图模型在信息流推荐的原理和实践

分享嘉宾:郭沛东 一点资讯
编辑整理:吴祺尧
出品平台:DataFunTalk
导读:传统的机器学习定义一个学习任务和损失函数后,根据构建的属性使用梯度回传的方式优化特征参数。而图模型通过构造图属性,定义一系列节点和边,使得训练时的损失可以传导至目标节点的邻居节点上。例如相亲市场上,传统机器学习任务根据男生的特征如职业、薪资、学历等判断他是否是一个优质相亲对象,而图模型可以引入如亲属、朋友等关联节点来共同决定他的特征。上述例子表明在信息流召回业务中引入图模型更加可靠。本次我分享的题目是图模型在信息流推荐的原理和实践。
今天的介绍会围绕下面四点展开:
图模型简介
召回业务简介
图模型算法应用及部署
总结与展望
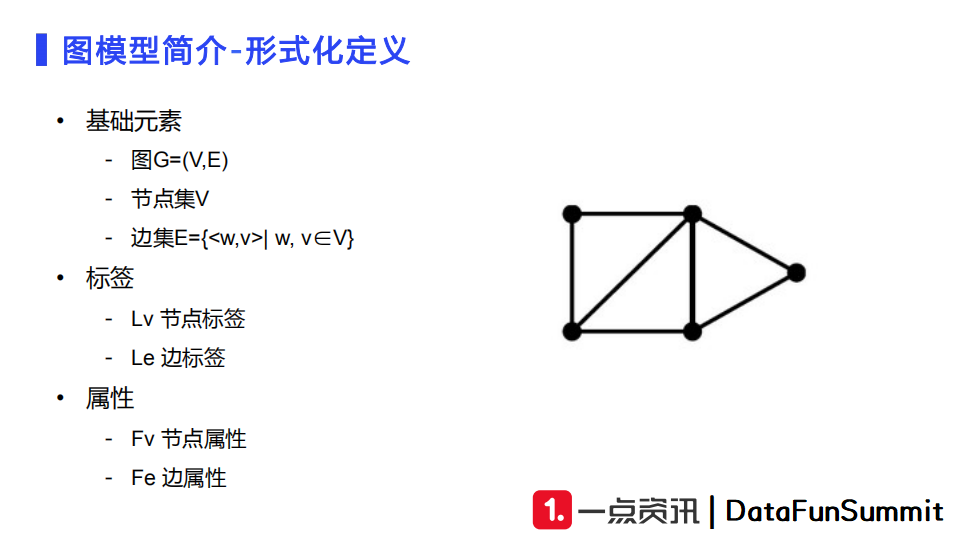
图模型广泛存在于日常生活中,如社交网络、通信网络、蛋白质结构以及知识图谱。图是由一系列节点和边构成的。其中节点是我们定义的实体,它构成了一个节点集;边是两个节点之间连成的一条线,分为有向边和无向边。图中我们还可以附加定义一些标签和属性特征。标签可以为边标签,也可以为节点标签。对于节点的属性,若节点被定义为用户,那么属性可以被定义为用户的性别、用户的年龄、用户的职业等;若节点为用户与文章,那么用户和文章产生的交互行为,如点击、分享等,或者是用户停留时长、时间戳,都可以作为边的属性。
根据构建的图我们可以设计出很多任务,大致上分为三类:节点预测、边预测和子图预测。例如,节点预测可以应用于预测用户、文章的类型;边预测可以是判断用户和文章之间的连接度有多高(点击率、时长、点赞等);子图预测从整个图上切出一小部分子图,可以设定回归任务来预测子图的潜在值或者设定分类任务来预测子图的类别。图模型的常见应用场景包括商业推荐、社交好友推荐、反欺诈、芯片设计、路况预测等。
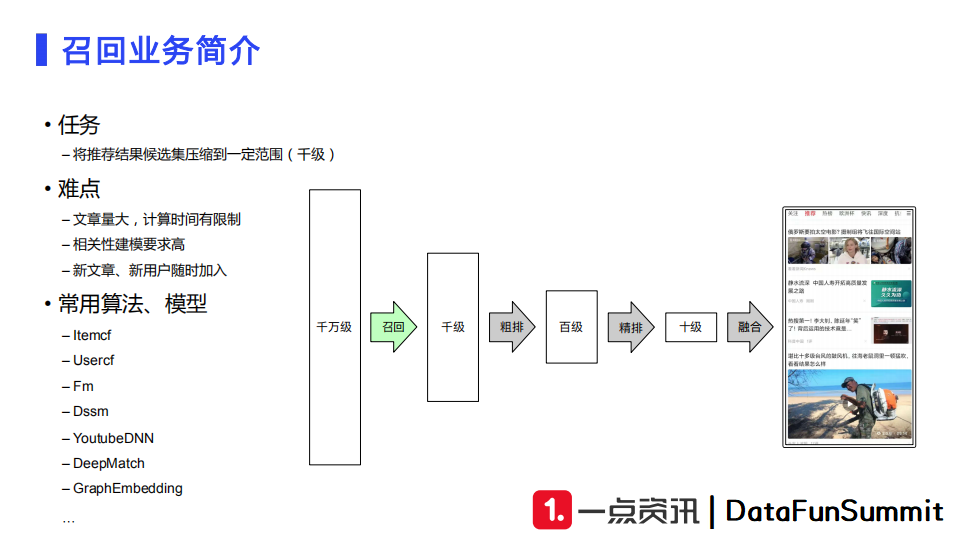
