让ML创造RS:推荐系统中的自动化机器学习
© 作者|田长鑫
机构|中国人民大学信息学院
研究方向|推荐系统
本文的目标是对自动化机器学习(AutoML)在推荐系统(RS)领域的相关研究作一些追溯和展望,内容主要参考论文《Automated Machine Learning for Deep Recommender Systems: A Survey》和《AutoML for Deep Recommender Systems: A Survey》,并掺杂了笔者的一些个人理解。封面及文中使用的图片均截取自上述两篇论文,转载请注明出处。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
0. 本文框架
RS与AutoML
AutoML在RS上的应用
未来研究方向
参考文献
1. RS与AutoML
近年来,深度学习被广泛用于构建推荐系统,用以捕捉非线性信息和物品-用户关系。类似于计算机视觉领域的模型由池化、卷积、层数等组件组成,深度推荐系统通常有四个组件组成,即输入层、嵌入层、交互层和预测层。
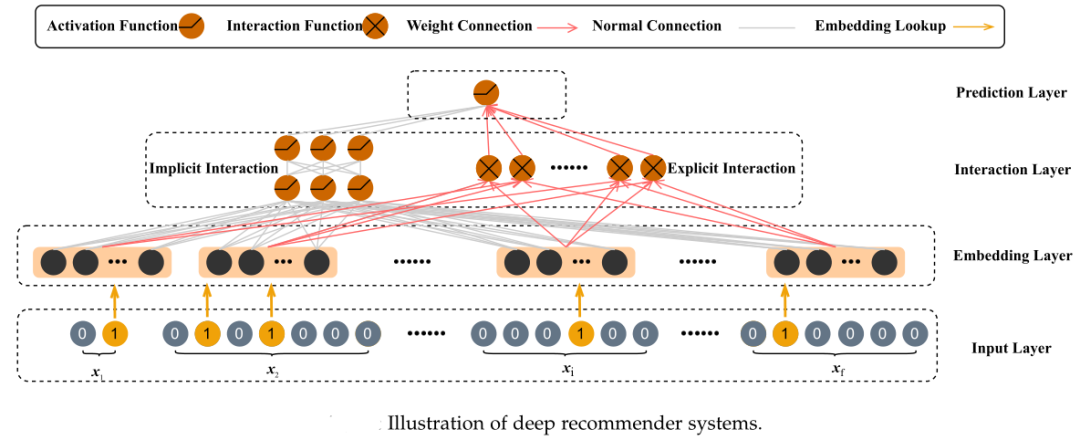
如上示意图所示,数据依次经过输入层、嵌入层、交互层和预测层,最终完成推荐预测。这四个组件的功能为:
输入层(Input Layer)从原始数据生成二进制特征。输入数据通常包含用户概要文件、项目概要文件和上下文信息。不同于图片和文本数据,深度推荐系统的输入数据通常采用表格格式,是海量和高度稀疏的。因此,通常采用一热或多热编码将原始特征作为二值特征映射到高维特征空间。
嵌入层(Embedding Layer)将二值特征映射到低维特征空间。如上所述,深度推荐系统的输入数据通常是高维稀疏的一热或多热编码,嵌入层可以将其转化为低维稠密的向量。嵌入层的输出是所有特征嵌入的拼接。
交互层(Interaction Layer)查找对模型性能有利的强大的特征交互。将原始特征映射到低维空间后,交互层捕获特征之间的特征交互信息。特征交互分为显式特征交互和隐式特征交互,其中显式特征交互实现了特定特征之间的交互功能,隐式特征交互利用多层感知器(MLP)从所有特征嵌入中学习非线性信息。
预测层(Input Layer)生成模型的预测。预测层根据特征交互层的输出生成预测,不同的推荐任务可能在预测层采用不同的激活函数。而根据预测层的输出和真实标签,损失函数被计算并被用于反向传播优化。
深度推荐系统所包含的上述每一组件的设计都存在很多选择,但传统深度推荐系统的设计在很大程度上依赖于人类的经验和专家知识。为此,自动机器学习技术(AutoML) 被引入到深度推荐系统, 而autoML是自动化生成某些组件或整个机器学习框架的一种很有前途的方法,它分为自动数据清理(Auto Clean)、自动特征工程(AutoFE)、超参数优化(HPO)、神经网络架构搜索(NAS)等诸多方向。而随着神经网络的发展,神经网络架构搜索(NAS)技术日趋重要,简而言之,NAS在搜索空间中通过某种搜索策略得到子网络结构,评估优劣并优化,其中的关键要素包括:
