一文读懂因果推测、倾向模型(结合实例)

原文题目:Propensity Modeling, Causal Inference, and Discovering Drivers of Growth
作者:Edwin Chen
翻译:张逸
校对:卢苗苗
本文共5400字,建议阅读9分钟。
本文通过举例为你介绍因果推测方法、倾向建模及增长的驱动因素。
在正文之前,先想象这样一个场景。
你刚开始一份新工作,而且最近看了《僵尸世界大战》这部电影,正处于一种怀疑人生的状态。再加上前不久你的两个初创公司因为缺乏数据开不下去了,所以你看什么都不太顺眼。
你最先开始考虑销售团队的影响。他们到底为公司带来了多少额外的收入?你遇见的销售人员们说他们推销的客户有90%都买了公司的产品,但你还是心存疑问:这些客户中,到底有多少是因为销售员的功劳才决定购买的?
所以你查看了工作日志,并且注意到一些有意思的事儿:上个星期是hack week,一半的销售员都因为要打电话收集资料而腾不出空来,然而这一周客户的转化率却没有发生变化。
正在百思不得其解的时候,一个同事走到桌边来。他拿了一提Soylent饮料,想让你尝尝。这个饮料看起来不怎么样,所以你问同事它好在哪,同事说他朋友喝了这个饮料几个月以后就能跑马拉松了。所以呢?他们刚开始跑吗?--当然不是,人家去年就能跑马拉松了!
Causal Inference(因果推断)
事物之间的因果关系毫无疑问是很重要的,但难点就在于如何确定这种关系。
考虑以下几个问题:
某个病人吃了一种新药以后身体情况有所好转,这种好转是因为药物的作用还是本来他的身体就在恢复?
是你的销售团队确实起到了作用,还是他们仅仅是向那些本来就要购买商品的客户进行了推销?
喝Soylent饮料(或者你公司的巨额广告投入)值得吗?
在理想世界中,只要我们乐意,就可以做实验来验证---实验才是检验因果关系的最好标准。但现实情况是我们不能这样做。就拿刚才那些例子来说,你不能让病人服用安慰剂或者未经测试的药品,这是有违道德的。而且公司经理们恐怕不会愿意为了潜在的短期收益把精力放在随机的客户上。同理,那些靠销售额领取奖金的销售团队也会反对这样做。
那么我们应该如何在没有A/B测试的情况下理解因果关系?这就是propensity modeling(倾向建模)和其他因果推断技术发挥作用的地方。
Propensity Modeling(倾向建模)
继续Soylent饮料的例子,我们用倾向建模的技术来分析喝soylent饮料到底有什么作用。为了解释清楚这个概念,接下来要开始一场思想实验。
假定Brad Pitt有一个双胞胎的哥哥,兄弟俩哪都一样:Brad1和Brad2一起起床,吃一样的事物,进行同样强度的体能锻炼等等。有一天,Brad 1 碰巧从街上的促销员那里得到了最后一打Soylent饮料,但Brad 2没有这样的好运气。所以Soylent只出现在了Brad1的食谱上。在这种情况下,可以认为,双胞胎此后出现的任何行为差异就是这个饮料造成的。
将这种情景带入现实世界,我们用下面的方法来估计Soylent对健康的影响:
对于每一个喝Soylent的人来说,找到一个各方面都比较接近他的不喝这个饮料的人。比如我们会将喝Soylent的Jay-Z和不喝Soylent的Kanye当做一组,或者喝Soylent的Keira 配对不喝Soylent的Knightley这样。
接下来我们就观察二者的不同之处来量化soylent的影响。
然而,在实践时找到两个非常相近的双胞胎是很困难的,如果Jay-Z比Kanye平均多睡一个小时,那么怎么保证二者真的很接近呢?
