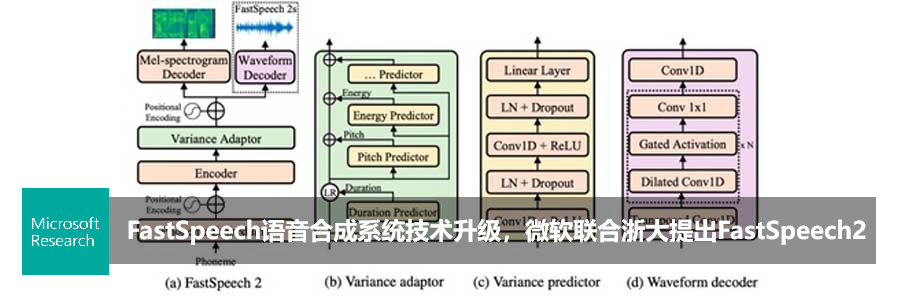
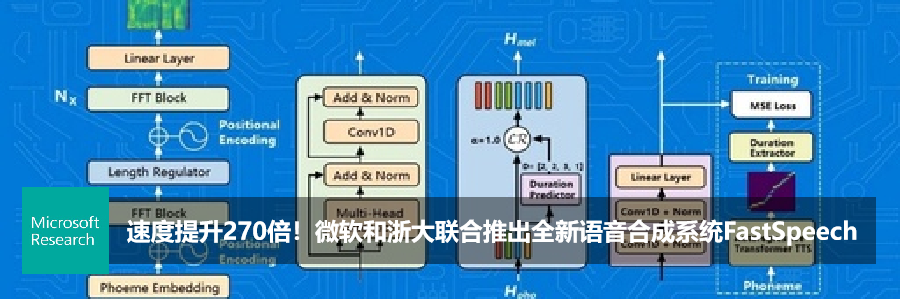
KDD 2020 | LRSpeech:极低资源下的语音合成与识别

编者按:上周,清华大学硕士研究生、微软亚洲研究院机器学习组实习生徐进(指导研究员:谭旭)在 B 站分享了 KDD 2020论文“LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition”。本次直播介绍了 LRSpeech 的相关技术,并分享了在构建极低资源语音合成与识别系统中的一些心得体会。
以下是直播分享的全部内容:
今天介绍一下我们在 KDD 2020 上发表的一篇关于语音方面的工作——极低资源场景下的语音合成与语音识别。如今,语音合成(TTS, Text to Speech)与语音识别(ASR, Automatic Speech Recognition)已经有很多商业应用,比如微软 Azure 云平台已经可以支持几十种语言,包括中文、英语以及德语等等。这个世界上有超过7000多种语言,商业应用有动力去拓展更多的语言来支持更多的用户。但是要想把语言从几十种扩展到7000多种,并不是一件简单的事情,为新的语言建立一个 TTS/ASR 系统,需要高昂的数据成本来训练模型。根据估算,建立一个可以商用的 TTS 系统,数据标注成本大约需要超过100万美金,这使得直接用已有的方案去拓展到7000多种语言上是不可行的。学术界对于如何在不同数据资源场景下建立 TTS 和 ASR 系统有许多探索。图一是过去解决这类问题的一些工作。
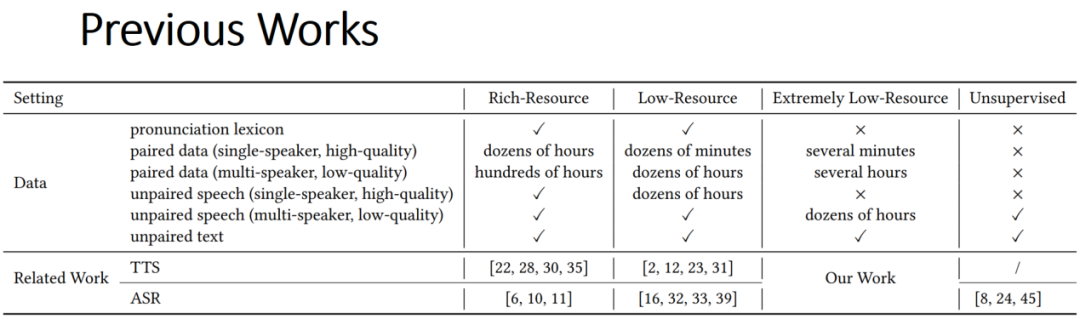
图一:TTS 和 ASR 系统之前的工作
图一中,Rich-Resource 一列是资源丰富场景下做的一些 TTS 和 ASR 的工作,使用大量的语料能够把 TTS 和 ASR 做到较好的效果。这样的系统首先需要 grapheme-to-phoneme 转换以及大量的高质量数据。其中,grapheme-to-phoneme 是指在给 TTS 系统合成声音时,不是把一个个字母丢进去,而是把字母(character)通过 grapheme-to-phoneme 转换成系统所要的音素(phoneme),然后再进行 TTS 合成。但对于构建一个新的语言,grapheme-to-phoneme 模型/词典的构建需要非常高昂的代价。
