【数据分析】数据分析就不用掌握Python了?看看这位数据分析师给的最全资料!
一,基本语法
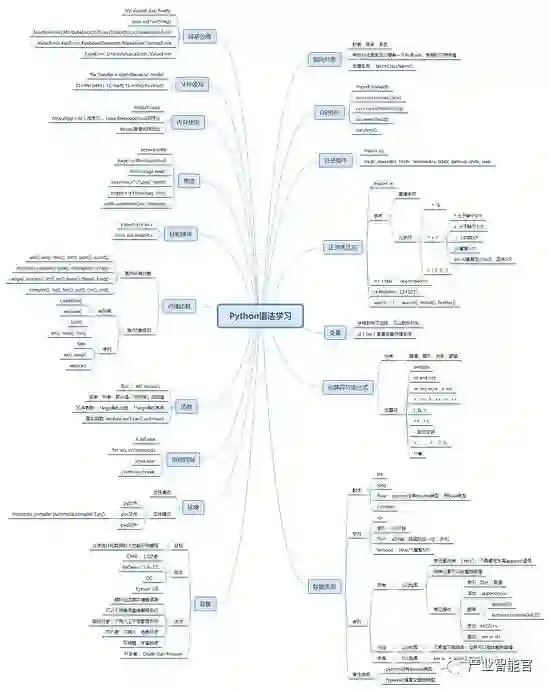
在给大家分享之前呢,小编推荐一下一个挺不错的交流宝地,里面都是一群热爱并在学习Python的小伙伴们,大几千了吧,各种各样的人群都有,特别喜欢看到这种大家一起交流解决难题的氛围,群资料也上传了好多,各种大牛解决小白的问题,这个Python群:330637182 欢迎大家进来一起交流讨论,一起进步,尽早掌握这门Python语言。

1)python3新增特性:
A:print()变化
B:新增字节类型,可以与str进行互换,以b字母作为前缀
C:新增格式()进行格式化处理
D:dict里面删除了iterkeys(),itervalues(),iteritems(),新增keys(),values(),items()
二,数据分析
2.1基本理论
1)数据处理的最基本前期工作:
A:类别型数据
明确取值类别
明确每类取值的分布
B:数值型数据
了解极值与分位情况
了解正态性,均值,方差情况
了解变量相关性
C:通用处理
缺失值情况
重复性情况
检查 - >清洁 - >转换 - >建模 - >发现有用的信息/建议结论/支持决策
2)常见的任务分类:
A:分类问题
B:回归问题
C:聚类问题
D:时序分析问题
2.2基本工具
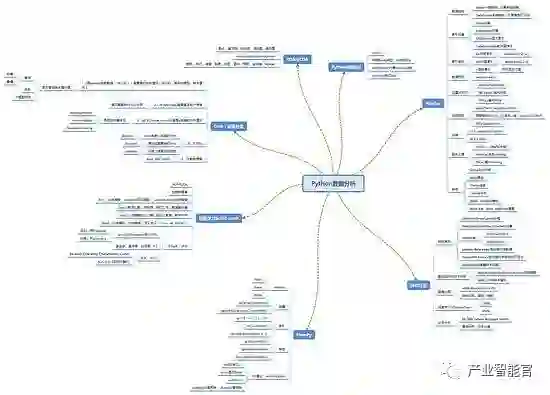
1)Numpy:ndarray
2)熊猫:Series和DataFrame
3)EDA的工具:Matplotlib,Seaborn,Bokeh
4)机器学习Scikit学习
5)量化分析与回测:塔里布/溜索/ PyAlgoTrade / Pybacktest
6)Scikit-Image:图像处理
7)NLTK:自然语言处理
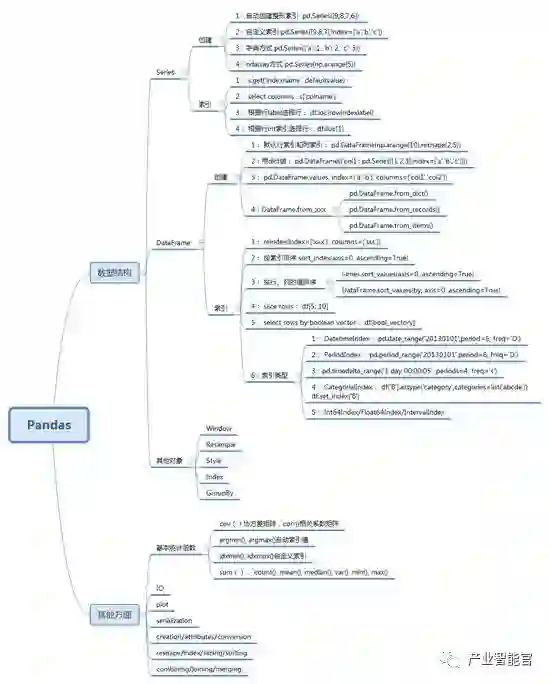
2.3熊猫
1)数据结构:Series / DataFrame / GroupBy / Index / Style / Resample / Window
2)索引:IntegerIndex / CategoricalIndex / IntervalIndex / DatetimeIndex / TimedeltaIndex
3)功能:创建/转换/属性/索引/选择/切片/分组/排序
4)重塑/组合/合并/加入/序列化/绘制/丢失数据/数据操作
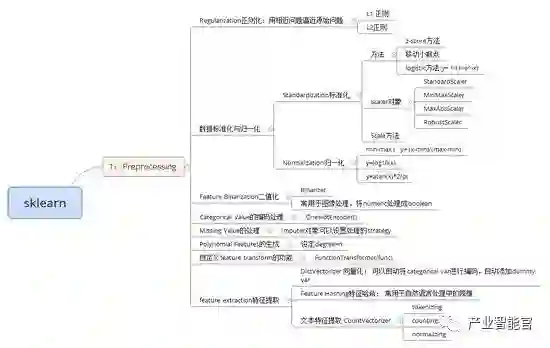
2.4 Sklearn
)预处理:包括样本切割,特征提取,
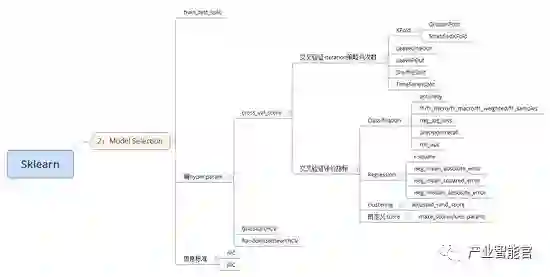
2)Model_selection:包括特征选择,交叉验证等
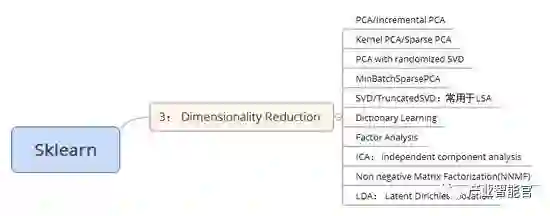
3)尺寸缩小:包括PCA,FA等