Propensity modeling(倾向建模)就是这种双胞胎匹配过程的简化。我们并不是根据所有的变量来匹配两个个体,而是根据一个简单的数字来匹配所有用户-----他们喝soylent的可能性(“倾向”)
下面是建立倾向分析的细节:
首先,选定一些变量作为特征(比如吃的食物种类,睡眠时间,居住地点等)
根据这些变量建立一个概率模型(即逻辑斯特回归)预测人们是否会喝Soylent。比如说,我们的训练集由一群人组成,其中有一部分人在2014年3月的第一周订购了Soylent,我们会训练一个分类器来对哪些人会喝Soylent进行建模。
该模型将用户开始饮用Soylent的概率估计称为“倾向得分”
形成一定数量的“桶”,比如总计有十个等级(第一个桶代表喝饮料的倾向是0.0-0.1,第二个桶是0.1-0.2,以此类推),将所有的实验数据放入对应的“桶”中。
最后,比较每个桶中喝饮料与不喝饮料的样本数据(比如测量他们随后的身体素质、体重或者任何其他健康指标)来估计Soylent的因果效应。
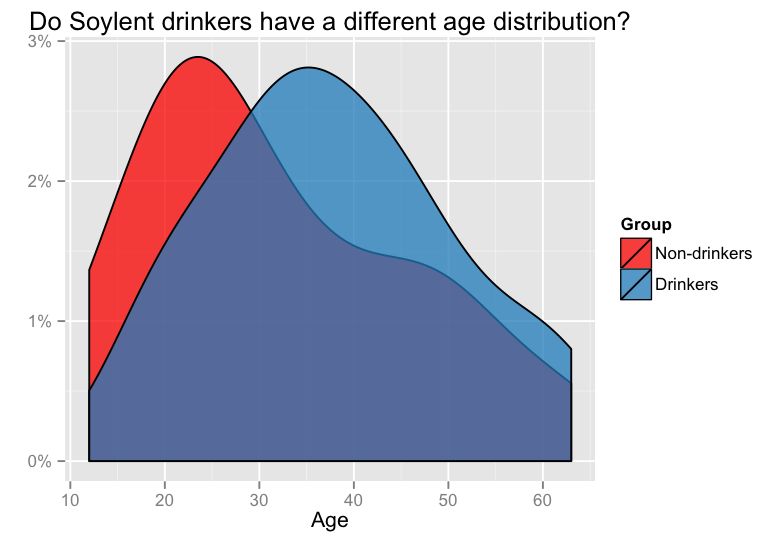
比如说,这有一个虚构的喝与不喝Soylent人群年龄的分布图。我们可以看到,喝Soylent的人群年龄要稍大一些。这个混杂的事实是我们不能简单地进行相关性分析的原因之一。
在训练好Soylent倾向估计的模型并将用户分配到对应桶中后,下边这幅图展示了Soylent对一个人每周运动里程的影响。
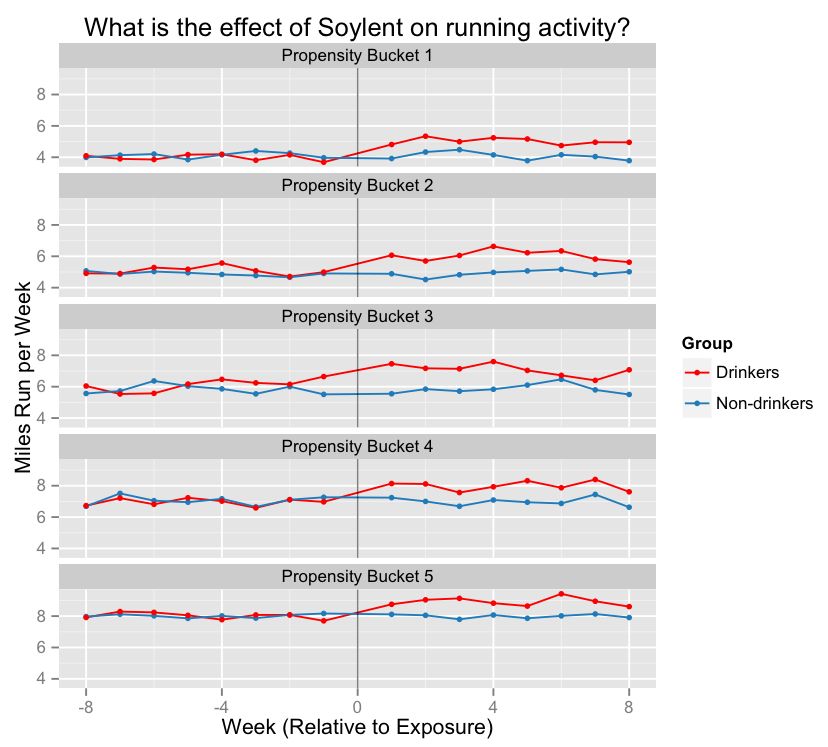
在上面的图表(假设的)中,每一幅行都代表了不同倾向等级的人群,开头代表的是三月的第一周,此时对照组收到了他们的Soylent饮料。在这个星期之前,我们可以看出,两组的数据轨迹差异不大,但当对照组开始按计划饮用Soylent之后,他们每周跑步的距离增加,这就形成了我们对饮料因果效应的估计。
当然,还有一些其他的因果推测方法。下面会讲两个我最喜欢的:
Regression Discontinuity(断点回归法)
这个例子是这样的:
Quora最近开始在它的top writers主页上展示徽章,我们想知道这个功能到底会产生什么样的影响。(假设现在功能已经上线,不能进行A/B测试了)。更具体的,我们想知道在主页展示徽章这个功能会不会给用户增加更多的关注者?
