英伟达再出GAN神作!多层次特征的风格迁移人脸生成器
选自arXiv
作者:Tero Karras、Samuli Laine、Timo Aila
机器之心编译
GAN 自 2014 年提出以来得到了广泛应用。前不久效果令人震惊的 ICLR 2019 论文 BigGAN 引发了众多关注。去年英伟达投稿 ICLR 2018 的论文《Progressive Growing of GANs for Improved Quality, Stability, and Variation》效果也很惊艳。昨天 PGGAN 的作者再发论文,这次的效果更加真实。请戳视频:

是的,这些图片都是由 GAN 生成的。
这款新型 GAN 生成器架构借鉴了风格迁移研究,可对高级属性(如姿势、身份)进行自动学习和无监督分割,且生成图像还具备随机变化(如雀斑、头发)。该架构可以对图像合成进行直观、规模化的控制,在传统的分布质量指标上达到了当前最优,展示了更好的插值属性,并且能够更好地将潜在的变差因素解纠缠。
下图展示了这款新型生成器的风格效果。它将隐编码生成的风格(source)叠加在另一种隐编码的风格子集(destination)上。
对空间分辨率较低(4^2 – 8^2)的层的风格进行叠加的效果见「Coarse styles copied」部分:生成图像从 source 中复制了姿势、大致发型、脸形和眼镜等高级属性,但保留了 destination 图像的所有颜色(眼睛、头发、光线)和细节脸部特征。
对空间分辨率为 16^2 – 32^2 的层的风格进行叠加的效果见「Middle styles copied」部分:复制了 source 图像的细微面部特征、发型、眼睛睁开的状态,同时保留了 destination 图像的姿势、脸形和眼镜。
对高分辨率 (64^2 – 1024^2) 的层的风格进行叠加的效果见「Fine styles」:主要保留了 source 图像的颜色和微小特征。

论文:A Style-Based Generator Architecture for Generative Adversarial Networks

论文链接:https://arxiv.org/pdf/1812.04948.pdf
基于风格的生成器
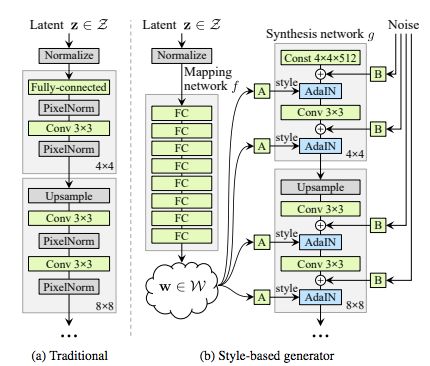
如下图所示,(a)PGGAN 生成器将隐编码仅馈入输入层,而(b)英伟达最近提出的基于风格的生成器首先将输入映射到中间潜在空间 W,W 控制生成器在每个卷积层的自适应实例归一化(adaptive instance normalization,AdaIN)。然后在应用非线性激活之前在每个卷积层之后添加高斯噪声。图中 A 表示学到的仿射变换,B 表示学到的每个通道对噪声输入的比例因子。映射网络 f 包含 8 个层,合成网络 g 包含 18 个层(4^2、8^2、16^2、32^2、64^2、128^2、256^2、512^2、1024^2 这九种分辨率中每种分辨率有两个层)。使用互相分离的 1 × 1 卷积将最后一层的输出转换成 RGB,与前作 PGGAN 类似。
基于风格的生成器的属性
该生成器架构通过对风格的尺度调整来控制图像合成。映射网络和仿射变换用来从学到的分布中获取每种风格的采样,合成网络用来基于多种风格生成新图像。每种风格的效果都在该网络内有呈现,即修改多种风格的特定子集以影响图像的某些特定属性。
该研究介绍了该生成器的三个属性,分别是风格混合、随机变化(Stochastic variation)和全局效应与随机性的分离。
风格混合
上图展示了在多种分辨率情况下混合两种隐编码合成的图像示例。可以看到风格的每个子集控制图像的有意义高级属性。
随机变化

图 4. 随机变化的示例。(a)两张生成的图像。(b)放大输入噪声的不同实现。尽管整体外观大致相同,但个体毛发细节还是有不同。(c)100 个不同实现中像素的标准偏差,高亮处为图像受噪声影响的区域。主要区域是头发、轮廓和部分背景,但眼睛的反射也有有趣的随机变化。身份和姿势等全局特征不受随机变化的影响。

图 5:生成器不同层的输入噪声对生成结果的影响。(a)噪声被应用到所有层;(b)没有噪声;(c)噪声仅应用到(64^2 - 1024^2)分辨率的精细层;(d)噪声仅应用到(4^2 - 32^2)分辨率的粗糙层。我们可以看到人工消除噪声可以让图像看起来更正常,粗糙噪声会导致大幅度的头发和背景扭曲;精细噪声带来的头发变形更加细致,背景细节更加丰富,甚至能看到皮肤毛孔。
全局效应与随机性的分离
前文及随附的视频说明,虽然改变风格会产生全局效应(global effect),如改变姿势、ID 等,但噪声只会影响无关紧要的随机变化(如发型、胡子等)。这个观察结果与风格迁移文献一致,后者已经确定了空间不变的统计数据(格拉姆矩阵、通道均值、方差等)能够可靠地编码图像的风格 [17, 33],同时空间变化的特征编码特定实例。
在本文基于风格的生成器中,风格会影响整个图像,因为整个特征图会以同样的值进行缩放和偏移。因此,姿势、光线或背景风格等全局效应可以得到连贯的控制。同时,噪声被单独添加到每个像素中,因此非常适于控制随机变化。如果该网络试图用噪声控制姿势,那将会导致空间不一致的决策,然后被判别器惩罚。因此该网络学会了在没有明确指导的情况下适当地使用全局和局部通道。
此外,英伟达还提出两种可应用于任意生成器架构的新型自动化方法,并创建了一个包含千差万别、高质量人脸图像的新型数据集 FlickrFaces-HQ(FFHQ)。该数据集中的图像来自于 Flickr 网站,并经过自动对齐和剪裁。该数据集包含 70000 张分辨率为 1024^2 的高质量图像,其中的图像在年龄、种族、图像背景等方面比 CelebA-HQ [26] 具备更宽泛的变化,且涵盖更多配饰,如眼镜、太阳镜、帽子等。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



