业界 | 谷歌新进展:用DNN模型为YouTube视频添加环境音效字幕

我们在感知外部世界的过程中,声音(audio)起到了极大的作用。在这里,我们把声音分解为两类,一类是语音(speech),另一类是环境音(sound)。人们会本能地对环境音做出反应,比如会被突如其来的骚动所惊吓,或被情景喜剧中的背景笑声所感染。
而影音网站界的翘楚——YouTube 也深知音频的重要性。自2009年起,他们就开始让视频自动生成字幕。如今,这一功能又有了升级版——AI科技评论了解到,谷歌于昨日(3月23日)宣布,将为YouTube视频中的自动字幕增加音效信息,使人们拥有更丰富的视听体验。
据AI科技评论了解,这也是YouTube第一个用机器学习为视频自动添加音效字幕的技术,由Accessibility、Sound Understanding和YouTube团队共同完成。
用于探测环境音的DNN模型
为了探测环境音,研究人员使用深度神经网络(DNN)模型来解决下面三个问题:
检测出用户想要的声音;
对该声音进行时间定位;
音频中可能也有识别出其他并行或独立的语音,将上述两步的声音结果整合其中。
研究人员在开发DNN模型时,遇到的第一个挑战是难以获得大量有标记的环境音信息。而他们的解决方法是,转向使用弱标记数据来生成足够多的数据集。不过,问题又来了:
一个视频中有那么多种环境音,要选择哪种呢?
研究人员最后选择检测的三种环境音是“鼓掌”、“音乐”和“笑声”,因为在人们添加的字幕中,这三种被添加的次数最多,并且传达的语义信息也比较明确。
除了选定环境音,研究人员也做了许多检测环境音的工作,包括开发基础与分析框架,探测声音事件,以及将其整合进自动字幕中,这些工作可使以后在音频中整合其它类型的声音(比如“铃声”、 “犬叫声”)变得更加容易。
字幕密度检测
将视频传到YouTube上后,DNN会自动查看音频,并预测其是否包含人们感兴趣的声音事件(sound event)。由于多个音频可以同时出现,所以模型需要在每个时间段内对每个音频进行预测,直到预测完所有音频(如下图所示)。最后会得到一个密集流,即表示词表中的声音以100帧/s的频率出现。
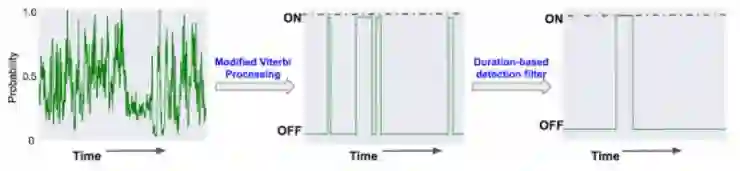
同时,研究人员还使用了含有ON和OFF的改进维特比算法(Viterbi algorithm),让密集流预测变得更平滑。每个音效的预测断对应ON。
但是,这样的分类系统可能会导致模型无法区分同一时段内发生的不同事件。这就需要模型在信息误报(false positives )和信息丢失这两点中寻找平衡。具体做法是:
根据 ON 上的时间做进一步限制,从而将系统性能推至精确度召回曲线上的一个预期点。
用户体验反馈
研究人员还与用户体验研究团队展开合作,分析了在不同条件下,用户体验有何差异。条件设定如:
分开显示语音字幕和音效字幕;
兼有语音字幕和音效字幕时,让它们交叉呈现;
仅在句子结束或语音出现停顿时,显示音效字幕;
消音看视频,评价对字幕的感受如何。
除此之外,研究人员还重点关注了声音监测系统的错误反馈。事实证明,音效信息错误会并不会使用户体验降低,原因可能是以下两点:
能听到声音的用户,忽略了字幕中的错误;
听不到声音的用户,也能从错误的字幕信息中得知有声音事件发生,因而没有遗漏关键的语音信息。
研究人员最后表示,系统偶尔犯下小打小闹的错误影响不大,只要提供的信息大部分正确,还是会赢得用户的好评。
AI科技评论招聘季全新启动!
很多读者在思考,“我和AI科技评论的距离在哪里?”,答案就是:一封求职信。
AI科技评论自创立以来,围绕学界和业界鳌头,一直为读者提供专业的AI学界,业界,开发者内容报道。我们与学术界一流专家保持密切联系,获得第一手学术进展;我们深入巨头公司AI实验室,洞悉最新产业变化;我们覆盖A类国际学术会议,发现和推动学术界和产业界的不断融合。
而你只要加入我们,就有机会和我们一起记录这个风起云涌的人工智能时代!
如果你有下面任何两项,请投简历给我们:
*英语好,看论文毫无压力
*计算机科学或者数学相关专业毕业,好钻研
*新闻媒体相关专业,好社交
*态度好,学习能力强
简历投递:lizongren@leiphone.com