语音识别之--扑朔迷“离”


前言
把离线语音识别放到移动设备上,可让用户随时随地体验识别服务。不仅如此,一些简单的识别(例如语法识别、唤醒识别)放在移动端完成,可以节省庞大的服务器成本。然而,语音识别工程中,面对的是巨大的计算资源消耗:
1)庞大的内存资源
语音识别主要的统计模型有:声学模型+语言模型。这两者都是内存杀手,就笔者团队的云端引擎而言,运行的内存达几十个G。
2)高负载的CPU
将用户输入的语音提取特征之后,先用GMM(高斯混合模型)或DNN(深度学习模型)进行概率计算,再利用已有模型进行维特比解码的匹配搜索,这些过程对CPU的使用极高。
因此,通用的LVCSR(大词表连续语音识别)目前都是在服务器端进行。那么,要将如此大规模资源消耗的识别在手机等移动设备上完成,将怎么做呢?必须的途径是——压缩模型。语音识别中压缩模型主要包含声学模型和语言模型的压缩,减少模型的大小既能节省内存,又能同时减少算法的运行时间。然而压缩模型是以牺牲识别性能为代价。如何在模型压缩后对性能进行保证,是离线识别中的难题。
语音团队自2011年起步后技术日益成熟,于2013年底启动离线识别引擎的研发,团队先后完成了“离线Gram识别(语法识别)”、“离线唤醒识别”、“离线LVCSR(大词表连续语音识别)”三个离线识别引擎。在模型压缩的基础上,我们做了“字典树优化”、“GMM子空间聚类”、“DNN计算优化”、“前背景模型”、“即时唤醒”、“动态解码”等一系列优化工作,以保证引擎在移动设备的运行性能。本文从这三个引擎的介绍出发,基于以上的优化工作展开阐述。
一、引擎介绍
离线Gram识别
节点 |
$send = 发微信| 发语音| 发消息 $to = 给 $name = 李欣晖 | 张喜临|王珥域| 张详 $call = 打电话 |
句式 |
S1 = $send $to $name S2 = $to $name $call |
表1Gram实例
Gram识别(grammar识别)即语法识别。顾名思义,该引擎只支持指定语法的识别。离线Gram识别适用于一些固定句式的场景,比如说通讯录拨号、微信发信息等等。其优点在于符合语法的识别率很高,速度极快。
表1为Gram识别的一个样例。上方为语法中的节点,每个节点表示一个集合。比如表中共有5个节点,其中节点$name表示的是名字的集合。下方为语法中的句式,例子中共有两个句式,其中句式S1可以构成“发微信给张喜临”如此语法,句式S2可以构成“给王珥域打电话”的语法。
离线唤醒识别

图1语音唤醒“芝麻开门”
所谓唤醒识别,在这里指唤醒移动设备的识别,识别的内容可以是一个或几个唤醒词。比如大家很熟悉《大话西游》(老祖宗是《阿里巴巴与四十大盗》)的“芝麻开门”,星爷高声一呼“芝麻开门”,大石门立马乖乖打开(图1)。对比Gram识别,唤醒识别相当于“做减法”,支持的识别的内容更为精简。然而,唤醒的使用场景需时刻待机,如何保持低功耗是实现引擎中的难点。
离线LVCSR
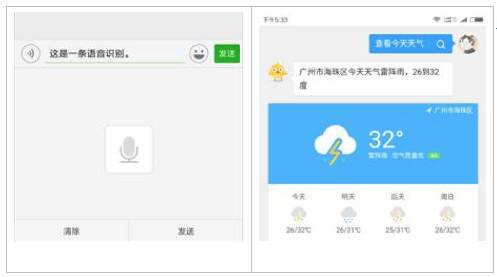
图2 团队一些LVCSR引擎(在线)
LVCSR引擎,即大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition)引擎,即为通用说话识别引擎。常见的微信语音输入法、微信语音转文字、QQ浏览器语音助手(图2),这些都是LVCSR引擎(这些应用都是在线的)。对比Gram识别,LVCSR相当于“做加法”,支持的句子灵活多变,需要庞大的数据资源。如何有效组织控制资源,以在移动设备中使用,是LVCSR引擎中的难点。