搜索空间(Search Space): 搜索空间定义了可以代表哪些体系结构。结合适用于任务属性的先验知识可以减小搜索空间大小并简化搜索。然而,简化搜索也可能会阻止找到超越当前人类知识的模型架构。
搜索策略(Search strategy):搜索策略说明了如何做空间搜索。它包含了经典的探索-开发之间的权衡。一方面,需要快速找到性能良好的架构,另一方面,避免过早收敛到次优架构区域。
性能评估策略(Performance estimation strategy):NAS的目标通常是找到在未知数据实现高预测性能的架构。性能评估是指评估此性能的过程:最简单的选择是对数据架构执行标准训练和验证,但这种方法计算成本很高;因此,最近的研究大多集中在开发出方法去降低性能估计成本。
基于上述要素,NAS领域主要有三种方法:(1)基于样例的方法,它们通过从搜索空间中选择或对现有的有希望的方法进行变异来探索新的体系结构。(2)基于强化学习的方法,它们实现一个循环神经网络作为策略控制器,逐渐确定体系结构的设计。(3)基于梯度的方法接近,它们将离散搜索空间转化为连续搜索,利用验证集上的性能计算出的梯度下降对搜索结构进行优化。
2. AutoML在RS上的应用
借助AutoML,我们可以为深度推荐系统的不同组件自动搜索合适的候选对象。根据被搜索的组件,当前AutoML在推荐系统上的研究工作可被分为:
嵌入维度搜索(embedding dimension search)
特征交互搜索(feature interaction search)
模型设计搜索(model design search)
其他组件搜索(other components search)
2.1 嵌入维度搜索
如上所述,推荐系统的典型输入包含许多特征字段,每个字段由多个特征字段组成。由于这些原始特征通常被编码为高维稀疏向量,深度推荐系统都通过嵌入层将其映射为低维稠密的嵌入表示(embedding)。但是,这些方法大多为所有特征赋予了统一的嵌入维数,这造成了资源浪费、性能不佳等问题,因为嵌入矩阵中参数数量庞大,且特征一般都是长尾分布,不同特征可能需要不同维度。特别是高频特征需要更多的参数来表达其丰富的信息,而对低频特征过度参数化会由于训练数据有限而导致过拟合。因此,自动为每个特征分配嵌入维度成为近年来研究的热点,这便是自动嵌入维度搜索(automated embedding dimension search,Auto-EDS)。如下图所示,Auto-EDS的关键组件是混合维度嵌入层(mixed dimension (MD) embedding layer),它为每个特征赋予可变的嵌入维度,然后这些混合维度的嵌入在对齐嵌入层被对齐到相同的维度,以满足后续操作。
