((context_vec, sentence_ends, qvs, spt, context_words, cqas, avs, aws))
return np.array(final_data)
final_train_data = finalize(train_data)
final_test_data = finalize(test_data)
定义超参数
到这里,我们已经完全准备好了所需的训练和测试数据。下面的任务就是构建用来理解数据的神经网络。让我们从清除TensorFlow的默认计算图开始,从而能让我们在修改了一些东西后再次运行网络。
tf.reset_default_graph()
这里是网络的开始,因此让我们在这里定义所有需要的常量。我们叫它们“超参数”,因为它们定义了网络的结构和训练的方法。
转自:OReillyData
完整内容请点击“阅读原文”