稀疏性的3个优势 -《稀疏统计学习及其应用》

统计机器学习界泰斗作品
“本书涵盖了统计学的所有重要分支,每个主题都有基本问题的详尽介绍和求解算法,给出了基于稀疏性的分析方案。可以说,此书就是稀疏统计学习的标准教材。”
——Anand Panangadan,加州大学富勒顿分校
下文节选自《稀疏统计学习及其应用》, 已获出版社授权许可, [遇见数学] 特此表示感谢!
这段话是棒球投手 Dizzy Dean 说的,他曾在 1930 ∼1947 年参加美国职业棒球大联盟的比赛。
一晃 75 年过去了,世界发生了很大的变化!如今,人们在科学、娱乐、商业和 工业各领域收集和挖掘大量数据,并对其进行研究和应用。医学家们通过研究患者 的基因组选择最佳的治疗方法,并由此了解这些疾病产生的根本原因。在线电影和 网上书店会研究客户的评价,以便向他们推荐新的电影或书籍。社交网络会研究其 会员及好友的资料,优化在线体验。而且,现在多数大联盟棒球队都有统计员收集 和分析击球手和投手的详细信息,帮助球队经理和队员做出更好的决策。
由此可知,这个世界淹没在了数据中。而 Rutherford D. Roger 等人则说: “我们淹没在了信息的海洋里,却渴求着知识。” 海量信息亟待整理,取其精华去其糟粕。为了成功完成这项工作,人们期望真实情况得以简化:也许人体内大约 30 000 个基因并非都与癌症的发展过程直接相关;也许只需要客户对 50 或 100 部电影做出评价就足以揭示他们的爱好;也许左 撇子投手对付左撇子击球手会比较轻松。
这些情形背后都有简单性假设。稀疏性(sparsity)是简单性的一种形式,这也 是本书的中心主题。简而言之,在一个稀疏统计模型中,仅有较少参数(也称预测 子,predictor)在发挥重要作用。本书将介绍如何利用稀疏性来恢复一组数据中的 基础信号。
最典型的例子是线性回归,即有 N 组观测值,每组观测值由一个输出变量 yi 和 p 个相关预测子变量(也称特征)xi = (xi1, . . . , xip)T 所组成。线性回归的目标 是通过预测子来预测输出值,既要正确预测将来的数据,又要找出哪些预测子在起 重要作用。一个线性回归模型可设为:
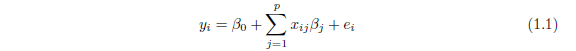
其中,β0 和 β =(β1, β2, . . . , βp)是未知参数,ei 为误差项。这些参数可用最小二 乘法来估计,即最小化最小二乘目标函数:
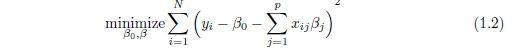
通常,式(1.2)的所有最小二乘估计都不为零。若 p 很大,则最终模型会变得难以 解释。事实上,若 p > N ,最小二乘估计的结果并不唯一,有无穷多个解可使目标 函数为零,而且大多数解都会过拟和(overfit)数据。
因此,这个估计过程需要进行约束(即正则化)。可采用 lasso(即 f1正则化) 回归,通过求解问题
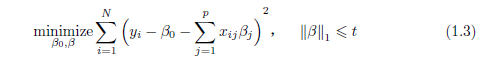
来估计参数,其中,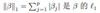
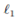
为什么要采用 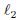
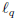
因此,稀疏性的优势在于它可以解释拟和的模型,并且计算简单。除此以外, 最近几年人们对该领域进行了深入的数学分析,发现稀疏性还有第三个优势,这个优势称为押注稀疏性(bet on sparsity)原理: 既然无法有效处理稠密问题, 倒不如在 稀 疏问题上寻找有效的处理方法。
(注: 人民邮电出版社65周年庆 京东每满200减100(活动时间:10月23~25日)图灵所有图书都参加活动, 点击[阅读原文]跳转查看)
具有稀疏性的统计学习