4)分类/回归,聚类
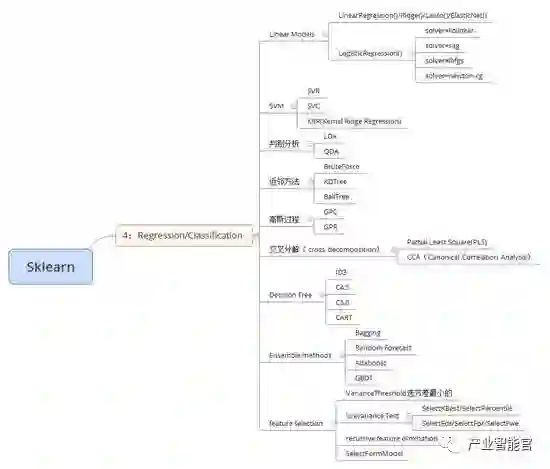
2.5 imblearn
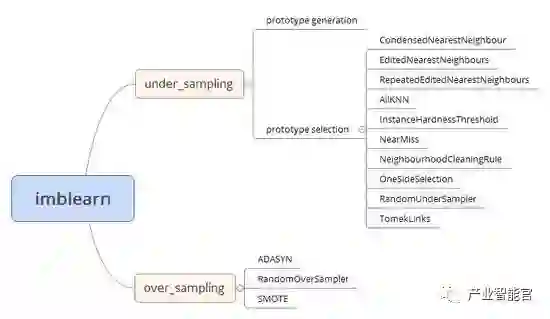
2.6 statsmodels
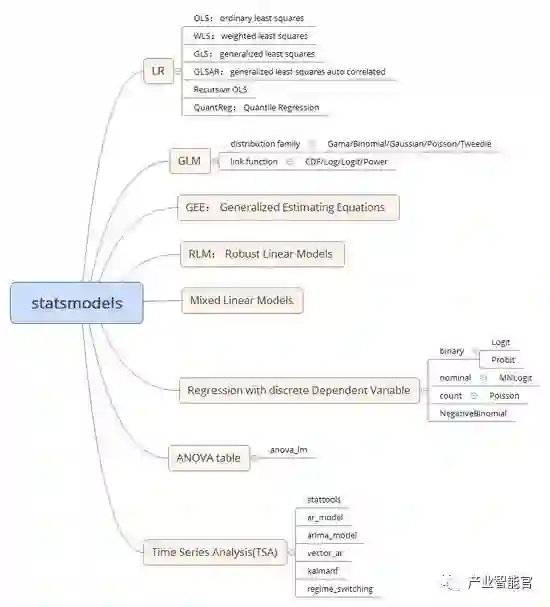
2.7 tushare
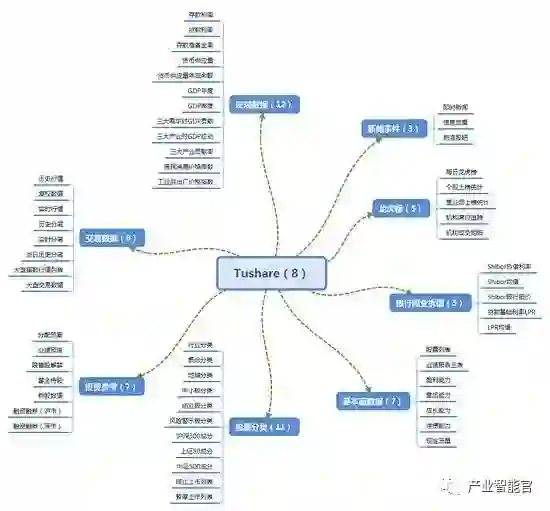
三,金融数据分析基础
3.1业务背景
1)客户类型,业务类型,建模类型
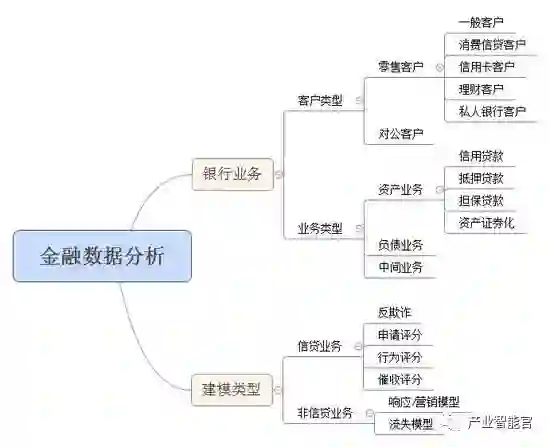
3.2金融数据分析建模基础
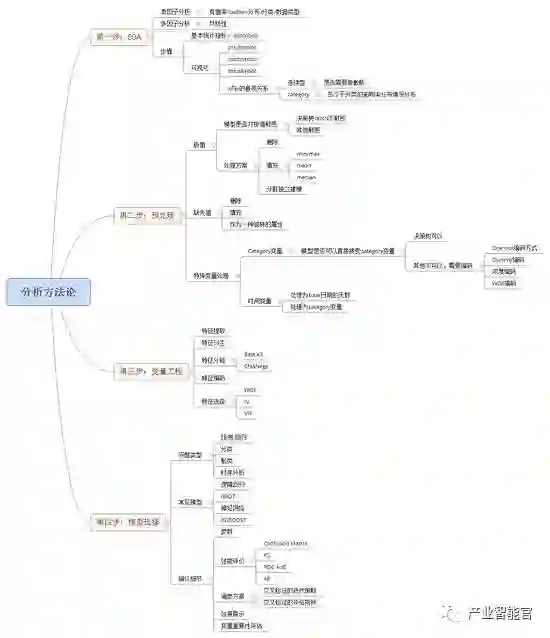
1)EDA的常用方法
2)极值,缺失值的处理方法
3)标准化与归一化的处理
4)范畴变量的编码方式
5)变量分箱的常用方式
6)IV值的计算与经验判断
7)WOE的计算,WOE编码
8)交叉验证的策略与评价
9)各类模型的优缺点,各类模型对输入的质量敏感性程度
10)各类模型的调参经验总结
四,数据分析实例
4.1案例:KNN做玻璃分类 - KNN,sklearn,seaborn
第一步:用pandas读取csv文件,用df.info()方法查看
第二步:查看直观特征:
df.shape查看有几行几列
df.columns获取每一列的表头名称,可以将ÿ过滤掉,只留下X
df.head(n)的可以预览读取的数据Ñ行
df.dtypes可以查看DF的数据类型
第三步:查看简单的统计特征:
df.describe()可以查看count,mean,sd,min,max,25%,50%,75%
比如:通过意味着可以查看各个X的取值范围是否大概一致,如果相差太大,要做归一化处理
DF [ 'Y']。value_counts()可以用来查看样本里面ý标签的取值与对应个数情况
比如:如果某个取值的数目特别多,表名样本非常不平衡,需要做样品重等相关处理,或者将样本分割一下
第四步:查看可视化的统计特征:
歪斜的计算与描述 - 每个单变量X与Y ^的分布情况--distplot
查看哪些变量需要做归一化处理--boxplot
查看两两变量之间的关系--pairplot
第五步:分割数据集:trainset和testset,可以直接用sklearn.model_selection里面的train_test_split
第六步:使用KNN分类器做分类算法,看各个k取值下的准确率,从而决定best_k
第七步:使用KNN模型拟合列车,查看测试集的准确率
提升模型准确率:
1)非平衡样本的数据处理
2)特征的归一化处理
3)其他分类器的尝试
4)尝试获取更多的数据
4.2 CASE:逻辑回归做借贷数据分析
第一步:文件目录相关操作import os
os.path.exists(filepath)检查某个文件或目录是否存在
os.path.join(A,B)拼接目录地址