训练语料方面,模型需要大约几十个小时单一说话者(single-speaker)的高质量数据来保证语音的质量。然而这种高质量的数据通常会使用专业设备来进行录音,所以成本也相对较为昂贵。除此之外,模型还需要其他语料进一步提升系统对于语言本身的理解能力和泛化能力,比如成本更低的多个说话者(multi-speaker),相对低质量的成对数据(paired data),大概需要几百小时。一些模型还会用一些不成对的(unpaired)语音和文本进一步提高效果。
其他的场景包括低资源以及无监督任务,同样会使用 grapheme-to-phoneme 转换和训练语料,但是训练语料会减少。然而包括 Rich-Resource 场景在内,他们都存在一些问题。Rich-Resource 需要大量的成对数据,尤其是高质量的单一说话者,这个数据的收集成本非常高昂。目前的低资源(low-resource)场景仍然需要较高的代价,而且低资源和无监督场景的准确率也并不能满足要求。所以我们论文的定位,就是做极端低资源场景下的工作,尽可能使用较少的数据,建立出一个满足要求的 TTS和 ASR 系统。(点击阅读原文,查看论文细节)

图二:LRSpeech 的研究目标
可以在图二中看到我们的数据使用情况。LRSpeech 并不需要 grapheme-to-phoneme 转换,而是直接使用原始文本作为输入。数据方面,相比于之前的工作我们进一步压缩了使用的数据量。LRSpeech 使用了5分钟的高质量单一说话者的语音数据以及几个小时的低质量多个说话者成对数据,最后还使用了部分不成对的语音和文本。把数据成本降低之后,我们还要保证系统可以达到工业上的要求:IR(intelligibility rate,可懂率)要大于98%,MOS(mean opinion score,平均意见得分)要大于3.5,并且与真实声音 (GT, ground truth)的差距要小于0.5。
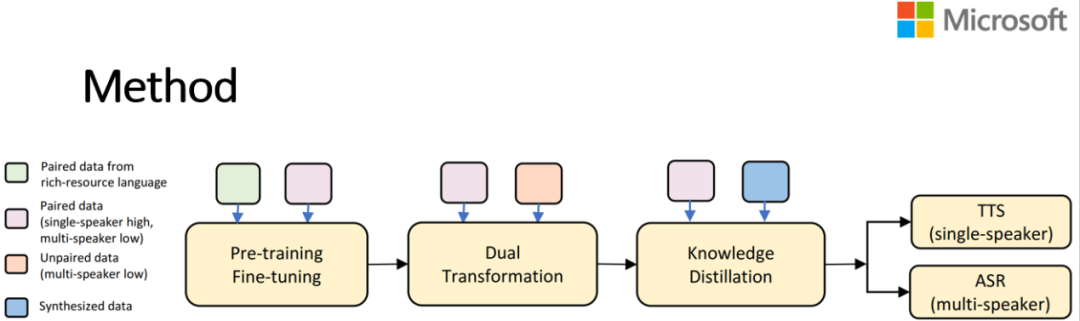
