信息安全公益宣传,信息安全知识启蒙。
加微信群回复公众号:微信群;QQ群:16004488
加微信群或QQ群可免费索取:学习教程
教程列表见微信公众号底部菜单
![]()
作者:王雨城
寻找并分析百度云的转存api
首先你得有一个百度云盘的账号,然后登录,用浏览器(这里用火狐浏览器做示范)打开一个分享链接。F12打开控制台进行抓包。手动进行转存操作:全选文件->保存到网盘->选择路径->确定。点击【确定】前建议先清空一下抓包记录,这样可以精确定位到转存的api,这就是我们中学时学到的【控制变量法】2333。
可以看到上图中抓到了一个带有 “transfer” 单词的 post 请求,这就是我们要找的转存(transfer)api 。接下来很关键,就是分析它的请求头和请求参数,以便用代码模拟。
![]()
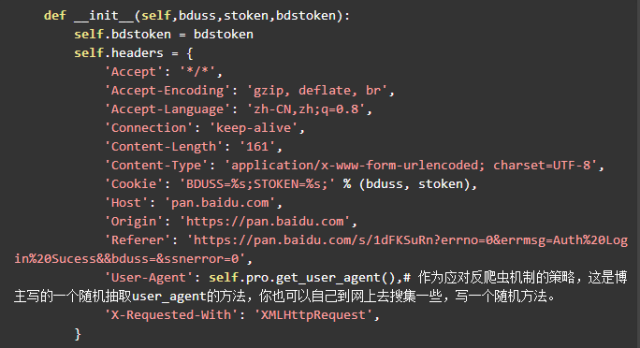
点击它,再点击右边的【Cookies】就可以看到请求头里的 cookie 情况。
cookie分析
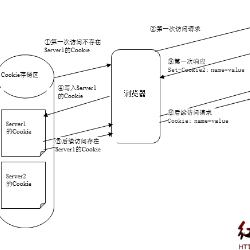
因为转存是登录后的操作,所以需要模拟登录状态,将与登录有关的 cookie 设置在请求头里。我们继续使用【控制变量法】,先将浏览器里关于百度的 cookie 全部删除(在右上角的设置里面,点击【隐私】,移除cookies。具体做法自己百度吧。)
然后登录,右上角进入浏览器设置->隐私->移除cookie,搜索 "bai" 观察 cookie 。这是所有跟百度相关的 cookie ,一个个删除,删一个刷新一次百度的页面,直到删除了 BDUSS ,刷新后登录退出了,所以得出结论,它就是与登录状态有关的 cookie 。
同理,删除掉 STOKEN 后,进行转存操作会提示重新登录。所以,这两个就是转存操作所必须带上的 cookie 。
弄清楚了 cookie 的情况,可以像下面这样构造请求头。
![]()
除了上面说到的两个 cookie ,其他的请求头参数可以参照手动转存时抓包的请求头。这两个 cookie 预留出来做参数的原因是 cookie 都是有生存周期的,过期了需要更新,不同的账号登录也有不同的 cookie 。
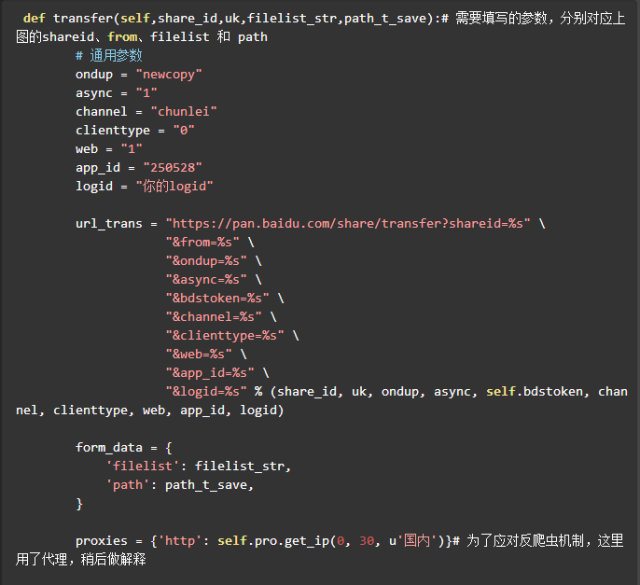
参数分析
接下来分析参数,点击【Cookies】右边的【Params】查看参数情况。如下:
上面的query string(也就是?后跟的参数)里,除了框起来的shareid、from、bdstoken需要我们填写以外,其他的都可以不变,模拟请求的时候直接抄下来。
前两个与分享的资源有关,bdstoken与登录的账号有关。下面的form data里的两个参数分别是资源在分享用户的网盘的所在目录和刚刚我们点击保存指定的目录。
所以,需要我们另外填写的参数为:shareid、from、bdstoken、filelist 和 path,bdstoken 可以手动转存抓包找到,path 根据你的需要自己定义,前提是你的网盘里有这个路径。其他三个需要从分享链接里爬取,这个将在后面的【爬取shareid、from、filelist,发送请求转存到网盘】部分中进行讲解。
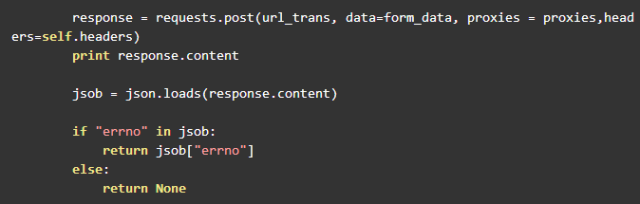
搞清楚了参数的问题,可以像下面这样构造转存请求的 url 。
![]()
![]()
爬取shareid、from、filelist,发送请求转存到网盘
![]()
以上面这个资源链接为例(随时可能被河蟹,但是没关系,其他链接的结构也是一样的),我们先用浏览器手动访问,F12 打开控制台先分析一下源码,看看我们要的资源信息在什么地方。控制台有搜索功能,直接搜 “shareid”。
定位到4个shareid,前三个与该资源无关,是其他分享资源,最后一个定位到该 html 文件的最后一个标签块里。双击后可以看到格式化后的 js 代码,可以发现我们要的信息全都在里边。如下节选:
![]()
![]()
可以看到这两行
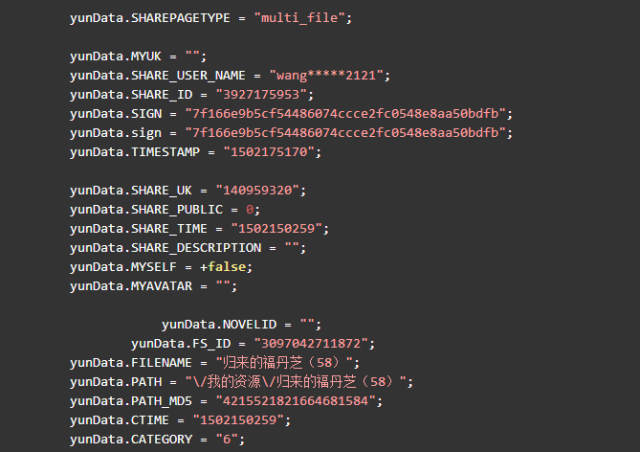
![]()
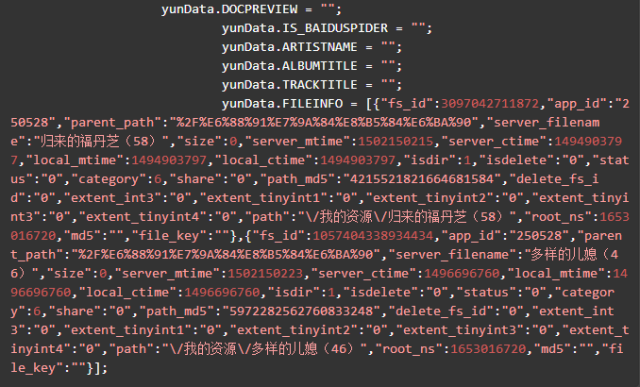
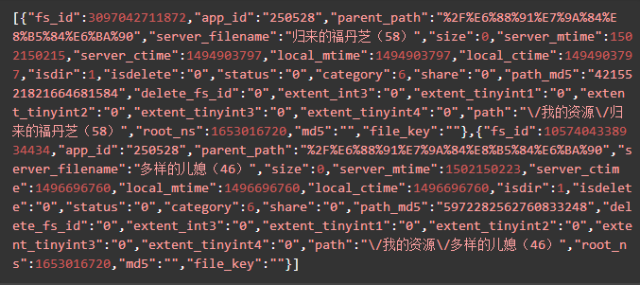
yunData.PATH 只指向了一个路径信息,完整的 filelist 可以从 yunData.FILEINFO 里提取,它是一个 json ,list 里的信息是Unicode编码的,所以在控制台看不到中文,用Python代码访问并获取输出一下就可以了。