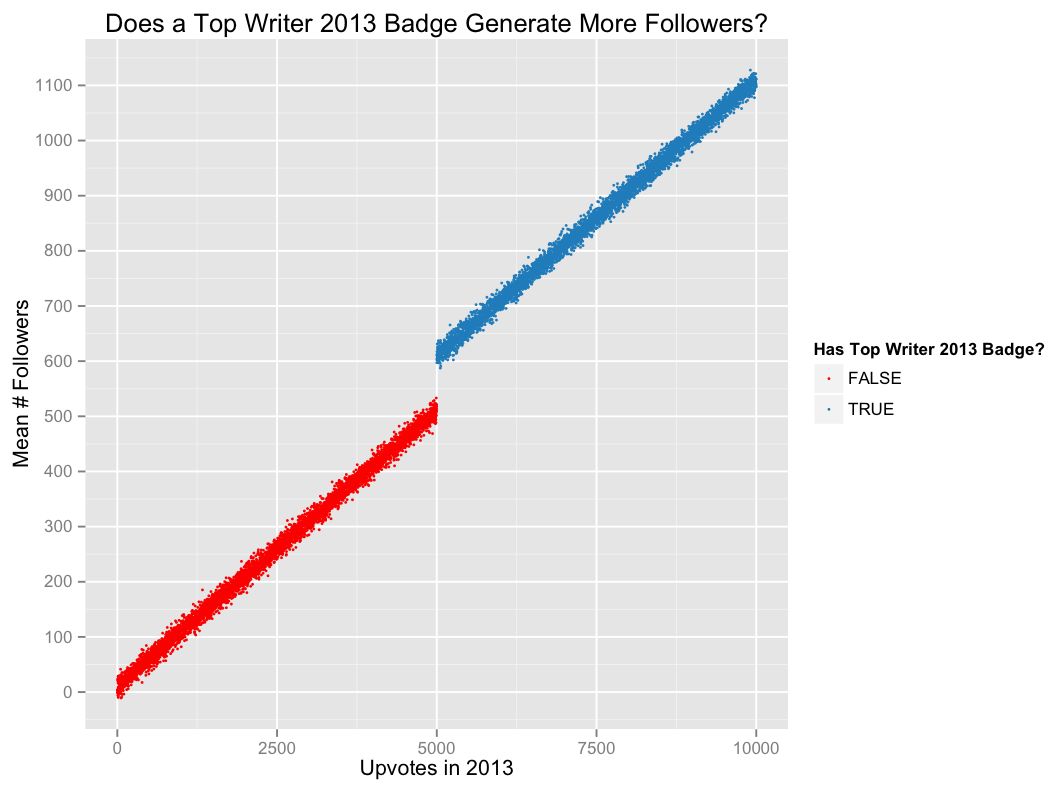
为了简化分析,假定2013一整年中获得赞数超过5000的用户有资格获得徽章。那么断点回归的关注点是那些刚刚好获得徽章(即有5000个赞)和那些差一点够资格(获得4999个赞)的用户,他们之间的差异或多或少是随机的。我们可以用这个阈值来估计因果效应。
比如说,在下面这个虚构的图表中,在5000赞这个界限处的不连续性表明,获得勋章的作者平均会多大约100多个粉丝。
自然实验法
不过,理解了top writer徽章的作用并没有什么意思,它只是为了解释这个概念举的简单例子。更值得深入探讨的问题是:当用户新发现了一个喜欢的作者后会怎么样?作者是否激励他们写一些他们自己的内容,去探索更多的相同的内容,并通过管理使他们更多参与到网站呢?换句话说,跟用户浏览随机的帖子相比,他们与这些厉害的作者之间建立联系是不是很重要?