第二步:文件压缩与解压相关操作:import zipfile
用zipfile.ZipFile(originalFilepath)为zf:
zf .extractAll(targetPath)
第三步:pandas DataFrame里面取到某个列目标的数据,做类型转换:
data ['newcolname'] = pd.to_datetime(data ['oldcolname'])
DATA2 = data.groupby([ 'newcolname'])[ '目标']。总和()
DF = pd.DataFrame(DATA2).reset_index()
将日期换成月份:(将DateTimeIndex变更为PeriodIndex)
data ['newcolname_2'] = data ['newcolname']。apply(lamda x:x.to_period('M'))
第四步:观察数据
直观情况:raw_data.head(),raw_data.info(),raw_data.describe()
类型分布:used_data [ 'loan_status'] value_counts()。
按时间统计:新增一列作为日期时间索引,由这个索引列组成
used_data [ 'issue_d2'] = pd.to_datetime(used_data [ 'issue_d'])
data_group_by_date = used_data.groupby([ 'issue_d2'])。总和()
data_group_by_date.reset_index(就地=真)
data_group_by_date ['issue_month'] = data_group_by_date ['issue_d2']。apply(lambda x:x.to_period('M'))loan_amount_group_by_month = data_group_by_date.groupby('issue_month')['loan_amnt'] sum()loan_amount_group_by_month_df = pd .DataFrame(loan_amount_group_by_month).reset_index()
查看多变量间的分类统计情况:
data_group_by_state = used_data.groupby([ 'addr_state'])[ 'loan_amnt']。总和()
data_group_by_state_df = pd.DataFrame(data_group_by_state).reset_index()
data_group_by_term = used_data.groupby([ '级', '术语'])[ 'int_rate']。意味着()
data_group_by_term_df = pd.DataFrame(data_group_by_term).reset_index()