我们可从每个参数的信息量 N/p 来研究稀疏统计学习。如果 p 》 N 且真实模型不稀疏,则样本数 N 太小,无法精确估计参数。若真实模型是稀疏的,也就是说真实模型仅含有 k < N 个不为零的参数,则可使用本书所介绍的 lasso 和相关方法来有效估计这些参数。这可能有些让人惊讶,因为即使不知道 p 个参数向量 的第 k 个元素是否为零,也可以这样做。当然,这样得到的结果相对而言不那么准确,而事实证明这样的准确性也相当不错了。 综上所述,对于数据分析师、计算机科学家和理论家而言,稀疏统计建模是令人兴奋的领域,并且也很实用。图 1-1 就展示了这样的例子。这些数据来自 349 个癌症病人样本中的 4718 个基因,通过量化这些基因表达的测量值而得到。这些癌症分为 15 类,包括膀胱癌、乳腺癌、中枢神经系统肿瘤,等等。这里的目标是通过这 4718 个特征或部分特征来建立一个分类器,以预测癌症类别。所得到的分类器 应该对独立样本(independent sample)有低的错误率,并且仅依赖于基因子集,以 协助生物学基础研究。
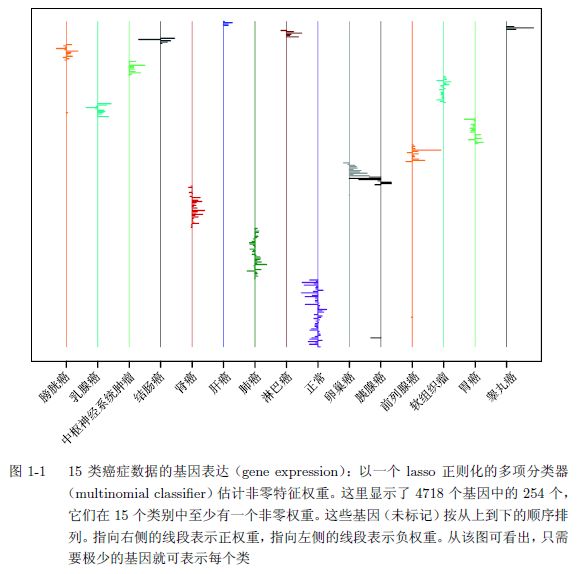
第 3 章会在这些数据上采用基于 lasso 正则化(lasso-regularized)的多项分类 器来实现该目标。这会对 15 个类中的每一个生成 4718 个权重(或系数),以便在 测试时进行区分。由于采用了 f1 惩罚,这些权重仅有一部分不为零(这取决于正则 化参数的选取)。可通过交叉验证(cross-validated)来估计最优的正则化参数,图 1-1 显示了由此所得的权重。图中仅有 254 个基因有非零的权重。对该分类器进行 的交叉验证,所得误差率约为 10%。也就是说,它能正确预测 90%的样本类别。相 比之下,使用所有特征的标准支持向量机误差率(13%)稍高一些。lasso 所具有的 稀疏性会在不牺牲精度的情况下大幅减少特征数量。稀疏性也提高了计算效率:虽 然可能要估计 4178 × 15 ≈ 70 000 个参数,但图 1-1 的整个计算在一个普通笔记本 上不到一分钟就可完成。第 3 章和第 5 章所介绍的 glmnet 程序包可以完成相关计 算。
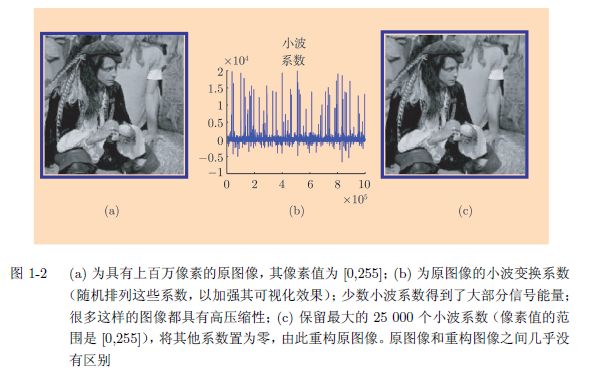
图 1-2 展示了另一个例子(Cand`es and Wakin 2008),属于压缩感知(compressed sensing)领域。图 1-2a 是一幅具有上百万像素的图像。为了节省存储空间,图像 可用小波基(wavelet basis)来表示,见图 1-2b。将最大的 25 000 个系数保留下来, 其余的全部置为零,图 1-2c 是基于这些系数重构的图像,效果非常不错。这一切 都归功于稀疏性:虽然图像看似复杂,但只有相对较少的小波基系数不为零。仅用 96 000 个不相关度量(incoherent measurement),原图像就可被完全恢复。压缩感 知是一种强大的图像分析工具,详见第 10 章。
本书意在总结稀疏统计模型最新的发展迅速的领域。第 2 章会介绍 lasso 线性 回归,以及用来计算这种回归的简单坐标下降算法。第 3 章会介绍 f1 惩罚项在广 义线性模型(比如多项式模型、生存模型以及支持向量机等)中的应用。第 4 章会 介绍广义惩罚项,如弹性网(elastic net)和分组的 lasso。第 5 章会介绍优化问题 的数值计算方法,重点介绍一阶方法,它能用于本书所讨论的大规模问题,第 6 章 介绍拟和 lasso 模型的统计推断,包括 bootstrap、贝叶斯方法和一些最新的研究方 法。第 7 章会介绍稀疏矩阵分解,并将这些方法应用到第 8 章的稀疏多元分析中。
第 9 章会介绍图和模型及其选择,而压缩感知会在第 10 章介绍。最后,第 11 章 对 lasso 的理论成果进行概述。
需注意,本书会介绍监督学习问题和无监督学习问题。第 2 章、第 3 章、第 4章和第 10 章讨论监督学习,而无监督学习会在第 7 章和第 8 进行讨论。(完)
☟ 点击【阅读原文】查看京东人邮社庆65周年狂欢主场