为了更进一步讨论,得暂且先把这个虚构的Quora案例放下。来看看一个我在谷歌工作时研究的类似问题。
例如很多人会选择周日晚上待在家里追家庭主妇的更新,看完剧以后,人们可能就会停在这个频道上找其他节目来看。
这个问题是这样的:现在我们想知道给用户匹配一个“完美的YouTube频道”之后会发生什么,这种推荐的价值在何处?
用户对某一新频道的喜爱会不会带来对该频道一些超出本身的关注度? 因为用户可能会专门返回YouTube并留在新频道观看更多的节目。(倍增效应)
喜欢上一个新频道是否会增加在这个频道上的活动?(正面的影响)
新频道是否取代了YouTube上现有的互动?毕竟用户没有多少时间能花在网站上(中立的影响)
完美频道是否真的减少了用户在网站上花费的时间?因为他们一旦知道怎么迅速直接的找到想看的东西,就不会再网站上闲逛很久(负面的影响)。
同样的,在这个案例中进行A/B测试是不现实的,因为不能强制让用户喜欢或阻止他们浏览某一个频道(我们可以进行推荐,但不能保证用户会买账)。
一个解决办法是利用自然实验(在这个场景中,经验本身产生了类似随机的赋值。)来研究这种影响。以下是具体的方法:
设想某个用户在每周三都上传一个新视频。一个月之后,因为要去旅游,所以他通知收看这个频道的其他用户接下来的几周都不会有视频上传。
这些用户这时候会有什么反应?因为只有这个频道能够访问YouTube,所以他们在星期三就不上YouTube了吗?还是根本没有什么影响,因为这些用户只有在首页上出现这些视频的时候才会点开看?
想象一下,如果这个频道改在每周五上传视频,这些用户还会不会继续关注它?既然他们正在访问YouTube,他们只是为了新的视频,或许只是他们的访问导致了一连串的搜索和相关的内容?
事实证明,这种情况经常会发生。比如以下是一个受欢迎的频道上传视频的日历。你可以看到,在2011年,它喜欢在周二和周五上传视频,但在年底的时候改为周三和周六。
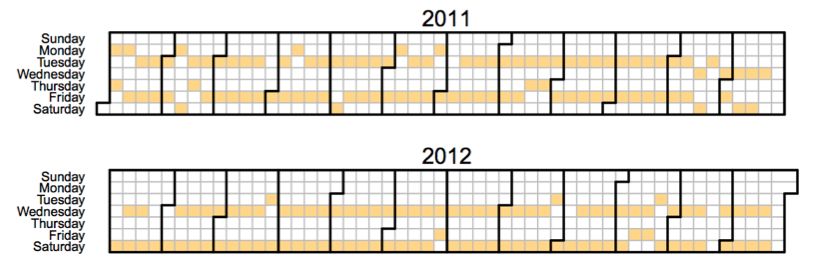
把这种转变当做一个自然实验,就好像是“随机”地把特定时间一个受欢迎的频道转移到另外的日子。从这,我们可以理解一个好的推荐的重要性。
上边这个例子作为一个自然实验有点过于复杂了,为了更清晰的阐明这个观点,假设我们需要理解收入情况对精神健康的影响,我们不能强行让一些人变得有钱或者没钱,与之相关的研究显然存在不足。这篇文章(链接:https://opinionator.blogs.nytimes.com/2014/01/18/what-happens-when-the-poor-receive-a-stipend/)描述了一种自然实验,即一群切诺基印第安人在向其成员分发开赌场所得的利润时,会“随机”地让其中一些人摆脱贫困。
在我上述的场景中,假定编程周期间并没有什么特别之处,另一个例子就是利用编程周,将其作为能类似随机“阻止”销售团队完成他们的工作的工具。
驱动力发掘
让我们回到倾向建模这个问题。
假设现在我们成为公司发展团队的一员,当下的任务是弄清楚如何才能将那些随机的用户转换成为常客。
这时可以采取倾向建模的方法。我们选择一些特征(比如说手机APP,登录注册信息,对某特定用户的关注等等)并为每一个特征建立一个倾向模型。然后,我们可以对所有参与因果估计的特征进行排名,用这个有序的特征列表来决定我们下一次的目标群体。(或者我们使用这些数据告诉执行团队我们需要更多的资源)。这是构建参与回归模型(或流失回归模型)以及检查每个特征权重的一个稍微更复杂的方法。
不过即便是写了这个帖子,我也并不热衷于对技术领域的很多应用进行倾向建模。(我没有在医疗领域工作过,所以不敢保证它的实用性到底怎样,但我觉得可能在这个领域还是比较需要倾向建模),就算下一次遇到类似的场景,我也会保留更多的意见。毕竟,进行因果推断是非常困难的,我们没办法控制所有的潜在影响因素,而这些因素恰恰会给实验结果带来偏差。另外,我们必须选择要包含在模型当中的特征(记住,构建特征非常耗时而且很困难)。这一点意味着我们对这些特征是否有用已经有了明确的判断,但是我们真正想做的却是发现那些隐藏的动机。
那么接下来还能怎么办?
