看都不看,我就知道你没戴口罩

作者 | 青暮、蒋宝尚
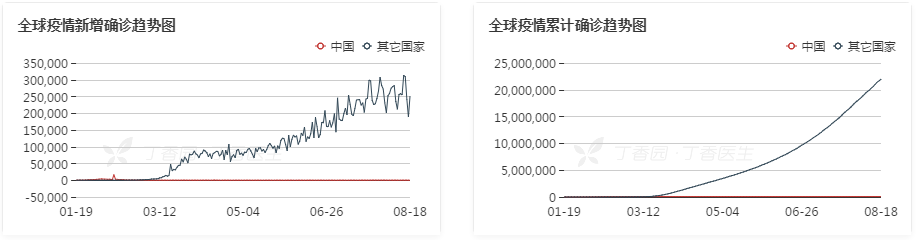 (新冠肺炎全球新增确诊和累计确诊统计图。图源:丁香医生)
(新冠肺炎全球新增确诊和累计确诊统计图。图源:丁香医生)







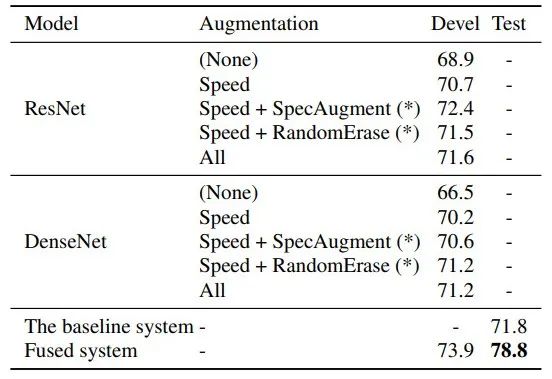 表2:开发集和测试集上的UAR。
表2:开发集和测试集上的UAR。
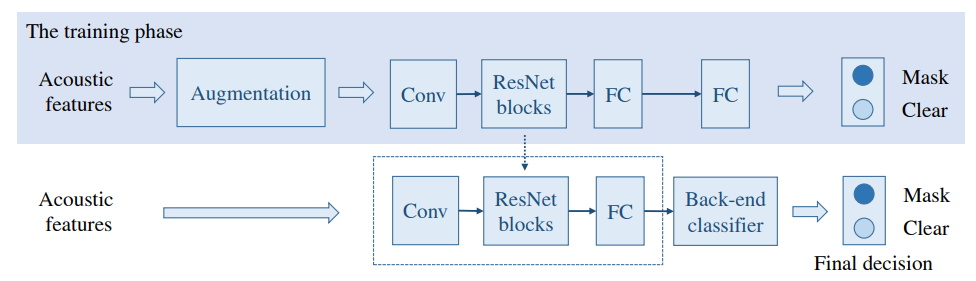 图2:ResNet嵌入系统的框架。
图2:ResNet嵌入系统的框架。

登录查看更多
相关内容
Arxiv
4+阅读 · 2019年4月9日
相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月9日