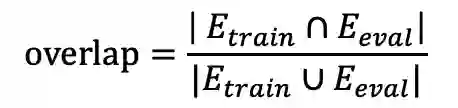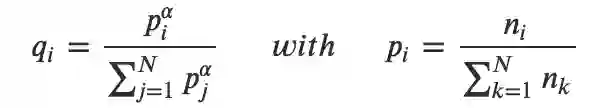©PaperWeekly 原创 · 作者|刘世兴、程任清
单位|腾讯游戏知几AI团队
研究方向|自然语言处理
![]()
简介
垂直领域业务出海,往往面临着新语种、低资源语言数据不足等多语言挑战,其中一条技术路线是通过机器翻译的方式将单语(大语种)方案迁移到多语言场景,但是这种做法效果往往很差,原因是小语种、口语化的文本翻译误差不断累积,导致最终模型训练和预测偏差较大。
我们选择的技术路线是通过预训练的方式来解决多语的问题,主要原因是:以往的研究表明预训练能使许多单语任务获得显著的性能提升;考虑到多语数据标注成本昂贵等因素,为每个语种开发维护一套方案成本太大,而预训练可以在不依赖标注的数据情况下来实现领域知识的迁移。
预训练技术路线同时也存在着挑战:基于开放域训练的开源预训练模型,是否适用于垂直领域?大规模多语数据需要大的模型,如何部署到线上进行推理?我们团队支撑了腾讯游戏出海业务,本文将介绍团队在游戏智能客服场景解决多语挑战的实践经验,给出上述问题的解决方案。
考虑到不太了解多语预训练的读者,本文第一部分将介绍近年来在这方向的前沿工作,读者可通过这一部分了解到:单语的预训练如何扩展到多语上的;面对多语的场景,预训练可以通过怎样的方式应去学习更通用的语言表示 ;以及时下多语言模型主流的关注点。
如果您是已十分了解这些背景,可直接跳到第二部分。第二部分将介绍我们团队的工作:包括多语垂直领域预训和知识蒸馏。多语垂直领域预训我们采用两阶段微调方法,第一阶段使用领域数据对 XLM-R 进行二次预训练,第二阶段进行任务相关微调。通过 XLM-R 微调,模型在多语言业务上取得了明显提升,准确率在英语、中文和阿拉伯语数据上相比线上模型平均提升 6.29%。进一步通过知识蒸馏的技术,在不明显降低模型效果的同时提升推断速度,蒸馏的小模型对比大模型提速 12 倍,准确率只降低 0.87%。
https://share.weiyun.com/Vl2gHKxS
![]()
经典预训练语言模型介绍
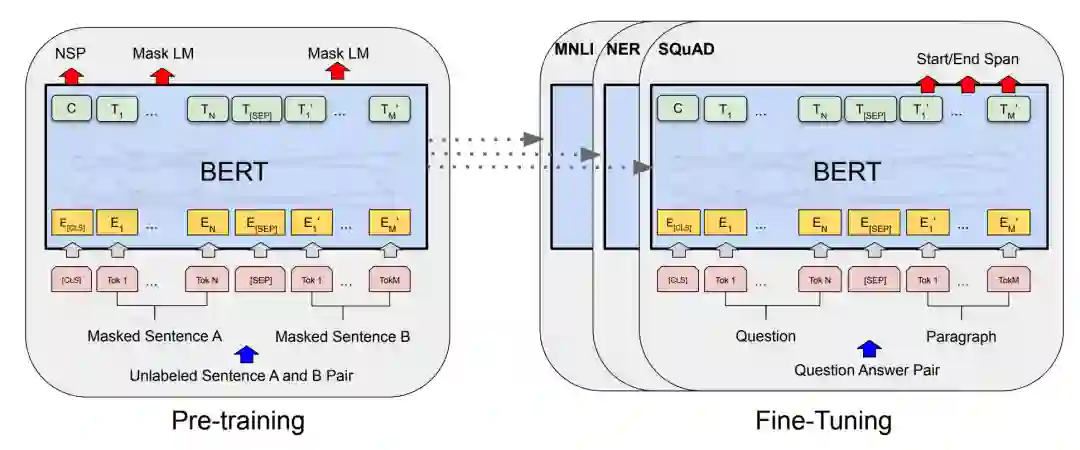
2.1 大名鼎鼎的BERT
大名鼎鼎的 BERT
[2]
一经面世,就刷新了 11 项 NLP 任务的性能记录。可以说很多下游任务基于 BERT 进行 fine-tune 都能带来比较理想的效果。这篇论文比较亮的点是:
证明了双向预训练对语言表示的重要性。
两项自监督任务进行预训练:MLM、NSP
其两项自监督任务中的 Mask language model(MLM)会随机 mask 15% 的输入(token),模型需要通过上下文(context)信息还原被 masked 的输入。MLM 的意义在于,可以使 BERT 作为单模型学习到上下文相关的表征,并能更充分地利用双向的信息。此外,论文里强调了设计 MLM 任务需要注意的问题:
意思就是预训练和微调时存在 [mask] token 的不对齐情况。为了解决为了解决这个问题,MLM 采取以下策略 mask15% 的输入(token):
80%的概率,把输入替换为 [MASK]。
10%的概率,把输入替换为随机的 token。
10%的概率,维持输入不变。
另外,其两项自监督任务中的 Next Sentence Prediction(NSP)任务是:其从语料中提取两个句子 A 与 B ,50% 的概率 B 是 A 的下一个句子,50% 的概率 B 是一个随机选取的句子,对于上述随机生成句子对,模型需要判断句子对是否连续(next sentence),以此为标注训练分类器。NSP 能使 BERT 可以从大规模语料中学习句子级别表征、句子关系的知识,这对于某些下游任务是很有用的。
以上是对 BERT 的一个简单介绍,下面要介绍的是引入多语言(multilingual)特性的 BERT,也就是 M-BERT。
2.1.1 M-BERT
Multilingual BERT 的核心思想是用相同的模型和权值来处理所有的目标语言,通过共享参数,Multilingual BERT 可以获得一定的跨语言迁移能力,以下是 M-BERT 主要的点:
-
数据取的是 Wikipedias 中 top104 的语言语料,由于数据不均衡,采用指数加权平滑对不同语种进行了采样。
-
因为不同语言有不同的词汇,Multilingual BERT 建立了一个包含所有目标语言的词汇表。
-
Multilingual BERT 编码部分的结构和 BERT 相同,并且在所有语言之间共享。
预训练的任务与 BERT 相同。
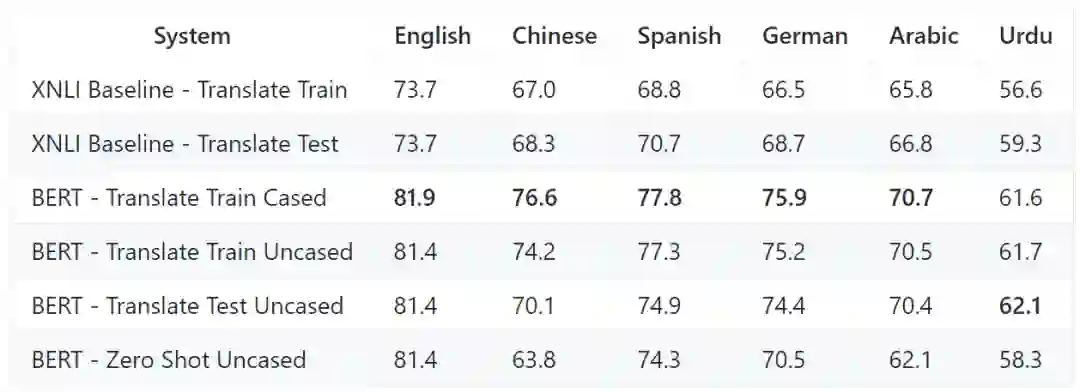
M-BERT 在 XNLI 数据集上进行评测( MultiNLI 的多语言版本),下面是其实验结果:
Translate Train:在训练的时候将英文翻译为每种目标语言,提供分类器进行训练
Translate Test:翻译系统只在测试中使用,用于将输入句子翻译为训练所用语言。
Zero Shot:指只在英文数据上训练,shot 到各个语言的结果
从实验结果可以看出不管是在 Translate Train 还是 Translate Test 的情况下均获得比较理想的效果,可以验证 M-BERT 具有一定的跨语言能力。另外需要指出的是,其实英文版的 BERT 在英文上的效果是 84.2,比上面 MBERT 的 81.4 高,同样的在中文上也是。
作者说对于高资源的语种,单语言模型会比多语言模型来的好,但是对于让他们维护几十种语种的单语模型是做不到的,如果你要训练的语种没有单语模型,基于这个多语模型进行训练是个不错的选择。