直接用request请求会收获 404 错误,可能是需要构造请求头参数,不能直接请求,这里博主为了节省时间,直接用selenium的webdriver来get了两次,就收到了返回信息。第一次get没有任何 cookie ,但是baidu 会给你返回一个BAIDUID ,在第二次 get 就可以正常访问了。
yunData.FILEINFO 结构如下,你可以将它复制粘贴到json.cn里,可以看得更清晰。
![]()
清楚了这三个参数的位置,我们就可以用正则表达式进行提取了。代码如下:
![]()
![]()
爬取到了这三个参数,就可以调用之前的 transfer 方法进行转存了。
我们想获取贴吧上帖子的标题。
解决方法为:在相应的网页的html代码中找到title出现的地方。然后提取正则表达式。
![]()
根据上面的截图:提取的正则表达式如下:
pattern=re.compile(r'<h3 class="core_title_txt pull-left text-overflow .*?>(.*?)</h3>',re.S)
因此,得到帖子的标题的代码可以这么写。
#得到帖子的标题def getPageTitle(self,pageNum):content=self.getPageContent(pageNum)#得到网页的html代码pattern=re.compile(r'<h3 class="core_title_txt pull-left text-overflow .*?>(.*?)</h3>',re.S)
title=re.search(pattern,content)
if title:
#print title.group(1).strip() 测试输出
return title.group(1).strip()
else:
print None
同样的道理,我们可以得到获取帖子作者的代码如下:
#得到帖子的作者
def getPageAuthor(self,pageNum):
content=self.getPageContent(pageNum) # <div class="louzhubiaoshi j_louzhubiaoshi" author="懂球君">
pattern=re.compile(r'<div class="louzhubiaoshi j_louzhubiaoshi" author="(.*?)">',re.S)
author=re.search(pattern,content) if author: print author.group(1).strip()#测试输出
return author.group(1).strip() else : print None
同样的道理,可以得到任何我们想要的内容。比例:帖子的回复总数等。
下面是完整代码:
#encoding=utf-8#功能:抓取百度贴吧中帖子的内容import urllib2import urllibimport re#定义一个工具类来处理内容中的标签class Tool:
#去除img标签,7位长空格
removeImg=re.compile('<img.*?>| {7}|') #去除超链接标签
removeAddr=re.compile('<a.*?>|</a>') #把换行的标签换为\n
replaceLine=re.compile('<tr>|<div>|</div>|</p>') #将表格制表<td>替换为\t
replaceTD=re.compile('<td>') #把段落开头换为\n加空两格
replacePara=re.compile('<p.*?>') #将换行符或双换行符替换为\n
replaceBR=re.compile('<br><br>|<br>') #将其余标签删除
removeExtraTag=re.compile('<.*?>') def replace(self,x):
x=re.sub(self.removeImg,"",x)
x=re.sub(self.removeAddr,"",x)
x=re.sub(self.replaceLine,"\n",x)
x=re.sub(self.replaceTD,"\t",x)
x=re.sub(self.replacePara,"\n ",x)
x=re.sub(self.replaceBR,"\n",x)