图三:LRSpeech 方法框图
预训练和微调之后已经把极低资源场景下的一些成对数据用上了,但显然这是不够的,因为我们的成对数据很少,所以还需要一些不成对的语音以及文本,来进一步提高系统的性能。因此,接下来采用了对偶学习(dual transformation),这主要借鉴了微软亚洲研究院机器学习组在 ICML 2019 上发表的一篇文章——使用 TTS 和 ASR 系统彼此互相帮助来提高模型的性能,所以图三框图的地方可以看到上面有两个小框,是用上这个不成对的数据的。
我们发现通过使用前两部分之后,ASR 和 TTS 系统的质量还是没有达到要求,所以还需要第三部分,即用知识蒸馏的方法来进一步提高性能,最后可以得到单一说话者的 TTS 和多个说话者的 ASR。
我们对于 TTS 的需求是,用户给一段文字,TTS 系统能用一个特定的声音读出来,这需要一个高质量的、特定的声音,所以 TTS 是单一说话者的。而对于自动语音识别系统,则要能识别出任何一个声音,所以 ASR 需要支持多个说话者。
让我们具体深入到每个模块细节。第一部分是预训练和微调,Rich-Resource 语言用的是中文,然后在低资源语言上进行微调。但在这个过程中有几个问题:一是,说话人不一样在模型设计里的说话人的嵌入矩阵(speak embedding)是不一样的;二是语言上的问题,它们的文本是不一样的,也就是语言字符的嵌入矩阵(text embedding)不一样。
如何解决这种不一致的问题呢?我们在训练的时候,把 Rich-Resource 的说话人的嵌入矩阵和语言字符的嵌入矩阵直接丢掉,对新的语言的语料重新训练。然后在训练的时候,把 TTS 以及 ASR 的主干模型固定住,先只微调说话人/语言字符的嵌入矩阵,在微调一定的轮数之后,再微调整个模型。
第二部分是对偶学习(Dual Transformation)。首先看图四的这个公式,公式第一行 θ_asr 是ASR 系统,y 是语音,大 y^u 代表不成对的语音数据,所以第一行的公式表示把不成对的语音,通过 ASR 系统转换成文本 X ̂,X ̂ 和不成对的语音就可以组合成成对数据,也就是公式的第二行。我们用这个成对数据再去训练 TTS 系统。这个流程就是使用 ASR 来帮助 TTS 系统。