二、引擎优化
在研发以上三个引擎的过程中,我们完成了一些优化工作。在离线Gram识别中,我们先后完成了“字典树优化”、“GMM子空间聚类”、“DNN计算优化”三个优化。在以上三个优化的基础上,我们又针对唤醒识别进行了“前背景模型”、“即时唤醒”两个工作。除此之外,我们还利用“动态解码”实现了LVCSR。表2为对应每个工作的主要目标,接下来我们分别对每个优化工作展开介绍。
内容 |
目标 |
|
离线Gram识别 |
1:字典树优化 |
优化引擎整体内存 |
2:GMM子空间聚类 |
优化GMM声学模型内存及计算 |
|
3:DNN计算优化 |
优化DNN声学模型计算 |
|
离线唤醒识别 |
4:前背景模型 |
优化唤醒声学模型内存及计算 |
5:即时唤醒 |
优化唤醒体验 |
|
离线LVCSR |
6:动态解码 |
优化LVCSR语言模型内存 |
表2优化内容及对应目标
1.字典树优化
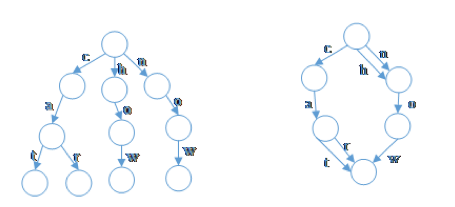
图3 前缀字典树与前后缀字典树
对于字典树,广大的工程师们并不陌生。字典树利用公共前缀来减少查询时间,最大限度地减少无谓的重复存储和检索,具有强大的存储能力和高效的查询效率。一般地,字典树是一颗前缀树。而为了更加充分地利用存储空间,引擎中采用的是前后缀字典树(图3左为前缀字典树,右为前后缀字典树)。更准确地来说,前后缀字典树不再是一颗树,而是一张有向拓扑图。而构建前后缀字典树的方法也很简单,仅需在前缀字典树的基础上进行图的最小化(minimization,见参考文献[1])操作。
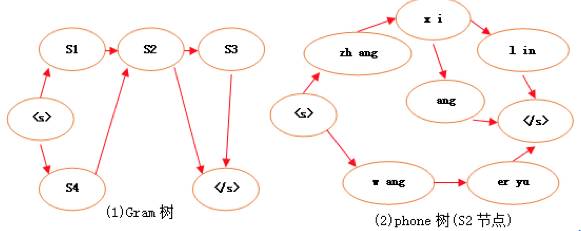
Gram树 |
phone树(S2节点) |
||
节点 |
S1={打开、查看} S2={张喜临、王珥域、张详} S3={手机号码、聊天记录} S4={发微信给} |
词语 |
S2={张喜临、王珥域、张详} name1: zh ang x i l in name2: w ang er yu name3: zh ang x i ang (拼音举例,引擎为国际音标。) |
语法 |
S1àS2àS3 “打开à王珥域à聊天记录” S4àS2“发微信给à王珥域” |
||
图4大树语法路,小树走音素
在离线Gram识别引擎中,字典树有两个作用:
(1)组织Gram(语法)上下文,这里称为Gram树;
(2)组织phone(音素)上下文,这里称为phone树。
如图4(1)所示,Gram树的每个节点是一个词语集合,比如S2节点是名字集合,包含张喜临、王珥域、张详。这些集合构成了一颗有向树,这棵树从头到位的一条路径就是一句“语法”,比如“打开王珥域聊天记录”、“发微信给李欣晖”。
由于每个词语都由一个音素串表示发音,所以一个集合里的全部词语对应的音素串可以构成一颗phone树。图4(2)为S2节点里面的词语构成的phone树(为方便阅读,图4用拼音举例,实际引擎的音素为另一套国际标准)。
以上总结起来就是:大树套小树,大树语法路,小树走音素。在解码过程中,我们只需要顺着Gram树,找出一条最优路径。而路径上每个集合节点的分数,又只需从phone树找出最优路径。所以采用这样的字典树结构,不仅可以优化空间和时间,更重要的是对我们解码提供了便利,保证了引擎解码过程的稳定性。
2.GMM子空间聚类
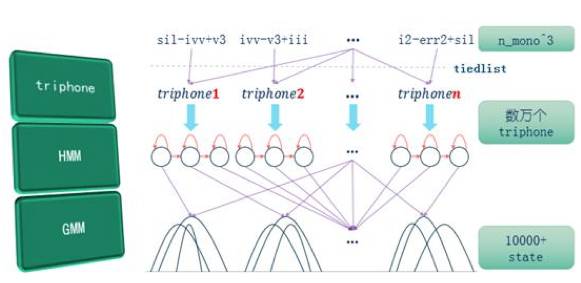
图5基于GMM的声学模型结构图