x=re.sub(self.removeExtraTag,"",x) return x.strip()#定义一个类class BaiduTieBa:
#初始化,传入地址,以及是否只看楼主的参数,floorTag:为1就是往文件中写入楼层分隔符
def __init__(self,url,seeLZ,floorTag):
self.url=url
self.seeLZ="?see_lz="+str(seeLZ)
self.tool=Tool() #全局的文件变量
self.file=None
#默认标题,如果没有获取到网页上帖子的标题,此将作为文件的名字
self.defultTitle="百度贴吧"
#是否往文件中写入楼与楼的分隔符
self.floorTag=floorTag #楼层序号
self.floor=1
#根据传入的页码来获取帖子的内容太
def getPageContent(self,pageNum):
url=self.url+self.seeLZ+"&pn="+str(pageNum)
user_agent="Mozilla/5.0 (Windows NT 6.1)"
headers={"User-Agent":user_agent} try:
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
content=response.read().decode("utf-8") #print content #测试输出
return content except urllib2.URLError,e: if hasattr(e,"reason"): print e.reason #得到帖子的标题
def getPageTitle(self,pageNum):
content=self.getPageContent(pageNum)
pattern=re.compile(r'<h3 class="core_title_txt pull-left text-overflow .*?>(.*?)</h3>',re.S)
title=re.search(pattern,content) if title: print title.group(1).strip() return title.group(1).strip() else: print None
#得到帖子的作者
def getPageAuthor(self,pageNum):
content=self.getPageContent(pageNum) # <div class="louzhubiaoshi j_louzhubiaoshi" author="懂球君">
pattern=re.compile(r'<div class="louzhubiaoshi j_louzhubiaoshi" author="(.*?)">',re.S)
author=re.search(pattern,content) if author: print author.group(1).strip()#测试输出
return author.group(1).strip() else : print None
#得到帖子的总页数和总回复数
def getPageTotalPageNum(self,pageNum):
content=self.getPageContent(pageNum) #<li class="l_reply_num" style="margin-left:8px" ><span class="red" style="margin-right:3px">1</span>回复贴,共<span class="red">1</span>页</li>
pattern=re.compile(r'<li class="l_reply_num".*? style="margin-right:3px">(.*?)</span>.*?<span class="red">(.*?)</span>',re.S)
totalPageNum=re.search(pattern,content) if totalPageNum: print totalPageNum.group(1).strip(),totalPageNum.group(2).strip()#测试输出
#print totalPageNum[0],totalPageNum[1]
return totalPageNum.group(1).strip(),totalPageNum.group(2).strip()#第一个返回值为回复个数,第二个返回值为帖子的页数