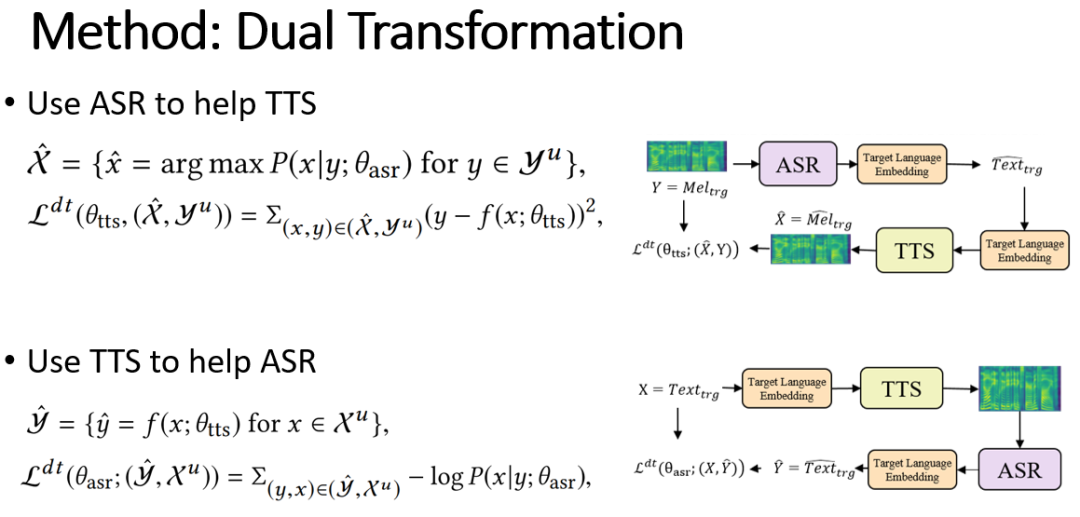
图四:对偶学习公式
同样地,第三行公式,θ_tts 是 TTS 系统,X^u 代表不成对的文本数据,这行表达式就是把不成对的文本数据通过 TTS 系统转换成语音,得到 y ̂ 和 X^u,这是一对成对数据。再用这对成对数据按照第四行公式训练 ASR 系统。这个流程就是用 TTS 帮助 ASR。两个系统在这个训练过程中逐步地相互提高。
但要注意的是,我们对于不成对文本的使用是直接的,但是对于不成对的语音并没有直接使用,这是因为语音有说话人的区分。如果有一个从来没有见过的说话者(unseenspeaker),我们没有这个说话者的嵌入矩阵(embedding),这个时候直接拿它来训练 TTS 肯定是行不通的,那该怎么处理呢?

图五:对偶学习处理没有见过的说话者的语音数据
我们首先用 ASR 系统将没有见过的说话者的语音转化成文本,然后再用这种合成的成对数据去训练 TTS,这样 TTS 就能适应没有见过的说话者了。然后再用 TTS 来帮助 ASR。这种方式的好处是对于不成对的语料是不受限制的,可以搜集更多不成对的语料来帮助提高系统。
第三部分是知识蒸馏。通过上一步的训练之后,我们已经有了一个效果不错的 TTS 和ASR 系统,但 TTS 系统仅仅通过上面两步的 TTS 和 ASR 系统还存在一些跳词和漏词的问题,质量还不能满足要求。
所以接下来,我们做了数据方面的知识蒸馏。可以看一下图六中的这两行公式。用 θ_tts(TTS 系统)把 X^u(不成对的文本数据)转换成 y ̃(语音数据),这样就得到成对数据,再拿成对数据去训练 TTS 系统。

图六:知识蒸馏
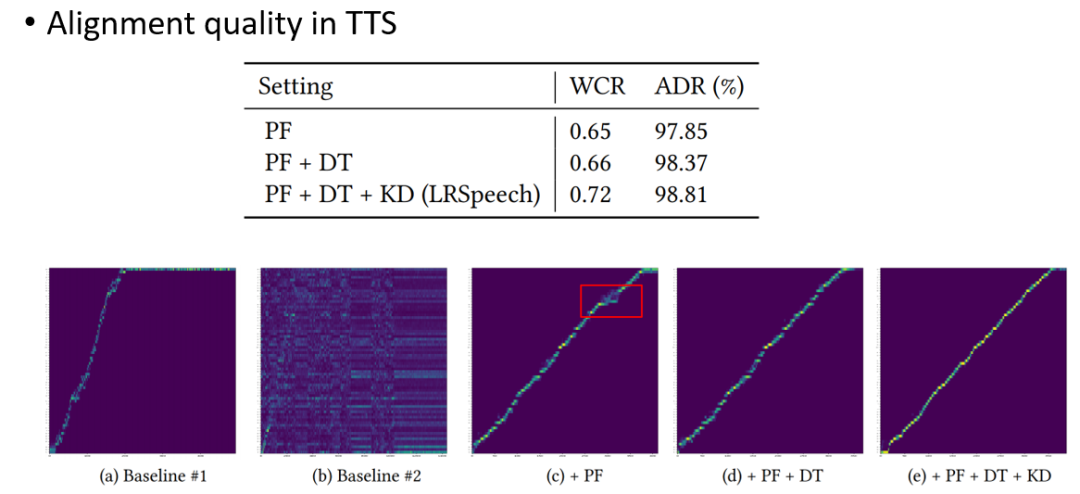
这个原理是,我们使用 TTS 模型基于文本生成语料,然后再用 Student TTS 模型,但直接这样的训练是你的 Student 模型会去模仿 Teacher 模型,而没有办法克服 Teacher 模型的问题。所以我们提出了两个衡量指标来对这些数据进行筛选,使用筛选过的数据训练 Student,这样就可以保证 Student 模型的效果。第一个衡量指标叫 WCR(word coverage ratio,词覆盖率),这个指标是为了克服词里面跳或者漏的问题。