我们信息流中推荐业务主要的应用场景是资讯。资讯有很多类型,如图文、视频、音频等。召回的主要任务是将大量入库的候选文章从百万级甚至千万级在几十毫秒的响应时间内检索出千级的范围。请求可能是用户的主动搜索,也可能是随机浏览。召回完成后我们再经过粗排、精排、融合,最后给用户呈现推荐的信息流内容。
召回服务面临的主要难点是:
候选文章量非常大,且每天都有非常多新内容产生,但我们的计算时间非常有限(100毫秒内完成);
召回对于相关性建模的要求非常高,若召回不能保证相关性,那么后续的粗排、精排和融合模块容易产生bad case;
新文章、新用户会随时加入业务场景,我们需要一个很好的方式去表达这些新用户和新文章。
召回常用的方法和模型包括:Itemcf、Usercf、Fm、Dssm、YoutubeDNN、DeepMatch等。最近几年比较火的是图模型,也就是基于Graph Embedding的方法。
1. 构图
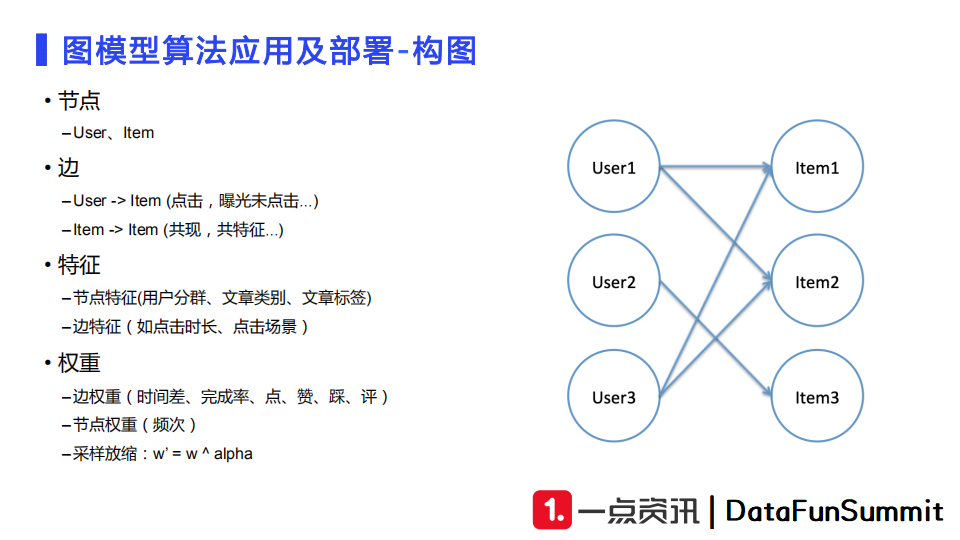
上图展示的是我们的推荐业务中常用的构图方式。
首先,我们定义节点为user和item两类。
边的定义方式可以将图分为二部图以及同构图。二部图有user节点和item节点组成,如果user和item产生了点击、分享、收藏等交互行为,那么我们就在节点之间连上一条边。同构图中节点均为item,如果item共现次数达到一定量级、或者它们有相同的属性,那么它们之间也可以连上一条边。
之后,我们需要构建特征,主要是特征工程的内容。对于用户节点,我们会将用户分群、用户画像等特征作为用户特征;对于文章节点,我们会把文章的类别、文章标签、文章的来源等作为节点特征。边特征可以选取点击时段以及点击应用场景等环境信息。
最后,我们需要设定边的权重。边的权重往往表示重要性,比如从文章入库到文章产生点击的时间差、点击的完成率、赞、踩、评等。我们会使用合适的加权来提升样本的重要性。节点的权重主要根据其出现频次来进行加权,通常会在全局负采样的时候使用。在定义好权重之后,我们还会采用采样放缩的技巧对原有的权重做指数放缩,来使数据分布更加平滑。
2. DeepWalk
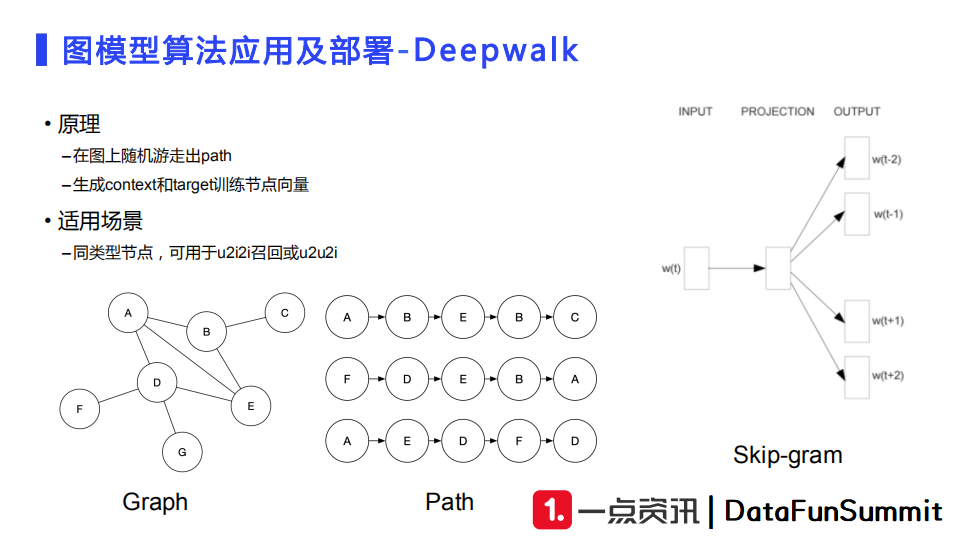