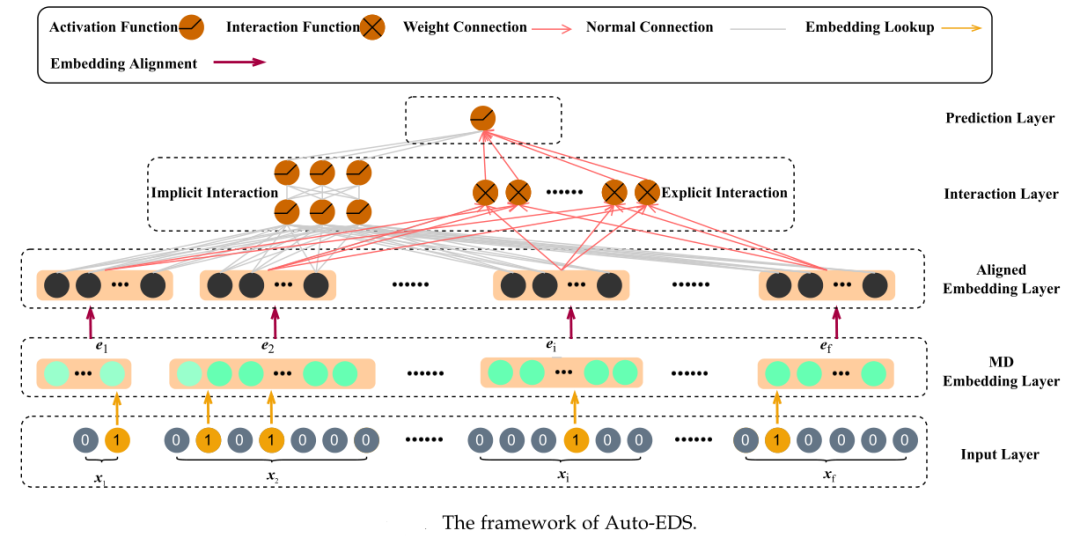
自动嵌入维度搜索的现有方法可分为三大类:启发式方法、超参数优化方法和嵌入剪枝方法:
启发式方法通常基于预定义的人工规则为每个特征分配嵌入维数。例如,MDE引入了一个混合维度嵌入层,根据特征的流行程度来分配嵌入维数。这种启发式方法虽然简单,但其所基于的幂律的谱衰减(the spectral decay following the powerlaw)并不能保证总是满足,因此限制了其在复杂任务中的推广。
超参数优化方法(HPO)受神经结构搜索(NAS)在深度神经网络体系结构自动搜索方面的启发,将嵌入维度搜索视为超参数优化(HPO)问题,从预定义的候选维度集搜索嵌入维度。例如,NIS (Neural Input Search)是第一个基于HPO的Auto-EDS工作,可以自动学习每个独特特性的嵌入维度和词汇量。虽然基于HPO的方法可以学习不同层次的混合维度嵌入,但这类方法存在资源消耗大、优化耗时长、假设条件严苛的缺点。
嵌入剪枝方法将Auto-EDS看作嵌入剪枝问题,通过不同的剪枝策略对整个嵌入矩阵进行嵌入剪枝,从而自动获得混合维度嵌入矩阵。因此,这类方法的关键思想是通过识别并去除嵌入矩阵中的冗余参数,建立内存高效的模型,并尽可能保持准确性。例如。PEP引入可学习阈值来识别嵌入矩阵中参数的重要性。虽然嵌入剪枝的方法可以通过选择性地减少嵌入矩阵中的参数实现维度搜索,但这些方法通常需要进行迭代优化,耗时较长。
2.2 特征交互搜索
特征交互是指用户、项目和其他上下文信息的单个特征的组合。二阶特征交互的有效性已经被因子分解机(FMs)证明。与此同时。高阶特征交互作用也可以由高阶因式分解机(HOFM)近似。而随着深度神经网络的发展,神经网络被用于提取高阶特征。例如,Wide&Deep和DeepFM通过浅层组件和深层组件学习低阶和高阶特征交互,并证明低阶和高阶特征交互在推荐系统中都起着重要作用。然而,枚举所有高阶特征交互需要耗费时间和空间。因此,如何保留必要的特征交互,过滤掉无用的特征交互是自动特征交互搜索(Auto-FIS)关心的问题。如下图所示,Auto-FIS的关键组件是包含所有阶特征交互(All Order Feature Interactions)的集合,以及在搜索过程确定的丢弃的特征交互链接(Discarded Connection After Search)。
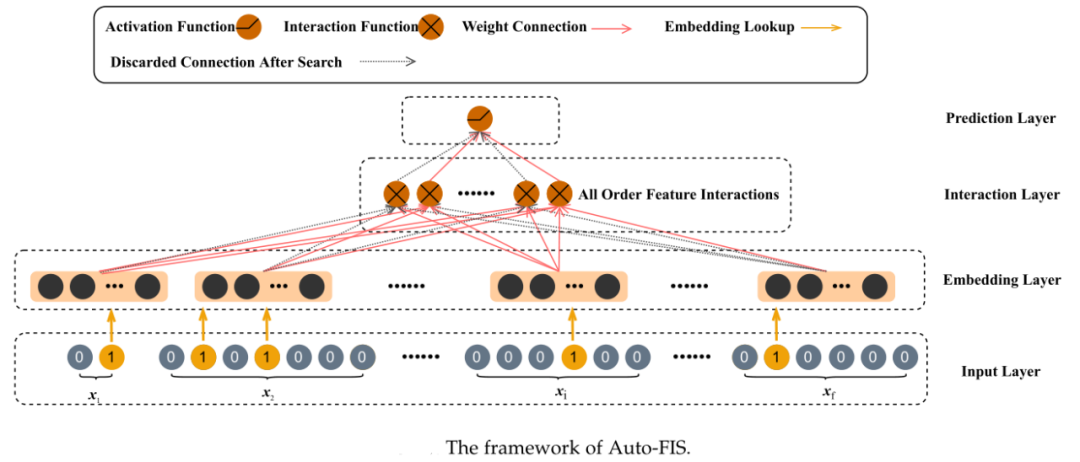