图七右上角是一个注意力分数(attention score)图,横坐标是时间维度,纵坐标是对应的文本,这个注意力分数图来自于 Transformer 模型中的编码解码注意力机制。红色框里这个字符是没有对应声音的,这说明这块声音可能丢失。

图七:数据蒸馏过程中的数据筛选指标
我们可以看一下图七中的公式,公式中 WCR 指句子里面有 N 个词,N 个词里,我们做了两个 Max。一个 Max 维度是按时间维度,另一个 Max 维度是字符维度。比如在公式里,我们就去找这个词最大的注意力值,作为这个词被注意到的强度,然后对于整个句子而言,去找被注意到的强度最低的词的强度。如果 WCR 值比较低,那就说明这句话里面至少有一个词,被注意到的强度非常低,那么这个句子就很有可能会漏词,我们就把这个样本删掉。
我们可以发现注意力图的曲线基本上是对角的,代表发音和文本序列的单调对应关系,这也是符合我们认知的。因为读一段话都是从前往后读的,不可能乱序。基于此,我们有了第二个衡量指标——注意力分数图的对角率(Attention Diagonal Ratio, ADR),来去掉一些异常的句子。比如图七中右下角的图,声音可能完全崩掉了,就不是对角关系了,那我们就把不是对角关系的声音去掉。通过这两个指标过滤数据之后就可以去训练 TTS Student 模型了。
然后再说 ASR 的蒸馏,不同于 TTS,ASR 更要求泛化性,需要更加广泛的语料,所以训练 ASR 系统的时候,首先使用 ASR 模型,用给定了的语音数据生成文本。然后使用 TTS 系统,用给定的文本来生成合成的语音数据,并用之前提到的同样的方法过滤数据。我们用这两者一起来训练 ASR 模型,来进一步提高 ASR 的结果。
最后是实验部分。我们的数据配置中,Rich-Resource 语言是中文,低资源语言则选取了两种语言来做实验,一种是英文,一种是立陶宛语。表一概括了我们使用的数据量。
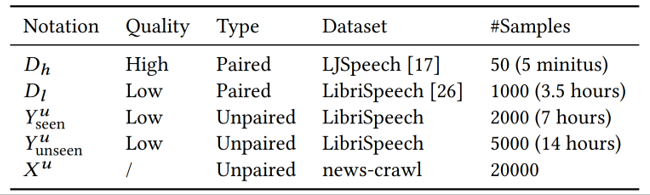
表一:实验数据量