第一种常用的模型是DeepWalk。我们在构建好的涂上随机选取初始节点进行随机游走,产生一些路径。这些路径可以采用类似于Word2Vec的方式继续训练,得到节点向量。DeepWalk的主要适用场景是同类型的节点,即类似于我们item-item的同构图,主要应用于u2i2i召回或者u2u2i召回。我们可以使用DeepWalk训练生成大量的文章向量,它们可以用于建库,然后做相似文章的检索服务,或者对相似用户的文章进行检索。
3. LINE
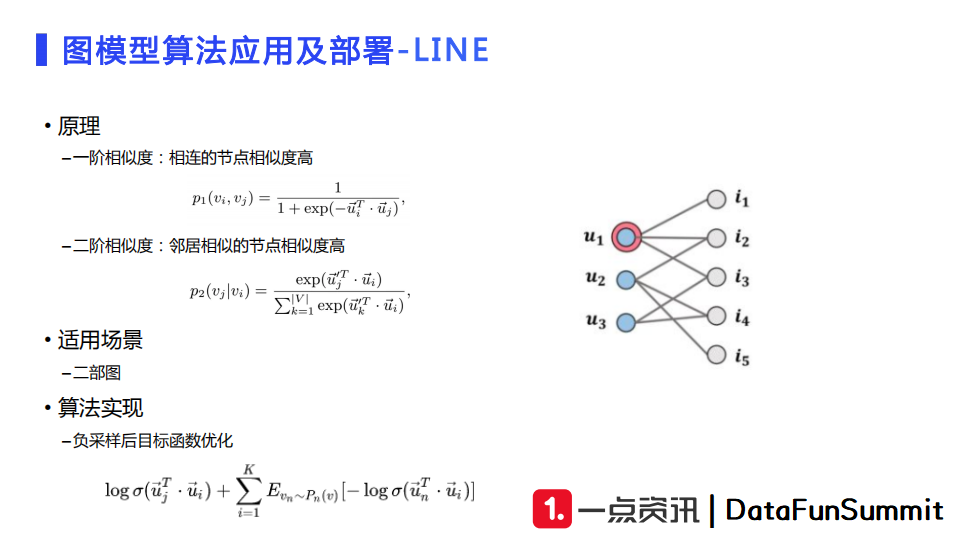
第二种模型是LINE,它的优点是训练速度比较快,计算代价较低。LINE中定义了一阶相似度和二阶相似度。一阶相似度的定义是如果两个节点直接连接,则它们的相似度比较高。二阶相似度的定义类似于协同过滤的概念,有共通邻居的节点,相似度较高,例如点击相同文章的用户相似度较高,或者被一个用户点击的两篇文章关联度较高。我们在业务中更多地会去使用二阶相似度。
LINE的适用场景是二部图,即图中既有用户节点又有文章节点,文章和用户之间有边、用户之间以及文章之间不存在边。通过LINE进行训练可以得到用户向量和文章向量。通常我们会使用负采样进行优化,将一些正样本和采样到的负样本构成一个batch,再去使用sampled softmax损失函数去训练LINE。
4. Graphsage
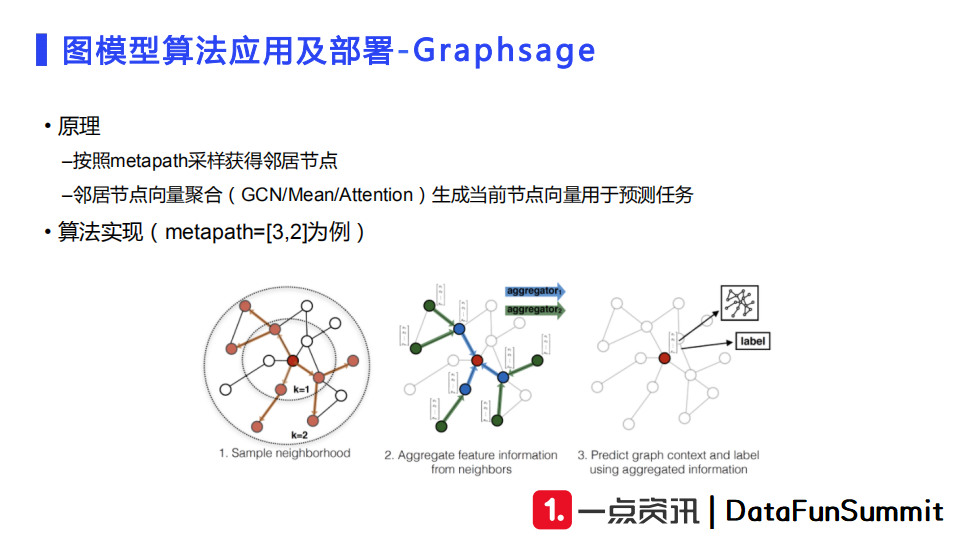
另外一个使用效果较好的模型是Graphsage。它的计算过程相当于从一个节点出发进行多跳聚合。例如,我们从一个用户节点出发,先跳至其邻居节点(如文章节点),再跳至另一个用户节点。这样相当于先将最外层的用户节点向量聚合得到文章节点向量,再由文章节点向量聚合得到目标用户的向量表达。
Graphsage的优点在于训练效果比较好,但是存在的问题是较慢的训练速度和较高的硬件要求。模型需要设定的参数包括向量聚合方式,如均值、加和或者attention。当新文章、新用户入库的时候,一旦他们产生了交互行为,那么使用这一模型就可以很好地产生用户向量和文章向量。
5. 损失函数