2.1.2 M-BERT如何做到跨语言的(How Multilingual is MultilingualBERT?)
多语言 BERT 在训练的时候既没有使用任何输入数据的语言标注,也没有使用任何机制来拉近相似语言的句子的特征表示(预训练任务和 BERT 是一样的),哪 M-BERT 怎么做到跨语言的?《How Multilingual is MultilingualBERT?》
[9]
这篇论文针对 MBERT 多语言特性进行了分析。
首先作者通过 NER 和 POS 任务进行跨语言迁移学习实验来验证 MBERT 的跨语言能力。
上面实验是在某语言上进行 Fine-tuning,在其他语言上进行评测(Eval),可以看到每个实验除了在自身语言取得最好的效果(对角线上的结果),在别的语言上也取得不错的效果,特别是 Pos 任务上,其迁移到其他语言的效果均达到了 80% 以上,作者说是由于 MBERT 在相似语言上的迁移能力会更好,EN、DE、ES、IT 均属于欧系语种。哪问题来了,是什么给 MBERT 带来了跨语言的迁移能力呢?
一个猜想是由于词典记忆,由于多语言 BERT 使用单个的多语言词典,所以当在微调期间出现的单词也出现在评估语言中时,这会发生一种跨语言的转换迁移,作者称这种现象为词汇重叠(overlap)。为了测量这个影响,作者计算了 E_train 和 E_eval ,分别表示训练集和测试集词汇集合,定义重叠计算公式:
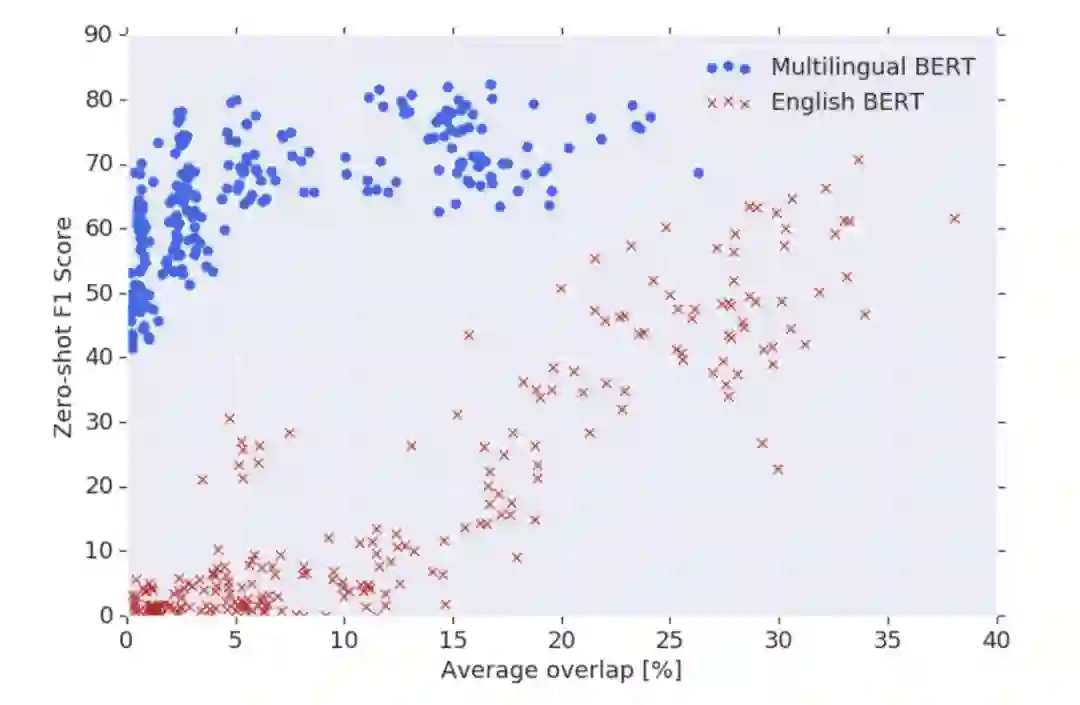
作者在 16 种语言对进行了 zero-shot ner 实验(如 EN-DE 语言对,指在 EN 数据集上训练,在 DE 数据集上进行测试),测试的模型则包括 Multilingual BERT 和 English BERT。
从上图看(横坐标是通过上面公式计算,纵坐标是 F1 值),我们可以看到 English BERT 的性能表现非常依赖于词汇重叠,迁移学习的能力会随着重叠率的下降而逐渐下降,甚至在完全不同的语言文本中(即重叠率为 0)出现 F1 分数为 0 的情况。
但是多语言 BERT 则在大范围重叠率上表现得非常平缓,即使是不同的语言文本,这证明多语言 BERT 在某种程度上拥有超过浅层词汇级别的深层次表征能力,而不依赖于简单的词典记忆。
为了深入研究多语言 BERT 为何能在不同的语言文本上具有良好的泛化能力,作者在词性标注任务 POS 上做了一些实验尝试。
在 table4 中,我们可以看到,多语言 BERT 在只有阿拉伯文(UR)的数据集上进行 POS 任务的微调,在只有梵文(HI)上的数据集进行测试,仍然达到了 91% 的准确率,这是令人非常惊讶的,这表明多语言 BERT 拥有强大的多语言表征能力。
但是,跨语言文本迁移却在某些语言对上表现出糟糕的结果,比如英文和日语(49.4%、57.4%),这表明多语言 BERT 不能在所有的情况下都表现良好。
一个可能的解释就是类型相似性,比如英语和日语有不同的主语、谓语以及宾语顺序,但是英语却和保加利亚语(BG)有相似的顺序,这说明多语言 BERT 在不同的顺序上泛化性能不够强。为了验证这个解释,更深入的了解深层次的多语言表征的本质,作者设计了实验来更深入了解这种表征。
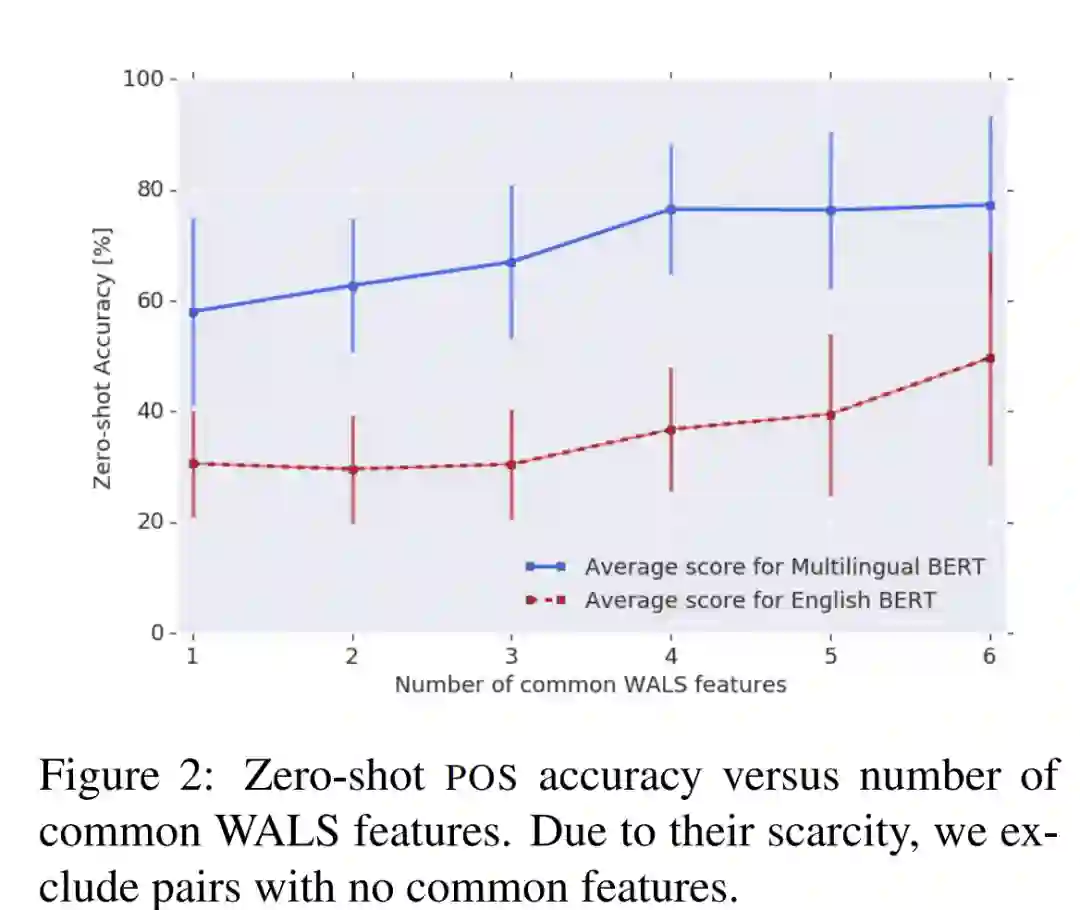
备注:WALS 是与语法结构相关的特征,从描述性材料中收集的语言结构属性。可以简单理解两个语种间 WALS 特征共有的更多,则更相似。