图中可以看到,我们只使用了50条高质量的成对数据(5分钟的录音),使用了1000条 LibriSpeech 上低质量的成对数据(大约3.5个小时)。对于不成对的语音,大概使用了7000条(约20个小时)。我们还从 news-crawl 上面随机选出了2万条文本数据。
主干模型我们用的是 Transformer 模型,使用了6层的解码器和编码器,模型的 hidden size 是384,FFNsize 是1536,FFN kernel size 是9,attention heads是4,在4卡 P40 上进行训练。对于 TTS 的评估使用的是 IR 和 MOS,对于 ASR 系统的评估使用的是 WER(word error rate,词错误率)和 CER(character error rate,字符错误率)。大家可以扫描访问以下网页来听一听声音。

接下来介绍一下实验结果。我们论文里面提出了3个阶段——PF(pre-training,预训练)、DT(dual transformation,对偶学习)、KD(knowledge distillation,知识蒸馏),那每一个阶段对最后的结果有多大的贡献呢?我们在英语上做了实验,Baseline #1 是只使用成对的高质量数据,Baseline #2 是使用成对的高质量数据和低质量数据,做我们的基准。然后相应地加上 PF、DT、KD 来提升模型的效果。
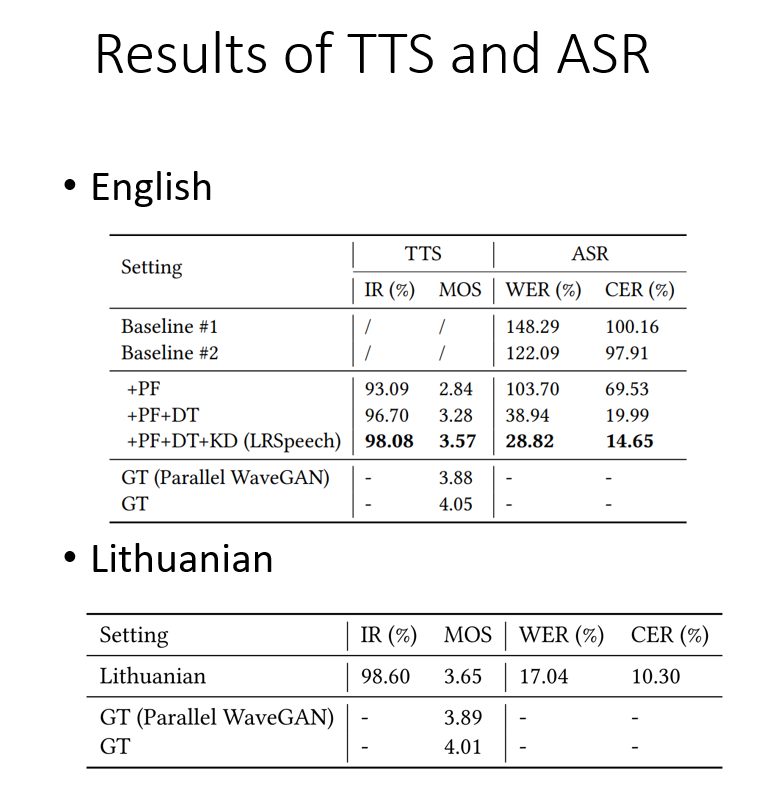
表二:在英语和立陶宛语上的实验结果
在表二中可以看到,最后 TTS 系统 IR 超过了98%,MOS 超过了3.5。最底下两行是GT(ground truth)。所谓 ground truth 就是给真实的声音评 MOS 分数,GT 是3.88,我们的分数是3.57,这个差距小于0.5。
在英语上做完实验之后,我们在真实的低资源语言立陶宛语上做了实验,可以看到在立陶宛语上,IR 超过98%,MOS 是3.6,也是满足要求的。
ASR 系统上,我们也达到了一个可观的分数。我们的 ASR 是在 LibriSpeech 的 test-clean 数据集上测的,WER、CER 的结果也比较可观。