选取好图模型之后,我们就可以设计损失函数了。
常用的baseline损失函数是Cross Entropy(交叉熵),它常用于二分类问题,如节点之间有无连接,它的计算速度比较快。
在Cross Entropy基础之上,我们可以针对业务需求调整损失函数的权重,例如我们的任务是完成率优先或者时长优先,那么我们可以给Cross Entropy进行加权。
另外一个经常使用的损失函数是Pairwise的BPR Loss。它需要构建一个正负样本对,相当于一个用户点击了a文章没有点击b文章,那么在训练时网络尽量应该使用户点击a文章的得分比点击b文章的得分差距大,让a文章的得分更高,b文章的得分更低。这样我们可以拉远文章a的向量与文章b的向量之间的距离。
Triplet Loss是一个限定预测边界的设计方式。训练的时候使用Triplet Loss相当于将正样本和负样本的分数差距设置了一个阈值,若距离足够大那么就认为样本学习得很不错,就不会产生loss了;而当正负样本区分度较低时才会产生loss。Triplet Loss对margin的调参要求较高。
我们还需要对训练样本进行一些处理。首先,我们需要做正样本权重的优化,比如点击的权重置为1,评论、点赞、分享的权重会调整得高一些,这样可以使得模型更倾向于学习高权重的样本。第二个技巧是使用时间衰减。构图的时候点击事件发生时间与最近交互行为较近的正样本需要做增强,而点击时间较为久远的正样本需要做一些权重衰减。此外,我们需要对时长进行加权,如视频的时间长度不一致,有些长达一个小时而有些只有几分钟,那么我们需要对它们根据设定的阈值进行截断,或者使用指数平滑的方式使得正样本与正样本之间的权重差别不至于过大。这种做法会使得模型训练收敛性更好。
针对负样本,由于召回任务中面临的负样本的数量巨大,而实际线上真实曝光的数量非常少,所以我们需要从全局中采一些负样本做训练。目前我们按照文章的类型去做负采样,比如根据视频证样本取视频负样本构建batch,图文正样本则对应图文负样本构建batch。我们也会进行用户的负采样来帮助低频用户快速更新用户向量,避免他们点击次数较少导致向量参数更新次数较少,进而使得向量没有被充分更新。最后,我们借鉴Facebook提出的hard样本的优化方案,从Top101-500中筛选一些样本作为batch的负样本。