第五步:处理类变量,改成0,1这样的标签
filtered_mask = raw_data ['loan_status']。isin(['Fully Paid','Charge off','Default'])
filtered_data = raw_data [filtered_mask]
proc_filter_data = filtered_data.copy()
proc_filter_data [ '标签'] = filtered_data [ 'loan_status']。应用(formateY)
proc_filter_data [ 'emp_length_feat'] = filtered_data [ 'emp_length']。应用(formateEmpLength)
第六步:原始特征选择
第七步:缺失值处理
第八步:开始学习
A:LabelEncoder(),OneHotEncoder()检查类别var
B:处理不平衡数据:SMOTE
C:分割火车组,试验台
D:选择模型,例如Logistic回归
E:交叉验证调整最优化的超参数:cross_val_score
1)迭代策略的选择:KFold / LeaveOneOut / LeavePOut / ShuffleSplit
2)交叉验证评估的度量:score类型(例如,precision / f1 / precision / recall / roc_auc / r2)
4.3案例:股票量化示例
资料地址:http : //www.chinahadoop.cn/classroom/48/introduction
1)股票收益率(log(pt / p(t-1)))的计算
1)使用tushare提供的接口,获取上证指数的价格数据
2)使用tushare提供的接口,获取某只股票的价格数据
3)股票价格服从日志正常分布,所以对价格数据,需要日志价格的序列
log_return = np.log(price / price.shift(1))
4)两个序列处理缺失值:方案,dropna
5)add_constant(x)的加入截距数据
sm .add_constant(x)
6)调用OLS适合两个对数价格序列
sm .OLS(y,x_cons).fit()
7)查看模型的情况:
res_ols 。总结()
2)预测某只指数的涨跌
1)使用tushare读取某只指数(股票)的日ķ线数据
2)生成对应的时滞序列:price.shift(x)
hist_lag ['lag {}'。format(str(i + 1))] = hist_data ['close']。shift(i + 1)
3)标签每天的涨跌:
ret_df ['today'] = hist_lag ['today']。pct_change()* 100.0
ret_df ['lag {}'format(str(i + 1))] = hist_lag ['lag {}'format(str(i + 1))] pct_change()* 100.0