图 2 展示了多语言 BERT 在零样本迁移学习上 POS 任务的准确率与 WALS 特征数量的对比图。我们可以看到,准确率会随着语言相似度的提升而提升,这证明多语言 BERT 对具有相似特征的语言的迁移学习更加友好。
顺序类型特征是语种相似特征的一种,如 Table4 中展示的英文和日语具有不同的顺序类型特征,为了验证顺序类型特征是否会影响跨语言表征,作者设计实验包括包括主谓宾(subject/verb/object,SVO)顺序、形容词名词(adjective/noun,AN)顺序。
SVO languages:
Bulgarian, Catalan, Czech, Danish,English, Spanish, Estonian, Finnish, French, Galician, He- brew, Croatian,Indonesian, Italian, Latvian, Norwegian (Bokmaal and Nynorsk), Polish, Portuguese(European and Brazilian), Romanian, Russian, Slovak, Slovenian, Swedish, andChinese.
SOV Languages:
Basque, Farsi, Hindi, Japanese, Korean,Marathi, Tamil, Telugu, Turkish, and Urdu.
table 5 展示了在 POS 任务上进行的跨语言迁移学习的宏平均准确率与语言类型特征的对比。我们可以看到性能表现最好的情况是语言类型特征一样(SVO 和 SVO,SOV 和 SOV,AN 和 AN 以及 NA 和 NA)的迁移学习,这表明虽然多语言BERT能够学习到一定的多语言表征,但是似乎没有学习到这些语言类型结构的系统转换去适应带有不同语言顺序的目标语言。
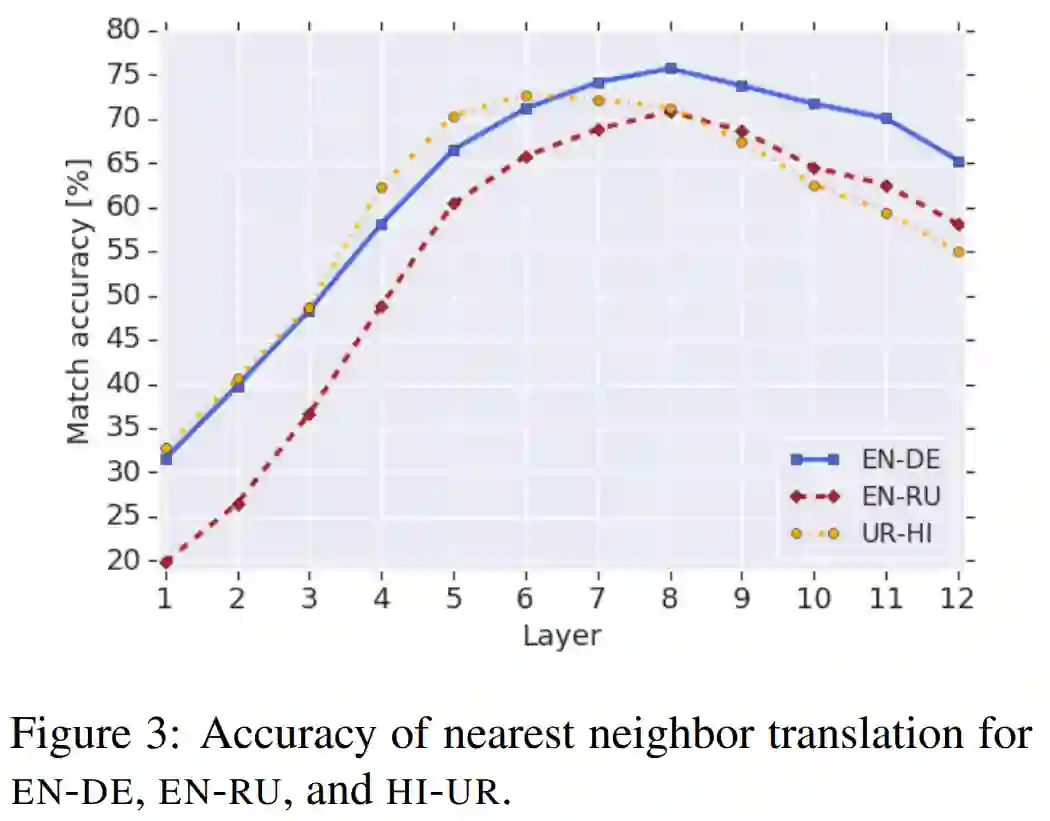
最后作者还设计了一个实验探索多语言 BERT 在特征空间上的多语言表征。作者首先从数据集 WMT16 中采样了 5000 个句子对,将句子分别输入到没有经过微调的多语言 BERT。然后抽取每个句子在 BERT 每一层的隐藏特征向量(除开 [CLS] 与 [SEP])并取平均,每层每句利用 L2 距离计算最近得到句子。
如图 3 所示,该图是翻译任务上的最近邻准确度在 BERT 每一层网络上的结果。我们可以看到,在 BERT 的非底层网络都实现了较高的准确率,这说明多语言 BERT 可能一种语言无关的方式,在大多数隐藏层共享语言特征表示。至于为什么在最后几层网络上准确率又下降了,论文提到:BERT 在预训练的时候可能需要添加与语言相关的信息。
Multilingual BERT 多语言特性的分析。可以总结的是:多语言 BERT 在某种程度上拥有超过浅层词汇级别的深层次表征能力。而不依赖于简单的词典记忆,在相似的语种上迁移能力表现较好,而没有学习到这些语言类型结构的系统转换去适应带有不同语言顺序的目标语言。
2.2 迁移能力强大的XLMs(XLMR)
XLMs
[4]
是 Facebook AI 提出的一个多语言改良版的 BERT,这个模型在跨语言分类任务(15 个语言的句子蕴含任务)上比其他模型取得了更好的效果。XLMs 的核心概念有以下两点:
1. 共享 sub-word 字典:
所有语种共用一个字典,该字典是通过 Byte Pair Encoding(BPE)构建的。
共享的内容包括相同的字母、符号 token 如数字符号、专有名词。