模型线上部署的召回方式主要由u2i,u2i2i和u2u2i。u2i根据用户向量直接召回相似文章,即对文章向量进行建库,然后拿用户向量做检索。这种类型的召回用于长期稳定兴趣的建模。u2i2i主要根据用户点击的文章,将它们的向量作为检索的query来召回索引库中的相似文章。这种类型的召回响应速度较快,常用于短期兴趣的追打。u2u2i类似于usercf的召回,我们需要对用户向量进行建库,然后在得到当前用户的向量后检索出topN个相似用户,再根据相似用户向量选取他们的点击文章向量再做一次聚合,最终得到当前用户的召回结果。这种类型的召回常用于做兴趣拓展。
6. 效果评估
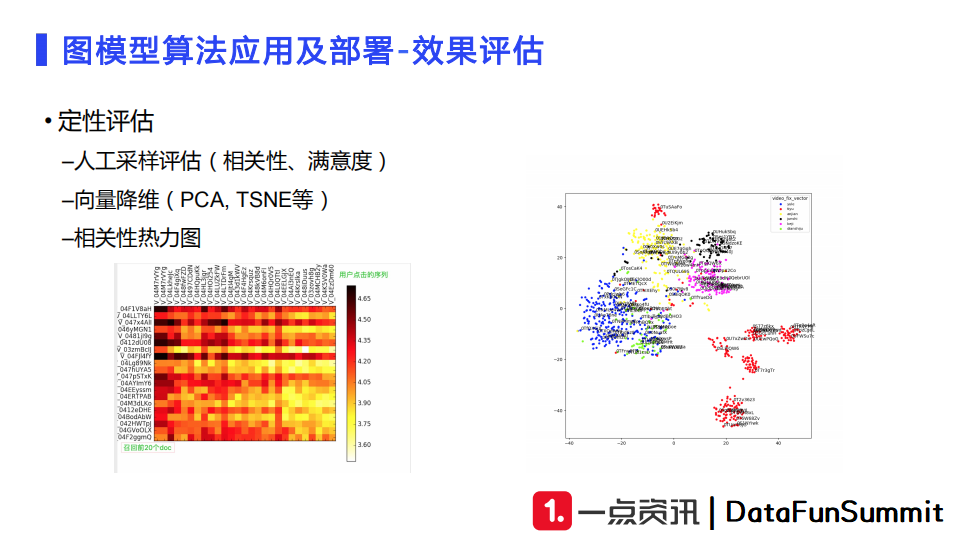
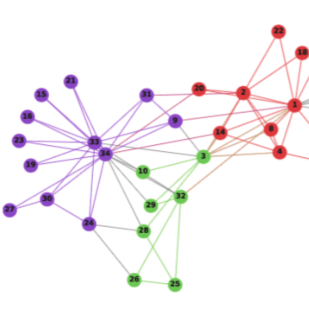
在模型上线之前还需要做效果评估。第一步的评估是定性评估。比如我们输入一些用户请求,根据用户的历史行为观察模型召回结果,评估结果的相关性和满意度。我们还可以对召回向量进行降维,如上图所示。降维的方式有PCA以及TSNE。降维之后我们可以根据向量的类型来打上不同颜色的标签,观察相同类型的向量是否聚到了一起,不同类型的向量是否分开。分析向量相关性的时候,我们也可以将点击文章向量和召回的文章向量计算相关性构建热力图来评估整体相关性。
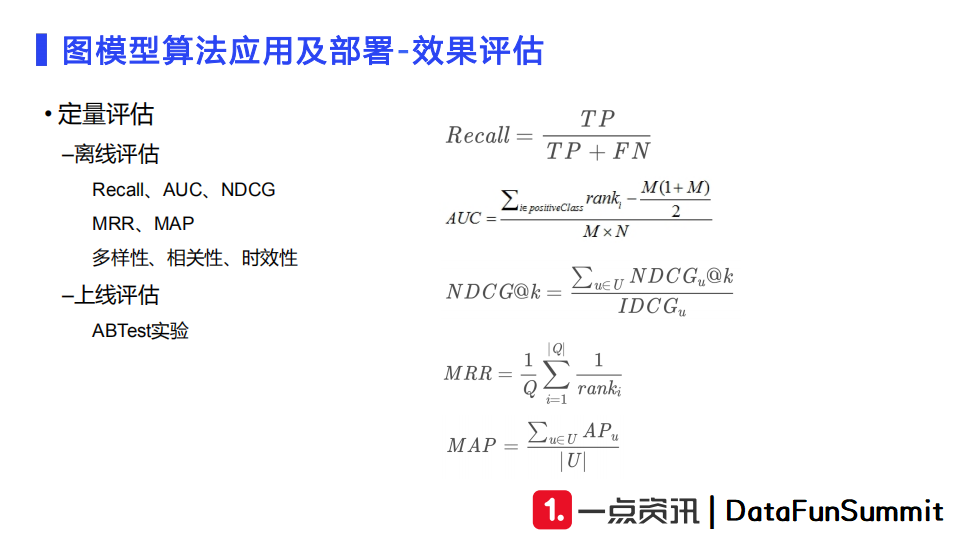
定量评估的指标有召回率、AUC、NDCG、MRR和MAP。对于召回任务,我们还会补充多样性、相关性和时效性等指标。离线评估完成后,就可以进行线上ABTest实验了。
7. 训练及上线
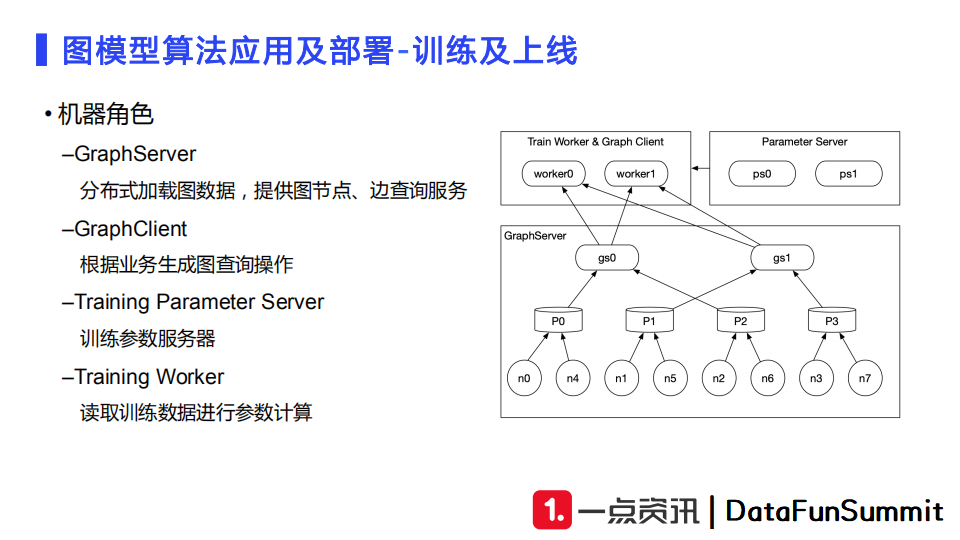
工程部署我们会有GraphServer、GraphClient、Training Parameter Server、Training Worker这四种角色。