else: print "没找到"
print None
#提取帖子的内容
def getContent(self,pageNum):
content=self.getPageContent(pageNum) #html代码中的格式如下:
#<div id="post_content_80098618952" class="d_post_content j_d_post_content ">
#一个省女性几千万人 比刘亦菲漂亮的可以找出几个</div>
#提取正则表达式如下:
pattern=re.compile(r'<div id="post_content_.*?>(.*?)</div>',re.S)
items=re.findall(pattern,content)
floor=1
contents=[] for item in items: #将每个楼层的内容进行去除标签处理,同时在前后加上换行符
tempContent="\n"+self.tool.replace(item)+"\n"
contents.append(tempContent.encode("utf-8")) #测试输出
#print floor,u"楼-------------------------------------------\n"
#print self.tool.replace(item)
#floor+=1
return contents #将内容写入文件中保存
def writedata2File(self,contents):
for item in contents: if self.floorTag=="1": #楼与楼之间的分隔符
floorLine=u"\n"+str(self.floor)+u"-------------------\n"
self.file.write(floorLine) print u"正在往文件中写入第"+str(self.floor)+u"楼的内容"
self.file.write(item)
self.floor+=1
#根据获取网页帖子的标题来在目录下建立一个同名的.txt文件
def newFileAccTitle(self,title):
if title is not None:
self.file=open(title+".txt","w+") else:
self.file=open(defultTitle+".txt","w+") #写一个抓取贴吧的启动程序
def start(self,pageNum):
#先获取html代码
content=self.getPageContent(pageNum) #第二步:开始解析,获取帖子的标题和作者
title=self.getPageTitle(pageNum) #根据title建立一个即将用于写入的文件
self.newFileAccTitle(title)
author=self.getPageAuthor(pageNum) #第三步:获取帖子各个楼层的内容
contents=self.getContent(pageNum) #第四步:开始写入文件中
try:
self.writedata2File(contents) except IOError,e: print "写入文件发生异常,原因"+e.message finally: print "写入文件完成!"#测试代码如下:#url=raw_input("raw_input:")url="http://www.tieba.baidu.com/p/4197307435"seeLZ=input("input see_lz:")
pageNum=input("input pageNum:")
floorTag=raw_input("input floorTag:")
baidutieba=BaiduTieBa(url,seeLZ,floorTag)#实例化一个对象baidutieba.start(pageNum)#content=baidutieba.getPageContent(pageNum)#调用函数#开始解析得到帖子标题#baidutieba.getPageTitle(1)#开始解析得到帖子的作者#baidutieba.getPageAuthor(1)#baidutieba.getPageTotalPageNum(1)#解析帖子中的内容#baidutieba.getContent(pageNum)
自己动手敲敲代码,运行一下试试吧!