这种共享字典能够显著的提升不同语种在嵌入空间的对齐效果。
本文在单语料库中从随机多项式分布中采样句子进行 BPE 学习。
为了保证平衡语料,句子的采样服从多项式分布:
中 𝛼=0.5。使用这种分布抽样,可以增加分配给 low-resource 语种的 token 数量,并减轻对 high-resource 语种的偏见。这可以防止 low-resource 语种数据集的单词在字符级被分割。
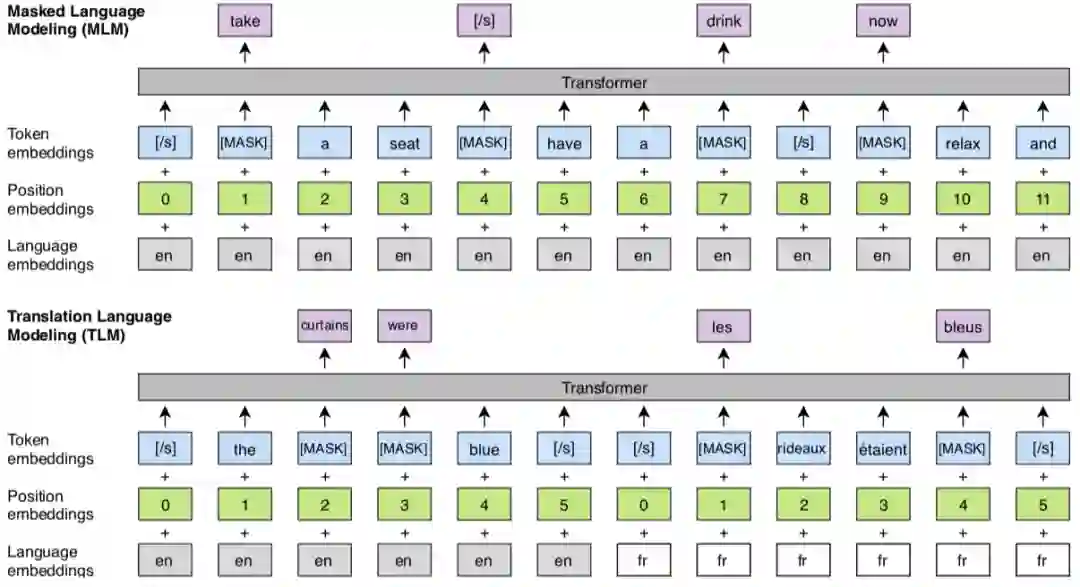
2. 改良了基于单语种语料的无监督学习 MLM 和提出了新的基于跨语言的平行语料的有监督学习方法 TLM。
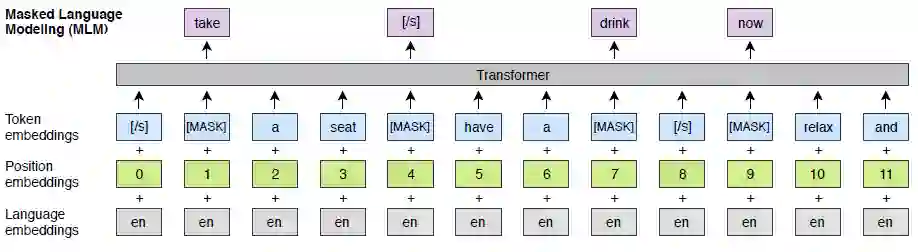
XLMs 的 MLM 这一个预训练目标与 BERT 的 MLM 思想相同,不同的点在于在于模型输入。BERT 的输入是句子对,而 XLM 使用的是随机句子组成的连续文本流,另外引入了语种编码。
TLM 使用的是有监督的跨语言并行数据。如上图所示输入为两种并行语言的拼接,同时还将 BERT 的原始 embedding 种类改进为代表语言 ID 的 Laguage embedding。TLM 训练时将随机掩盖源语言和目标语言的 token,除了可以使用一种语言的上下文来预测该 Token 之外(同 BERT),XLM 还可以使用另一种语言的上下文以及 Token 对应的翻译来预测。这样不仅可以提升语言模型的效果还可以学习到 source 和 target 的对齐表示。
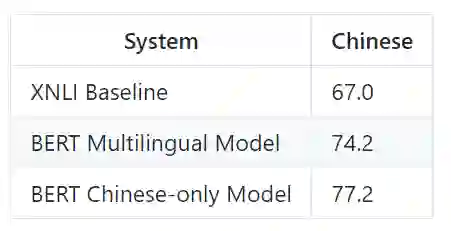
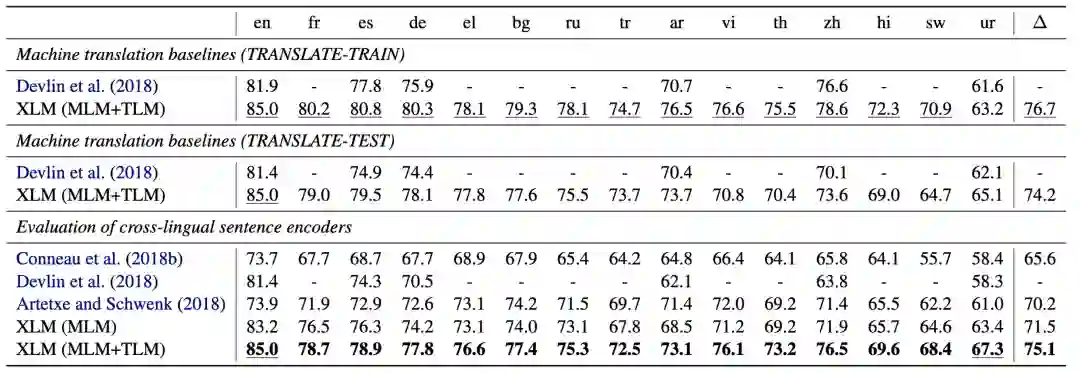
XLMs 在 XNLI 上进行的试验,其在 translate-train、translate-test 和 zero shot 上对比都达到了最好的效果。首先可以看到平均准确率:MLM 比 laser 高 1.3%,并通过 TLM 任务进一步提高到了 75.1%。另外在低资源语种:sw (斯瓦希里语)和 ur(乌尔都语)上,提高了 6.2% 和 6.3%,而在单语种:如英语也比 mBERT 提高了 3.6%,比 laser 提高了 11.1。可以说 XLMs 在各语种上做到了全面的提升。
▲ Resultson cross-lingual classification accuracy. Test accuracy on the 15 XNLIlanguages.
然而这些还不够,XLMs 的进阶版 XLMR
[5]
进一步扩大了其跨语言优势,XLMR 主要在两个方面进行了优化,一个是模型上、一个是数据上。
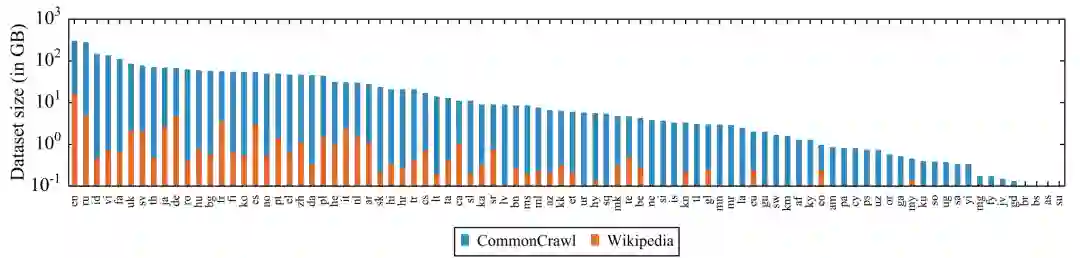
训练数据:作者采用 CommonCrawl 作为训练数据,并且通过采样加强了小语种的训练数据比例,下图是 CommonCrawl 和 Wikipedia 各语言语料规模的对照,CommonCrawl 规模更大,特别是小语种的优势更为明显。
总结起来其实就是:模型更大、数据更多并且没有用 TLM 。
XLMR 也在 XNLI 上进行的试验评测,如下图所示:
▲ Resultson cross-lingual classification. We report the accuracy on each of the 15 XNLIlanguages and the average accuracy.