GraphServer主要用于分布式加载图数据,提供图节点、边查询服务;
GraphClient主要根据业务写的查询语句或者查询操作生成发送给GraphServer的图查询操作;
Training Parameter Server和Training Worker是基于Tensorflow做的底层分布式训练框架,主要用于线上的分布式训练的数据读取及参数计算。
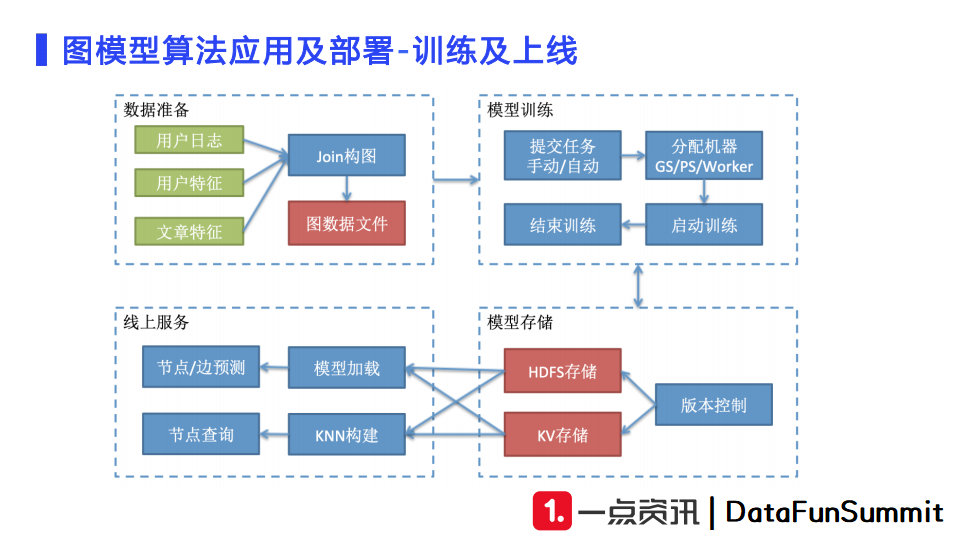
我们得到用户日志、用户特征和文章特征之后,首先需要进行join构图,产生图数据文件,完成数据准备。第二步,我们需要对模型进行训练。借助机器学习平台,可以实现机器分配,训练实例部署,模型训练。训练完毕后,我们需要定期将模型保存到HDFS上做版本控制。我们还会把训练完毕的向量存入KV方便线上使用。这样线上有请求到来的时候,我们可以从KV中查询出向量,向KNN服务发起请求召回相似的文章或者用户向量来做线上服务。
在推荐召回阶段中,图模型使得样本的比例调整变得更加灵活,样本的分布更加平滑。其次,由于一些节点也作为特征进行建模,图模型可以使得loss能传导至邻居节点,减少了模型的整体预测误差,而DSSM和FM这些传统模型只能针对当前样本特征做参数更新。
但是目前召回场景中还面临着很多问题:
User和item的冷启动问题需要被解决;
模型存在bias问题。比如有的用户点击量比较多并不代表这个用户的样本很重要。又如位置偏差,即召回的item有可能因为排在前面导致其CTR偏高,这时候我们需要进行纠偏操作;
频次对模型的拟合效果影响较大。模型会被活跃用户以及高频文章影响,导致低频用户和长尾文章难以得到充分拟合;
大样本下的扩充学习需要进一步探索。目前业界比较流行的方法是对比学习。我们也可以在已有的模型的基础上做一些样本和图数据的扩充,使得模型更加鲁棒。
Q:图数据文件是直接使用文件还是类似于neo4j的图数据库进行存储的?
A:我们会设定一个定时任务来拼接生成图数据文件,以文件的方式存储至hdfs。在线上使用时是从hdfs上拉取图数据文件,加载至内存中使用的。