作者:Jack-Cui
一、实战背景
爱奇艺的VIP视频只有会员能看,普通用户只能看前6分钟。比如加勒比海盗5的URL:http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1
![]()
我们怎么免费看VIP视频呢?一个简单的方法,就是通过旋风视频VIP解析网站。URL:http://api.xfsub.com/
这个网站为我们提供了免费的视频解析,它的通用解析方式是:
http://api.xfsub.com/index.php?url=[播放地址或视频id]
比如,对于绣春刀这个电影,我们只需要在浏览器地址栏输入:
http://api.xfsub.com/index.php?url=http://www.iqiyi.com/v_19rr7qhfg0.html#vfrm=19-9-0-1
这样,我们就可以在线观看这些VIP视频了:
![]()
但是这个网站只提供了在线解析视频的功能,没有提供下载接口,如果想把视频下载下来,我们就可以利用网络爬虫进行抓包,将视频下载下来。
二、实战升级
分析方法相同,我们使用Fiddler进行抓包:
![]()
我们可以看到,有用的请求并不多,我们逐条分析。我们先看第一个请求返回的信息。
![]()
可以看到第一个请求是GET请求,没有什么有用的信息,继续看下一条。
![]()
我们看到,第二条GET请求地址变了,并且在返回的信息中,我们看到,这个网页执行了一个POST请求。POST请求是啥呢?它跟GET请求正好相反,GET是从服务器获得数据,而POST请求是向服务器发送数据,服务器再根据POST请求的参数,返回相应的内容。这个POST请求有四个参数,分别为time、key、url、type。记住这个有用的信息,我们在抓包结果中,找一下这个请求,看看这个POST请求做了什么。
![]()
很显然,这个就是我们要找的POST请求,我们可以看到POST请求的参数以及返回的json格式的数据。其中url存放的参数如下:
xfsub_api\/url.php?key=02896e4af69fb18f7029b6046d7c718&time=1505724557&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rr7qhfg0.html&type=&xml=1
这个信息有转义了,但是没有关系,我们手动提取一下,变成如下形式:
xfsub_api/url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1
我们已经知道了这个解析视频的服务器的域名,再把域名加上:
http://api.xfsub.com/xfsub_api\url.php?key=02896e4af69fb18f70129b6046d7c718&time=1505724557&url=http://www.iqiyi.com/v_19rr7qhfg0.html&type=&xml=1
这里面存放的是什么东西?不会视频解析后的地址吧?我们有浏览器打开这个地址看一下:
![]()
果然,我们可以看到视频地址近在眼前啊,URL如下:
http://disp.titan.mgtv.com/vod.do?fmt=4&pno=1121&fid=1FEA2622E0BD9A1CA625FBE9B5A238A6&file=/c1/2017/09/06_0/1FEA2622E0BD9A1CA625FBE9B5A238A6_20170906_1_1_705.mp4
我们再打开这个视频地址:
![]()
瞧,我们就这样得到了这个视频在服务器上的缓存地址。根据这个地址,我们就可以轻松下载视频了。
PS:需要注意一点,这些URL地址,都是有一定时效性的,很快就会失效,因为里面包含时间信息。所以,各位在分析的时候,要根据自己的URL结果打开网站才能看到视频。
接下来,我们的任务就是编程实现我们所分析的步骤,根据不同的视频播放地址获得视频存放的地址。
现在梳理一下编程思路:
三、编写代码
编写代码的时候注意一个问题,就是我们需要使用requests.session()保持我们的会话请求。简单理解就是,在初次访问服务器的时候,服务器会给你分配一个身份证明。我们需要拿着这个身份证去继续访问,如果没有这个身份证明,服务器就不会再让你访问。这也就是这个服务器的反爬虫手段,会验证用户的身份。
![]()
![]()