实用语音识别系统中,声学模型里的HMM聚类成nstate(10000+)个state。而这些state均由M(一般为几十)个Gaussian分布(正态分布)混合而成。这意味着,每一帧语音需nstate*M次的Gaussian公式计算。而Gaussian计算里面有浮点运算和对数运算,嵌入式设备上这两种运算均较低效。
为了避免GMM声学模型中大量的浮点运算和对数运算,我们采用SDCHMM(子空间聚类HMM,Subspace Distribution Clustering HMM)算法优化。在GMM声学模型中,如果O表示输出的HMM状态,P(O)表示输出为O的声学概率,M表示高斯混合数,C表示每个高斯分布的权重,K表示特征纬度,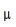
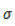
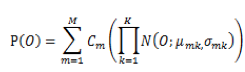
从以上介绍及公式可以得出,GMM声学模型计算中,共有nstate*M个不同的高斯分布。而SDCHMM算法将这些分布聚类到ntied个分布上,形成一张codebook,原来的分布由codebook索引替代。
然而,在多维Gaussian模型里,两个Gaussian分布的差异性过大,直接聚类将造成很大的模型误差,所以在聚类之前需要先进行子空间划分。图6所示为子空间划分及子空间聚类的过程,对于nstate*M个分布,先按特征维度K分成K个子空间。划分之后,每个K维Gaussian将变成K个单维的Gaussian分布。而在K个子空间里,每个子空间有nstate*M个单维Gaussian分布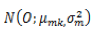
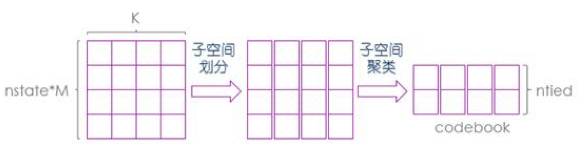
图6Subspace Distribution Clustering
在以上的k-means聚类过程中,距离计算采用巴氏距离。巴氏距离能有效衡量两个Gaussian分布的相似度,巴氏距离的计算公式及合并公式见表3。
巴氏距离 |
|
期望合并 |
|
方差合并 |
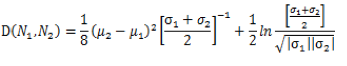
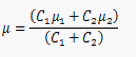
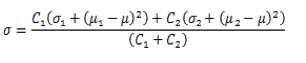
表3 巴氏距离及其合并公式
聚类之后,原有的高斯分布只需在codebook里面进行索引寻找Ntied,所以声学概率P(O)计算公式如下:
从公式中可知,SDCHMM并未减少的Gaussian分布数量,然而从codebook索引能有效降低存储。与此同时,在进行声学计算时,我们只需对codebook里面的分布进行运算,然后利用索引得出需要的声学分数,计算效率得到了提高。SDCHMM与HMM相比,在模型大小、内存及运行时间都具有优势。在手机上运行引擎,同一个测试集下两个模型的性能比较见表4:
声学算法 |
资源大小 |
召回率(句) |
准确率(句) |
实时率 |
HMM |
60MB |
(97.8%)616/630 |
(99.8%)616/617 |
0.5 |
SDCHMM |
12MB |
(98%)618/630 |
(99.8%)618/619 |
0.2 |
表4 SDCHMM实验性能结果
3. DNN计算优化
DNN声学模型的triphone层及HMM层均与GMM声学模型一致(图7)。DNN声学模型中,具有多层次的矩阵及向量运算。所以一般来说,DNN声学模型的识别准确率比GMM声学模型高,但计算量更大。
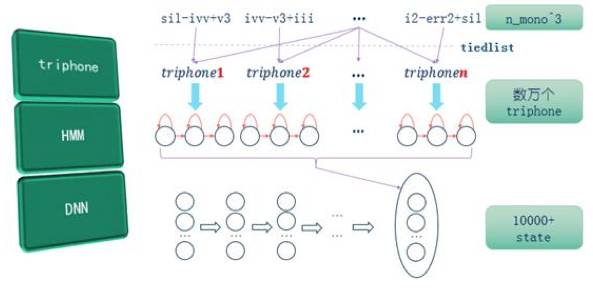
图7基于DNN的声学模型结构图
为了让DNN模型在手机上有效运行,引擎做了一些优化:
(1)将计算进行定点化处理。避开float类型,用short类型和char类型进行运算。由于DNN多层深度结构的属性,具有较强的鲁棒性。而定点化过程仅丢失少量的精度,对识别结果的影响基本可忽略。
(2)利用ARM架构处理器的扩展结构NEON进行优化,进一步用汇编语言编写核心运算代码。NEON为128位寄存器(图8),可对多个元素同时进行运算。而且NEON寄存器提供了c语言和汇编接口,易于使用。
(3)利用多线程进行优化,DNN计算中有大量的矩阵乘法运算,利用并行可以有效提高效率。
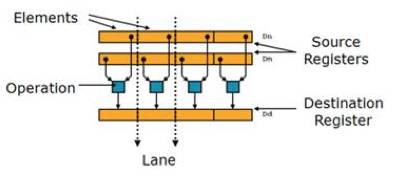
图8NEON寄存器
表5为我们优化DNN计算过程中的实时率实验结果。由结果可知,定点化计算带来了飞跃性的实时率提升,而其他优化均都具有一定有效提升。
计算 |
实时率 |
未优化 |
20 |
定点化 |
2 |
NEON c语音 |
1.2 |
NEON 汇编 |
1 |
双线程 |
0.7 |
表5实时率优化实验结果
4.前背景模型
智能家居概念的这几年愈发火热,而在智能硬件产品中,“语音唤醒”是中间不可缺少的一环。与离线Gram识别相比,唤醒识别的解码空间更小。但在实际使用中,唤醒识别有2个难点:
(1)唤醒识别的句子较短,常为一个短语,因此易受噪音干扰;
(2)唤醒识别实时待机,必须保持低功耗,否则会成为“电量杀手”。
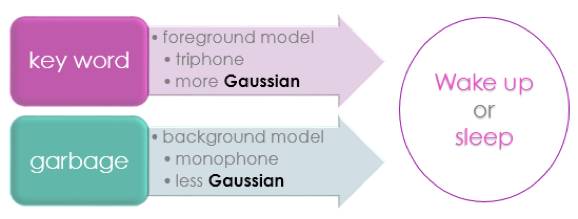
图9语音唤醒模型
为了更好的处理拒识,抵抗噪音的影响,我们对唤醒引擎的GMM声学模型分前景模型和背景模型两部分组成。如图9所示,前景模型负责识别语音中的唤醒关键词,背景模型负责吸收非关键词无关内容。
而为了保持唤醒识别低功耗,我们对模型的大小进行了优化。由于唤醒词与上下文相关,需使用三音素triphone来表示声学音素。而背景模型则只负责过滤无关语音,不需要对内容进行识别,采用单音素monophone既能有效吸收无关语音,同时可以节省空间与时间。除此之外,为了让识别的效果更好,前景模型比背景模型采用更多的高斯混合数。表6为前背景模型的实验结果,实验中前背景模型的大小仅需689KB。
声学算法 |
模型大小 |
召回率(句) |
HMM |
60MB |
92.1%(543/589) |
SDCHMM |
12MB |
92.5%(545/589) |
F&B SDCHMM |
689KB |
94.5%(557/589) |
表6唤醒前背景模型实验结果
5.即时唤醒
一般情况下,语音识别需先经过VAD(Voice Activity Detection,静音检测)的处理,来判断一句话的开头和结尾。若采用VAD的逻辑,唤醒关键词说完之后必须保持安静,否则引擎无法得出识别结果,这在体验和唤醒率两方面都会产生影响。

图10唤醒音频与据识音频
为了提高唤醒的体验,引擎对语音唤醒的逻辑进行优化,研发了即时唤醒功能。引擎抛开VAD判断说话结束,当一段录音中出现要唤醒的关键词,立马返回识别结果。如图10所示,上方为一段唤醒音频,下方为非唤醒音频。当引擎识别到唤醒词之后(get recognize result线条)立马返回结果,通知设备进行唤醒。
6. 动态解码
在研发离线LVCSR引擎过程中,鉴于手机内存的限制,引擎抛开wfst(带权有限状态自动机),采用了动态解码器。介绍动态解码之前,先提一提静态解码。一般地,语音识别包含四个过程,均可以用wfst表示:
(1) HMM状态到phone(音素)的映射,称为H(HMM)
(2)phone(音素)到音素串的映射,称为C(context)
(3)音素串到汉字的映射,称为L(lexicon)
(4)汉字到句子的映射,即语言模型,称为G(grammar)
为了方便解码过程,我们利用组合(compose,见参考文献[1])操作,将四张图合并成一张。利用这张静态的图即可完成语音识别解码过程,此图的数据量和复杂程度可想而知。
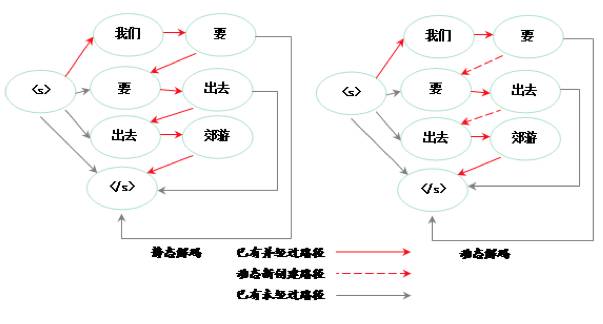
图11 静态解码与动态解码语音模型图
因此,在移动设备环境下,将所有图全部静态生成并组合是不现实的。所以对H、C、L、G这四张图,只好分而治之。此时上文提及的前后缀字典树就大显身手,C、L、G三张图均可由字典树结构建立索引。其中C构成的字典树,等价于上文中的phone树。而L构成的字典树,真的如同“查字典”作用,去寻找汉字的发音。
而G图即为语言模型G构成的字典树,这里称为语言模型树。这棵树的深度等于语言模型的阶数,所以在移动设备这样资源有限的环境下,引擎采用了二阶语言模型。在静态解码器中,G图所有可走的边全部静态生成,所以图的空间复杂度为O(n^2),其中n为图节点数。而在动态解码器中,我们只预先载入二阶词汇。简单来说,就是除了起点和终点,其他节点的入度和出度均为1,所以图的空间复杂度为O(n)。图11所示为“我们要出去郊游”这句话的二阶语言模型。左为静态解码,全部边均预先生成。右边为动态解码,两条虚线为动态生成的边。
我们对LVCSR的离线引擎和在线引擎在同一个数据集上进行了实验比较,结果见表7。在解码资源文件大小上,在线引擎是离线引擎的数百倍。而在字错率方面,在线引擎比离线引擎大概好45%。
解码器 |
语音模型阶数 |
资源大小 |
字错率 |
在线 |
四阶 |
20+G |
7.0 |
离线 |
二阶 |
40M |
12.7 |
表7 离线LVCSR实验结果
三、总结
本文基于离线识别,介绍了研发引擎过程中我们完成的一些工作。目前引擎已在华为手机、智能手表和智能机器人等产品落地使用,说明引擎已具有一定的实用性。虽然离线引擎在实时率和识别率上都远不及云端,但在应用限定的情况下,比如说查地图、查天气、查通讯录这样的固定场景,依然具有良好的体验,而且能避免网络因素的影响,节省服务器的部署。相信未来随着团队更新迭代算法和模型,以及手机性能不断提高和芯片的计算能力日益增强,离线语音识别的体验将不断提升。
参考文献
[1] M Mohri,“SPEECH RECOGNITION WITH WEIGHTEDFINITE-STATE TRANSDUCERS”
[2] adolphlu, blakezhang, “语音识别之觉迷录”
[3] eryuwang, “深度学习及其在语音识别领域的应用”
[4] Gue Jun Jung, Su-Hyun Kim and Yung-HwanOh“An efficient codebook design in SDCHMM for mobilecommunicationEnvironments”
[5] http://www.arm.com/zh/products/processors/technologies/neon.php

 微信ID:WeChatAI
微信ID:WeChatAI
 长按左侧二维码关注
长按左侧二维码关注