Q:离线效果提升但是线上效果反而下降,请问一般如何排查原因?
A:对于召回来说,出现这一现象有时需要查一下数据的时间是不是错位了。比如有时候在训练时存在标签泄漏,或者构图的时候训练的节点和边没有与测试集中预测的节点和边分开,这样就导致离线预测效果偏好。此外,我们还可以去看一下训练数据处理后特征是否存在线上流量特征存在比较大的偏差。
Q:用户向量和文章向量使用在排序阶段会不会有效?
A:在排序模块会使用召回侧生成的向量作为辅助特征,比如在相关视频推荐中我们会把文章向量输入至排序侧,使用文章向量的相似分值作为一个特征参数进行调参。一般来说这种做法对排序效果的提升有一些效果。
Q:图模型可以解决您在总结和展望部分提及的几个问题吗?
A:这些挑战其实是整个推荐召回场景中所共同面临的,图模型可以缓解部分问题,例如模型的debias等。比如有的用户点击了1000个item,有些用户只点击了1个item,那么我们可以使用图模型的采样操作来减少这两类用户之间的偏差,使得低频用户也可以得到很好的学习。对于user和item的冷启动问题,如果不产生交互,我们还是只能使用特征推断的方式来得到向量,此时这和传统dssm以及fm模型面临的问题相同,无法得到解决。但是一旦产生了交互,我们就可以生成一条边,然后使用目标节点的邻居节点的信息来辅助预测,进而缓解冷启动问题。
Q:图的特征是怎么构建的?
A:这主要是看节点是如何定义的。比如定义用户节点时,我们会使用用户画像特征;定义文章节点时,我们就会选取文章的画像,即文章的标签、类别等,来构建节点特征。
Q:邻居节点是否有权重?权重是如何计算的?
A:邻居节点是有权重的,且这个权重会根据业务进行调整。比如我们的目标是强时长相关的,那么我们希望文章停留时长越大的节点权重越大。具体地,我们会对时间做平滑操作以及阈值截断。例如阈值可以设定为5分钟或者15分钟,如果超过这个阈值则将其截断。然后我们会对其进行平滑,因为一秒钟和十五分钟在数值上相差900倍,通过平滑就可以把它限定在五六倍的差距。
Q:u2i2i的召回是先训练u2i再训练i2i吗?