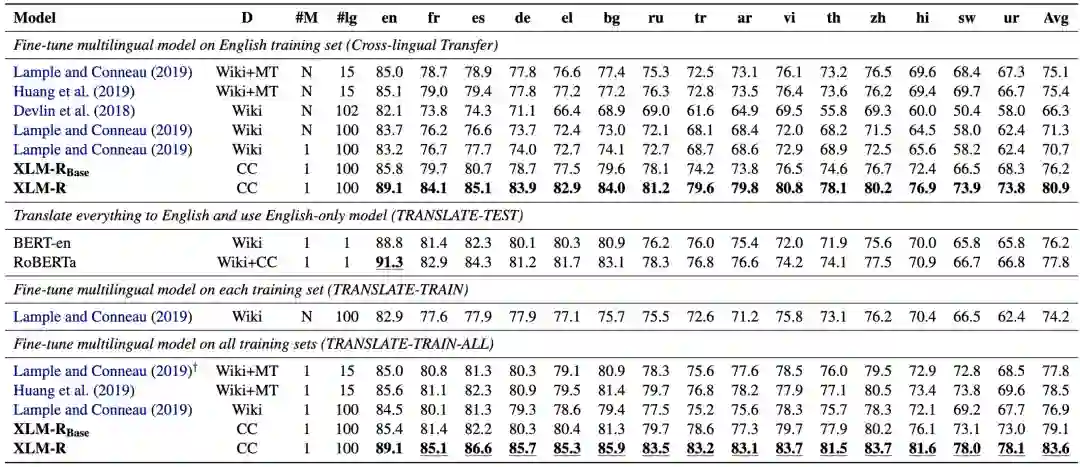
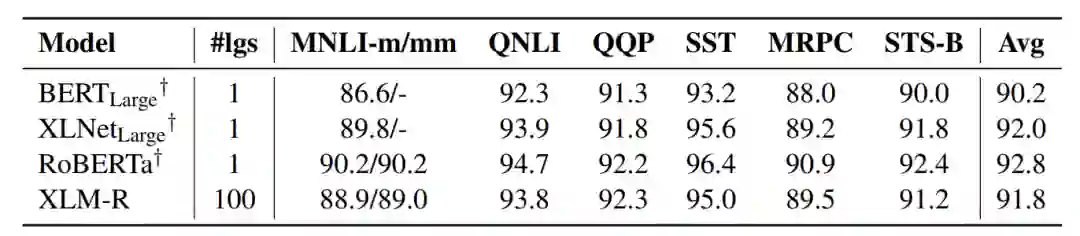
上图试验结果,在 Cross-lingualTransfer 的设定下,xlmr 达到 80.9% 准确率,分别比 xlm 和 mbert 提高了 10.2% 和 14.6%。并在小语种上表现尤为明显,如在 sw 上比前缀提高了 15.7% 和 23.5%。另一方面,与单语模型相比,跨语言模型可以借助翻译方法进行更多语言的数据增强,如 TRANSLATE-TRAIN-All 的设定下,XLM-R 的效果达到 82.4%。
另外在 GLUE 数据集上对比了 XLM-R 和 XLNET、RoBERTa 等单语种语言模型,XLM-R 超过了 BERT-large,略低于 XLNET 和 RoBERTa。也就是说 XLM-R 不仅获得了多语种能力,而且没有牺牲英文上的水平
▲ GLUEdev results.
最后作者又做了一系列实验来探究跨语言迁移的影响因素。
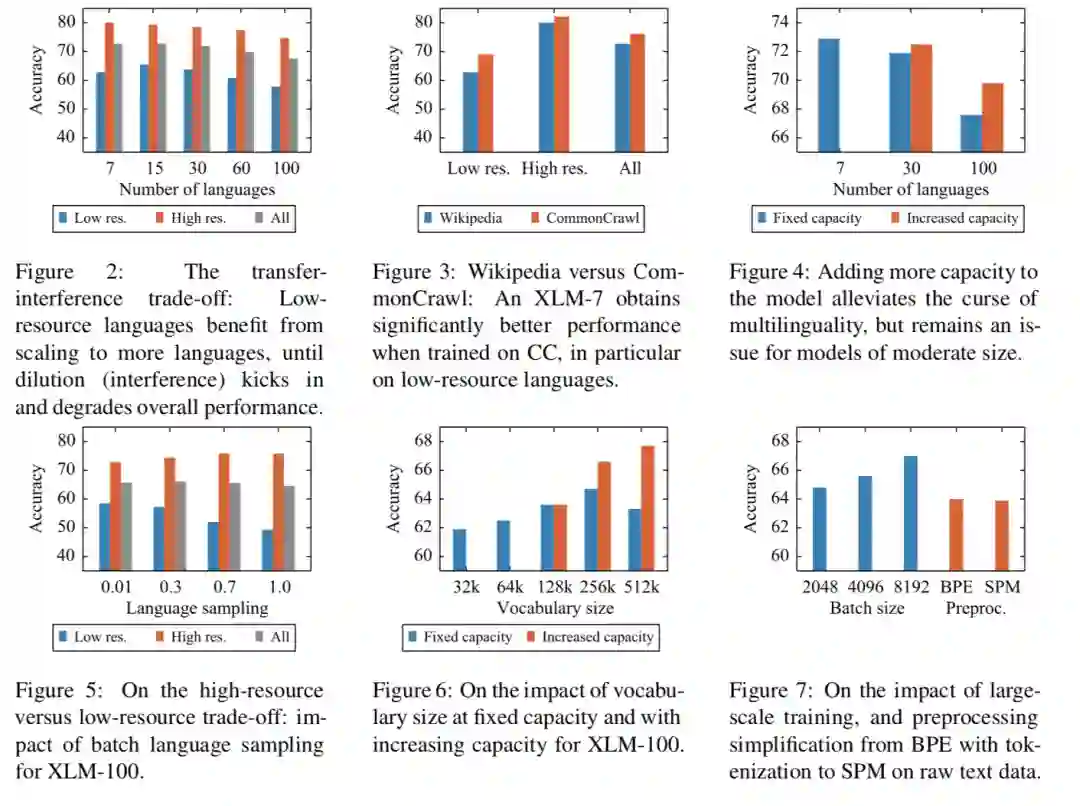
图 2 所示,在初期,语言数量的增加可以带动小语种语言的学习,小语种语言效果逐渐提升。而当数量达到并超过某个点时,模型总体迁移效果下降,包括高低资源语言。整体上,语言越多,模型学习难度越大。7 种语言到 100 种语言效果从 71.8% 下降到 67.7%。
图 3 所示,语料规模上,训练语料越充分,模型效果越好,在小语种上的表现更加明显。同时图 7 中,增加训练的 BatchSize,模型效果也会有明显的提升。
图4 所示,分别是 wiki 在 7、30 和 100 个语种上,并增加隐层大小为 768、960 和 1152,在模型参数规模与词表规模上,整体上,模型参数规模越大、词表越大,模型效果越好。增加模型参数可以在一定程度上缓解语言增加带来的模型能力退化。
图 5 所示,可以看出随着增加小语种语料数量,可以较显著地提升小语种的表现。如何平衡高低资源对模型效果有较大的影响?高低资源语言的平衡,作者通过平滑系数平衡高低资源语言的训练数据。综合考虑,作者取平滑系数为 0.3。
图 6 所示,体现了增加词典大小可以提高模型效果,32k 到 256k 在 XNLI 上提高了 2.8%(橙色是 bert_base,提高了 3%)
2.3 多语预训练模型关注点
![]()
游戏垂直领域实战
我们团队的业务场景是一个从候选标准问题集匹配出和用户查询(query)匹配的问题,通过计算 query 与每个候选标准问题的匹配分数,选择最高分的标准问题。所以我们的任务是一个句子对分类任务,预测两个文本是否匹配。我们使用的评测指标是匹配分数最高的准确率即 Top1 准确率。结合业务特性,我们在多语言问答的业务场景下选择采用 XLM-R 来提升业务效果。
预训练模型是在通用语料上训练好的,如何应用在具体领域任务上呢?一般通过迁移学习的方法,将预训练模型学到的语言知识迁移到目标任务上。具体方法有两种:
1. 特征抽取:训练时把预训练模型当作一个编码器,固定其参数不变;
2. 微调:训练时预训练模型的参数与任务层参数一起参与训练。
两种方法各有优劣,特征抽取方法能够减少训练参数,还可以预计算预训练特征,但是可能需要额外的复杂网络结构;微调方法通常只需要加上任务相关的预测层就能取得很好的效果,所以一般采用微调方法。
3.1 二次预训练探索
自从 BERT 之后,微调成为了利用预训练模型进行下游任务的主要方法。预训练模型通过足够的参数和预训练,能够从文本中提取足够的信息,在进行具体任务时,只需加上少量参数构成的预测层就能取得很好的效果。尽管如此,不同的微调策略仍然能进一步提升效果。因为预训练模型是在通用语料上训练的,和下游任务的数据通常差别较大。
所以通过在下游任务微调前,先进行一个“中间”微调通常可以提升下游任务的效果。这个“中间”任务可以是用下游任务领域数据进行预训练
[7]
,也可以是和下游任务类型相同或接近、但训练数据更充足的任务
[8]
。通过在下游任务领域内数据进行二次预训练,通常能够取得更好的效果
[7]
。