ret_df ['direction'] = np.sign(ret_df ['today'])
4)分割列车组/试验台
X = lag_ret_df [['lag1','lag2']]
y = lag_ret_df ['direction']
start_test = dt.datetime(2016,1,1)
X_train = X [X.index <start_test]
X_test = X [X.index> = start_test]
y_train = y [y.index <start_test]
y_test = y [y.index> = start_test]
5)选择不同的模型,交叉验证获取优化的超参数,在train set上拟合,在测试集上预测,评估模型的优
4.4案例:银行客户流失预警模型
1)使用熊猫读取2个数据源文件
2)合并ID:pd.merge(A,B,on ='ID')
3)区分数据类型:

4)EDA
A:distplot,看X的偏度,分布
B:boxplot,看所有X的分布(比对哪些需要做归一化,标准化)
C:pairplot,看X两两之间的关联情况
D:category var各个取值与X的分布情况--subplots合并多张图,轴
E:查看X是否需要做截断,截断前和截断后与Y的关系
5)变量预处理:
A:时间变量的处理,作为标签或者作为基于某一天之间的天数
统一处理两个时间的格式,转变为日期时间变量,两者相减之后取天属性

B:类别变量的编码,
最常用的做法,用y变量在这个类别变量的某一类中的比率来代替这一类的取值。
如:gender ='女' - 用等于'女'的坏样本比率ratio1来替代
性别= '男' - 用等于 '男' 的坏样本比率比* 2来替代
第二种做法,添加哑变量,适合于类别取值较少的情况
如:city ='guangzhou'
城市=“南京”
用isGuangzhou,isNanjing这两个变量来替换掉这个变量
第三种做法,用类变量的某一类在样本中的出现次数来代替。
如:status ='default'出现100次,''default''用100表示
状态= '正常' 的出现1000次, '正常的' 用1000表示
C:缺价值的处理
判断是不是有存在缺失值 - 从原始数据中取出非缺失数据,比对形状

6)变量衍生
A:X之间相除得到某个比例
B:X的均值,最大值,最小值
C:X的求和
7)模型选择与训练:
A:train_test_split
B:选择模型:
GBDT
神经网络
C:参数调整:
默认参数,参数调整
D:在选定的模型中查看变量的重要性
4.5 CASE:互联网金融/银行申请评分卡模型
1)使用熊猫读取3个输入文件
2)查看3个输入文件里面的ID,是否存在有的有值,有没有值,取3个里面都有的数据出来做列车