自动特征交互搜索的现有方法主要解决以下三个问题:(1)期望的有益特征交互集是离散的。(2) 低阶和高阶特征交互都是高度相关的。(3)考虑搜索过程中低阶交互和高阶交互的优先级。例如,贝叶斯个性化特征交互选择(BP-FIS)提出通过贝叶斯变量选择为单个用户自适应选择交互;AutoFIS提出通过为每个潜在的特征交互添加一个注意门来学习推荐系统模型中的特征交互,而不是简单地列举所有二阶特征交互。与AutoFI只关注二阶特征交互选择不同,AutoGroup 将高阶特征交互搜索视为一个结构优化问题,以识别有用的高阶交互;AutoCross通过实现贪婪波束搜索,在树结构搜索空间上实现显式高阶特征交互搜索。
2.3 模型设计搜索
许多经典方法已经证明了特征交互在处理高维特征属性和大规模数据集方面的有效性。例如,Wide&Deep和DeepFM通过浅部和深层组件学习显式低阶和隐式高阶特征交互。然而,现有的特征交互搜索方法只能搜索一个特定的层,而深度推荐系统的其他组件依然依靠手工设计,这导致了三个问题:(1)上述自动搜索方法无法直接获得完整的推荐系统模型,还需要领域专家人工设计其他组件;(2)由于需要人工设计其他组件,因此不太可能获得性能良好的整体架构;(3)由于一个特定层而非整个体系结构的搜索空间有限,模型的通用能力降低。此外,经典方法中MLP层的设计在效率和有效性方面可能都不是最优的,但专家们无法尝试所有可能的设计架构。因此,自动模型设计搜索方法被用来搜索自动设计的特定于任务的架构,这其中主要有三个关键问题:
精确的搜索空间:自动模型设计方法的搜索空间应该仔细设计,同时搜索空间也不能过于笼统。
搜索效率:推荐系统可能拥有数亿级别的用户,自动模型设计搜索方法应该是高效的。
区分能力:自动模型设计搜索方法应该对模型的微小改进的进展敏感,以免错过最优模型。
现有的自动模型设计搜索的方法主要包括AutoCTR、AMEIR和AutoIAS。其中,AutoCTR提出了一个两级分层搜索空间,通过将不同的特征交互方法抽象为虚拟块,该空间包括流行的人工构建的深度推荐系统架构。AMEIR将推荐模型分为三个阶段:行为建模、特征交互和MLP聚合,其中行为建模网络基于顺序输入特征封装用户的特定和动态兴趣。AutoIAS统一了现有的基于交互的点击率预测模型体系结构,并提出了一个完整的点击率预测模型的集成搜索空间。尽管这些模型非常有效,但自动模型设计搜索的最大挑战之一是巨大的搜索空间。为解决这个问题,AutoCTR采用多目标进化搜索而非梯度下降方法,并行探索广阔的搜索空间。AMEIR使用一次性随机搜索来加速搜索过程,而AutoIAS使用DNN来建模不同组件之间的依赖关系。
2.4 其他组件搜索
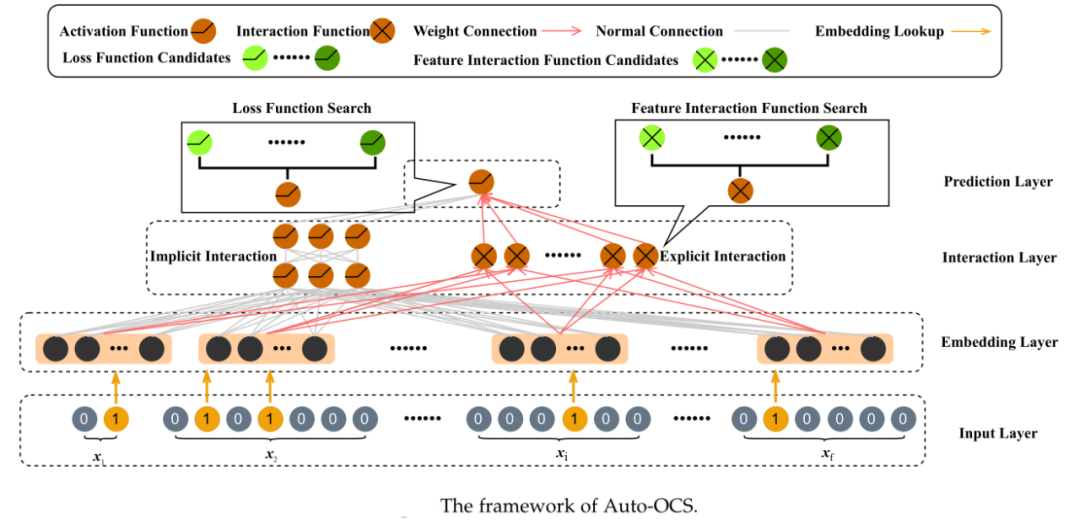
除了针对嵌入维度、特征交互和模型设计的自动化搜索,推荐系统的其他组件也可以通过自动化机器学习找到最优选项,其中最关键也是最受关注的是对损失函数的特征交互函数的搜索。
损失函数搜索(Loss Function Search)从损失函数候选集合中选择关于不同任务和目标的适当损失函数。在推荐系统领域,损失函数搜索的相关研究工作并不多。例如,AutoLoss提出一种包含控制器网络的端到端框架,可以通过数据驱动的方式选择合适的损失函数来提高推荐性能和深度推荐系统的训练效率。
特征交互函数搜索(Feature Interaction Function Search)根据不同的数据集搜索合适的交互函数 。相比大多数文献使用相同的特征交互函数来建模所有的特征交互,特征交互函数搜索考虑了不同特征之间的区别,一定程度上防止模型陷入次优性能。例如,SIF被提出用于自动选择协同过滤(CF)的交互函数 ,AutoFeature将计算图(DAG)引入搜索空间,通过独特的DAG子网络结构,将适当交互函数搜索扩展到高阶。
3. 未来研究方向
尽管已经有相当一些工作将AutoML引入到深度推荐系统,但仍有一些研究方向有待探索。
特征冷启动。在实际的推荐系统中,可能会实时添加新的特征,如何有效地为这些新特征分配嵌入维度仍然是一个悬而未决的问题。
长尾特征。由于长尾用户/项目的数据稀疏,其维度分配仍然是一个具有挑战性的问题。
理论分析。目前的方法在寻找模型的合适组件方面都表现出了很好的推荐性能,但很少有研究能提供坚实的理论分析来保证搜索策略的有效性。
终端设备的推荐系统。现有的方法大多关注部署在集中式云服务器上的模型,而忽略了部署在用户设备上推荐推荐模型。随着人们隐私保护意识的增强,针对终端设备上推荐系统的AutoML方法很有意义。
特定类型的推荐系统。随着图神经网络、多模态等技术的引入,推荐系统已经不仅仅局限于上述框架,如何针对不同类型的推荐系统设计AutoML方法,是备受关注的问题。
特定类型的推荐任务。除了一般的推荐任务和CTR任务,POI推荐、社交推荐、新闻推荐等推荐任务都有其自身的独特性,如何让AutoML算法适用于不同类型的推荐任务是有待研究的。
4. 参考文献
[1] Bo Chen et al., “Automated Machine Learning for Deep Recommender Systems: A Survey,” ArXiv:2204.01390 [Cs], April 4, 2022, http://arxiv.org/abs/2204.01390.
[2] Ruiqi Zheng et al., “AutoML for Deep Recommender Systems: A Survey,” ArXiv:2203.13922 [Cs], March 25, 2022, http://arxiv.org/abs/2203.13922.
更多推荐
SDM 2022 | GNN预训练中的自适应图表示 —— 图匹配任务