我们基于 XLM-R base 进行微调,采用领域数据二次预训练然后再进行任务微调的二阶段微调法。我们搜集了业务相关的数据,总共 1000 万数据量,包含多种语言,其中主要语言是 en(英文)、zh(中文)、ar(阿拉伯语)、tr(土耳其语)、hi(印地语)和 id(印度尼西亚语)。
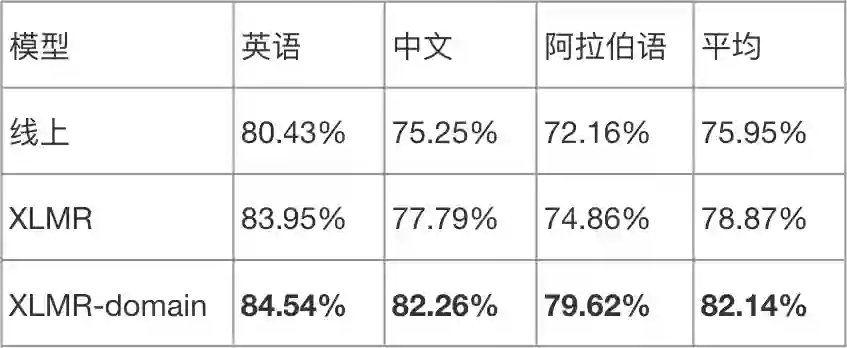
先上最终效果,下表对比了有无二次预训练的效果,XLMR 是直接用 12 层的 XLM-RoBERTa base 模型微调,XLMR-domain 是先进行二次预训练,然后再微调。XLMR 微调相比线上模型带来平均 2.92% 提升,二次预训练进一步增加了平均 3.27% 的提升。
![]()
接下来详细介绍我们二次预训练的方法和探索。预训练模型的三个主要部分是数据、模型(编码器)结构、训练任务。基于预训练模型进行二次预训练一般不改变模型结构,于是我们可以从数据和训练任务两方面进行优化。
3.1.1 预训练任务
XLM-R 是 XLM 的改进版,XLM
[4]
提出了 Translation Language Modeling (TLM)训练任务,将平行文本以 [eos] 分隔符分隔进行拼接,作为一条训练数据。XLM 使用 Masked Language Modeling(MLM)任务与 TLM 任务交替训练。
因为 XLM-R 使用了更大的训练数据和更充分的训练,只用 MLM 任务就取得了非常好的效果,且 TLM 任务需要平行语料,所以 XLM-R 没有使用 TLM 任务。
在我们的业务场景中,需要计算两个问题的匹配分数,且两个问题可能是不同种语言。这种情况下,MLM 任务中每条数据都来自一种语言,与我们的情景存在差距,带来了训练、预测的“鸿沟“。在错例分析中我们也发现有一部分是跨语言匹配错例。那我们能否通过 TLM 任务,来去除这个“鸿沟”呢?
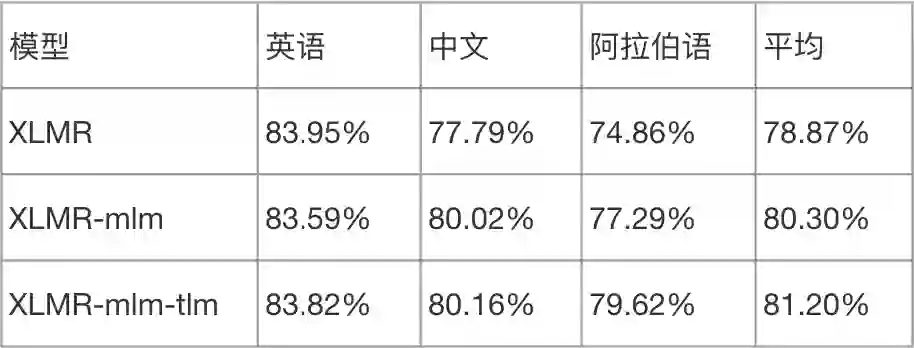
TLM 任务需要使用平行语料,但是我们没有,于是我们尝试使用其他语种文本的机器翻译作为平行文本,构造平行文本对训练数据。我们采用 MLM+TLM 任务进行二次训练,下表是实验对比,加入 TLM 任务后英语和中文没有明显提升,阿拉伯语提升明显。说明 TLM 任务确实带来了一定的提升。但是在后续的知识蒸馏时,加入 TLM 任务的模型蒸馏效果较差,所以后续没有使用 TLM 任务。
![]()
3.1.2 Batch构造方法
接着,我们尝试从数据角度进行优化。首先是模型输入 Batch 的构造方法。
如上图,XLM-R 训练时,将同种语言下的所有文档的句子当作句子流,每行文本后加上句末符号 eos([\s]),构造训练 batch 的数据时截取固定长度如 256 token 作为一条训练数据。
我们二次训练的数据以短文本居多,我们担心上述方法会造成多个不相关的句子拼成一条训练数据,影响模型对文本上下文的学习,因此我们最初是以语料的每行文本作为一条训练数据(Line by Line),长度不足的以 padding 补齐(2.1 节的实验结果使用 Line by Line 方法构造 batch)。
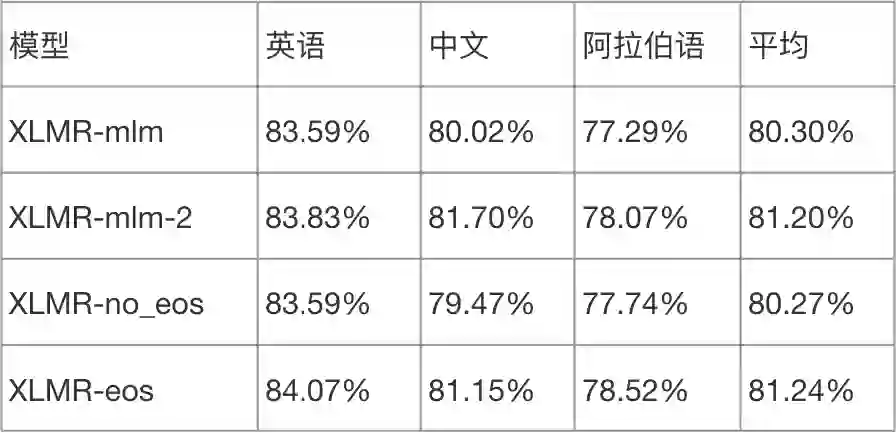
但是发现每个 batch 下会有很多的 padding,这显然极大地浪费算了,特别是 self-attention 的计算对序列长度比较敏感。因此,我们实验对比了 XLM-R 的构造方法(XLMR-mlm-2)和 Line by Line(XLMR-mlm) 方法,发现 XLM-R 的构造方法loss收敛更快,loss 降得更低,训练效率更高,效果也有所提升。实验表明,不需要担心不同句子拼接成长文本“句子”会给模型训练带来不利影响。
![]()
另外,我们实验了基于 XLMR 的构造方式下,是否添加句末分隔符 eos 的影响。如上表,XLMR-no_eos 是没有 eos,XLMR-eos 是有 eos。我们发现,无分隔符的模型效果较差,和 Line by Line 方式差不多。显然,分隔符成功地将不同上下文的句子分隔开来,让模型能够区分出数据中的不同上下文。
3.1.3 训练数据的语言分布的影响
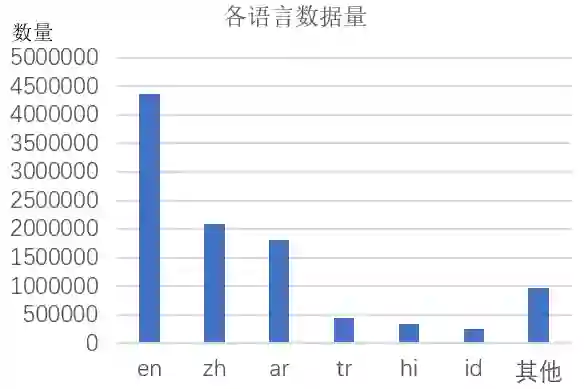
多语言场景下,不同语言的数据分布也对模型预训练有影响。我们预训练的数据中各语言的数据分布不平衡,如下图所示,英语、中文、阿拉伯语等数量较多,其他语种较少。
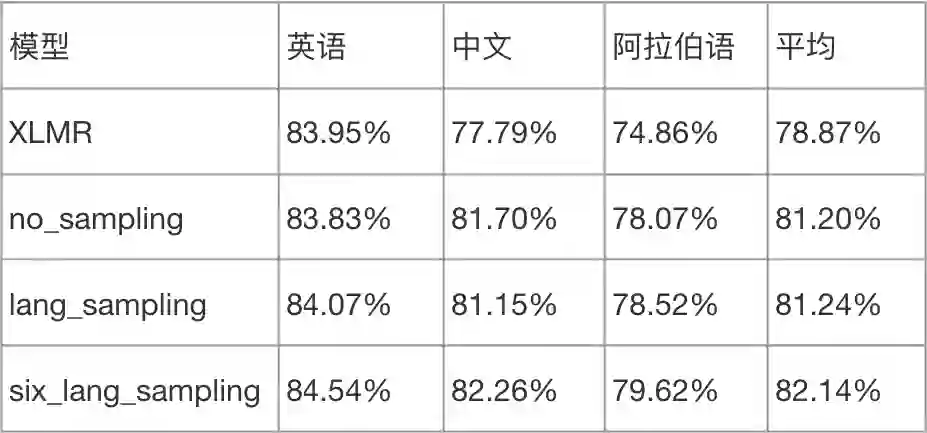
针对这种情况,XLM-R 论文在训练时采取了语言采样策略,对大语种欠采样,小语种过采样。我们进行二次预训练时实验对比了不同采样策略:无语言采样(no_sampling);所有语言参与采样(lang_sampling);将 6 大语种外的小语种看成一种“语言”,进行 7 大“语种”采样(six_lang_sampling)。
实验结果如下表所示。因为小语种数量很少,所以所有语言参与采样(lang_sampling)会将大语种数据“过分”欠采样,最终的实验效果没有明显提升,而针对 6 大语种采样的效果提升明显。
![]()
3.2 预训模型上线——知识蒸馏
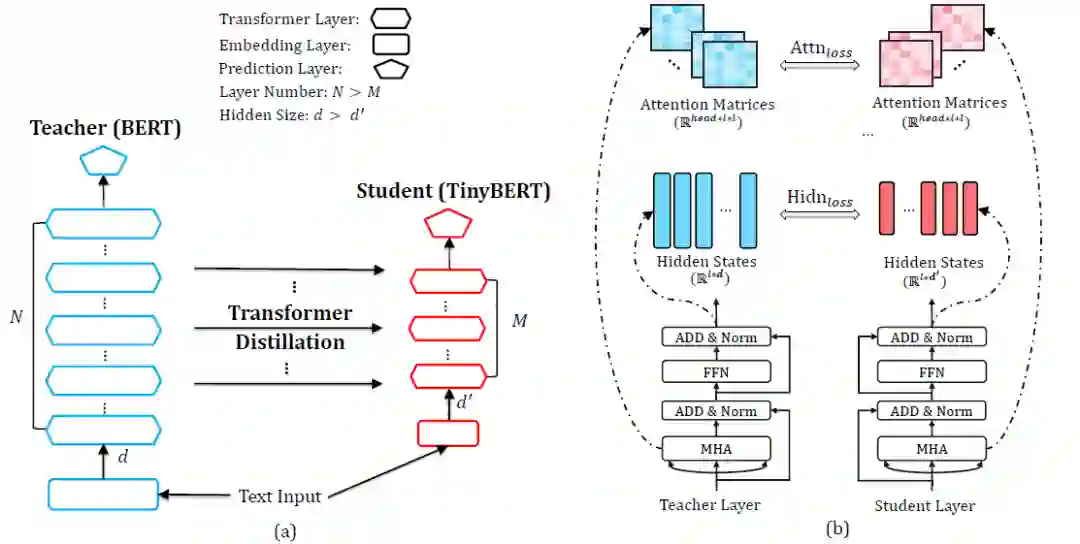
经过上述实验,我们终于得到了一个效果不错的模型,然而微调出来的大模型虽然效果好,但是模型的推断耗时太长,难以部署。我们调研了模型压缩方法,发现模型压缩主要有减枝、权重量化、参数共享和知识蒸馏等方法。我们的目标主要是在不明显降低效果的情况下提升模型的推断速度,所以我们选择了知识蒸馏方法,将大模型知识迁移到小模型上。我们参考 TinyBERT 的蒸馏方法,并根据实验得出一套有效的蒸馏流程。
3.2.1 TinyBERT简介
TinyBERT
[6]
使用 4 层 312 隐层维度的小 transformer 结构做学生模型(student),蒸馏 BERT(teacher),相比 BERT-base 在 GLUE 上达到了其 96% 的效果,13% 的参数和 10% 的推断时间。下面简单介绍 TinyBERT 的实现方式。
TinyBERT 提出了从 transformer 的具体组件蒸馏,包括 embedding 层;transformer 的隐层和 attention 矩阵;预测层的 logits,总体的损失函数是相应的 4 部分。预测层 logits 的 loss 定义为 teacher 的 logits 与 student 的 logits 的 soft cross-entropy loss,其他 3 个 loss 是 teacher 与 student 相应组件的 MSE loss。
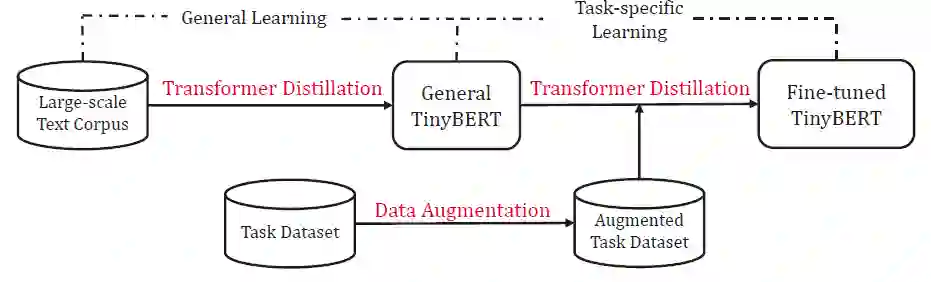
训练时提出了两阶段蒸馏框架,通用模型蒸馏和任务相关蒸馏。通用模型蒸馏使用大规模通用语料进行蒸馏训练,这一阶段的蒸馏不包括预测层 logits 的蒸馏。进行任务蒸馏时,先对任务数据集进行数据增强,然后进行蒸馏,此时的 teacher 是 BERT 在改任务的微调模型。
需要注意的是任务蒸馏也分为两步:(1)step1 蒸馏 : 对 embedding 层、transformer 隐层和注意力矩阵蒸馏;(2)预测蒸馏: 只对预测层的 logits 蒸馏。
3.2.2 蒸馏XLMR
3.2.2.1 只使用任务蒸馏
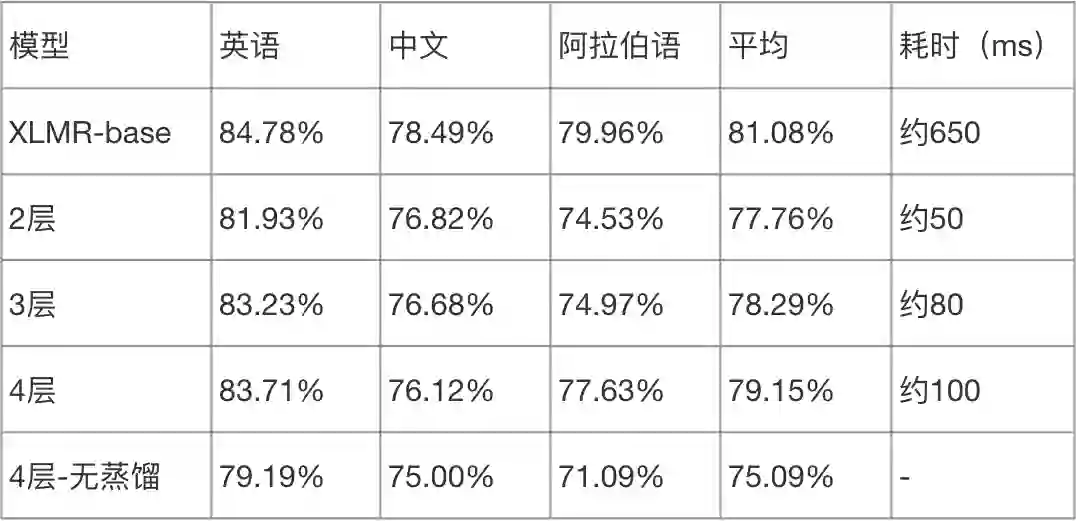
首先,我们采用 TinyBERT 的任务蒸馏方法,即随机初始化一个小模型,然后进行 step1 蒸馏,预测蒸馏。teacher 模型是微调好的 XLMR-base(12层,隐层维度 768),student 模型选择了层数 2、3 和 4 层,隐层维度都是 384 的小模型。
实验结果如下表,蒸馏的4层模型效果最好,平均准确率只比 XLMR-base 降低了 1.93%,2、3 层的模型效果较差。从耗时上看,4 层小模型的耗时较高,2 层最低。所有蒸馏模型效果都优于没使用蒸馏、直接随机初始化然后训练的模型(4 层-无蒸馏)。
![]()
3.2.2.2 加上通用蒸馏
具体任务的训练数据是有限的,因此仅仅使用任务蒸馏无法获得类似预训练模型一样的泛化能力。我们可以先进行通用蒸馏,令小模型具备通用知识,然后再进行任务蒸馏,学习具体任务知识。考虑到用开放语料进行通用蒸馏比较耗时,我们使用二次预训练 XLMR 的训练数据,进行了领域内的通用蒸馏。
如上文所述,通用蒸馏会蒸馏 embedding 层、transformer 的隐层和注意力矩阵,但是不使用 MLM 任务的 loss。通用蒸馏后的小模型相比随机初始化的模型会有更好的模型参数,通用蒸馏可以相当于一个高质量的 student 的参数初始化,能够应用在同领域的多个下游任务上。
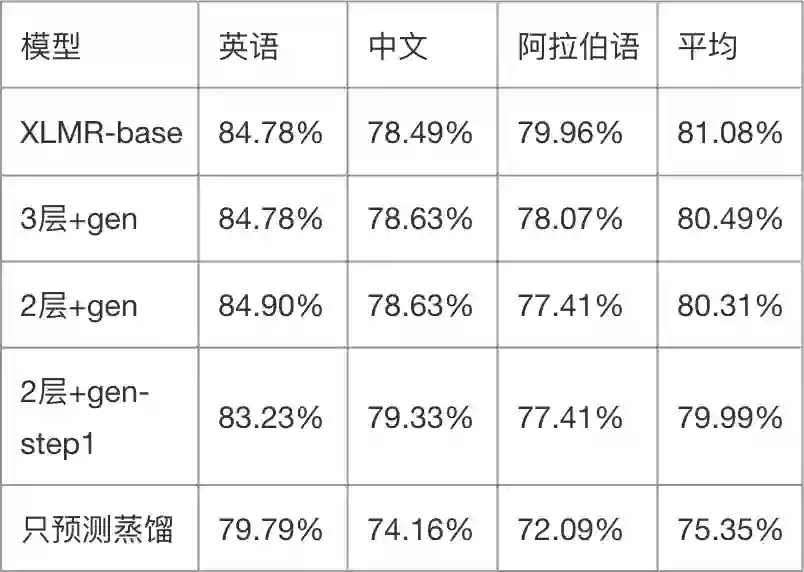
如下表所示,加上通用蒸馏后(+gen),2 层和 3 层小模型也能取得接近大模型的效果。TinyBERT 的任务蒸馏里包含两个训练阶段(step1 阶段和预测蒸馏),step1 阶段蒸馏的任务和通用阶段是一样的,也不包括预测任务的 loss。所以我们可以实验跳过 step1 阶段直接进行预测蒸馏(2 层+gen-step1),结果发现效果只降低 0.32%。
进一步的,我们实验了只使用预测蒸馏(只预测蒸馏),发现实验效果差很多。所以,最终采取的蒸馏流程是先进行通用蒸馏,然后再进行预测蒸馏。
![]()
![]()
总结
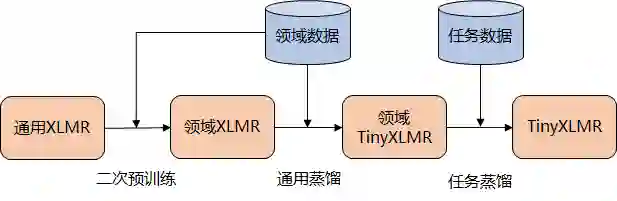
我们将多语言预训练模型 XLM-R 应用在多语言业务上,通过二次预训练和知识蒸馏,最终提升了模型效果。整个流程可以总结为下图,通用 XLMR 模型二次预训练后得到领域 XLMR 模型,然后基于领域 XLMR 模型进行微调得到微调 XLMR,最后通过通用蒸馏、任务蒸馏两阶段蒸馏法得到小模型 TinyXLMR。
[1] Qiu X, Sun T, Xu Y, et al. Pre-trained models for natural language processing: A survey[J]. arXiv preprint arXiv:2003.08271, 2020.
[2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Yang Z, Dai Z, Yang Y, et al. Xlnet: Generalized autoregressive pretraining for language understanding[C]//Advances in neural information processing systems. 2019: 5753-5763.
[4] Conneau A, Lample G. Cross-lingual language model pretraining[C]//Advances in Neural Information Processing Systems. 2019: 7059-7069.
[5] Conneau A, Khandelwal K, Goyal N, et al. Unsupervised cross-lingual representation learning at scale[J]. arXiv preprint arXiv:1911.02116, 2019.
[6] Jiao X, Yin Y, Shang L, et al. Tinybert: Distilling bert for natural language understanding[J]. arXiv preprint arXiv:1909.10351, 2019.
[7] Sun C, Qiu X, Xu Y, et al. How to fine-tune bert for text classification?[C]//China National Conference on Chinese Computational Linguistics. Springer, Cham, 2019: 194-206.
[8] Garg S, Vu T, Moschitti A. Tanda: Transfer and adapt pre-trained transformer models for answer sentence selection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(05): 7780-7788.
[9] Telmo Pires, Eva Schlinger, and Dan Garrette. 2019. How multilingual is multilingual bert? In ACL.
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()