打个比方,如果想知道为什么有些用户会成为网站的深度使用者,我们何不直接问他们呢?
具体来说,我们可以这样做:
首先选定几百个用户群体进行调查
在问卷中,我们会问用户,与去年相比,他们参与某一个网站的程度是增加,下降还是基本保持不变?紧接着,询问用户为什么会出现这种变化,让他们描述最近一次浏览这个网站的情况,或者让他们补充一些细节(例如他们的人口统计信息)。
最后,我们把在去年一年中参与度明显增加的用户的反馈筛选出来(如果相反,则选出显著下降的人群),分析他们给出的原因。
比如,下面是我在YouTube上进行此项研究时收到的一个有意思的反馈。

“我是一个音乐重度粉,最近沉迷于弹吉他,所以这一段时间会在YouTube上多看一些音乐会还有其他音乐相关的视频。当然了,包括很多的吉他教学视频(网址是www.justinguitar.com)”
从这个反馈中我们发现:用户有了一个新的线下爱好,然后会将这种爱好转嫁到YouTube上。这很好理解,比如想要开始在家做饭的人会到YouTube上寻找烹饪教程,想要开始打网球或者其他运动的用户会去找教学视频,大学生会找一些类似可汗学院的频道来辅助学习。换句话说,线下的活动会影响到线上行为。在这种情况下,我们就无需猜测用户到底对什么内容感兴趣(比如说,他们喜欢Facebook上的什么文章,他们在Twitter上追棒谁,他们喜欢Reddit上的什么文章),而是将关注点放在怎么把这些现实生活中的喜好转化到数字世界中。
这种“线下爱好”的想法肯定不会成为我投入到任何参与模式中的一个特征,即使只是因为这种特征很难生成。(我们怎么能知道哪些视频是与真实世界的喜好相对应的呢?)
但是既然我们怀疑它是一种潜在的增长驱动力(“潜在”,因为调查不一定具有代表性),这是我们可以深入探讨的问题。
结语
总结一下:在没有条件进行随机试验的时候,倾向建模是判断因果影响的一个有力技术手段。
不过,这种建立在观察研究之上的纯粹的相关性分析可能会产生一些误导。举一个我最喜欢的例子:我们发现某个城市警察越多,犯罪案件可能会越多---但这总不能意味着我们应该为了减少犯罪数量而减少警力吧?
还有一个例子,Gelman曾就研究激素替代疗法得出的矛盾结论在哈佛护士健康研究上发了一个帖子(有兴趣的朋友可以详细看一下,这里不展开讲了)(http://andrewgelman.com/2005/01/07/could_propensit/)
也就是说,只有数据足够优质,得到的模型才会比较好。但是我们又很难去把所有的隐藏变量考虑在内,结果就是可能你绞尽脑汁设计出来的模型在实际中并不比随机模型好多少。因此,可以考虑是不是还有其他的方法,无论是易于理解的因果分析技术,还是简单的去对用户进行调研,甚至说目前比较难实现的随机试验等等,这些最后都会对你的研究有帮助。
原文链接:http://blog.echen.me/2014/08/15/propensity-modeling-causal-inference-and-discovering-drivers-of-growth/
译者简介

张逸,中国传媒大学大三在读,主修数字媒体技术。对数据科学充满好奇,感慨于它创造出来的新世界。目前正在摸索和学习中,希望自己勇敢又热烈,学最有意思的知识,交最志同道合的朋友。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织