data1_Idx,data2_Idx,data3_Idx = set(data1 ['Idx']),set(data2 ['Idx']),set(data3 ['Idx'])
check_Idx_integrity =(data1_Idx - data2_Idx)|(data2_Idx - data1_Idx)|(data1_Idx - data3_Idx)|(data3_Idx - data1_Idx)
集(XXX)能够去掉XXX里面的重复数据
3)特征衍生:
A:一些原始变量,衍生不同时间窗口下面的count,mean等变量
B:category变量:
如果缺失率超过50%,则去掉这个变量
如果不超过,作为一种特殊取值留着
C:连续变量:
如果缺失率超过70%,则去掉这个变量
如果不超过,则考虑用填充的方式进行填充(random,mean,min)
4)特征分箱:
A:category变量:
如果分类的取值个数> 5个,则用每种分类里面的坏率代替每个分类
如果这个bin的大小坏样本占比为0,那么将这个bin与最小的那个bin合并,再重新检查最大bin
B:连续变量:
使用卡方分箱方法,默认5个bin
查看每个bin里面的坏率,如果差率不单调,则降低bin的个数重新分
查看最大大小的bin占比,如果超过90%,则删掉这个变量
5)变量选择:
A:计算每个剩下来的变量的IV值,WOE值
B:取IV> = 0.02的所有变量
C:生成变量对,计算变量对之间的相关系数,如果相关系数大于某个阈值(取0.8),则变量对里面选IV值高的那个变量入模
D:查看每个变量的VIF值,VIF = 1 /(1-R2),VIF> 10的去掉
E:循环检查入模变量是否显着,如果不显着(取Pvalue> 0.1为不显着),就去掉之后再跑一遍
F:直到所有变量都是显着的为止
6)跑基础的逻辑回归模型,将模型序列化存下来
LR = sm.Logit(y,X).fit()
saveModel = open('./ data / LR_Model_Normal.pkl','w')
和pickle.dump(LR,saveModel)
saveModel.close()
7)跑Lasso正则化(L1)的逻辑回归模型,type1 error和type 2 error采用不同的惩罚系数
A:用交叉验证的方式调超参数:
LR_model_2 = LogisticRegressionCV(Cs = [C_penalty],penalty ='l1',solver ='liblinear',class_weight = {1:bad_weight,0:1})
LR_model_2_fit = LR_model_2.fit(X_train,y_train)
B:序列化应用Lasso的逻辑回归模型
8)可以通过随机森林的方式确定变量的重要性,根据随机森林的结果(如:取重要前10的变量入模等)来跑逻辑回归模型

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com