后面是一些更加细致的探究实验。比如,前面提到的 WCR、ADR 指标,每一个模块对指标都有提高吗?我们再回顾一下,WCR 是漏词的比例或者漏词的分数,可以理解为分数越高,这个句子越不容易漏词。ADR 越高,文本和语料对齐越好,这个声音越流畅。
可以看到随着增加我们设计的方法,WCR、ADR 越来越高。同时,可以看到注意力图,随着模块的增加,注意力变得越来越清晰,对角(见图八)。
另外我们还做了一些其它详细的实验。比如图九(a)Dl 中指的是低质量多个说话者的语音,前面提到我们使用了1000条的数据量,我们做了一个实验来测试系统的敏感度,横轴1/5就是1000条的1/5——200条,5倍就是5000条。可以看到,随着数据量的增多,IR 和 WER 都变得越好。
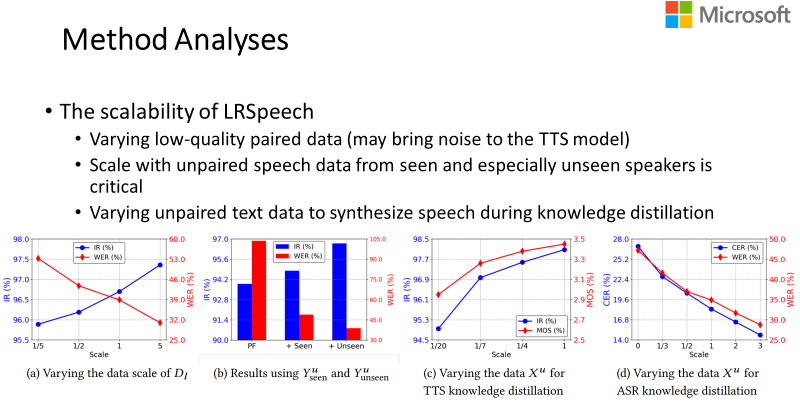
图九:LRSpeech 可扩展性实验结果
图九(b)是在系统里面,支持见过的说话者(seen speaker)和支持没有见过的说话者的实验结果。我们发现随着两种数据添加进系统,IR 是越来越高的,WER 越来越低。
图九(c)是 TTS 蒸馏,模型产生了很多的数据,经过筛选,然后对 TTS 模型进行训练,那到底生成多少数据才合适呢?可以看到越靠近1,使用数据越多,IR 和 MOS 就越高。ASR 系统也是同样的趋势(图九(d)),数据数量越多,CER、WER 越低。
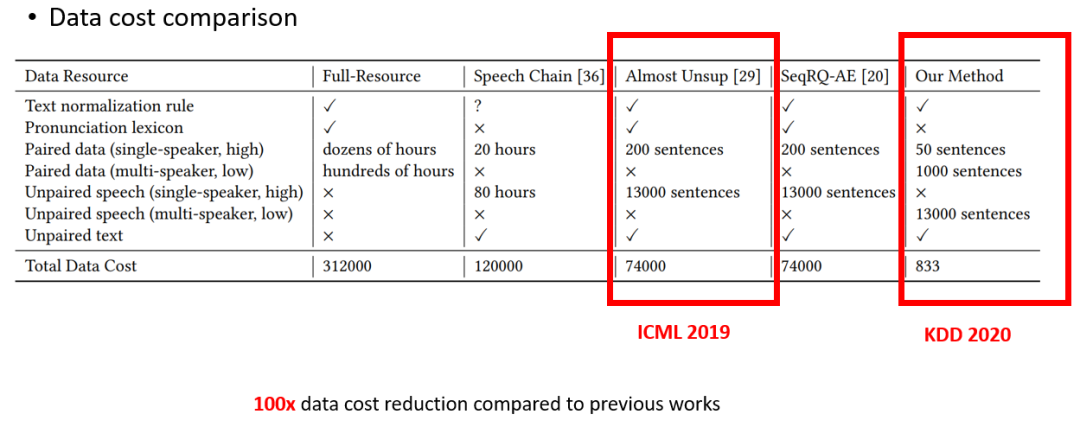
最后,我们重新回顾一下数据设置,以及数据成本(图十)。相比之前的工作,LRSpeech 的工作数据量少了很多,并且构建一个新系统的成本要比 Full-Resource 的少一百倍,并且效果可以达到工业界的要求。
微软亚洲研究院机器学习组致力于语音方面的研究,包括文本到语音合成、低资源语音合成与识别、语音翻译、歌声及音乐合成等。欢迎关注我们语音方面的研究工作:https://speechresearch.github.io/
论文:LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition
链接:https://dl.acm.org/doi/pdf/10.1145/3394486.3403331
作者:徐进、谭旭、任意、秦涛、李建、赵晟、刘铁岩
你也许还想看: