【干货】利用NLTK和Gensim进行主题建模(附完整代码)
【导读】在这篇文章中,我们将学习如何辨别出一个文档到底在讨论什么主题,我们称之为主题建模。文中将包括潜在Dirichlet分布(LDA):一种广泛使用的主题建模技术,并应用LDA将研究论文集转换成一组主题。
作者 | Susan Li
编译 | 专知
参与 | Xiaowen
Topic Modelling in Python with NLTK and Gensim
利用NLTK和Gensim进行主题建模
研究论文主题建模是一种无监督的机器学习方法,它帮助我们发现论文中隐藏的语义结构,使我们能够在语料库中学习论文的主题表示。该模型可应用于文档上的任何标签,如网站上发布帖子的标签。
1.实现过程
即使我们不确定主题是什么,我们也会提前选择主题的数量。
每个文档都表示为主题的分布。
每个主题都表示为单词的分布。
注:研究论文的文本数据只是一堆未标注的文本,可以在下面链接找到。
https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/dataset.csv
2.文本清洗
我们使用以下函数来清理文本并返回tokens列表:
import spacy
spacy.load('en')
from spacy.lang.en import English
parser = English()
def tokenize(text):
lda_tokens = []
tokens = parser(text)
for token in tokens:
if token.orth_.isspace():
continue
elif token.like_url:
lda_tokens.append('URL')
elif token.orth_.startswith('@'):
lda_tokens.append('SCREEN_NAME')
else:
lda_tokens.append(token.lower_)
return lda_tokens
我们使用NLTK的Wordnet来查找单词、同义词、反义词等的含义。此外,我们还使用WordNetLemmatzer来获取词根。
import nltk
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
def get_lemma(word):
lemma = wn.morphy(word)
if lemma is None:
return word
else:
return lemma
from nltk.stem.wordnet import WordNetLemmatizer
def get_lemma2(word):
return WordNetLemmatizer().lemmatize(word)
过滤停用词:
nltk.download('stopwords')
en_stop = set(nltk.corpus.stopwords.words('english'))
现在,我们可以定义一个函数来为主题建模准备文本:
def prepare_text_for_lda(text):
tokens = tokenize(text)
tokens = [token for token in tokens if len(token) > 4]
tokens = [token for token in tokens if token not in en_stop]
tokens = [get_lemma(token) for token in tokens]
return tokens
打开我们的数据,逐行读取,每一行为LDA准备文本,然后添加到列表中。
现在我们可以看到文本数据是如何转换的:
import random
text_data = []
with open('dataset.csv') as f:
for line in f:
tokens = prepare_text_for_lda(line)
if random.random() > .99:
print(tokens)
text_data.append(tokens)
[‘sociocrowd’,‘social’, ‘network’, ‘base’, ‘framework’, ‘crowd’, ‘simulation’]
[‘detection’, ‘technique’, ‘clock’, ‘recovery’, ‘application’]
[‘voltage’, ‘syllabic’, ‘companding’, ‘domain’, ‘filter’]
[‘perceptual’, ‘base’, ‘coding’, ‘decision’]
[‘cognitive’, ‘mobile’, ‘virtual’, ‘network’, ‘operator’, ‘investment’,‘pricing’, ‘supply’, ‘uncertainty’]
[‘clustering’, ‘query’, ‘search’, ‘engine’]
[‘psychological’, ‘engagement’, ‘enterprise’, ‘starting’, ‘london’]
[‘10-bit’, ‘200-ms’, ‘digitally’, ‘calibrate’, ‘pipelined’, ‘using’, ‘switching’,‘opamps’]
[‘optimal’, ‘allocation’, ‘resource’, ‘distribute’, ‘information’, ‘network’]
[‘modeling’, ‘synaptic’, ‘plasticity’, ‘within’, ‘network’, ‘highly’,‘accelerate’, ‘i&f’, ‘neuron’]
[‘tile’, ‘interleave’, ‘multi’, ‘level’, ‘discrete’, ‘wavelet’, ‘transform’]
[‘security’, ‘cross’, ‘layer’, ‘protocol’, ‘wireless’, ‘sensor’, ‘network’]
[‘objectivity’, ‘industrial’, ‘exhibit’]
[‘balance’, ‘packet’, ‘discard’, ‘improve’, ‘performance’, ‘network’]
[‘bodyqos’, ‘adaptive’, ‘radio’, ‘agnostic’, ‘sensor’, ‘network’]
[‘design’, ‘reliability’, ‘methodology’]
[‘context’, ‘aware’, ‘image’, ‘semantic’, ‘extraction’, ‘social’]
[‘computation’, ‘unstable’, ‘limit’, ‘cycle’, ‘large’, ‘scale’, ‘power’,‘system’, ‘model’]
[‘photon’, ‘density’, ‘estimation’, ‘using’, ‘multiple’, ‘importance’,‘sampling’]
[‘approach’, ‘joint’, ‘blind’, ‘space’, ‘equalization’, ‘estimation’]
[‘unify’, ‘quadratic’, ‘programming’, ‘approach’, ‘mix’, ‘placement’]
3.用Gensim实现LDA
首先,我们将根据数据创建一个字典,然后转换为bag-of-words,并保存词典和语料库以备将来使用。
from gensim import corpora
dictionary = corpora.Dictionary(text_data)corpus =
[dictionary.doc2bow(text) for text in text_data]
import pickle
pickle.dump(corpus, open('corpus.pkl', 'wb'))
dictionary.save('dictionary.gensim')
我们要求LDA在数据中找到5个主题:
import gensim
NUM_TOPICS = 5
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics =
NUM_TOPICS, id2word=dictionary, passes=15)
ldamodel.save('model5.gensim')
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
(0,‘0.034*”processor” + 0.019*”database” + 0.019*”issue” + 0.019*”overview”’)
(1, ‘0.051*”computer” + 0.028*”design” + 0.028*”graphics” + 0.028*”gallery”’)
(2, ‘0.050*”management” + 0.027*”object” + 0.027*”circuit” +0.027*”efficient”’)
(3, ‘0.019*”cognitive” + 0.019*”radio” + 0.019*”network” + 0.019*”distribute”’)
(4, ‘0.029*”circuit” + 0.029*”system” + 0.029*”rigorous” +0.029*”integration”’)
主题0包括“处理器”、“数据库”、“问题”和“概述”这样的单词,听起来像是一个与数据库相关的主题。主题1包括“计算机”、“设计”、“图形”和“图库”等词,这是一个与平面设计相关的主题。主题2包括“管理”、“对象”、“电路”和“效率”等词,听起来像是一个与公司管理相关的话题。等等。
通过LDA,我们可以看到不同的文档有不同的主题,并且区别是明显的。
我们来试试新的文档:
new_doc = 'Practical Bayesian Optimization of Machine Learning Algorithms'
new_doc = prepare_text_for_lda(new_doc)
new_doc_bow = dictionary.doc2bow(new_doc)
print(new_doc_bow)
print(ldamodel.get_document_topics(new_doc_bow))
[(38,1), (117, 1)]
[(0, 0.06669136), (1, 0.40170625), (2, 0.06670282), (3, 0.39819494), (4,0.066704586)]
我的新文档是关于机器学习算法的,LDA输出显示主题1有最高的概率分配,主题3有第二高的概率分配。请记住,上述5个概率之和为1。现在我们要求LDA在数据中查找3个主题:
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = 3,
id2word=dictionary, passes=15)
ldamodel.save('model3.gensim')
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
(0, ‘0.029*”processor” +0.016*”management” + 0.016*”aid” + 0.016*”algorithm”’)
(1, ‘0.026*”radio” + 0.026*”network” + 0.026*”cognitive” + 0.026*”efficient”’)
(2, ‘0.029*”circuit” + 0.029*”distribute” + 0.016*”database” +0.016*”management”’)
我们还可以找到10个主题:
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = 10,
id2word=dictionary, passes=15)
ldamodel.save('model10.gensim')
topics = ldamodel.print_topics(num_words=4)
for topic in topics:
print(topic)
(0, ‘0.055*”database” + 0.055*”system” +0.029*”technical” + 0.029*”recursive”’)
(1, ‘0.038*”distribute” + 0.038*”graphics” + 0.038*”regenerate” +0.038*”exact”’)
(2, ‘0.055*”management” + 0.029*”multiversion” + 0.029*”reference” +0.029*”document”’)
(3, ‘0.046*”circuit” + 0.046*”object” + 0.046*”generation” +0.046*”transformation”’)
(4, ‘0.008*”programming” + 0.008*”circuit” + 0.008*”network” +0.008*”surface”’)
(5, ‘0.061*”radio” + 0.061*”cognitive” + 0.061*”network” +0.061*”connectivity”’)
(6, ‘0.085*”programming” + 0.008*”circuit” + 0.008*”subdivision” +0.008*”management”’)
(7, ‘0.041*”circuit” + 0.041*”design” + 0.041*”processor” +0.041*”instruction”’)
(8, ‘0.055*”computer” + 0.029*”efficient” + 0.029*”channel” +0.029*”cooperation”’)
(9, ‘0.061*”stimulation” + 0.061*”sensor” + 0.061*”retinal” + 0.061*”pixel”’)
4.pyLDAvis
pyLDAvis旨在帮助用户解释主题模型中的主题,该主题模型适合于文本数据集。该软件包从一个合适的LDA主题模型中提取信息,以进行交互式的基于web的可视化。
可视化5个主题:
dictionary = gensim.corpora.Dictionary.load('dictionary.gensim')
corpus = pickle.load(open('corpus.pkl', 'rb'))
lda = gensim.models.ldamodel.LdaModel.load('model5.gensim')
import pyLDAvis.gensim
lda_display = pyLDAvis.gensim.prepare(lda, corpus, dictionary,
sort_topics=False)
pyLDAvis.display(lda_display)
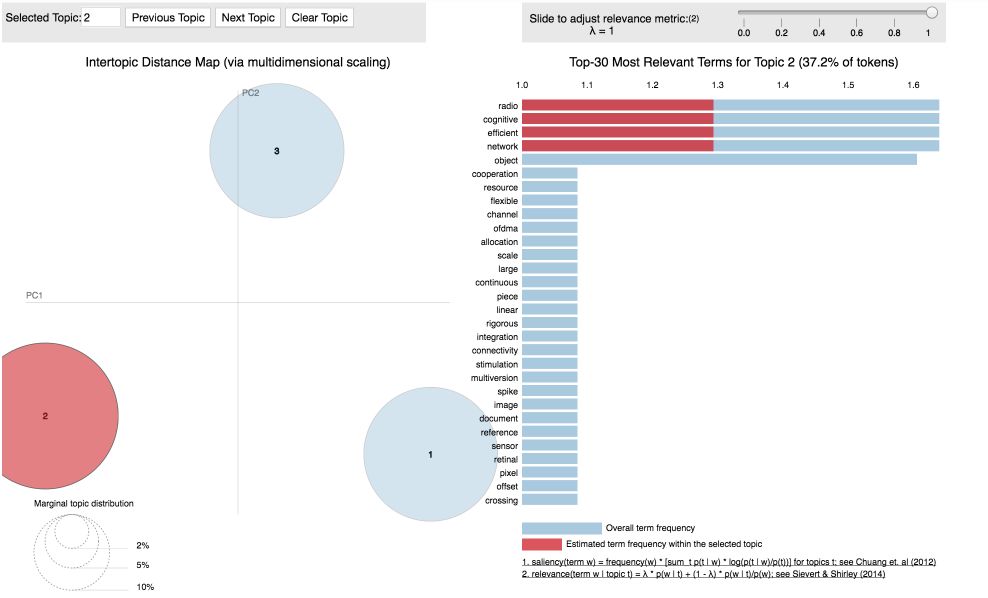
突显性(Saliency):衡量这个词对这个话题有多少信息的度量。
相关性(Relevance):给定主题的单词和给定主题的单词的概率的加权平均值。
泡泡的大小相对于数据衡量了主题的重要性。
首先,我们得到了最突出的术语,意思是术语主要告诉我们相对于主题发生了什么。我们也可以看个别的话题。
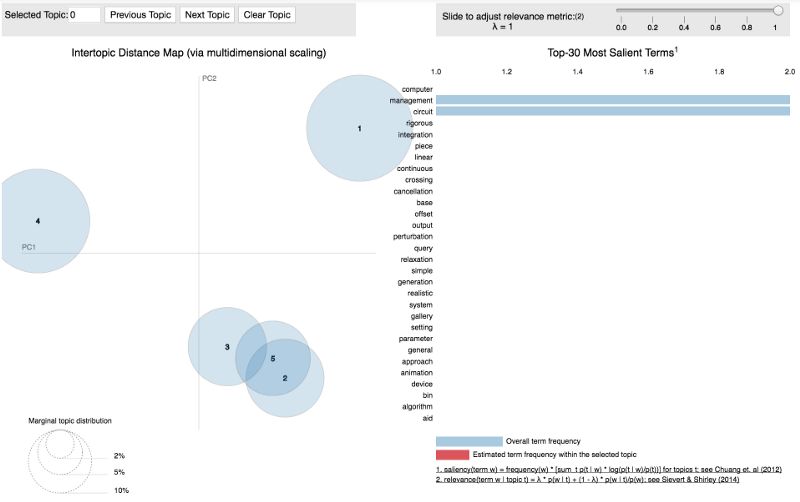
可视化3个主题:
lda3 = gensim.models.ldamodel.LdaModel.load('model3.gensim')
lda_display3 = pyLDAvis.gensim.prepare(lda3, corpus, dictionary,
sort_topics=False)
pyLDAvis.display(lda_display3)
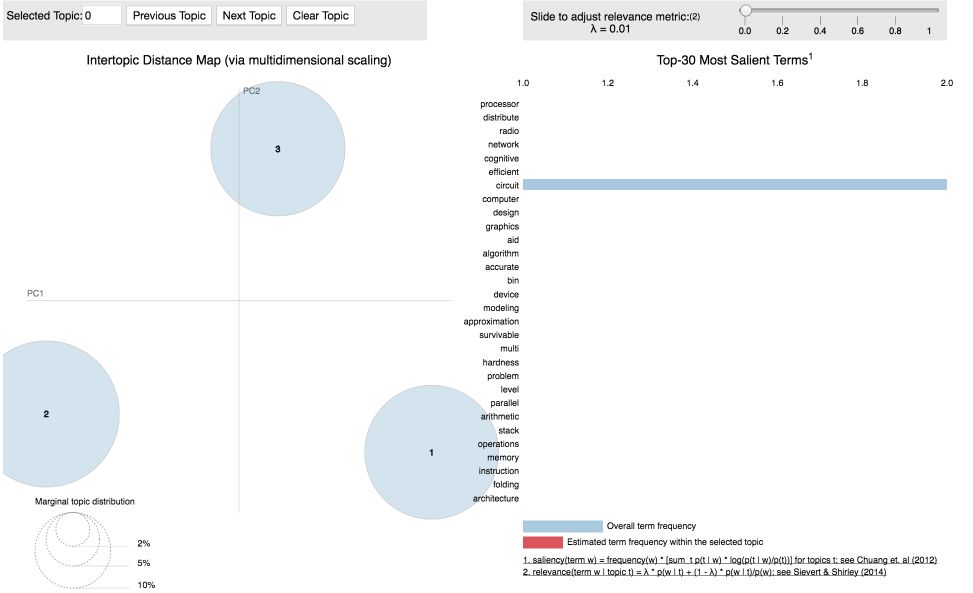
可视化10个主题:
lda10 = gensim.models.ldamodel.LdaModel.load('model10.gensim')
lda_display10 = pyLDAvis.gensim.prepare(lda10, corpus, dictionary,
sort_topics=False)
pyLDAvis.display(lda_display10)
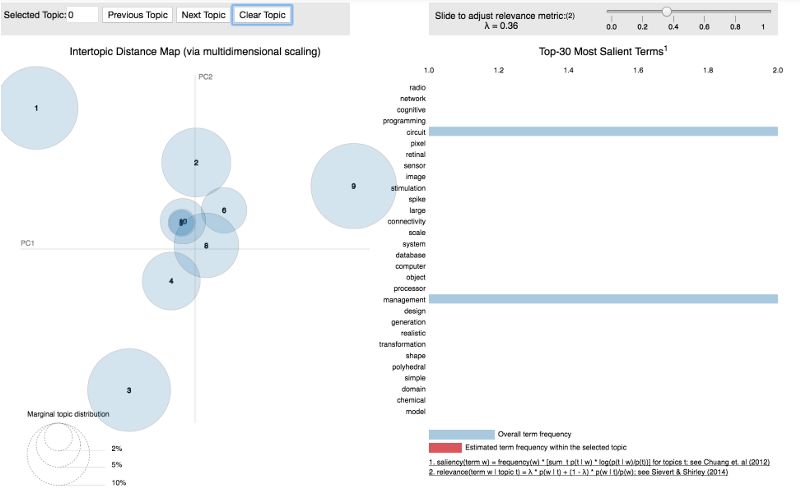
当我们有5或10个主题时,我们可以看到某些主题聚集在一起,这表明了主题之间的相似性。这是一种很好的方式来想象我们到目前为止所做的事情!试一试,找到一个文本数据集,如果标签被标记,移除标签,并自己构建一个主题模型!源代码可以在
Github上找到。链接:
https://github.com/susanli2016/Machine-Learning-with-Python/blob/master/topic_modeling_Gensim.ipynb
原文链接:
https://towardsdatascience.com/topic-modelling-in-python-with-nltk-and-gensim-4ef03213cd21
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知