A:u2i2i还是直接使用item之间的构图,即直接训练i2i就可以了。使用u2i2i的召回时首先先通过存储将用户的最近点击全部存储下来,然后我们可以使用点击的item适应i2i的KNN检索来得到相似文章向量。
Q:如何解决大样本问题?
A:大样本构图存储方面,往往采用分布式方案加载图数据。另外大数据在训练中存在的最大问题是噪声数据,大样本会对其中的长尾样本很不友好,有一些debais相关的工作处理推荐中的噪声数据。
Q:负样本的采样分为文章负采样和用户负采样,哪一种效果更好?是一起使用还是分开使用?
A:我们目前是一起使用的,相当于做了样本扩充,因为原有的样本存在严重的马太效应,所以需要唤醒沉默用户/文章的向量。两种负采样本质上的目的相同,没有孰好孰坏。
Q:图模型的孤立点如何处理?一些行为较少的用户以及没有交互行为覆盖的文章如何得到向量?
A:孤立节点只能使用特征推断的方式来得到向量。具体地,我们使用predict server,得到它使用的特征,同时将邻居节点的特征全部mask起来,最后我们也可以得到它的向量,但是这个向量一定是没有直接训练出来的向量效果好。对于交互行为较少的用户和没有交互行为覆盖的内容,我们会首先判断用户和文章本身是否存在画像信息。如果存在画像特征,那么我们也可以推断出对应的向量。
Q:图模型使用的数据是多久范围内的数据?图模型针对新用户有策略上的优化吗?
A:图数据分为半年至一年的量级,天级以及小时级的数据。对于新用户,若它完全没有点击且没有用户画像,那就需要借助非图模型的方式,比如挖掘热门内容来进行优化。
Q:hard样本的比例一般选取多少比较合适?
A:Hard样本的比例一般会选取得偏小一些,且加入训练样本的时间会较晚。一般我们会选取1%至10%这个区间内。
Q:Graphsage和GAT哪个模型更适合推荐场景?
A:我们这边使用的是Graphsage,它的优点是聚合函数比较简单,计算速度会较快,从而向量会训练得比较充分。GAT因为包含attention结构,它的计算复杂度更高,对计算资源要求更高。在推荐的大数据场景下,Graphsage可能会更合适一点。只不过模型的选取需要根据实验情况,哪一个更合适就使用哪一个。
Q:请问边权重会做归一化吗?
A:边权重会先做一些处理,生成采样表后做归一化。比如针对用户点击的文章次数,有的文章这个数值会达到几十万,而有些文章的点击只有几次,那么我们会使用采样缩放技术做权重调整,使得其更为平滑。
Q:Hard样本Top101-500是按排序打分进行排序的吗?
A:我们目前版本是对文章向量进行定时建库,然后使用KNN从Top101到500中挑选近邻向量。所以它并不是按照排序得分。Facebook使用的是排序打分,但是我们这里因为排序打分可能存在数量极少的情况,所以使用的是训练得分。
Q:时间衰减的逻辑一般如何设定比较合理?
A:首先我们需要分析数据类型。比如业务具有强时效性、强新闻性,那么设定时间衰减时可以看一下近几天的文章分布比例,选取一个合适的衰减曲线。如果业务是弱时效性的,那么时间衰减的逻辑没那么重要。
Q:视频和图文在召回后分别会留下多少候选样本?
A:我们这边其实图文和视频是两个队列,经过召回、粗排、精排过后两个队列都不会合并。视频和图文的合并是在融合排序的环节进行的,所以召回场景下不存在两类内容分别留下多少的问题。我们这边视频文章量比较大,所以视频样本会稍微多一些,大约为图文的1~2倍。
Q:召回的多路合并排序是么做的?如何评估加入图模型作为新的召回后,相较于其他召回路径的增量效果?
A:召回的多路合并排序是一个粗排模型,主要负责根据当前用户请求来设定对应的配额。会有一些保量逻辑或者提权逻辑加入粗排环节。评估相对于其他召回路的增量信息是一个集合判定问题,不仅限于图模型召回。我们根据新的一路召回,会与原来的召回结果做对比,观察新召回与之前的结果有多少内容是重合的,有多少内容是只有新召回所独有的。
今天的分享就到这里,谢谢大家。
分享嘉宾:

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“图模型” 就可以获取《图模型专知资料合集》专知下载链接